CLEAR: Coverage-Based Limiting-Cell Experiment Analysis for RNA-Seq
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Supp Material.Pdf
Legends for Supplemental Figures and Tables Figure S1. Expression of Tlx during retinogenesis. (A) Staged embryos were stained for β- galactosidase knocked into the Tlx locus to indicate Tlx expression. Tlx was expressed in the neural blast layer in the early phase of neural retina development (blue signal). (B) Expression of Tlx in neural retina was quantified using Q-PCR at multiple developmental stages. Figure S2. Expression of p27kip1 and cyclin D1 (Ccnd1) at various developmental stages in wild-type or Tlx-/- retinas. (A) Q-PCR analysis of p27kip1 mRNA expression. (B) Western blotting analysis of p27kip1 protein expression. (C) Q-PCR analysis of cyclin D1 mRNA expression. Figure S3. Q-PCR analysis of mRNA expression of Sf1 (A), Lrh1 (B), and Atn1 (C) in wild-type mouse retinas. RNAs from testis and liver were used as controls. Table S1. List of genes dysregulated both at E15.5 and P0 Tlx-/- retinas. Gene E15.5 P0 Cluste Gene Title Fold Fold r Name p-value p-value Change Change nuclear receptor subfamily 0, group B, Nr0b1 1.65 0.0024 2.99 0.0035 member 1 1 Pou4f3 1.91 0.0162 2.39 0.0031 POU domain, class 4, transcription factor 3 1 Tcfap2d 2.18 0.0000 2.37 0.0001 transcription factor AP-2, delta 1 Zic5 1.66 0.0002 2.02 0.0218 zinc finger protein of the cerebellum 5 1 Zfpm1 1.85 0.0030 1.88 0.0025 zinc finger protein, multitype 1 1 Pten 1.60 0.0155 1.82 0.0131 phospatase and tensin homolog 2 Itgb5 -1.85 0.0063 -1.85 0.0007 integrin beta 5 2 Gpr49 6.86 0.0001 15.16 0.0001 G protein-coupled receptor 49 3 Cmkor1 2.60 0.0007 2.72 0.0013 -

T-Brain Regulates Archenteron Induction Signal 5207 Range of Amplification
Development 129, 5205-5216 (2002) 5205 Printed in Great Britain © The Company of Biologists Limited 2002 DEV5034 T-brain homologue (HpTb) is involved in the archenteron induction signals of micromere descendant cells in the sea urchin embryo Takuya Fuchikami1, Keiko Mitsunaga-Nakatsubo1, Shonan Amemiya2, Toshiya Hosomi1, Takashi Watanabe1, Daisuke Kurokawa1,*, Miho Kataoka1, Yoshito Harada3, Nori Satoh3, Shinichiro Kusunoki4, Kazuko Takata1, Taishin Shimotori1, Takashi Yamamoto1, Naoaki Sakamoto1, Hiraku Shimada1 and Koji Akasaka1,† 1Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Higashi-Hiroshima 739-8526, Japan 2Department of Integrated Biosciences, Graduate School of Frontier Sciences, University of Tokyo, Hongo, Bunkyo-ku, Tokyo 113-0033, Japan 3Department of Zoology, Graduate School of Science, Kyoto University, Sakyo-ku, Kyoto 606-8502, Japan 4LSL, Nerima-ku, Tokyo 178-0061, Japan *Present address: Evolutionary Regeneration Biology Group, RIKEN Center for Developmental Biology, Kobe 650-0047, Japan †Author for correspondence (e-mail: [email protected]) Accepted 30 July 2002 SUMMARY Signals from micromere descendants play a crucial role in cells, the initial specification of primary mesenchyme cells, sea urchin development. In this study, we demonstrate that or the specification of endoderm. HpTb expression is these micromere descendants express HpTb, a T-brain controlled by nuclear localization of β-catenin, suggesting homolog of Hemicentrotus pulcherrimus. HpTb is expressed that -

Accompanies CD8 T Cell Effector Function Global DNA Methylation
Global DNA Methylation Remodeling Accompanies CD8 T Cell Effector Function Christopher D. Scharer, Benjamin G. Barwick, Benjamin A. Youngblood, Rafi Ahmed and Jeremy M. Boss This information is current as of October 1, 2021. J Immunol 2013; 191:3419-3429; Prepublished online 16 August 2013; doi: 10.4049/jimmunol.1301395 http://www.jimmunol.org/content/191/6/3419 Downloaded from Supplementary http://www.jimmunol.org/content/suppl/2013/08/20/jimmunol.130139 Material 5.DC1 References This article cites 81 articles, 25 of which you can access for free at: http://www.jimmunol.org/content/191/6/3419.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists by guest on October 1, 2021 • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2013 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Global DNA Methylation Remodeling Accompanies CD8 T Cell Effector Function Christopher D. Scharer,* Benjamin G. Barwick,* Benjamin A. Youngblood,*,† Rafi Ahmed,*,† and Jeremy M. -

UNIVERSITY of CALIFORNIA RIVERSIDE Investigations Into The
UNIVERSITY OF CALIFORNIA RIVERSIDE Investigations into the Role of TAF1-mediated Phosphorylation in Gene Regulation A Dissertation submitted in partial satisfaction of the requirements for the degree of Doctor of Philosophy in Cell, Molecular and Developmental Biology by Brian James Gadd December 2012 Dissertation Committee: Dr. Xuan Liu, Chairperson Dr. Frank Sauer Dr. Frances M. Sladek Copyright by Brian James Gadd 2012 The Dissertation of Brian James Gadd is approved Committee Chairperson University of California, Riverside Acknowledgments I am thankful to Dr. Liu for her patience and support over the last eight years. I am deeply indebted to my committee members, Dr. Frank Sauer and Dr. Frances Sladek for the insightful comments on my research and this dissertation. Thanks goes out to CMDB, especially Dr. Bachant, Dr. Springer and Kathy Redd for their support. Thanks to all the members of the Liu lab both past and present. A very special thanks to the members of the Sauer lab, including Silvia, Stephane, David, Matt, Stephen, Ninuo, Toby, Josh, Alice, Alex and Flora. You have made all the years here fly by and made them so enjoyable. From the Sladek lab I want to thank Eugene, John, Linh and Karthi. Special thanks go out to all the friends I’ve made over the years here. Chris, Amber, Stephane and David, thank you so much for feeding me, encouraging me and keeping me sane. Thanks to the brothers for all your encouragement and prayers. To any I haven’t mentioned by name, I promise I haven’t forgotten all you’ve done for me during my graduate years. -

Apoptotic Cells Inflammasome Activity During the Uptake of Macrophage
Downloaded from http://www.jimmunol.org/ by guest on September 29, 2021 is online at: average * The Journal of Immunology , 26 of which you can access for free at: 2012; 188:5682-5693; Prepublished online 20 from submission to initial decision 4 weeks from acceptance to publication April 2012; doi: 10.4049/jimmunol.1103760 http://www.jimmunol.org/content/188/11/5682 Complement Protein C1q Directs Macrophage Polarization and Limits Inflammasome Activity during the Uptake of Apoptotic Cells Marie E. Benoit, Elizabeth V. Clarke, Pedro Morgado, Deborah A. Fraser and Andrea J. Tenner J Immunol cites 56 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription http://www.jimmunol.org/content/suppl/2012/04/20/jimmunol.110376 0.DC1 This article http://www.jimmunol.org/content/188/11/5682.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2012 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 29, 2021. The Journal of Immunology Complement Protein C1q Directs Macrophage Polarization and Limits Inflammasome Activity during the Uptake of Apoptotic Cells Marie E. -

Tbr1 Regulates Differentiation of the Preplate and Layer 6
Neuron, Vol. 29, 353±366, February, 2001, Copyright 2001 by Cell Press Tbr1 Regulates Differentiation of the Preplate and Layer 6 Robert F. Hevner,* Limin Shi,* Nick Justice,* proliferative cells of the ventricular zone (reviewed in Yi-Ping Hsueh,² Morgan Sheng,² Susan Smiga,* Allendoerfer and Shatz, 1994). Subsequent generations Alessandro Bulfone,*# Andre M. Goffinet,§ of postmitotic neurons migrate into the preplate and Anthony T. Campagnoni,³ intercalate between the inner and outer cell populations, and John L. R. Rubenstein*k to form the cortical plate. Thus, the cortical plate splits *Nina Ireland Laboratory of the preplate into superficial and deep components, Developmental Neurobiology thereafter termed the marginal zone and subplate, re- Department of Psychiatry spectively (Allendoerfer and Shatz, 1994). The cortical University of California, San Francisco plate grows in an ªinside-outº order, from layer 6, which San Francisco, California 94143 contains the earliest-born cortical plate neurons, to layer ² Howard Hughes Medical Institute and 2, which contains the latest-born neurons (Angevine and Department of Neurobiology Sidman, 1961; Caviness, 1982). Massachusetts General Hospital and The preplate is thought to function primarily as a Harvard Medical School framework for further development of the cortex, or- Boston, Massachusetts 02114 ganizing its laminar structure and some of its connec- ³ Neuropsychiatric Institute tions. In mice, preplate cells differentiate into at least UCLA Medical School two distinct types of neurons: Cajal-Retzius cells and 760 Westwood Plaza subplate cells (though other classifications have also Los Angeles, California 90024 been proposed; see Meyer et al., 1998, 1999). Cajal- § Neurobiology Unit Retzius cells express Reelin and calretinin (del RõÂoet FUNDP Medical School al., 1995; Alca ntara et al., 1998; Meyer et al., 1999) and B5000 Namur have been implicated in controlling cell migrations (re- Belgium viewed by Rice and Curran, 1999) and radial glia mor- phology (SupeÁ r et al., 2000). -
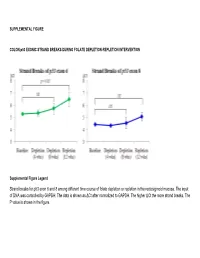
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

Haploinsufficiency of Autism Causative Gene Tbr1 Impairs Olfactory
Huang et al. Molecular Autism (2019) 10:5 https://doi.org/10.1186/s13229-019-0257-5 RESEARCH Open Access Haploinsufficiency of autism causative gene Tbr1 impairs olfactory discrimination and neuronal activation of the olfactory system in mice Tzyy-Nan Huang1†, Tzu-Li Yen1†, Lily R. Qiu2, Hsiu-Chun Chuang1,4, Jason P. Lerch2,3 and Yi-Ping Hsueh1* Abstract Background: Autism spectrum disorders (ASD) exhibit two clusters of core symptoms, i.e., social and communication impairment, and repetitive behaviors and sensory abnormalities. Our previous study demonstrated that TBR1, a causative gene of ASD, controls axonal projection and neuronal activation of amygdala and regulates social interaction and vocal communication in a mouse model. Behavioral defects caused by Tbr1 haploinsufficiency can be ameliorated by increasing neural activity via D-cycloserine treatment, an N-methyl-D-aspartate receptor (NMDAR) coagonist. In this report,weinvestigatetheroleofTBR1inregulatingolfaction and test whether D-cycloserine can also improve olfactory defects in Tbr1 mutant mice. Methods: We used Tbr1+/− mice as a model to investigate the function of TBR1 in olfactory sensation and discrimination of non-social odors. We employed a behavioral assay to characterize the olfactory defects of Tbr1+/− mice. Magnetic resonance imaging (MRI) and histological analysis were applied to characterize anatomical features. Immunostaining was performed to further analyze differences in expression of TBR1 subfamily members (namely TBR1, TBR2, and TBX21), interneuron populations, and dendritic abnormalities in olfactory bulbs. Finally, C-FOS staining was used to monitor neuronal activation of the olfactory system upon odor stimulation. Results: Tbr1+/− mice exhibited smaller olfactory bulbs and anterior commissures, reduced interneuron populations, and an abnormal dendritic morphology of mitral cells in the olfactory bulbs. -

Specific, Gene Expression Signatures in HIV-1 Infection1
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Qingsheng Li Publications Papers in the Biological Sciences 2009 Microarray Analysis of Lymphatic Tissue Reveals Stage- Specific, Gene Expression Signatures in HIV-1 Infection1 Qingsheng Li University of Minnesota, [email protected] Anthony J. Smith University of Minnesota Timothy W. Schacker University of Minnesota John V. Carlis University of Minnesota Lijie Duan University of Minnesota See next page for additional authors Follow this and additional works at: https://digitalcommons.unl.edu/biosciqingshengli Li, Qingsheng; Smith, Anthony J.; Schacker, Timothy W.; Carlis, John V.; Duan, Lijie; Reilly, Cavan S.; and Haase, Ashley T., "Microarray Analysis of Lymphatic Tissue Reveals Stage- Specific, Gene Expression Signatures in HIV-1 Infection1" (2009). Qingsheng Li Publications. 8. https://digitalcommons.unl.edu/biosciqingshengli/8 This Article is brought to you for free and open access by the Papers in the Biological Sciences at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Qingsheng Li Publications by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. Authors Qingsheng Li, Anthony J. Smith, Timothy W. Schacker, John V. Carlis, Lijie Duan, Cavan S. Reilly, and Ashley T. Haase This article is available at DigitalCommons@University of Nebraska - Lincoln: https://digitalcommons.unl.edu/ biosciqingshengli/8 NIH Public Access Author Manuscript J Immunol. Author manuscript; available in PMC 2013 January 23. Published in final edited form as: J Immunol. 2009 August 1; 183(3): 1975–1982. doi:10.4049/jimmunol.0803222. Microarray Analysis of Lymphatic Tissue Reveals Stage- Specific, Gene Expression Signatures in HIV-1 Infection1 $watermark-text $watermark-text $watermark-text Qingsheng Li2,*, Anthony J. -

The Roles of Orphan Nuclear Receptors in the Development and Function of the Immune System
Cellular & Molecular Immunology 401 Review The Roles of Orphan Nuclear Receptors in the Development and Function of the Immune System Ivan Dzhagalov1, Nu Zhang1 and You-Wen He1, 2 Hormones and their receptors regulate cell growth, differentiation and apoptosis and also play important roles in immune function. Recent studies on the subfamily of the orphan nuclear receptors known as retinoid-acid related orphan receptors (ROR) have shed important insights on the roles of this group of nuclear proteins in the development and function of the immune system. RORα regulates inflammatory cytokine production in both innate and adaptive immune system while RORγ regulates the normal development of T lymphocyte repertoire and secondary lymphoid organs. Cellular & Molecular Immunology. 2004;1(6):401-407. Key Words: thymocyte apoptosis, TCR repertoire, inflammatory cytokine, lymphoid organogenesis, ROR Introduction LBD of RORs shares approximately 50% identity at the amino acid level. Though they do not share ligands, the The nuclear hormone receptor superfamily is composed of highly conserved DBD of RORs suggests that these orphan both ligand-regulated transcription factors as well as receptors may bind to the same DNA elements. orphan receptors (1, 2). These receptors perform diverse functions in development, reproduction, and homeostasis RORα by regulating cell growth, differentiation, and apoptosis. Aberrant activities of certain receptors have been causally RORα was initially discovered through its homology to linked to neoplasia. Despite an intensive search for their retinoid acid receptor (RAR). It is widely expressed in a ligands, most members of the orphan nuclear receptor variety of tissues, with particularly high levels in family still do not have an identified ligand (3). -

The T-Box Transcription Factor Eomesodermin Is Essential for AVE Induction in the Mouse Embryo
Downloaded from genesdev.cshlp.org on October 5, 2021 - Published by Cold Spring Harbor Laboratory Press RESEARCH COMMUNICATION zation of cells within the VE epithelium (Arnold and The T-box transcription factor Robertson 2009; Rossant and Tam 2009; Nowotschin and Eomesodermin is essential Hadjantonakis 2010). This Nodal signaling-dependent, unilateral movement of cells converts the pre-existing for AVE induction in the proximodistal (PD) axis of the egg cylinder to an AP axis (Norris et al. 2002). Cells of the AVE express secreted mouse embryo Nodal, Bmp, and Wnt antagonists, thereby restricting Sonja Nowotschin,1,4 Ita Costello,2,4 signaling to the posterior epiblast and confining the site of nascent mesoderm induction to the primitive streak. Anna Piliszek,1,5 Gloria S. Kwon,1 Chai-an Mao,3 3 2,6 Eomesodermin (Eomes, also referred to as Tbr2), a mem- William H. Klein, Elizabeth J. Robertson, ber of the T-box family of transcription factors, is dynam- and Anna-Katerina Hadjantonakis1,6 ically expressed in both the embryonic and extraembryonic tissues of the early embryo. Eomes mutants exhibit defects 1Developmental Biology Program, Sloan-Kettering Institute, 2 in the trophectoderm and arrest at implantation (Russ et al. New York, New York 10065, USA; Sir William Dunn School 2000), obscuring its role at later stages of development. of Pathology, University of Oxford, Oxford OX1 3RE, United Chimera analysis, together with epiblast-specific ablation, 3 Kingdom; Department of Biochemistry and Molecular Biology, has uncovered essential functions for Eomes in epithelial- M.D. Anderson Cancer Center, Houston, Texas 77030, USA to-mesenchymal transition (EMT) and mesoderm delami- nation as well as in specification of the definitive endoderm Reciprocal inductive interactions between the embryonic and cardiac mesoderm (Arnold et al. -

Revisiting the Impact of Local Leptin Signaling in Folliculogenesis and Oocyte Maturation in Obese Mothers
International Journal of Molecular Sciences Review Revisiting the Impact of Local Leptin Signaling in Folliculogenesis and Oocyte Maturation in Obese Mothers Karolina Wołodko 1 , Juan Castillo-Fernandez 2 , Gavin Kelsey 2,3 and António Galvão 1,2,3,* 1 Department of Reproductive Immunology and Pathology, Institute of Animal Reproduction and Food Research of PAS, Tuwima 10, 10-748 Olsztyn, Poland; [email protected] 2 Epigenetics Programme, Babraham Institute, Cambridge CB22 3AT, UK; [email protected] (J.C.-F.); [email protected] (G.K.) 3 Centre for Trophoblast Research, University of Cambridge, Cambridge CB2 3EG, UK * Correspondence: [email protected] or [email protected] Abstract: The complex nature of folliculogenesis regulation accounts for its susceptibility to maternal physiological fitness. In obese mothers, progressive expansion of adipose tissue culminates with severe hyperestrogenism and hyperleptinemia with detrimental effects for ovarian performance. Indeed, maternal obesity is associated with the establishment of ovarian leptin resistance. This review summarizes current knowledge on potential effects of impaired leptin signaling throughout folliculogenesis and oocyte developmental competence in mice and women. Keywords: leptin; obesity; ovary; folliculogenesis; oocyte Citation: Wołodko, K.; Castillo-Fernandez, J.; Kelsey, G.; 1. Introduction Galvão, A. Revisiting the Impact of Local Leptin Signaling in Obesity is a prevalent disease worldwide, usually associated with infertility. Studies Folliculogenesis and Oocyte in obese infertile females show the occurrence of systemic hyperestrogenemia, hyperin- Maturation in Obese Mothers. Int. J. sulinemia, and associated ovarian dysfunction through premature follicular atresia and Mol. Sci. 2021, 22, 4270. https:// anovulation [1]. Indeed, the ovaries of obese mothers have been shown to accumulate doi.org/10.3390/ijms22084270 lipids, high levels of reactive oxygen species [2], and inflammatory mediators [3].