24 X 7 Borland Starteam
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Code Review Is an Architectural Necessity
Code review is an architectural necessity Colin Dean @colindean 1 @ColinDean Software Engineer Organizer, Abstractions.io Wearer of many hats 2 My words are my own and not my employer(s), past or present. Please save questions until the end of the presentation. 3 Agenda • Quick anecdote • What is code review? • What problems does code review solve? • Quality attributes code review ensures • Tips for code reviews • Limitations 4 5 Agenda • Quick anecdote • What is code review? • What problems do code review solve? • Quality attributes code review ensures • Tips for code reviews • Limitations 6 What is code review? 7 Code review is the process by which those who maintain a software codebase evaluate a proposed change to that codebase, regardless of the source of the proposed change. 8 Code review is systematic examination of computer source code. Code Review, Wikipedia 9 Peer Review 10 Code Review 11 Code Review Vocabulary • Change - an individual unit of work altering what exists • Submission - a collection of changes • Submitter - the person proposing the submission • Reviewer - the people evaluating the submission • Annotation - remarks or ratings bestowed upon the submission 12 The submitter proposes changes in a submission, which is evaluated by a reviewer, who annotates or accepts it. 13 Most formal Least formal Team Pair Peer Inspection Walkthrough Ad-hoc review review programming deskcheck, passaround Wiegers’ peer review formality spectrum 14 Most formal Least formal Team Pair Peer Inspection Walkthrough Ad-hoc review review programming deskcheck, passaround Wiegers’ peer review formality spectrum 15 16 Agenda • Quick anecdote • What is code review? • What problems does code review solve? • Quality attributes code review ensures • Tips for code reviews • Limitations 17 Aside from the primary goal of reducing defects, Code review solves two major problems. -

Visual Build Help
Visual Build Professional User's Manual Copyright © 1999-2021 Kinook Software, Inc. Contents I Table of Contents Part I Introduction 1 1 Overview ................................................................................................................................... 1 2 Why Visual................................................................................................................................... Build? 1 3 New Features................................................................................................................................... 2 Version 4 .......................................................................................................................................................... 2 Version 5 .......................................................................................................................................................... 3 Version 6 .......................................................................................................................................................... 4 Version 7 .......................................................................................................................................................... 7 Version 8 .......................................................................................................................................................... 9 Version 9 ......................................................................................................................................................... -

Versie Beheer Systemen (VCS) 1
Versie beheer systemen (VCS) 1 Computerclub Volwassenen, Jeugd en Informatica vzw www.vji.be Versie beheer systemen (VCS) Inleiding ..................................................................................................................................... 2 Beheer repository en client programma’s .............................................................................. 2 In- en uitchecken, merging, labeling, branching.................................................................... 2 Software ..................................................................................................................................... 3 Microsoft Visual SourceSafe (VSS) ...................................................................................... 3 SourceOffSite..................................................................................................................... 3 VSSConnexion................................................................................................................... 3 Borland StarTeam .................................................................................................................. 3 CVS (Concurrent Versions System) ...................................................................................... 4 CvsGui................................................................................................................................4 TortoiseCVS...................................................................................................................... -

Starteam 16.2
StarTeam 16.2 Release Notes Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com Copyright © Micro Focus 2017. All rights reserved. MICRO FOCUS, the Micro Focus logo and StarTeam are trademarks or registered trademarks of Micro Focus IP Development Limited or its subsidiaries or affiliated companies in the United States, United Kingdom and other countries. All other marks are the property of their respective owners. 2017-11-02 ii Contents StarTeam Release Notes ....................................................................................5 What's New ........................................................................................................ 6 16.2 ..................................................................................................................................... 6 StarTeam Command Line Tools .............................................................................. 6 StarTeam Cross-Platform Client ...............................................................................6 StarTeam Git Command Line Utility. .........................................................................7 StarTeam Server ...................................................................................................... 7 Workflow Extensions ................................................................................................ 8 StarTeam Web Client ................................................................................................8 16.1 Update 1 ......................................................................................................................9 -

Teamcity 7.1 Documentation.Pdf
1. TeamCity Documentation . 4 1.1 What's New in TeamCity 7.1 . 5 1.2 What's New in TeamCity 7.0 . 14 1.3 Getting Started . 26 1.4 Concepts . 30 1.4.1 Agent Home Directory . 31 1.4.2 Agent Requirements . 32 1.4.3 Agent Work Directory . 32 1.4.4 Authentication Scheme . 33 1.4.5 Build Agent . 33 1.4.6 Build Artifact . 34 1.4.7 Build Chain . 35 1.4.8 Build Checkout Directory . 36 1.4.9 Build Configuration . 37 1.4.10 Build Configuration Template . 38 1.4.11 Build Grid . 39 1.4.12 Build History . 40 1.4.13 Build Log . 40 1.4.14 Build Number . 40 1.4.15 Build Queue . 40 1.4.16 Build Runner . 41 1.4.17 Build State . 41 1.4.18 Build Tag . 42 1.4.19 Build Working Directory . 43 1.4.20 Change . 43 1.4.21 Change State . 43 1.4.22 Clean Checkout . 44 1.4.23 Clean-Up . 45 1.4.24 Code Coverage . 46 1.4.25 Code Duplicates . 47 1.4.26 Code Inspection . 47 1.4.27 Continuous Integration . 47 1.4.28 Dependent Build . 47 1.4.29 Difference Viewer . 49 1.4.30 Guest User . 50 1.4.31 History Build . 51 1.4.32 Notifier . 51 1.4.33 Personal Build . 52 1.4.34 Pinned Build . 52 1.4.35 Pre-Tested (Delayed) Commit . 52 1.4.36 Project . 53 1.4.37 Remote Run . .. -
Tasktop Integration Hub Editions.Pdf
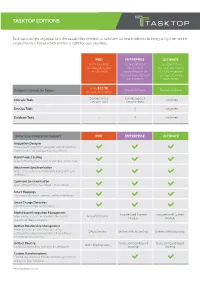
TASKTOP EDITIONS Tasktop provides organizations the capabilities needed to transform software delivery by integrating their entire value stream. Choose which edition is right for your business. PRO ENTERPRISE ULTIMATE Starter package For organizations For organizations for integrating two interested in that want the benefit Lifecycle tools. connecting part of of a fully integrated their software delivery software delivery value stream. value stream. From $12.50 Request a Quote Request a Quote Endpoint Connector Types per user, per month* Connect Any 2 Connect up to 5 Lifecycle Tools Unlimited Lifecycle Tools Lifecycle Tools DevOps Tools - $ Unlimited Database Tools - $ Unlimited Enterprise Integration Support PRO ENTERPRISE ULTIMATE Integration Designer Web-based integration designer and administra- tion interface for configuring integrations Rapid Project Scaling Scale to hundreds of projects with just a few clicks Attachment Synchronization Share screenshots and diagrams along with your artifacts Comment Synchronization Use comments for in-context collaboration Smart Mappings Automatically maps common artifact attributes Smart Change Detection Optimized for high-performance Model-based Integration Management Included and Custom Included and Custom Map artifacts to a central model instead of Included Models Models Models creating endless tool pairs Artifact Relationship Management Maintain critical context by mirroring 1 Relationship Unlimited Relationships Unlimited Relationships relationships like parent-child, validated by or blocked -

Using Visual COBOL in Modern Application Development Micro Focus the Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK
Using Visual COBOL in Modern Application Development Micro Focus The Lawn 22-30 Old Bath Road Newbury, Berkshire RG14 1QN UK http://www.microfocus.com © Copyright 2018-2020 Micro Focus or one of its affiliates. MICRO FOCUS, the Micro Focus logo and Visual COBOL are trademarks or registered trademarks of Micro Focus or one of its affiliates. All other marks are the property of their respective owners. 2020-08-25 ii Contents Using Visual COBOL in Modern Application Development ........................... 4 Introduction to Modern Application Development ................................................................4 What is Modern Application Development? ..............................................................4 Key Concepts in Modern Application Development ..................................................5 Steps Involved in Modern Application Development ................................................ 6 Agile Methods ..................................................................................................................... 7 Introduction to Agile Methods ...................................................................................7 Agile Development Workflow ....................................................................................7 Agile Development and Micro Focus Development Tools .........................................9 Continuous Integration ...................................................................................................... 11 Introduction to Continuous Integration .................................................................. -

Main Brochure2.Indd
Automate your Build Process . Powerful and fl exible user interface . Automate version control, compilers, install builders, deployment, testing, notifi cations, and lots more... Dynamic build process using fl ow control, iterators, loops, and exceptions . Full debugger built in - breakpoints, variable watches, live logging . Script events for every action to customise your build process Hierarchical Logging Error Handling FinalBuilder ActionStudio . The log is presented in the same . Easily detect and handle errors during . Allows development of native FinalBuilder hierarchy as your build process your build process actions . Optionally view live log output . Exception handling actions . Includes property page designer and as the build runs include: TRY, CATCH, FINALLY code editor with syntax highlighting . Builds logs are automatically . Control the fl ow of your build process . Develop actions in VBScript, JScript, COM, archived and recover from errors or any .Net language such as C#, VB.Net or Delphi for .Net . Export the log as XML, HTML, or . Unhandled errors trigger the OnFailure Text action list . Included in all editions of FinalBuilder VSoft Technologies Pty Ltd http://www.fi nalbuilder.com ABN: 82 078 466 092 P.O. Box 126, Erindale Centre, ACT 2903, Australia salesinfo@fi nalbuilder.com Phone: +61 2 6282 7488, Fax +61 2 6282 7588 news://news.fi nalbuilder.com FinalBuilder Integrates with your version control system . Microsoft TeamSystem Use a GUI instead of XML fi les . Microsoft Visual SourceSafe . Perforce Although FinalBuilder uses an XML based fi le format, you . IBM Rational ClearCase don’t need to understand it or even look at it. The FinalBuilder . QSC Team Coherence GUI allows you to quickly and easily create a build process . -

Key Facts Key Benefits Key Features Continuous Integration for Everybody
7.0 Continuous Integration for Everybody “Continuous Integration is a software development practice where members of a team integrate their work frequently, usually each person integrates at least daily — leading to multiple integrations per day. Many teams find that this approach leads to significantly reduced integration problems and allows a team to develop cohesive software more rapidly.” Martin Fowler Key Facts “So the reason I made the TeamCity is a userfriendly continuous integration (CI) server for switch is because of the professional developers and build engineers. It is trivial to setup and time it take to set it up: 20 absolutely free for small teams. minutes. Everything was fully functional in under 20 minutes. I absolutely got no Key Benefits error at all. I just got through all the step of the wizard and • Automate code analyzing, compiling, and testing processes, with having then: done. Unit testing, code instant feedback on build progress, problems and test failures, all in simple, coverage, build, reports, etc... intuitive webinterface; And it’s absolutely free for • Run multiple builds and tests under different configurations and platforms small team.” simultaneously; Sebastien Lachance, Software Developer at • Make sure your team sustains an uninterrupted workflow with the help of BXSYSTEMS Pretested commits and Personal builds; • Have build history insight with customizable statistics on build duration, “Teamcity is totally awesome, success rate, code quality and custom metrics; after i got the grails project • Enable -

Konstantin Yakovlev, Phd
Konstantin Yakovlev, PhD. Curriculum Vitae. Page 1 of 4 KONSTANTIN YAKOVLEV, PhD +7 (926) 270 89 79 [email protected] www.kyakovlev.me PERSONAL PROFILE I am a highly motivated, hard-working and open-minded person possessing a sound (10+ years) experience in research, education and software development. I am a PhD in theoretical computer science. I used to work at the frontier research centers, top-ranked universities, well-established software development companies and dynamic startups both at my home country and abroad. I am always enthusiastic and happy to be part of a vibrant dynamic team involved in solving complex technical problems and ensuring The Next Big Things happen day by day, every day. SOFT SKILLS • Strong communication skills • High-level of computer and technological competence • Presentation skills • Focused professional • Team work skills • Flexible and adaptive • Planning and time management skills • Patient and tolerant AREAS OF EXPERTISE • Artificial Intelligence • Languages and technologies of programming • Automated Planning • Object-oriented design • Machine Learning • Database design • Robotics • Theory of algorithms EDUCATIONAL BACKGROUND Institute for Systems Analysis, research center of Russian Academy of Sciences Moscow, Russia Doctor of Philosophy in Theoretical Computer Sciences 2006-2010 Peoples' Friendship University of Russia, top-ranked university in Russia Moscow, Russia Master of Applied Mathematics and Informatics (Honors) 2004-2006 Peoples' Friendship University of Russia, top-ranked university -

Esa Study Contract Report
ESA STUDY CONTRACT REPORT ESA Contract No: Subject: Contractor: ESA ITT Number Current and Future Tech- Distributed Systems Group, AO/3-12280/07/NL/CB nologies for Collaborative Vienna University of Tech- Working Environments nology ESA CR() No: No of volumes: 1 Contractor’s Reference: This Volume No: 1 TEUN Abstract: This document reports the final, detailed result of the study on current and future technologies for collaborative working environments (CWEs). The goal of this study is to analyze current CWEs and whether they and their future trends are suitable for large- scale multinational organizations. To this end, we have analyzed the structure of large-scale organizations in general, and of ESA in particular, with respect to organization, geographical distribution, and IT environments. Requirements for CWEs used in collaborative work are presented. Based on an initial list of criteria given by ESA, we have revised and extended the list to introduce a comprehensive set of criteria for evaluating CWEs. The state-of-the- art CWEs are discussed and classified. We have selected 15 representative CWE products and evaluated and compared them in detail. From the evaluation and comparison of CWE products, we have presented our findings of current issues and future trends of CWEs. In particular, existing products provide many features required by large-scale and multinational organizations but those features are not well-integrated into a single system. Due to the complexity of collaborative work within those organizations, often many CWEs are used in parallel and it is not easy to integrate those CWEs together. The work described in this report was done under ESA Contract. -

Bill Laboon Friendly Introduction Version Control: a Brief History
Git and GitHub: A Bill Laboon Friendly Introduction Version Control: A Brief History ❖ In the old days, you could make a copy of your code at a certain point, and release it ❖ You could then continue working on your code, adding features, fixing bugs, etc. ❖ But this had several problems! VERSION 1 VERSION 2 Version Control: A Brief History ❖ Working with others was difficult - if you both modified the same file, it could be very difficult to fix! ❖ Reviewing changes from “Release n” to “Release n + 1” could be very time-consuming, if not impossible ❖ Modifying code locally meant that a crash could take out much of your work Version Control: A Brief History ❖ So now we have version control - a way to manage our source code in a regular way. ❖ We can tag releases without making a copy ❖ We can have numerous “save points” in case our modifications need to be unwound ❖ We can easily distribute our code across multiple machines ❖ We can easily merge work from different people to the same codebase Version Control ❖ There are many kinds of version control out there: ❖ BitKeeper, Perforce, Subversion, Visual SourceSafe, Mercurial, IBM ClearCase, AccuRev, AutoDesk Vault, Team Concert, Vesta, CVSNT, OpenCVS, Aegis, ArX, Darcs, Fossil, GNU Arch, BitKeeper, Code Co-Op, Plastic, StarTeam, MKS Integrity, Team Foundation Server, PVCS, DCVS, StarTeam, Veracity, Razor, Sun TeamWare, Code Co-Op, SVK, Fossil, Codeville, Bazaar…. ❖ But we will discuss git and its most popular repository hosting service, GitHub What is git? ❖ Developed by Linus Torvalds ❖ Strong support for distributed development ❖ Very fast ❖ Very efficient ❖ Very resistant against data corruption ❖ Makes branching and merging easy ❖ Can run over various protocols Git and GitHub ❖ git != GitHub ❖ git is the software itself - GitHub is just a place to store it, and some web-based tools to help with development.