The R Journal, June 2012
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Advanced R Second Edition Chapman & Hall/CRC the R Series Series Editors John M
Advanced R Second Edition Chapman & Hall/CRC The R Series Series Editors John M. Chambers, Department of Statistics, Stanford University, California, USA Torsten Hothorn, Division of Biostatistics, University of Zurich, Switzerland Duncan Temple Lang, Department of Statistics, University of California, Davis, USA Hadley Wickham, RStudio, Boston, Massachusetts, USA Recently Published Titles Testing R Code Richard Cotton R Primer, Second Edition Claus Thorn Ekstrøm Flexible Regression and Smoothing: Using GAMLSS in R Mikis D. Stasinopoulos, Robert A. Rigby, Gillian Z. Heller, Vlasios Voudouris, and Fernanda De Bastiani The Essentials of Data Science: Knowledge Discovery Using R Graham J. Williams blogdown: Creating Websites with R Markdown Yihui Xie, Alison Presmanes Hill, Amber Thomas Handbook of Educational Measurement and Psychometrics Using R Christopher D. Desjardins, Okan Bulut Displaying Time Series, Spatial, and Space-Time Data with R, Second Edition Oscar Perpinan Lamigueiro Reproducible Finance with R Jonathan K. Regenstein, Jr. R Markdown The Definitive Guide Yihui Xie, J.J. Allaire, Garrett Grolemund Practical R for Mass Communication and Journalism Sharon Machlis Analyzing Baseball Data with R, Second Edition Max Marchi, Jim Albert, Benjamin S. Baumer Spatio-Temporal Statistics with R Christopher K. Wikle, Andrew Zammit-Mangion, and Noel Cressie Statistical Computing with R, Second Edition Maria L. Rizzo Geocomputation with R Robin Lovelace, Jakub Nowosad, Jannes Münchow Dose-Response Analysis with R Christian Ritz, Signe M. Jensen, Daniel Gerhard, Jens C. Streibig Advanced R, Second Edition Hadley Wickham For more information about this series, please visit: https://www.crcpress.com/go/ the-r-series Advanced R Second Edition Hadley Wickham CRC Press Taylor & Francis Group 6000 Broken Sound Parkway NW, Suite 300 Boca Raton, FL 33487-2742 © 2019 by Taylor & Francis Group, LLC CRC Press is an imprint of Taylor & Francis Group, an Informa business No claim to original U.S. -

Sweave User Manual
Sweave User Manual Friedrich Leisch and R-core June 30, 2017 1 Introduction Sweave provides a flexible framework for mixing text and R code for automatic document generation. A single source file contains both documentation text and R code, which are then woven into a final document containing • the documentation text together with • the R code and/or • the output of the code (text, graphs) This allows the re-generation of a report if the input data change and documents the code to reproduce the analysis in the same file that contains the report. The R code of the complete 1 analysis is embedded into a LATEX document using the noweb syntax (Ramsey, 1998) which is usually used for literate programming Knuth(1984). Hence, the full power of LATEX (for high- quality typesetting) and R (for data analysis) can be used simultaneously. See Leisch(2002) and references therein for more general thoughts on dynamic report generation and pointers to other systems. Sweave uses a modular concept using different drivers for the actual translations. Obviously different drivers are needed for different text markup languages (LATEX, HTML, . ). Several packages on CRAN provide support for other word processing systems (see Appendix A). 2 Noweb files noweb (Ramsey, 1998) is a simple literate-programming tool which allows combining program source code and the corresponding documentation into a single file. A noweb file is a simple text file which consists of a sequence of code and documentation segments, called chunks: Documentation chunks start with a line that has an at sign (@) as first character, followed by a space or newline character. -
![R Generation [1] 25](https://docslib.b-cdn.net/cover/5865/r-generation-1-25-805865.webp)
R Generation [1] 25
IN DETAIL > y <- 25 > y R generation [1] 25 14 SIGNIFICANCE August 2018 The story of a statistical programming they shared an interest in what Ihaka calls “playing academic fun language that became a subcultural and games” with statistical computing languages. phenomenon. By Nick Thieme Each had questions about programming languages they wanted to answer. In particular, both Ihaka and Gentleman shared a common knowledge of the language called eyond the age of 5, very few people would profess “Scheme”, and both found the language useful in a variety to have a favourite letter. But if you have ever been of ways. Scheme, however, was unwieldy to type and lacked to a statistics or data science conference, you may desired functionality. Again, convenience brought good have seen more than a few grown adults wearing fortune. Each was familiar with another language, called “S”, Bbadges or stickers with the phrase “I love R!”. and S provided the kind of syntax they wanted. With no blend To these proud badge-wearers, R is much more than the of the two languages commercially available, Gentleman eighteenth letter of the modern English alphabet. The R suggested building something themselves. they love is a programming language that provides a robust Around that time, the University of Auckland needed environment for tabulating, analysing and visualising data, one a programming language to use in its undergraduate statistics powered by a community of millions of users collaborating courses as the school’s current tool had reached the end of its in ways large and small to make statistical computing more useful life. -

Data Analysis in R
Data Analysis in R Course at a Glance This course will provide an introduction to reproducible data analysis with R (see Syllabus). Instructor Gabriel Baud-Bovy ([email protected] ) Credits: 5 Synopsis This course aims at giving to the student a methodology to analyze experimental results, from how to organize data to the writing of a report. It includes: an introduction to R an introduction to reproducible research with R examples of statistical analysis with R During this course, the student will have to analyze his own data and is expected to read before each course the material that will be made available on this page. The final grade will consist in the evaluation of a report demonstrating familiarity with the concepts and methods presented in the course. As an editor, the instructor will use Notepad++ (together with NppToR) on a Windows Machines but the student might use other ones (e.g., R studio, EMACS+ESS, Lyx, TexWork). The course will use Mardown as typesetting language. For those desirous to work with Latex and/or generate pdf, you will need to install also MikeTex. Syllabus Total of 15 hours Class 1: Case study, Reproducible research Class 2: R fundamental Class 3: Exploratory data analysis and graphical methods in R Class 4: Basic statistics Class 5: To be determined There will be a final examination decided by the instructor. Prerequisites The course assumes some familiarity with programming concepts and data structures (MATLAB, C/C++, Java or any other programming language). Contact the instructor if you have never programmed anything. -

A History of R (In 15 Minutes… and Mostly in Pictures)
A history of R (in 15 minutes… and mostly in pictures) JULY 23, 2020 Andrew Zief!ler Lunch & Learn Department of Educational Psychology RMCC University of Minnesota LATIS Who am I and Some Caveats Andy Zie!ler • I teach statistics courses in the Department of Educational Psychology • I have been using R since 2005, when I couldn’t put Me (on the EPSY faculty board) SAS on my computer (it didn’t run natively on a Me Mac), and even if I could have gotten it to run, I (everywhere else) couldn’t afford it. Some caveats • Although I was alive during much of the era I will be talking about, I was not working as a statistician at that time (not even as an elementary student for some of it). • My knowledge is second-hand, from other people and sources. Statistical Computing in the 1970s Bell Labs In 1976, scientists from the Statistics Research Group were actively discussing how to design a language for statistical computing that allowed interactive access to routines in their FORTRAN library. John Chambers John Tukey Home to Statistics Research Group Rick Becker Jean Mc Rae Judy Schilling Doug Dunn Introducing…`S` An Interactive Language for Data Analysis and Graphics Chambers sketch of the interface made on May 5, 1976. The GE-635, a 36-bit system that ran at a 0.5MIPS, starting at $2M in 1964 dollars or leasing at $45K/month. ’S’ was introduced to Bell Labs in November, but at the time it did not actually have a name. The Impact of UNIX on ’S' Tom London Ken Thompson and Dennis Ritchie, creators of John Reiser the UNIX operating system at a PDP-11. -

ESS — Emacs Speaks Statistics
ESS — Emacs Speaks Statistics ESS version 5.14 The ESS Developers (A.J. Rossini, R.M. Heiberger, K. Hornik, M. Maechler, R.A. Sparapani, S.J. Eglen, S.P. Luque and H. Redestig) Current Documentation by The ESS Developers Copyright c 2002–2010 The ESS Developers Copyright c 1996–2001 A.J. Rossini Original Documentation by David M. Smith Copyright c 1992–1995 David M. Smith Permission is granted to make and distribute verbatim copies of this manual provided the copyright notice and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this manual under the conditions for verbatim copying, provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Chapter 1: Introduction to ESS 1 1 Introduction to ESS The S family (S, Splus and R) and SAS statistical analysis packages provide sophisticated statistical and graphical routines for manipulating data. Emacs Speaks Statistics (ESS) is based on the merger of two pre-cursors, S-mode and SAS-mode, which provided support for the S family and SAS respectively. Later on, Stata-mode was also incorporated. ESS provides a common, generic, and useful interface, through emacs, to many statistical packages. It currently supports the S family, SAS, BUGS/JAGS, Stata and XLisp-Stat with the level of support roughly in that order. A bit of notation before we begin. emacs refers to both GNU Emacs by the Free Software Foundation, as well as XEmacs by the XEmacs Project. The emacs major mode ESS[language], where language can take values such as S, SAS, or XLS. -

August 12-14, Dortmund, Germany
AASC Austrian Association for Statistical Computing 2008 Program August 12-14, Dortmund, Germany useR! 2008, Dortmund, Germany 1 Contents Greetings and Miscellaneous 2 Maps 5 Social Program 8 Program 9 Tutorials 9 Schedule 10 List of Talks 14 2 useR! 2008, Dortmund, Germany Dear useRs, the following pages provide you with some useful information about useR! 2008, the R user con- ference, taking place at the Fakultät Statistik, Technische Universität Dortmund, Germany from 2008-08-12 to 2008-08-14. Pre-conference tutorials will take place on August 11. The confer- ence is organized by the Fakultät Statistik, Technische Universität Dortmund and the Austrian Association for Statistical Computing (AASC). Apart from challenging and likewise exciting scientific contributions we hope to offer you an attractive conference site and a pleasant social program. With best regards from the organizing team: Uwe Ligges (conference), Achim Zeileis (program), Claus Weihs, Gerd Kopp (local organiza- tion), Friedrich Leisch, and Torsten Hothorn Address / Contact Address: Uwe Ligges Fakultät Statistik Technische Universität Dortmund 44221 Dortmund Germany Phone: +49 231 755 4353 Fax: +49 231 755 4387 e-mail: [email protected] URL: http://www.R-Project.org/useR-2008/ Program Committee Micah Altman, Roger Bivand, Peter Dalgaard, Jan de Leeuw, Ramón Díaz-Uriarte, Spencer Graves, Leonhard Held, Torsten Hothorn, François Husson, Christian Kleiber, Friedrich Leisch, Andy Liaw, Martin Mächler, Kate Mullen, Ei-ji Nakama, Thomas Petzoldt, Martin Theus, and Heather Turner Conference Location Technische Universität Dortmund Campus Nord Mathematikgebäude / Audimax Vogelpothsweg 87 44227 Dortmund Conference Office Opening hours: Monday, August 11: 08:30–19:30 Tuesday, August 12: 08:30–18:30 Wednesday, August 13: 08:30–18:30 Thursday, August 14: 08:30–15:30 useR! 2008, Dortmund, Germany 3 Public Transport The conference site at the university campus and the city hall are best to be reached by public transport. -

Species' Traits and Phylogenetic
Northern Michigan University NMU Commons All NMU Master's Theses Student Works 8-2018 CLIMATE DRIVEN RANGE SHIFTS OF NORTH AMERICAN SMALL MAMMALS: SPECIES’ TRAITS AND PHYLOGENETIC INFLUENCES Katie Nehiba [email protected] Follow this and additional works at: https://commons.nmu.edu/theses Part of the Ecology and Evolutionary Biology Commons Recommended Citation Nehiba, Katie, "CLIMATE DRIVEN RANGE SHIFTS OF NORTH AMERICAN SMALL MAMMALS: SPECIES’ TRAITS AND PHYLOGENETIC INFLUENCES" (2018). All NMU Master's Theses. 557. https://commons.nmu.edu/theses/557 This Open Access is brought to you for free and open access by the Student Works at NMU Commons. It has been accepted for inclusion in All NMU Master's Theses by an authorized administrator of NMU Commons. For more information, please contact [email protected],[email protected]. CLIMATE DRIVEN RANGE SHIFTS OF NORTH AMERICAN SMALL MAMMALS: SPECIES’ TRAITS AND PHYLOGENETIC INFLUENCES By Katie R. Nehiba THESIS Submitted to Northern Michigan University In partial fulfillment of the requirements For the degree of MASTER OF SCIENCE Office of Graduate Education and Research July 2018 ABSTRACT By Katie R. Nehiba Current anthropogenically-driven climate change is accelerating at an unprecedented rate. In response, species’ ranges may shift, tracking optimal climatic conditions. Species-specific differences may produce predictable differences in the extent of range shifts. I evaluated if patterns of predicted responses to climate change were strongly related to species’ taxonomic identities and/or ecological characteristics of species’ niches, elevation and precipitation. I evaluated differences in predicted range shifts in well-sampled small mammals that are restricted to North America: kangaroo rats, voles, chipmunks, and ground squirrels. -

Reproducible Research.. Using Sweave, Knitr and Pandoc
Reproducible Research.. Using Sweave, Knitr and Pandoc Aedín Culhane [email protected] Nov 20th 2012 My R Course Website http://bcb.dfci.harvard.edu/~aedin/ My HSPH homepage http://www.hsph.harvard.edu/research/aedin-culhane/ When issues of reproducibility arise • ``Remember that microarray analysis you did six months ago? We ran a few more arrays. Can you add them to the project and repeat the same analysis?'' • ``The statistical analyst who looked at the data I generated previously is no longer available. Can you get someone else to analyze my new data set using the same methods (and thus producing a report I can expect to understand)?'' • ``Please write/edit the methods sections for the abstract/paper/grant proposal I am submitting based on the analysis you did several months ago.'' From Keith Baggerly • Selected articles published in Nature Genetics between January 2005 and December 2006 that had used profiling with microarrays • Of the 56 items retrieved electronically, 20 articles were considered potentially eligible for the project • The four teams were from – University of Alabama at Birmingham (UAB) – Stanford/Dana-Farber (SD) – London (L) and Ioannina/Trento (IT) • Each team was comprised of 3-6 scientists who worked together to evaluate each article. Results • Result could be reproduced n=2 • Reproduced with discrepancy n=6 • Could not be reproduced n=10 – No data n=4 (no data n=2, subset n=1, no reporter data n=1) – Confusion over matching of data to analysis (n=2) – Specialized software required and not available (n=1)m – Raw data available but could not be processed n=2 Reproducibility of Analysis Ioannidis JP, Allison DB, Ball CA, Coulibaly I, Cui X, Culhane AC, et al, (2009) Repeatability of published microarray gene expression Analyses. -

Language-Agnostic Data Analysis Workflows and Reproducible Research
Language-agnostic data analysis workflows and reproducible research Andrew John Lowe 28 April 2017 Abstract This is the abstract for a document that briefly describes methods for interacting with different programming languages within the same data analysis workflow. 0.1 Overview • This talk: language-agnostic (or polyglot) analysis workflows • I’ll show how it is possible to work in multiple languages and switch between them without leaving the workflow you started • Additionally, I’ll demonstrate how an entire workflow can be encapsulated in a markdown file that is rendered to a publishable paper with cross-references and a bibliography (and with raw a LATEX file produced as a by-product) in a simple process, making the whole analysis workflow reproducible 0.2 Which tool/language is best? • TMVA, scikit-learn, h2o, caret, mlr, WEKA, Shogun, . • C++, Python, R, Java, MATLAB/Octave, Julia, . • Many languages, environments and tools • People may have strong opinions • A false polychotomy? • Be a polyglot! 0.3 Approaches • Save-and-load • Language-specific bindings • Notebook • knitr 1 Save-and-load approach 1.1 Flat files • Language agnostic • Formats like text, CSV, and JSON are well-supported • Breaks workflow • Data types may not be preserved (e.g., datetime, NULL) • New binary format Feather solves this 1 1.2 Feather Feather: A fast on-disk format for data frames for R and Python, powered by Apache Arrow, developed by Wes McKinney and Hadley Wickham # In R: library(feather) path <- "my_data.feather" write_feather(df, path) # In Python: import feather -
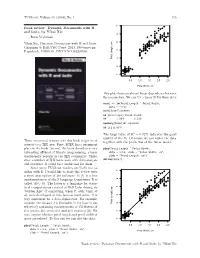
Dynamic Documents with R and Knitr, by Yihui Xie 116 Tugboat, Volume 35 (2014), No
TUGboat, Volume 35 (2014), No. 1 115 ● ● ● Book review: Dynamic Documents with R ● ● ● and knitr, by Yihui Xie ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Boris Veytsman ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● Yihui Xie, Dynamic Documents with R and knitr. ● ● ● ● ● ● ● ● ● ● ● ● ● ● Chapman & Hall/CRC Press, 2013, 190+xxvi pp. ● ● ● ● ● ● ● ● ● US$ ISBN ● Paperback, 59.95. 978-1482203530. ● ● ● ● Petal Length, cm Petal ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● ● 1 2 3 4 5 6 7 0.5 1.0 1.5 2.0 2.5 Petal Width, cm This plot shows an almost linear dependence between the parameters. We can try a linear fit for these data: model <- lm(Petal.Length ˜ Petal.Width, data = iris) model$coefficients ## (Intercept) Petal.Width ## 1.084 2.230 summary(model)$r.squared ## [1] 0.9271 The large value of R2 = 0.9271 indicates the good quality of the fit. Of course we can replot the data There are several reasons why this book might be of together with the prediction of the linear model: interest to a TEX user. First, LATEX has a prominent place in the book. Second, the book describes a very plot(Petal.Length ˜ Petal.Width, interesting offshoot of literate programming, a topic data = iris, xlab = "Petal Width, cm", traditionally popular in the TEX community. Third, ylab = "Petal Length, cm") abline(model) since a number of TEX users work with data analysis and statistics, R could be a useful tool for them. Since some TUGboat readers are likely not fa- ● ● ● miliar with R, I would like to start this review with ● ● a short description of the software. R [1] is a free ● ● ● ● ● ● ● ● ● ● ● implementation of the S language (sometimes R is ● ● ● ● ● ● ● ● ● ● ● ● ● ● called GNU S). -

LYX and Knitr
knitr.1 LYX and knitr The knitr package allows one to embed R code within LYX and LATEX documents. When a document is compiled into a PDF, LYX/LATEX connects to R to run the R code and the code/output is automatically put into the PDF. In addition to this being a convenient way to use both LYX/LATEX with R, it also provides an important component to the reproducibility of research (RR). For example, one can include the code for a data analysis de- scribed in a paper. This ensures that there would be no “copying and pasting errors” and also provide readers of the paper an im- mediate way to reproduce the research. RR continues to become more important and fortunately more tools are being developed to make it possible. Below are some discussions on the topic: • AMSTAT News column on RR at http://magazine. amstat.org/blog/2011/01/01/scipolicyjan11. • CRAN task view for RR and R at http://cran.r-project. org/web/views/ReproducibleResearch.html. • Yihui Xie: Author of knitr – First and second editions of his Dynamic Documents with R and knitr book. Note that this book was typed in LYX. – Website for knitr at http://yihui.name/knitr The Sweave environment is another way to include R code inside of LYX/LATEX. This was developed prior to knitr, but it is more difficult to use. The purpose of this section is to examine the main compo- nents of knitr so that you will be able to complete the rest of the semester using LYX and knitr together for all assign- ments in our course! Also, a very important purpose is to give you the tools needed to complete all assignments in other R- based courses by using knitr and LYX together! The files used knitr.2 here are intro_example_cereal.lyx, intro_example_cereal.pdf, cereal.csv, ExternalCode.R, FirstBeamer-knitr.zip, JSM2015.zip, and RMarkdown.zip.