Publishing Jack Vance: the SAS® System As a Tool for Literary Analysis Koen Vyverman, SAS, Netherlands
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Ox 57207 : Los ANGLES'; 57, Chw
fRoGRSSg Report *3 WfiST^COfJ XV .P.O. ?>ox 57207 : LoS ANGLES'; 57, ChW. :: *• <. ’ i : WESTERCON XV — Commit tea: Albert J Lewis Chairman William B Ellern Treasurer John Trimble Secretary Forrest J Ackerman Pro Publicity Ron Ellik Fan Publicity Bjo Trimble Art & Display Bruce Henstell Info Booklet I.IEI1B3RSHIP in the 15th Annual West Coast Science Fantasy Conference is only $1.00 (make checks pay able to William B Ellernwhich entitles you to the progress reports, the program booklet, the information booklet, admission to all conference activities and a membership card. AD RATES for the Program Booklet are: Full 8jx5j" page $3.00 Half page 1.50 Quarter page 0.75 Ads requiring photos, or in any way complicated enough to require it, can be photo-stencilled at $1.50 per page, pro-rata. DEADLINES: Program Book — 1 June (Absolute Deadline — 15 June) (FR#h has been eliminated, due to missed deadlines) REIiEiiBER... The Time: June 30 - July 1, 1962 The Place: Hotel Alexandria 5th @ Spring Los Angeles 13, Calif Reserve a room now...and plan to join in the fun! We asked JACK VANCE to be Guest of Honor at WEST- ERCON XV, feeling that we would like to express our appreciation to him for such tales as The Dying Earth and Big Planet. His talent for creating unique worlds and cultures, and for endowing them ' with a poetic fantasy-yet-reality is a quality that is all too rare in modern science fantasy. When we asked lir Vance for some autobiograph ical information, he told us... "I have a compulsion against making these matters to explicit. -

Australian SF News 28
NUMBER 28 registered by AUSTRALIA post #vbg2791 95C Volume 4 Number 2 March 1982 COW & counts PUBLISH 3 H£W ttOVttS CORY § COLLINS have published three new novels in their VOID series. RYN by Jack Wodhams, LANCES OF NENGESDUL by Keith Taylor and SAPPHIRE IN THIS ISSUE: ROAD by Wynne Whiteford. The recommended retail price on each is $4.95 Distribution is again a dilemna for them and a^ter problems with some DITMAR AND NEBULA AWARD NOMINATIONS, FRANK HERBERT of the larger paperback distributors, it seems likely that these titles TO WRITE FIFTH DUNE BOOK, ROBERT SILVERBERG TO DO will be handled by ALLBOOKS. Carey Handfield has just opened an office in Melbourne for ALLBOOKS and will of course be handling all their THIRD MAJIPOOR BOOK, "FRIDAY" - A NEW ROBERT agencies along with NORSTRILIA PRESS publications. HEINLEIN NOVEL DUE OUT IN JUNE, AN APPRECIATION OF TSCHA1CON GOH JACK VANCE BY A.BERTRAM CHANDLER, GEORGE TURNER INTERVIEWED, Philip K. Dick Dies BUG JACK BARRON TO BE FILMED, PLUS MORE NEWS, REVIEWS, LISTS AND LETTERS. February 18th; he developed pneumonia and a collapsed lung, and had a second stroke on February 24th, which put him into a A. BERTRAM CHANDLER deep coma and he was placed on a respir COMPLETES NEW NOVEL ator. There was no brain activity and doctors finally turned off the life A.BERTRAM CHANDLER has completed his support system. alternative Australian history novel, titled KELLY COUNTRY. It is in the hands He had a tremendous influence on the sf of his agents and publishers. GRIMES field, with a cult following in and out of AND THE ODD GODS is a short sold to sf fandom, but with the making of the Cory and Collins and IASFM in the U.S.A. -

SHAMAR's WAR the STAR KING OH, to BE'a-Btubel JACK VANCE
FEBRUARY SHAMAR’S WAR THE STAR KING OH, TO BE'A-BtuBEL by by by KRIS NEVILLE JACK VANCE PHILIP K. DICK A New Complete Novelette 1964 GRANDMOTHER A New EARTH Complete by J. Novelette T. MdNTQSH DON’T CLIP THE COUPON- — if you want to keep your copy of Galaxy intact for permanent possession!* Why mutilate a good thing? But, by the same token... if you're devotee enough to want to keep your copies in mint condition, you ought to subscribe. You really ought to. For one thing, you get your copies earlier. For another, you’re sure you'll get them! Sometimes newsstands run out — the mail never does. (And you can just put your name and address on a plain sheet of paper and mail it to us, at the address below. We’ll know what you mean... provided you enclose your check!) In the past few years Galaxy has published the finest stories by the finest writers in the field - Bester, Heinlein, Pohl, Asimov, Sturgeon, Leiber and nearly everyone else. In the next few years it will go right on, with stories that are just as good ... or better. Don’t miss any issue of Galaxy. You can make sure you won’t. Just subcribe today. *(lf, on the other hand, your habit is to read them once and go on to something new - please - feel free to use the coupon! It’s for your convenience, not ours.) U GALAXY Publishing Corp., 421 Hudson Street, New York 14, N. Y. (50c additional per 6 issues Enter my subscription for the New Giant 196-page Galaxy foreign postage) (U. -

Abraham, 151 Abercrombie Station, 130 Achilles, 357 Aesop, 355
Index Abraham, 151 Chauser, 231, 233 366 Abercrombie Station, 130 Chesterton, G. K., 207 Faulkner, William, 15 Achilles, 357 Churchill, 55, 86 Flaubert, Gustave, 296 Aesop, 355 Cholwell’s Chickens, 130 Flesh Mask, The, 365-7, 379, 385 Alfred’s Ark, 123, 204, 242-4 Chrétien de Troyes, 248 & etc, Ford Madox Ford, 118 Allen, Woody; 96 250-52, 257 Fra Angelico, 380 Anaxagoras, 335, 342-53 Clarges, 16, 25, 30-32, 74, Frazetta, Frank, 209, 228 Aquinas, St. Thomas, 150 174, 177 Gainsborough, Thomas, 288 Arcimboldo, 380 Clarke, Arthur C., 17 Gesualdo, 380 Aristophanes, 398 Communism, 59, 82-6, 93, 143, Gift of Gab, The, 123 Aristotle, 280-1, 330, 336 & etc. 147, 249 319, 321, 329 & etc. Giotto, 228 Augmented Agent, The, 146 Coup de Grace, 16, 207 Gogol, Nicolai, 20, 195 Austen, Jane, 105 & etc, 191-2, Crusade to Maxus, 140 & etc. Gold and Iron, 20-1, 36, 81, 112, 241, 289, 380 Cugel (stories), 51, 106, 135-6, 118, 141, 143, 292, 383 Babeuf, Gracchus; 320 & etc. 155-6, 191, 200, 207, 231, Golden Girl, The, 20 Bad Ronald, 55, 221-2, 225, 248, 248-9, 251, 298, 340, Goncharov, 230 337, 340, 364- 6 355 & etc, 390, 392-3 Goya, Francesco, 23 Bain, Joe (stories), 205-6, 364, Dante, 15, 231, 233 Green Magic, 175-6, 387 378-9 Dark Ocean, The, 142, 201, 365 Grey, Zane, 46 Balzac, 52-54, 230, 379-83 Darwin, 68 & etc, 265, 287 Hardy, Thomas, 20 Beiderbecke, Bix, 136 Deadly Isles, The, 53, 365, 369 Hayden, 115 Benda, Julian, 80 Dickens, 112, 230, 289, 380 Heidegger, Martin, 214-9, 223, Big Planet, 12, 132, 231-32, Diderot, 16 227, 360-3, 367, 385 290, 383 Dodkin’s Job, 123, 153, 204, Hitchcock, Alfred, 289 Bird Island, 264, 370, 373 332 Hitler, 83-7, 201 Blake, William, 209 Dogtown Tourist Agency, The, Hogarth, 288 Blue World, The, 59, 189, 36, 38, 108, 332 Holbein, 289 228 & etc, 271 Domains of Koryphon, The, 15, Homer, 15, 216, 228, 355 & etc. -

Cosmopolis#54
COSMOPOLIS Number 54 October, 2004 Paul outlines his findings on The Star King. To his left: Alun Hughes, Tim Stretton, Thomas Rydbeck, Bob Lacovara, Steve Sherman and Rob Friefeld. ANOTHER STEP CLOSER—GM3.2 REPORT By Tim Stretton n late September, twelve volunteers gathered once again at Paul Rhoads’ home in France to consider the final eleven Ivolumes which make the up the second half of VIE Wave 2. This was Golden Master 3.2, and it boasted an all-star multi-national cast: Rob Friefeld, America Bob Luckin, England Marcel van Genderen, The Netherlands Paul Rhoads, America Alun Hughes, Wales Thomas Rydbeck, Sweden Andreas Irle, Germany Steve Sherman, America Chuck King, America Tim Stretton, England Bob Lacovara, America Koen Vyverman, Belgium In addition some of us brought along wives, girlfriends and children for the first time, so thanks are due to Sue, Danielle, Sandy, Pia, Marie-Therese and Kris for exerting a civilising influence and making the week even more enjoy- able than usual. Paul’s and Genevieve’s hospitality was, as ever, matchless. Amidst the conviviality, there were many important VIE achievements. The Blue World, The Magnificent Showboats, Cugel: the Skybreak Spatterlight and Rhialto the Marvellous were all signed off as ‘blues-ready’, meaning that only the final stage of the review process, GM4.2, remains before the books are ready for printing. The World Thinker and Son of the Tree await only verification of the credits, while Space Opera needs only credit verification and the incorporation of the findings from Post-Proofing. The Killing Machine is now ready subject to the incorporation of a few minor changes. -

Cosmopolis#38
COSMOPOLIS Number 38 c3g4c May, 2003 The Wave I Deluxe Edition of The Complete Works of Jack Vance. Photo by Koen Vyverman. Announcement Contents A number of VIE volumes were discovered with some pages out of sequence. In particular, there have been two Vance on Vance . 1 reports of volume 6 having an error around pages 6-7. by Richard Chandler Please check your set to see that this error is not Jack’s published comments on his own work manifested. Further, you should try to make a thorough Work Tsar Status Report . 4 inspection of all volumes to see if they contain similar by Joel Riedesel errors. We have made provisions to replace flawed copies, An Account From Milan . 4 at project expense; but naturally we would like these to by John Edwards be reported as soon as possible. Please e-mail Suan, Bob, Italian cathedrals and food, and packing or Paul if you discover any errors. 38’s Ramblings . 5 Subscriptions to the VIE are still available; if you by Paul Rhoads haven’t purchased your set, take the plunge! Palace of Love, 3-Legged Joe, Unspeakable McInch, Man in the Cage, Maske:Thaery, Textport, cic w cic Notes from Europe, Finkielkraut and Cadwal, Thomas Sowell’s Cosmic Justice Sharing the Kudos . 21 Vance on Vance by Suan Yong by Richard Chandler Letters of appreciation for Wave 1 About the CLS . 24 Jack Vance has been famously reluctant to comment on by Till Noever his (or anyone else’s) writing, but on several occasions Letters to the Editor . -
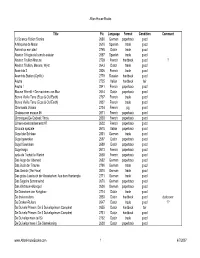
By Title.Pdf
Afton House Books Title Pic Language Format Condition Comment 13 Science Fiction Stories 2680 German paperback good A Maquina de Matar 2610 Spanish trade good Aanval op een stad 2768 Dutch trade good Alastor: Trilogia del cumulo estelar 2697 Spanish trade good Alastor: Trullion Marune 2729 French hardback good ? Alastor: Trullion, Marune, Wyst 2643 Dutch trade good Araminta 2 2806 French trade good Araminta Station (Cyrillic) 2779 Russian hardback good Asutra 2725 Italian hardback fair Asutra ! 2841 French paperback good Blauwe Wereld + De machines van Maz 2644 Dutch paperback good Bonne Vieille Terre (Ecce & Old Earth) 2757 French trade good Bonne Vieille Terre (Ecce & Old Earth) 2807 French trade good Charmants Voisins 2734 French pg good Chateaux en espace #6 2611 French paperback good Chroniques De Cadwal: Throy 2603 French paperback good Crimes et enchantements #7 2602 French paperback good Crociata spaziale 2675 Italian paperback good Cugel der Schlaue 2801 German trade good Cugel gewroken 2597 Dutch paperback good Cugel Gewroken 2699 Dutch paperback good Cugel saga 2673 French paperback good cycle de Tschai: le Wankh 2658 French paperback good Das Auge der Uberwelt 2682 German paperback good Das Buch der Traume 2790 German trade good Das Gesich (The Face) 2810 German trade good Das grobe Lesebuch der klassischen: Aus dem Hantemple 2771 German trade good Das Segelim Sonnenwind 2670 German paperback good Das Weltraum-Monopol 2600 German paperback good De Domeinen van Koryphon 2714 Dutch trade good De drakenruiters 2853 Dutch hardback -

GURPS Third Edition Jack Vance's Planet of Adventure by James L
GURPS Third Edition Jack Vance's Planet of Adventure By James L. Cambias Introduction Far off in space floats a planet with ale-colored skies… Jack Vance took us there. Vance introduced delighted Earthlings to the people, creatures, and customs of Tschai. It's a world of danger, where humans are ruled and exploited by strange alien races. With Vance's hero Adam Reith as your tour guide, learn the awful secrets of the Chasch, foil the treacherous agents of the Wanek, escape the hunters of the Dirdir, venture into the underworld labyrinth of the Pnume, and meet vivid characters like Traz Onmale, Zap 210, and the appalling Aila Woudiver. GURPS Planet of Adventure lets you plan your own excursions on Tschai. Retrace Adam Reith's footsteps as intrepid scouts for Earth, or play natives of Tschai just trying to survive and make a few sequins. Tschai's depth and variety cry out for a long visit, with time to admire the scenery and get a feel for the place. A talented author like Vance can imply a tremendous amount in just a few sentences. The game designer has to turn those references into rules and complete explanations. He can invent some things, but not too much… the feel of the original novels must shine through. If any errors remain, they are entirely the designer's fault. Some of Tschai's mysteries have been left unsolved. What's the connection among the Pnume, the Phung, and the night-hounds? What are the goals of the Wanek? What will Earth do when it learns about Tschai? Those are for individual GMs to decide. -

Nebula Awards® Weekend 2008
Nebula Awards® Weekend 2008 April 25–27, 2008 Austin, Texas SCIENCE FICTION & FANTASY WRITERS OF AMERICA, INC. Nebula Awards® Weekend 2008 Gr and Master Michael Moorcock Author Emeritus Ardath Mayhar Toastmaster Joe R. Lansdale April 25–27, 2008 Austin, Texas Nebula Awards® WEEKEND PROGR AM Thursday, April 24th 6:00 pm – 9:00 pm Registration (Balcony Alcove) Free books (Second floor lobby, near registration) (members only) 6:00 pm – 12:00 am Hospitality (Chambers) Friday, April 25th 8:00 am – 9:00 pm Registration (Balcony Alcove) 8:00 am – 1:00 am Hospitality (Chambers) Free books (Second floor lobby, near registration) (members only) 3:00 pm Panel (Capitol Ballroom) “Publishing Contracts”, Sean P. Fodera 4:30 pm – 8:00 pm Cash Bar (Longhorn) 5:00 pm – 5:30 pm Nominee Ceremony & Photo Op (Longhorn) 5:30 pm – 8:00 pm Mass Autographing (Longhorn) Sponsored by BookPeople Saturday, April 26th 8:00 am – 7:00 pm Registration (Balcony Alcove) 8:00 am – 1:00 am Hospitality (Chambers) Free books (Second floor lobby, near registration) (members only) 10:00 am Panel (Capitol Ballroom) “GriefCom”, Paul Melko 1:00 pm SFWA Annual Business Meeting (Capitol Ballroom) 3:00 pm Panel (Capitol Ballroom) “Kindle”, Dan B. Slater, Amazon.com 6:30 pm Cash Bar (outside Capitol Ballroom) 7:00 pm – 10:00 pm Nebula Awards Banquet & Ceremony (Capitol Ballroom) Sunday, April 27th 9:00 am – ???? Hospitality (Chambers) Nebula Awards® WEEKEND Gr and Master Michael Moorcock amed one of the 50 greatest postwar British writers by The Times of NLondon, Michael Moorcock is best-known for his stories featuring the albino swordsman Elric of Melnibone. -

Cosmopolis#27
COSMOPOLIS Number 27 June, 2002 Letters to the Editor . 25 Contents Chuck King, Karl T. Radtke, Bob Lacovara, Alain The Logan Square Book Club vs. Schremmer, John Rappel, Till Noever, Derek W. Benson Jack Vance. 1 Closing Words . 30 by Chuck King Presenting Vance to new readers VIE Contacts . 31 The Fine Print . 31 Work Tsar Status Report . 3 by Joel Riedesel Wave 1 texts soon finished d 38’s Crucible. 4 by Paul Rhoads Paul Allen and libraries, flexible covers, two Jacks, The Logan Square Book Di£ng procedure, and more Club vs. Jack Vance by Chuck King ‘Is is’ and Jack Vance’s Colons . 19 By George Rhoads Repair your sentence with the colon One of the stated goals of the VIE is to raise awareness of Jack Vance as a serious author, worthy of respect out- side the narrow genres in which his work has heretofore An Antidote to the Modern Educational been categorized. I have always felt that Vance is a styl- Malaise . 20 ist on a level with the greatest names in literature, and by William Tahil so when the opportunity came to do my part to further Turn o¥ MTV, read Vance instead our noble goal, I leapt at the chance. I am a member of a book club with a number of other The CLS . 21 people, none of whom are particular fans of science by Till Noever fiction or fantasy. They are regular folks, albeit all CLS 13 coming to a computer near you highly literate and avid readers. Members range in age from their 30s to their 60s, weighted a bit towards the You Have Done It!. -

Cosmopolis#57
COSMOPOLIS Number 57 January, 2005 And So It Ends SUBSCRIPTION know, we’re not done yet, but for someone who’s been I with the VIE for as long as I have (Volunteer # 76) the time remaining is vanishingly small compared to the eons DEADLINE is that have gone before. I’ve just received my last assign- JANUARY 25th! ment, and it’s like... well, the ‘last’. You know, like when you leave some place—house, employment, country—and lvl you’ll suddenly find yourself doing ‘last’ things. The deadline to order the complete set of ‘Last’ things that you’re aware of. ‘Last’ things that mat- VIE books is the 25th. ter; punctuation marks in the course of your life that add meta-meaning and frame its content. Punctuation we notice, You cannot procrastinate any longer! as if we were proofing the copy and wondering if that Order on the VIE website. comma really belongs here, or if it’s just a stylistic quirk, or if that colon should really be a full-stop. In contrast to this consider those sentence marks we don’t notice, because they, like someone wrote about Jack’s style, are Contents invisible, and by their implicitness serve to make limpid that which otherwise would be hidden. And So It Ends . 1 For everything in life, every action we take, is a ‘last’, at the same time as it is a first; only our urge to generalize, Till Noever simplify and abstract makes us believe otherwise. And, Work Tsar Report . .2 let’s face it, everything could just be ‘last’—because of our ignorance about what will be tomorrow, or maybe in the Joel Riedesel next few minutes, that will retroactively turn any given action into a ‘last’, by anybody’s definition. -

Fifty Works of Fiction Libertarians Should Read
Liberty, Art, & Culture Vol. 30, No. 3 Spring 2012 Fifty works of fiction libertarians should read By Anders Monsen Everybody compiles lists. These usually are of the “top 10” Poul Anderson — The Star Fox (1965) kind. I started compiling a personal list of individualist titles in An oft-forgot book by the prolific and libertarian-minded the early 1990s. When author China Miéville published one Poul Anderson, a recipient of multiple awards from the Lib- entitled “Fifty Fantasy & Science Fiction Works That Social- ertarian Futurist Society. This space adventure deals with war ists Should Read” in 2001, I started the following list along and appeasement. the same lines, but a different focus. Miéville and I have in common some titles and authors, but our reasons for picking Margaret Atwood—The Handmaid’s Tale (1986) these books probably differ greatly. A dystopian tale of women being oppressed by men, while Some rules guiding me while compiling this list included: being aided by other women. This book is similar to Sinclair 1) no multiple books by the same writer; 2) the winners of the Lewis’s It Can’t Happen Here or Robert Heinlein’s story “If This Prometheus Award do not automatically qualify; and, 3) there Goes On—,” about the rise of a religious-type theocracy in is no limit in terms of publication date. Not all of the listed America. works are true sf. The first qualification was the hardest, and I worked around this by mentioning other notable books in the Alfred Bester—The Stars My Destination (1956) brief notes.