Automatic Raaga Identification System for Carnatic Music Using Hidden Markov Model by Prasad Reddy P.V.G.D, B
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
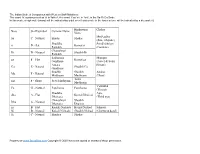
Note Staff Symbol Carnatic Name Hindustani Name Chakra Sa C
The Indian Scale & Comparison with Western Staff Notations: The vowel 'a' is pronounced as 'a' in 'father', the vowel 'i' as 'ee' in 'feet', in the Sa-Ri-Ga Scale In this scale, a high note (swara) will be indicated by a dot over it and a note in the lower octave will be indicated by a dot under it. Hindustani Chakra Note Staff Symbol Carnatic Name Name MulAadhar Sa C - Natural Shadaj Shadaj (Base of spine) Shuddha Swadhishthan ri D - flat Komal ri Rishabh (Genitals) Chatushruti Ri D - Natural Shudhh Ri Rishabh Sadharana Manipur ga E - Flat Komal ga Gandhara (Navel & Solar Antara Plexus) Ga E - Natural Shudhh Ga Gandhara Shudhh Shudhh Anahat Ma F - Natural Madhyam Madhyam (Heart) Tivra ma F - Sharp Prati Madhyam Madhyam Vishudhh Pa G - Natural Panchama Panchama (Throat) Shuddha Ajna dha A - Flat Komal Dhaivat Dhaivata (Third eye) Chatushruti Shudhh Dha A - Natural Dhaivata Dhaivat ni B - Flat Kaisiki Nishada Komal Nishad Sahsaar Ni B - Natural Kakali Nishada Shudhh Nishad (Crown of head) Så C - Natural Shadaja Shadaj Property of www.SarodSitar.com Copyright © 2010 Not to be copied or shared without permission. Short description of Few Popular Raags :: Sanskrut (Sanskrit) pronunciation is Raag and NOT Raga (Alphabetical) Aroha Timing Name of Raag (Karnataki Details Avroha Resemblance) Mood Vadi, Samvadi (Main Swaras) It is a old raag obtained by the combination of two raags, Ahiri Sa ri Ga Ma Pa Ga Ma Dha ni Så Ahir Bhairav Morning & Bhairav. It belongs to the Bhairav Thaat. Its first part (poorvang) has the Bhairav ang and the second part has kafi or Så ni Dha Pa Ma Ga ri Sa (Chakravaka) serious, devotional harpriya ang. -

Analyzing the Melodic Structure of a Raga-Based Song
Georgian Electronic Scientific Journal: Musicology and Cultural Science 2009 | No.2(4) A Statistical Analysis Of A Raga-Based Song Soubhik Chakraborty1*, Ripunjai Kumar Shukla2, Kolla Krishnapriya3, Loveleen4, Shivee Chauhan5, Mona Kumari6, Sandeep Singh Solanki7 1, 2Department of Applied Mathematics, BIT Mesra, Ranchi-835215, India 3-7Department of Electronics and Communication Engineering, BIT Mesra, Ranchi-835215, India * email: [email protected] Abstract The origins of Indian classical music lie in the cultural and spiritual values of India and go back to the Vedic Age. The art of music was, and still is, regarded as both holy and heavenly giving not only aesthetic pleasure but also inducing a joyful religious discipline. Emotion and devotion are the essential characteristics of Indian music from the aesthetic side. From the technical perspective, we talk about melody and rhythm. A raga, the nucleus of Indian classical music, may be defined as a melodic structure with fixed notes and a set of rules characterizing a certain mood conveyed by performance.. The strength of raga-based songs, although they generally do not quite maintain the raga correctly, in promoting Indian classical music among laymen cannot be thrown away. The present paper analyzes an old and popular playback song based on the raga Bhairavi using a statistical approach, thereby extending our previous work from pure classical music to a semi-classical paradigm. The analysis consists of forming melody groups of notes and measuring the significance of these groups and segments, analysis of lengths of melody groups, comparing melody groups over similarity etc. Finally, the paper raises the question “What % of a raga is contained in a song?” as an open research problem demanding an in-depth statistical investigation. -

A Novel EEG Based Study with Hindustani Classical Music
Can Musical Emotion Be Quantified With Neural Jitter Or Shimmer? A Novel EEG Based Study With Hindustani Classical Music Sayan Nag, Sayan Biswas, Sourya Sengupta Shankha Sanyal, Archi Banerjee, Ranjan Department of Electrical Engineering Sengupta,Dipak Ghosh Jadavpur University Sir C.V. Raman Centre for Physics and Music Kolkata, India Jadavpur University Kolkata, India Abstract—The term jitter and shimmer has long been used in In India, music (geet) has been a subject of aesthetic and the domain of speech and acoustic signal analysis as a parameter intellectual discourse since the times of Vedas (samaveda). for speaker identification and other prosodic features. In this Rasa was examined critically as an essential part of the theory study, we look forward to use the same parameters in neural domain to identify and categorize emotional cues in different of art by Bharata in Natya Sastra, (200 century BC). The rasa musical clips. For this, we chose two ragas of Hindustani music is considered as a state of enhanced emotional perception which are conventionally known to portray contrast emotions produced by the presence of musical energy. It is perceived as and EEG study was conducted on 5 participants who were made a sentiment, which could be described as an aesthetic to listen to 3 min clip of these two ragas with sufficient resting experience. Although unique, one can distinguish several period in between. The neural jitter and shimmer components flavors according to the emotion that colors it [11]. Several were evaluated for each experimental condition. The results reveal interesting information regarding domain specific arousal emotional flavors are listed, namely erotic love (sringara), of human brain in response to musical stimuli and also regarding pathetic (karuna), devotional (bhakti), comic (hasya), horrific trait characteristics of an individual. -

CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme
CARNATIC MUSIC (CODE – 032) CLASS – X (Melodic Instrument) 2020 – 21 Marking Scheme Time - 2 hrs. Max. Marks : 30 Part A Multiple Choice Questions: Attempts any of 15 Question all are of Equal Marks : 1. Raga Abhogi is Janya of a) Karaharapriya 2. 72 Melakarta Scheme has c) 12 Chakras 3. Identify AbhyasaGhanam form the following d) Gitam 4. Idenfity the VarjyaSwaras in Raga SuddoSaveri b) GhanDharam – NishanDham 5. Raga Harikambhoji is a d) Sampoorna Raga 6. Identify popular vidilist from the following b) M. S. Gopala Krishnan 7. Find out the string instrument which has frets d) Veena 8. Raga Mohanam is an d) Audava – Audava Raga 9. Alankaras are set to d) 7 Talas 10 Mela Number of Raga Maya MalawaGoula d) 15 11. Identify the famous flutist d) T R. Mahalingam 12. RupakaTala has AksharaKals b) 6 13. Indentify composer of Navagrehakritis c) MuthuswaniDikshitan 14. Essential angas of kriti are a) Pallavi-Anuppallavi- Charanam b) Pallavi –multifplecharanma c) Pallavi – MukkyiSwaram d) Pallavi – Charanam 15. Raga SuddaDeven is Janya of a) Sankarabharanam 16. Composer of Famous GhanePanchartnaKritis – identify a) Thyagaraja 17. Find out most important accompanying instrument for a vocal concert b) Mridangam 18. A musical form set to different ragas c) Ragamalika 19. Identify dance from of music b) Tillana 20. Raga Sri Ranjani is Janya of a) Karahara Priya 21. Find out the popular Vena artist d) S. Bala Chander Part B Answer any five questions. All questions carry equal marks 5X3 = 15 1. Gitam : Gitam are the simplest musical form. The term “Gita” means song it is melodic extension of raga in which it is composed. -
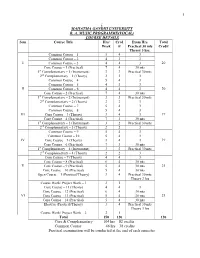
1 ; Mahatma Gandhi University B. A. Music Programme(Vocal
1 ; MAHATMA GANDHI UNIVERSITY B. A. MUSIC PROGRAMME(VOCAL) COURSE DETAILS Sem Course Title Hrs/ Cred Exam Hrs. Total Week it Practical 30 mts Credit Theory 3 hrs. Common Course – 1 5 4 3 Common Course – 2 4 3 3 I Common Course – 3 4 4 3 20 Core Course – 1 (Practical) 7 4 30 mts 1st Complementary – 1 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 1 (Theory) 2 2 3 Common Course – 4 5 4 3 Common Course – 5 4 3 3 II Common Course – 6 4 4 3 20 Core Course – 2 (Practical) 7 4 30 mts 1st Complementary – 2 (Instrument) 3 3 Practical 30 mts 2nd Complementary – 2 (Theory) 2 2 3 Common Course – 7 5 4 3 Common Course – 8 5 4 3 III Core Course – 3 (Theory) 3 4 3 19 Core Course – 4 (Practical) 7 3 30 mts 1st Complementary – 3 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 3 (Theory) 2 2 3 Common Course – 9 5 4 3 Common Course – 10 5 4 3 IV Core Course – 5 (Theory) 3 4 3 19 Core Course – 6 (Practical) 7 3 30 mts 1st Complementary – 4 (Instrument) 3 2 Practical 30 mts 2nd Complementary – 4 (Theory) 2 2 3 Core Course – 7 (Theory) 4 4 3 Core Course – 8 (Practical) 6 4 30 mts V Core Course – 9 (Practical) 5 4 30 mts 21 Core Course – 10 (Practical) 5 4 30 mts Open Course – 1 (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 1 2 1 Core Course – 11 (Theory) 4 4 3 Core Course – 12 (Practical) 6 4 30 mts VI Core Course – 13 (Practical) 5 4 30 mts 21 Core Course – 14 (Practical) 5 4 30 mts Elective (Practical/Theory) 3 4 Practical 30 mts Theory 3 hrs Course Work/ Project Work – 2 2 1 Total 150 120 120 Core & Complementary 104 hrs 82 credits Common Course 46 hrs 38 credits Practical examination will be conducted at the end of each semester 2 MAHATMA GANDHI UNIVERSITY B. -

Ragang Based Raga Identification System
IOSR Journal Of Humanities And Social Science (IOSR-JHSS) Volume 16, Issue 3 (Sep. - Oct. 2013), PP 83-85 e-ISSN: 2279-0837, p-ISSN: 2279-0845. www.Iosrjournals.Org Ragang based Raga Identification system Awadhesh Pratap Singh Tomer Assistant Professor (Music-vocal), Department of Music Dr. H. S. G. Central University Sagar M.P. Gopal Sangeet Mahavidhyalaya Mahaveer Chowk Bina Distt. Sagar (M.P.) 470113 Abstract: The paper describes the importance of Ragang in the Raga classification system and its utility as being unique musical patterns; in raga identification. The idea behind the paper is to reinvestigate Ragang with a prospective to use it in digital classification and identification system. Previous works in this field are based on Swara sequence and patterns, Pakad and basic structure of Raga individually. To my best knowledge previous works doesn’t deal with the Ragang Patterns for identification and thus the paper approaches Raga identification with a Ragang (musical pattern group) base model. This work also reviews the Thaat-Raagang classification system. This describes scope in application for Automatic digital teaching of classical music by software program to analyze music (Classical vocal and instrumental). The Raag classification should be flawless and logically perfect for best ever results. Key words: Aadhar shadaj, Ati Komal Gandhar , Bahar, Bhairav, Dhanashri, Dhaivat, Gamak, Gandhar, Gitkarri, Graam, Jati Gayan, Kafi, Kanada, Kann, Komal Rishabh , Madhyam, Malhar, Meed, Nishad, Raga, Ragang, Ragini, Rishabh, Saarang, Saptak, Shruti, Shrutiantra, Swaras, Swar Prastar, Thaat, Tivra swar, UpRag, Vikrat Swar A Raga is a tonal frame work for composition and improvisation. It embodies a unique musical idea.(Balle and Joshi 2009, 1) Ragang is included in 10 point Raga classification of Saarang Dev, With Graam Raga, UpRaga and more. -

Vocal Level 1
Vocal Level 1 Introduction Welcome to Vocal Level 1. You are about to start the wonderful journey of learning to sing, a journey that is challenging, but rewarding and enjoyable! Whether you want to jam with a band or enjoy singing solo, this series of lessons will get you ready to perform with skill & confidence. What will you learn? Level 1 covers the following topics Introduction to music Origin of Indian music Genres of Indian Music Swar o Shuddha and Vikrit Swar o Chal and Achal Swar Breathing Exercises Sur Exercises for perfecting the notes (swar) Varna Aaroh-Avaroh Alankaar Saptak Rhythm/Taal o Dadra Taal o Keherwa Taal Brief note on Tabla National Song National Anthem Simple tips to improve Singing 1 What You Need Harmonium / Synthesizer Electronic Tabla / Tabla App You can learn to sing without any of the above instruments also and by tapping your feet, however you will get a lot more out of this series if you have a basic harmonium and a digital Tabla to practice. How to Practice At Home Apart from this booklet for level 1, there will be video clippings shown to you for each topic in all the lessons. During practice at home, please follow the method shown in the clippings. Practice each lesson several times before meeting for the next lesson. A daily practice regime of a minimum of 15 minutes will suffice to start with. Practicing with the harmonium and the digital Tabla will certainly have an added advantage. Digital Tabla machines or Tabla software’s are easily available and ideally should be used for daily practice. -

Paper 66 2019.Pdf
1 Accademia Musicale Studio Musica International Conference on New Music Concepts and Inspired Education Proceeding Book Vol. 6 Accademia Musicale Studio Musica Michele Della Ventura Editor COPYRIGHT MATERIAL 2 Printed in Italy First edition: April 2019 ©2019 Accademia Musicale Studio Musica www.studiomusicatreviso.it Accademia Musicale Studio Musica – Treviso (Italy) ISBN: 978-88-944350-0-9 3 Preface This volume of proceedings from the conference provides an opportunity for readers to engage with a selection of refereed papers that were presented during the International Conference on New Music Concepts and Inspired Education. The reader will sample here reports of research on topics ranging from mathematical models in music to pattern recognition in music; symbolic music processing; music synthesis and transformation; learning and conceptual change; teaching strategies; e-learning and innovative learning. This book is meant to be a textbook that is suitable for courses at the advanced under- graduate and beginning master level. By mixing theory and practice, the book provides both profound technological knowledge as well as a comprehensive treatment of music processing applications. The goals of the Conference are to foster international research collaborations in the fields of Music Studies and Education as well as to provide a forum to present current research results in the forms of technical sessions, round table discussions during the conference period in a relax and enjoyable atmosphere. 36 papers from 16 countries were received. All the submissions were reviewed on the basis of their significance, novelty, technical quality, and practical impact. After careful reviews by at least three experts in the relevant areas for each paper, 12 papers from 10 countries were accepted for presentation or poster display at the conference. -

A Nonlinear Study on Time Evolution in Gharana
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 15 April 2019 doi:10.20944/preprints201904.0157.v1 A NONLINEAR STUDY ON TIME EVOLUTION IN GHARANA TRADITION OF INDIAN CLASSICAL MUSIC Archi Banerjee1,2*, Shankha Sanyal1,2*, Ranjan Sengupta2 and Dipak Ghosh2 1 Department of Physics, Jadavpur University 2 Sir C.V. Raman Centre for Physics and Music Jadavpur University, Kolkata: 700032 India *[email protected] * Corresponding author Archi Banerjee: [email protected] Shankha Sanyal: [email protected]* Ranjan Sengupta: [email protected] Dipak Ghosh: [email protected] © 2019 by the author(s). Distributed under a Creative Commons CC BY license. Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 15 April 2019 doi:10.20944/preprints201904.0157.v1 A NONLINEAR STUDY ON TIME EVOLUTION IN GHARANA TRADITION OF INDIAN CLASSICAL MUSIC ABSTRACT Indian classical music is entirely based on the “Raga” structures. In Indian classical music, a “Gharana” or school refers to the adherence of a group of musicians to a particular musical style of performing a raga. The objective of this work was to find out if any characteristic acoustic cues exist which discriminates a particular gharana from the other. Another intriguing fact is if the artists of the same gharana keep their singing style unchanged over generations or evolution of music takes place like everything else in nature. In this work, we chose to study the similarities and differences in singing style of some artists from at least four consecutive generations representing four different gharanas using robust non-linear methods. For this, alap parts of a particular raga sung by all the artists were analyzed with the help of non linear multifractal analysis (MFDFA and MFDXA) technique. -

Carnatic Music Primer
A KARNATIC MUSIC PRIMER P. Sriram PUBLISHED BY The Carnatic Music Association of North America, Inc. ABOUT THE AUTHOR Dr. Parthasarathy Sriram, is an aerospace engineer, with a bachelor’s degree from IIT, Madras (1982) and a Ph.D. from Georgia Institute of Technology where is currently a research engineer in the Dept. of Aerospace Engineering. The preface written by Dr. Sriram speaks of why he wrote this monograph. At present Dr. Sriram is looking after the affairs of the provisionally recognized South Eastern chapter of the Carnatic Music Association of North America in Atlanta, Georgia. CMANA is very privileged to publish this scientific approach to Carnatic Music written by a young student of music. © copyright by CMANA, 375 Ridgewood Ave, Paramus, New Jersey 1990 Price: $3.00 Table of Contents Preface...........................................................................................................................i Introduction .................................................................................................................1 Swaras and Swarasthanas..........................................................................................5 Ragas.............................................................................................................................10 The Melakarta Scheme ...............................................................................................12 Janya Ragas .................................................................................................................23 -

Transcription and Analysis of Ravi Shankar's Morning Love For
Louisiana State University LSU Digital Commons LSU Doctoral Dissertations Graduate School 2013 Transcription and analysis of Ravi Shankar's Morning Love for Western flute, sitar, tabla and tanpura Bethany Padgett Louisiana State University and Agricultural and Mechanical College, [email protected] Follow this and additional works at: https://digitalcommons.lsu.edu/gradschool_dissertations Part of the Music Commons Recommended Citation Padgett, Bethany, "Transcription and analysis of Ravi Shankar's Morning Love for Western flute, sitar, tabla and tanpura" (2013). LSU Doctoral Dissertations. 511. https://digitalcommons.lsu.edu/gradschool_dissertations/511 This Dissertation is brought to you for free and open access by the Graduate School at LSU Digital Commons. It has been accepted for inclusion in LSU Doctoral Dissertations by an authorized graduate school editor of LSU Digital Commons. For more information, please [email protected]. TRANSCRIPTION AND ANALYSIS OF RAVI SHANKAR’S MORNING LOVE FOR WESTERN FLUTE, SITAR, TABLA AND TANPURA A Written Document Submitted to the Graduate Faculty of the Louisiana State University and Agricultural and Mechanical College in partial fulfillment of the requirements for the degree of Doctor of Musical Arts in The School of Music by Bethany Padgett B.M., Western Michigan University, 2007 M.M., Illinois State University, 2010 August 2013 ACKNOWLEDGEMENTS I am entirely indebted to many individuals who have encouraged my musical endeavors and research and made this project and my degree possible. I would first and foremost like to thank Dr. Katherine Kemler, professor of flute at Louisiana State University. She has been more than I could have ever hoped for in an advisor and mentor for the past three years. -

Music & Dance Examinations
MUSIC & DANCE EXAMINATIONS I. THE AIMS AND OBJECTIVES OF THE FACULTY ARE 1. To encourage the study of Performing Arts as a vocation 2. To institute degree and Junior Diploma Courses in Performing Arts 3 To produce artists of high order and to train and prepare teachers well versed in theory, practice and history of Performing Arts; 4 To conduct research and to carry on auxiliary activities such as collection and publication of manuscripts; 5. To develop a high standard of education and knowledge of the Theory of Music and aesthetics, both ancient and modern, through the study of old and new literature in Sanskrit and other languages and give training in performing arts as a vocation 6. To make special arrangements by way of extension course for those who are not otherwise qualified to be admitted to the Faculty. 7. The Faculty while serving as a repository of all forms of Music including different schools of Music and regional styles, seeks to preserve the traditional methods of teaching and in doing so makes use of all modern techniques e.g. notation and Science of voice culture. In furthering the objectives laid down above, the Faculty arranges for lectures, concerts, demonstrations and excursion tours to important centers of Music in India. II. ADMISSION TO COLLEGES/FACULTIES OF THE UNIVERSITY 1. The last date for admission to all the constituent Colleges / Faculties of the University shall be fixed each year by the Academic Council. 2. Each College/ Faculty maintained by the University shall have a separate form of application which will be serially numbered and issued by the Principal/Dean of the College /Faculty concerned, on payment of the prescribed amount of application fee or by any other officer deputed by University.