Topographic Analysis and Predictive Modeling Using Geographic Information Systems Steven Hall Clemson University, [email protected]
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Shaded Elevation Map of Ohio
STATE OF OHIO DEPARTMENT OF NATURAL RESOURCES DIVISION OF GEOLOGICAL SURVEY Ted Strickland, Governor Sean D. Logan, Director Lawrence H. Wickstrom, Chief SHADED ELEVATION MAP OF OHIO 0 10 20 30 40 miles 0 10 20 30 40 kilometers SCALE 1:2,000,000 427-500500-600600-700700-800800-900900-10001000-11001100-12001200-13001300-14001400-1500>1500 Land elevation in feet Lake Erie water depth in feet 0-6 7-12 13-18 19-24 25-30 31-36 37-42 43-48 49-54 55-60 61-66 67-84 SHADED ELEVATION MAP This map depicts the topographic relief of Ohio’s landscape using color lier impeded the southward-advancing glaciers, causing them to split into to represent elevation intervals. The colorized topography has been digi- two lobes, the Miami Lobe on the west and the Scioto Lobe on the east. tally shaded from the northwest slightly above the horizon to give the ap- Ridges of thick accumulations of glacial material, called moraines, drape pearance of a three-dimensional surface. The map is based on elevation around the outlier and are distinct features on the map. Some moraines in data from the U.S. Geological Survey’s National Elevation Dataset; the Ohio are more than 200 miles long. Two other glacial lobes, the Killbuck grid spacing for the data is 30 meters. Lake Erie water depths are derived and the Grand River Lobes, are present in the northern and northeastern from National Oceanic and Atmospheric Administration data. This digi- portions of the state. tally derived map shows details of Ohio’s topography unlike any map of 4 Eastern Continental Divide—A continental drainage divide extends the past. -

Meyers Height 1
University of Connecticut DigitalCommons@UConn Peer-reviewed Articles 12-1-2004 What Does Height Really Mean? Part I: Introduction Thomas H. Meyer University of Connecticut, [email protected] Daniel R. Roman National Geodetic Survey David B. Zilkoski National Geodetic Survey Follow this and additional works at: http://digitalcommons.uconn.edu/thmeyer_articles Recommended Citation Meyer, Thomas H.; Roman, Daniel R.; and Zilkoski, David B., "What Does Height Really Mean? Part I: Introduction" (2004). Peer- reviewed Articles. Paper 2. http://digitalcommons.uconn.edu/thmeyer_articles/2 This Article is brought to you for free and open access by DigitalCommons@UConn. It has been accepted for inclusion in Peer-reviewed Articles by an authorized administrator of DigitalCommons@UConn. For more information, please contact [email protected]. Land Information Science What does height really mean? Part I: Introduction Thomas H. Meyer, Daniel R. Roman, David B. Zilkoski ABSTRACT: This is the first paper in a four-part series considering the fundamental question, “what does the word height really mean?” National Geodetic Survey (NGS) is embarking on a height mod- ernization program in which, in the future, it will not be necessary for NGS to create new or maintain old orthometric height benchmarks. In their stead, NGS will publish measured ellipsoid heights and computed Helmert orthometric heights for survey markers. Consequently, practicing surveyors will soon be confronted with coping with these changes and the differences between these types of height. Indeed, although “height’” is a commonly used word, an exact definition of it can be difficult to find. These articles will explore the various meanings of height as used in surveying and geodesy and pres- ent a precise definition that is based on the physics of gravitational potential, along with current best practices for using survey-grade GPS equipment for height measurement. -

Digital Mapping & Spatial Analysis
Digital Mapping & Spatial Analysis Zach Silvia Graduate Community of Learning Rachel Starry April 17, 2018 Andrew Tharler Workshop Agenda 1. Visualizing Spatial Data (Andrew) 2. Storytelling with Maps (Rachel) 3. Archaeological Application of GIS (Zach) CARTO ● Map, Interact, Analyze ● Example 1: Bryn Mawr dining options ● Example 2: Carpenter Carrel Project ● Example 3: Terracotta Altars from Morgantina Leaflet: A JavaScript Library http://leafletjs.com Storytelling with maps #1: OdysseyJS (CartoDB) Platform Germany’s way through the World Cup 2014 Tutorial Storytelling with maps #2: Story Maps (ArcGIS) Platform Indiana Limestone (example 1) Ancient Wonders (example 2) Mapping Spatial Data with ArcGIS - Mapping in GIS Basics - Archaeological Applications - Topographic Applications Mapping Spatial Data with ArcGIS What is GIS - Geographic Information System? A geographic information system (GIS) is a framework for gathering, managing, and analyzing data. Rooted in the science of geography, GIS integrates many types of data. It analyzes spatial location and organizes layers of information into visualizations using maps and 3D scenes. With this unique capability, GIS reveals deeper insights into spatial data, such as patterns, relationships, and situations - helping users make smarter decisions. - ESRI GIS dictionary. - ArcGIS by ESRI - industry standard, expensive, intuitive functionality, PC - Q-GIS - open source, industry standard, less than intuitive, Mac and PC - GRASS - developed by the US military, open source - AutoDESK - counterpart to AutoCAD for topography Types of Spatial Data in ArcGIS: Basics Every feature on the planet has its own unique latitude and longitude coordinates: Houses, trees, streets, archaeological finds, you! How do we collect this information? - Remote Sensing: Aerial photography, satellite imaging, LIDAR - On-site Observation: total station data, ground penetrating radar, GPS Types of Spatial Data in ArcGIS: Basics Raster vs. -

A New Geography of European Power?
A NEW GEOGRAPHY OF EUROPEAN POWER? EGMONT PAPER 42 A NEW GEOGRAPHY OF EUROPEAN POWER? James ROGERS January 2011 The Egmont Papers are published by Academia Press for Egmont – The Royal Institute for International Relations. Founded in 1947 by eminent Belgian political leaders, Egmont is an independent think-tank based in Brussels. Its interdisciplinary research is conducted in a spirit of total academic freedom. A platform of quality information, a forum for debate and analysis, a melting pot of ideas in the field of international politics, Egmont’s ambition – through its publications, seminars and recommendations – is to make a useful contribution to the decision- making process. *** President: Viscount Etienne DAVIGNON Director-General: Marc TRENTESEAU Series Editor: Prof. Dr. Sven BISCOP *** Egmont - The Royal Institute for International Relations Address Naamsestraat / Rue de Namur 69, 1000 Brussels, Belgium Phone 00-32-(0)2.223.41.14 Fax 00-32-(0)2.223.41.16 E-mail [email protected] Website: www.egmontinstitute.be © Academia Press Eekhout 2 9000 Gent Tel. 09/233 80 88 Fax 09/233 14 09 [email protected] www.academiapress.be J. Story-Scientia NV Wetenschappelijke Boekhandel Sint-Kwintensberg 87 B-9000 Gent Tel. 09/225 57 57 Fax 09/233 14 09 [email protected] www.story.be All authors write in a personal capacity. Lay-out: proxess.be ISBN 978 90 382 1714 7 D/2011/4804/19 U 1547 NUR1 754 All rights reserved. No part of this publication may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, electronic, mechanical, photocopying, recording or otherwise without the permission of the publishers. -

Geographical Influences on Climate Teacher Guide
Geographical Influences on Climate Teacher Guide Lesson Overview: Students will compare the climatograms for different locations around the United States to observe patterns in temperature and precipitation. They will describe geographical features near those locations, and compare graphs to find patterns in the effect of mountains, oceans, elevation, latitude, etc. on temperature and precipitation. Then, students will research temperature and precipitation patterns at various locations around the world using the MY NASA DATA Live Access Server and other sources, and use the information to create their own climatogram. Expected time to complete lesson: One 45 minute period to compare given climatograms, one to two 45 minute periods to research another location and create their own climatogram. To lessen the time needed, you can provide students data rather than having them find it themselves (to focus on graphing and analysis), or give them the template to create a climatogram (to focus on the analysis and description), or give them the assignment for homework. See GPM Geographical Influences on Climate – Climatogram Template and Data for these options. Learning Objectives: - Students will brainstorm geographic features, consider how they might affect temperature and precipitation, and discuss the difference between weather and climate. - Students will examine data about a location and calculate averages to compare with other locations to determine the effect of geographic features on temperature and precipitation. - Students will research the climate patterns of a location and create a climatogram and description of what factors affect the climate at that location. National Standards: ESS2.D: Weather and climate are influenced by interactions involving sunlight, the ocean, the atmosphere, ice, landforms, and living things. -

Chapter 13.2: Topographic Maps 1
Chapter 13.2: Topographic Maps 1 A map is a model or representation of objects and terrain in the actual environment. There are numerous types of maps. Some of the types of maps include mental, planimetric, topographic, and even treasure maps. The concept of mapping was introduced in the section using natural features. Maps are created for numerous purposes. A treasure map is used to find the buried treasure. Topographic maps were originally used for military purposes. Today, they have been used for planning and recreational purposes. Although other types of maps are mentioned, the primary focus of this section is on topographic maps. Types of Maps Mental Maps – The mind makes mental maps all the time. You drive to the grocery store. You turn right onto the boulevard. You identify a street sign, building or other landmark and know where this is where you turn. You have made a mental map. This was discussed under using natural features. Planimetric Maps – A planimetric map is a two dimensional representation of objects in the environment. Generally, planimetric maps do not include topographic representation. Road maps, Rand McNally ® and GoogleMaps ® (not GoogleEarth) are examples of planimetric maps. Topographic Maps – Topographic maps show elevation or three-dimensional topography two dimensionally. Topographic maps use contour lines to show elevation. A chart refers to a nautical chart. Nautical charts are topographic maps in reverse. Rather than giving elevation, they provide equal levels of water depth. Topographic Maps Topographic maps show elevation or three-dimensional topography two dimensionally. Topographic maps use contour lines to show elevation. -

Earth/Environmental (2014) Released Final Exam
Released Items Fall 2014 NC Final Exam Earth/Environmental Science RELEASED Public Schools of North Carolina Student Booklet State Board of Education Department of Public Instruction Raleigh, North Carolina 27699-6314 Copyrightã 2014 by the North Carolina Department of Public Instruction. All rights reserved. E ARTH/ENVIRONMENTAL S CIENCE — R ELEASED I TEMS 1 Cracks in rocks widen as water in them freezes and thaws. How does this affect the surface of the Earth? A It reduces the rates of soil formation. B It changes the chemical composition of the rocks. C It exposes rocks to increased rates of erosion and weathering. D It limits the exposure of rocks to acid precipitation. 2 How can urbanization affect a local area? A It can increase the number of invasive species in an area. B It can decrease the risk of water pollution in an area. C It can increase the risk of flooding in an area. D It can decrease the need for natural resources in an area. 3 Which is a farming technique that could improve the soil and the environment? A using fueled machines that will turn the soil continuously B creating undisturbed layers of mulch in the soil C placing inorganic chemical fertilizers in the soil D irrigating the RELEASEDsoil with salty water 1 Go to the next page. E ARTH/ENVIRONMENTAL S CIENCE — R ELEASED I TEMS 4 Subsurface ocean currents continually circulate from the warm waters near the equator to the colder waters in other parts of the world. What is the main cause of these currents? A differences in the topography along the ocean floor B differences -
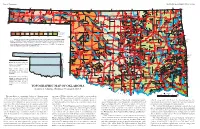
TOPOGRAPHIC MAP of OKLAHOMA Kenneth S
Page 2, Topographic EDUCATIONAL PUBLICATION 9: 2008 Contour lines (in feet) are generalized from U.S. Geological Survey topographic maps (scale, 1:250,000). Principal meridians and base lines (dotted black lines) are references for subdividing land into sections, townships, and ranges. Spot elevations ( feet) are given for select geographic features from detailed topographic maps (scale, 1:24,000). The geographic center of Oklahoma is just north of Oklahoma City. Dimensions of Oklahoma Distances: shown in miles (and kilometers), calculated by Myers and Vosburg (1964). Area: 69,919 square miles (181,090 square kilometers), or 44,748,000 acres (18,109,000 hectares). Geographic Center of Okla- homa: the point, just north of Oklahoma City, where you could “balance” the State, if it were completely flat (see topographic map). TOPOGRAPHIC MAP OF OKLAHOMA Kenneth S. Johnson, Oklahoma Geological Survey This map shows the topographic features of Oklahoma using tain ranges (Wichita, Arbuckle, and Ouachita) occur in southern contour lines, or lines of equal elevation above sea level. The high- Oklahoma, although mountainous and hilly areas exist in other parts est elevation (4,973 ft) in Oklahoma is on Black Mesa, in the north- of the State. The map on page 8 shows the geomorphic provinces The Ouachita (pronounced “Wa-she-tah”) Mountains in south- 2,568 ft, rising about 2,000 ft above the surrounding plains. The west corner of the Panhandle; the lowest elevation (287 ft) is where of Oklahoma and describes many of the geographic features men- eastern Oklahoma and western Arkansas is a curved belt of forested largest mountainous area in the region is the Sans Bois Mountains, Little River flows into Arkansas, near the southeast corner of the tioned below. -

Datums in Texas NGS: Welcome to Geodesy
Datums in Texas NGS: Welcome to Geodesy Geodesy is the science of measuring and monitoring the size and shape of the Earth and the location of points on its surface. NOAA's National Geodetic Survey (NGS) is responsible for the development and maintenance of a national geodetic data system that is used for navigation, communication systems, and mapping and charting. ln this subject, you will find three sections devoted to learning about geodesy: an online tutorial, an educational roadmap to resources, and formal lesson plans. The Geodesy Tutorial is an overview of the history, essential elements, and modern methods of geodesy. The tutorial is content rich and easy to understand. lt is made up of 10 chapters or pages (plus a reference page) that can be read in sequence by clicking on the arrows at the top or bottom of each chapter page. The tutorial includes many illustrations and interactive graphics to visually enhance the text. The Roadmap to Resources complements the information in the tutorial. The roadmap directs you to specific geodetic data offered by NOS and NOAA. The Lesson Plans integrate information presented in the tutorial with data offerings from the roadmap. These lesson plans have been developed for students in grades 9-12 and focus on the importance of geodesy and its practical application, including what a datum is, how a datum of reference points may be used to describe a location, and how geodesy is used to measure movement in the Earth's crust from seismic activity. Members of a 1922 geodetic suruey expedition. Until recent advances in satellite technology, namely the creation of the Global Positioning Sysfem (GPS), geodetic surveying was an arduous fask besf suited to individuals with strong constitutions, and a sense of adventure. -

What Is Geovisualization? to the Growing Field of Geovisualization
This issue of GeoMatters is devoted What is Geovisualization? to the growing field of geovisualization. Brian McGregor uses geovisualiztion to by Joni Storie produce animated maps showing settle- ment patterns of Hutterite colonies. Dr. Marc Vachon’s students use it to produce From a cartography perspective, dynamic presentation options to com- videos about urban visualization (City geovisualization represents a change in municate knowledge. For example, at- Hall and Assiniboine Park), while Dr. how knowledge is formed and repre- lases require extra planning compared Chris Storie shows geovisualiztion for sented. Traditional cartography is usu- to individual maps, structurally they retail mapping in Winnipeg. Also in this issue Honours students describe their ally seen a visualization (a.k.a. map) could include hundreds of maps, and thesis projects for the upcoming collo- that is presented after the conclusion all the maps relate to each other. Dr. quium next March, Adrienne Ducharme is reached to emphasize or compliment Danny Blair and Dr. Ian Mauro, in the tells us about her graduate research at the research conclusions. Geovisual- Department of Geography, provide an ELA, we have a report about Cultivate ization changes this format by incor- excellent example of this integration UWinnipeg and our alumni profile fea- porating spatial data into the analysis with the Prairie Climate Atlas (http:// tures Michelle Méthot (Smith). (O’Sullivan and Unwin, 2010). Spatial www.climateatlas.ca/). The combina- Please feel free to pass this newsletter data, statistics and analysis are used to tion of maps with multimedia provides to anyone with an interest in geography. answer questions which contribute to for better understanding as well as en- Individuals can also see GeoMatters at the Geography website, or keep up with the conclusion that is reached within riched and informative experiences of us on Facebook (Department of Geog- the research. -

Loading and Managing OS Mastermap Topography Layer
Loading and Managing OS MasterMap® Topography Layer An ESRI (UK) White Paper Confidentiality Statement This document contains information which is confidential to ESRI (UK) Limited. No part of this document should be reproduced or revealed to third parties without the express permission of ESRI (UK) Limited. © 2008 ESRI (UK) Ltd and its third party licensors. All rights reserved. ESRI (UK) Ltd Millennium House 65 Walton Street Aylesbury Buckinghamshire HP21 7QG Tel: +44 (0) 1296 745500 Fax: +44 (0) 1296 745544 Website: www.esriuk.com Released: 10/11/2008 Version: 5.3 Document History: Version Date Changes 1.0 31/08/2003 Document initial release. 2.0 16/12/2003 Document Updated/ Name Change. 3.0 23/11/2004 Document Reviewed/ Name Change. 4.0 05/06/05 OS MasterMap v6 4.1 11/08/05 Edits after Ordnance Survey review 5.0 19/05/2006 Technology updates 5.1 19/05/2006 Len Laver and Wai-Ming Lee review and edit of sections relevant to OS MasterMap-to-Go service 5.2 01/04/2008 Updated to new ESRI (UK) branding and style. 5.3 10/11/2008 Updates for new ‘minimise load on database’ option. © ESRI (UK) 2008 2 Contents Page 1. Introduction ........................................................................... 5 2. OS MasterMap® ...................................................................... 6 2.1. What is OS MasterMap? ............................................................... 6 2.2. Benefits of OS MasterMap ............................................................ 7 2.3. TOIDs and TOID-Associations ....................................................... 8 2.4. How OS MasterMap Topography Layer is Structured ........................ 9 2.5. OS MasterMap Topography Layer Data Schema ............................. 10 3. OS MasterMap Topography Layer Data Supply ................... 16 3.1. Initial OS MasterMap Topography Layer Data Supply ..................... -

The Topography of the Earth's Surface
CHAPTER 3 THE LAY OF THE LAND: THE TOPOGRAPHY OF THE EARTH’S SURFACE 1. LATITUDE AND LONGITUDE 1.1 You probably know already that the basic coordinate system that’s used to describe the position of a point on the Earth's surface is latitude and longitude. In this system (Figure 3-1), the Earth is imagined to be cut by a series of planes that pass through the north–south axis of rotation. The intersection of such a plane with the Earth’s surface is called a line (really a curve) of longitude, or a meridian. Longitude is measured in degrees, from zero to 360. One meridian (the one that passes through Greenwich, England) is called the prime meridian, and longitude is measured 180 degrees to the west of that and 180 degrees to the east of that. The opposite meridian, 180 degrees around the world from the prime meridian (and the intersection of the longitude plane with the other side of the world) lies about in the middle of the Pacific Ocean. 1.2 One consequence of this definition of longitude is that the spacing between two meridians gets smaller as you go north or south from the equator. Think about this the next time you fly west in a jetliner: You would have to move awfully fast to keep up with the sun, and land at the same time of day you took off, if you're flying along the equator, but if you're flying east to west in the far north or far south on the earth, you could easily arrive at your destination a lot earlier in the day than you took off! 1.3 The other element of the coordinate system is a series of latitude circles (Figure 3-1).