Vector Analysis: MS4613
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Transformation of Axes
19 Chapter 2 Transformation of Axes 2.1 Transformation of Coordinates It sometimes happens that the choice of axes at the beginning of the solution of a problem does not lead to the simplest form of the equation. By a proper transformation of axes an equation may be simplified. This may be accom- plished in two steps, one called translation of axes, the other rotation of axes. 2.1.1 Translation of axes Let ox and oy be the original axes and let o0x0 and o0y0 be the new axes, parallel respectively to the old ones. Also, let o0(h, k) referred to the origin of new axes. Let P be any point in the plane, and let its coordinates referred to the old axes be (x, y) and referred to the new axes be (x0y0) . To determine x and y in terms of x0, y0, h and x = h + x0 y = k + y0 20 Chapter 2. Transformation of Axes these equations represent the equations of translation and hence, the coeffi- cients of the first degree terms are vanish. 2.1.2 Rotation of axes Let ox and oy be the original axes and ox0 and oy0 the new axes. 0 is the origin for each set of axes. Let the angle x0 ox through which the axes have been rotated be represented by q. Let P be any point in the plane, and let its coordinates referred to the old axes be (x, y) and referred to the new axes be (x0, y0), To determine x and y in terms of x0, y0 and q : x = OM = ON − MN = x0 cos q − y0 sin q and y = MP = MM0 + M0P = NN0 + M0P = x0 sin q + y0 cos q 2.1. -

General Theory of Conicoids 1
GENERAL THEORY OF CONICOIDS Structure 1.1 Introduction Objectives 1.2 What is a Conicoid? 1.3 Change of Axes 1.3.1 Translat~on of Axes 1.3.2 Projection L 1.3.3 Rotation of Axes 1.4 Reduction to Standard Form 1.5 Summary 1.6 Solutions and Answers I 1.1 INTRODUCTION You have seen in Block 7 that the general equation of second degree in two variables x and y represents a conic. In analogy with this we can ask: what will a general second degree equation in three variables represent? In Block 8 you have studied some particular forms of second degree equations in three variables, namely, those representing spheres, cones and cylinders. In this unit we study the most general form of a second degree equation in three variables. The surface generated by these equations are called quadrics or conicoids. This name is apt because, as you will see in Unit 8, they can be formed by revolving a conic about a line called an axis. Alexis Clairaut (17 13- 1765), a French mathematician, was one of the pioneers to study quadric surfaces. He specified that a surface, in .general, can be represented by an equation in three variables. He presented his ideas in his book 'Recherche Sur Les Courbes a Double Courbure' in which he gave the equations of several conicoids like the sphere, cylinder, hyperboloid and ellipsoid. We start this unit with a small section in which we define a conicoid: In the next section we discuss rigid body motions in a three-dimensional system. -

C:\Book\Booktex\C1s3.DVI
65 §1.3 SPECIAL TENSORS Knowing how tensors are defined and recognizing a tensor when it pops up in front of you are two different things. Some quantities, which are tensors, frequently arise in applied problems and you should learn to recognize these special tensors when they occur. In this section some important tensor quantities are defined. We also consider how these special tensors can in turn be used to define other tensors. Metric Tensor Define yi,i=1,...,N as independent coordinates in an N dimensional orthogonal Cartesian coordinate system. The distance squared between two points yi and yi + dyi,i=1,...,N is defined by the expression ds2 = dymdym =(dy1)2 +(dy2)2 + ···+(dyN )2. (1.3.1) Assume that the coordinates yi are related to a set of independent generalized coordinates xi,i=1,...,N by a set of transformation equations yi = yi(x1,x2,...,xN ),i=1,...,N. (1.3.2) To emphasize that each yi depends upon the x coordinates we sometimes use the notation yi = yi(x), for i =1,...,N. The differential of each coordinate can be written as ∂ym dym = dxj ,m=1,...,N, (1.3.3) ∂xj and consequently in the x-generalized coordinates the distance squared, found from the equation (1.3.1), becomes a quadratic form. Substituting equation (1.3.3) into equation (1.3.1) we find ∂ym ∂ym ds2 = dxidxj = g dxidxj (1.3.4) ∂xi ∂xj ij where ∂ym ∂ym g = ,i,j=1,...,N (1.3.5) ij ∂xi ∂xj i are called the metrices of the space defined by the coordinates x ,i=1,...,N. -

Kaifangfa and Translation of Coordinate Axes 開方法과 座標軸의 平行移動
Journal for History of Mathematics http://dx.doi.org/10.14477/jhm.2014.27.6.387 Vol. 27 No. 6 (Dec. 2014), 387–394 Kaifangfa and Translation of Coordinate Axes 開方法과 座標軸의 平行移動 Hong Sung Sa 홍성사 Hong Young Hee 홍영희 Chang Hyewon* 장혜원 Since ancient civilization, solving equations has become one of the most impor- tant subjects in mathematics and mathematics education. The extractions of square roots and cube roots were first dealt in Jiuzhang Suanshu in the setting ofsub- divisions. Extending these, Shisuo Kaifangfa and Zengcheng Kaifangfa were in- troduced in the 11th century and the subsequent development became one of the most important contributions to mathematics in the East Asian mathematics. The translation of coordinate axes plays an important role in school mathematics. Con- necting the translation and Kaifangfa, we find strong didactical implications for improving students’ understanding the history of Kaifangfa together with the trans- lation itself although the latter is irrelevant to the former’s historical development. Keywords: Shisuo Kaifangfa, Zengcheng Kaifangfa, Translation of coordinate axes, Fanji, Yiji; 釋鎖開方法, 增乘開方法, 座標軸의 平行移動, 飜積, 益積. MSC: 01A25, 12-03, 12E12, 97A30, 97G70, 97H30, 97N50 1 Introduction It is well known that the theory of equations is one of the most important subjects in the history of mathematics. It divides into two parts, namely, constructing equa- tions and solving them [3]. In this paper, our main concern is how to solve poly- nomial equations so that we will not discuss the former part. As also well known, the first attempt to solve equations was how to extract square roots and cube roots. -
B]<OU 160228 >M
z </)> ro^ 160228 >m >*B]<OU ^S z ^g OSMANIA UNIVERSITY LIBRARY >5T /6 Call No. ^ _ . Accession No. Author Title This book should be returnedion or before the^date last marked below. H. B. E*HMOB KPATKHfi KYPC AHAJIHTHMECKOfi FEOMETPHM FOCy/lAPCTBEHHOE 4>H3HKO-MATEMATH4ECKOft ^HTEPATVPbl M o c K B a N. YEFIMOV A Brief Course in Analytic Geometry TRANSLATED FROM THE RUSSIAN by O. S R O K A PEACE PUBLISHERS MOSCOW Written by Professor N. Yefimov, Dr. Phys. Math. Sc., this book presents, in concise form, the theoretical foundations of plane and solid analytic geometry. Also, an elementary outline of the theory of determinants is given in the Appendix. The textbook is intended for students of higher educational institutions and for engineers engaged in the field of quadric surface design. The book is illustrated with 122 drawings. CONTENTS Part One PLANE ANALYTIC GEOMETRY Chapter 1. Coordinates on a Straight Line and in a Plane 11 1. An Axis and Segments of an Axis 11 2. Coordinates on a Line. The Number Axis 14 3. Rectangular Cartesian Coordinates in a Plane. A Note on Ob- lique Cartesian Coordinates 16 4. Polar Coordinates 20 Chapter 2. Elementary Problems of Plane Analytic Geometry 23 5. Projection of a Line Segment. Distance Between Two Points . 23 6. Calculation of the Area of a Triangle 28 7. Division of a Line Segment in a Given Ratio 30 8. Transformation of Cartesian Coordinates by Translation of Axes 35 9. Transformation of Rectangular Cartesian Coordinates by Rotation of Axes 36 10. Transformation of Rectangular Cartesian Coordinates by Change of Origin and Rotation of Axes 38 Chapter 3. -
SECTION 9-4 Translation of Axes
9-4 Translation of Axes 639 For the receiving antenna shown in the figure, the common focus F is located 120 feet above the vertex of the parabola, .and focus F (for the hyperbola) is 20 feet above the vertex The vertex of the reflecting hyperbola is 110 feet above the vertex for the parabola. Introduce a coordinate system by using the axis of the parabola as the y axis (up positive), and let the x axis pass through the center of the hyperbola (right Radiotelescope positive). What is the equation of the reflecting hyperbola? Write y in terms of x. (b) SECTION 9-4 Translation of Axes • Translation of Axes • Standard Equations of Translated Conics • Graphing Equations of the Form Ax2 ϩ Cy2 ϩ Dx ϩ Ey ϩ F ϭ 0 • Finding Equations of Conics In the last three sections we found standard equations for parabolas, ellipses, and hyperbolas located with their axes on the coordinate axes and centered relative to the origin. What happens if we move conics away from the origin while keeping their axes parallel to the coordinate axes? We will show that we can obtain new standard equations that are special cases of the equation Ax2 ϩ Cy2 ϩ Dx ϩ Ey ϩ F ϭ 0, where A and C are not both zero. The basic mathematical tool used in this endeavor is translation of axes. The usefulness of translation of axes is not limited to graphing conics, however. Translation of axes can be put to good use in many other graphing situations. • Translation of Axes A translation of coordinate axes occurs when the new coordinate axes have the same direction as and are parallel to the original coordinate axes. -

Mathematics Session
Mathematics Session Cartesian Coordinate Geometry And Straight Lines Session Objectives 1. Cartesian Coordinate system and Quadrants 2. Distance formula 3. Area of a triangle 4. Collinearity of three points 5. Section formula 6. Special points in a triangle 7. Locus and equation to a locus 8. Translation of axes - shift of origin 9. Translation of axes - rotation of axes René Descartes Coordinates Y 3 Y-axis : Y’OY 2 X-axis : X’OX 1 +ve direction+ve X’ O X -4 -3 -2 -1 1 2 3 4 Origin -1 +ve direction -2 -ve direction ve directionve Y’ -3 - Coordinates Y 3 2 (2,1) Abcissa 1 X’ O X -4 -3 -2 -1 1 2 3 4 -1 Ordinate -2 (-3,-2) Y’ -3 (?,?) Coordinates Y 3 2 (2,1) Abcissa 1 X’ O X -4 -3 -2 -1 1 2 3 4 -1 Ordinate -2 (-3,-2) Y’ -3 (4,?) Coordinates Y 3 2 (2,1) Abcissa 1 X’ O X -4 -3 -2 -1 1 2 3 4 -1 Ordinate -2 (-3,-2) Y’ -3 (4,-2.5) Quadrants Y (-,+) (+,+) II I X’ O X III IV (-,-) (+,-) Y’ Quadrants Y (-,+) (+,+) II I X’ O X III IV (-,-) (+,-) Y’ Ist? IInd? Q : (1,0) lies in which Quadrant? A : None. Points which lie on the axes do not lie in any quadrant. Distance Formula Y 1 y - 2 y 2 y N PQN is a right angled . 1 x1 y 2 2 2 (x2-x1) PQ = PN + QN 2 2 2 X’ O X PQ = (x2-x1) +(y2-y1) x2 Y’ 22 PQ =( x2 − x 1) +( y 2 − y 1 ) Distance From Origin Distance of P(x, y) from the origin is 22 =(x − 0) +( y − 0) =+xy22 Applications of Distance Formula Parallelogram Applications of Distance Formula Rhombus Applications of Distance Formula Rectangle Applications of Distance Formula Square Area of a Triangle Y A(x1, y1) ) 2 , y , C(x3, y3) 2 B(x X’ O M L N -

Unit 9 Will Be Followed by the Analytic Geometry Final Exam
Topics In this unit, we continue our study of the conic sections with investigations on translation and rotation of axes. The course concludes with a study of parametric equations. x Translation of axes (10.2-4) o standard equation of a translated conic o finding axes, foci, etc., of translated conics o finding equations of translated conics x Rotation of axes (10.5, plus supplementary pamphlet) o general equation of a conic section o finding the angle of rotation o converting the equation of a rotated conic to the standard equation of a translated conic o finding axes, foci, etc., of rotated conics o identifying conics x Parametric equations (10.7) o definition of parametric equations o graphing a plane curve given by parametric equations o eliminating the parameter o projectile motion o finding parametric equations of conic sections Unit 9 will be followed by the Analytic Geometry Final Exam. Study Guidelines for the 8th edition of Sullivan's Precalculus These reading and problem assignments are designed to help you learn the course material. You should complete all of these problems, check your answers in the back of the textbook, and get help with the problems that you missed. Most of the problems are odd-numbered, so you can check the solutions in the Solutions Manual. The only way to learn mathematics is to do mathematics, so while these problems will not be collected or graded, you will probably not do well in the course if you do not complete these and check your work as described above. After completing these problems, go on to the Unit Exam Description below and follow directions. -

Chapter 7: Identifying Second Degree Equations
Chapter 7 Identifying second degree equations 7.1 The eigenvalue method In this section we apply eigenvalue methods to determine the geometrical nature of the second degree equation ax2 + 2hxy + by2 + 2gx + 2fy + c = 0, (7.1) where not all of a, h, b are zero. a h Let A = be the matrix of the quadratic form ax2 + 2hxy + by2. h b · ¸ We saw in section 6.1, equation 6.2 that A has real eigenvalues λ1 and λ2, given by a + b (a b)2 + 4h2 a + b + (a b)2 + 4h2 λ1 = − − , λ2 = − . p 2 p 2 We show that it is always possible to rotate the x, y axes to x1, y1 axes whose positive directions are determined by eigenvectors X1 and X2 corresponding to λ1and λ2 in such a way that relative to the x1, y1 axes, equation 7.1 takes the form 2 2 a′x + b′y + 2g′x + 2f ′y + c = 0. (7.2) Then by completing the square and suitably translating the x1, y1 axes, to new x2, y2 axes, equation 7.2 can be reduced to one of several standard forms, each of which is easy to sketch. We need some preliminary definitions. 129 130 CHAPTER 7. IDENTIFYING SECOND DEGREE EQUATIONS DEFINITION 7.1.1 (Orthogonal matrix) An n n real matrix P is × called orthogonal if t P P = In. It follows that if P is orthogonal, then det P = 1. For ± det (P tP ) = det P t det P = ( det P )2, so (det P )2 = det I = 1. -

Section 8.2. Applications to Geometry
8.2 Applications to Geometry 1 Chapter 8. Eigenvalues: Further Applications and Computations 8.2. Applications to Geometry Note. Figure 8.2 shows there intersections of planes with a double right-circular cone (“right-circular” because a plane perpendicular to the axis of the cone cuts the cone in a circle). The resulting “conic sections” shown are an ellipse (a circle is a special case of an ellipse), a hyperbola, and a parabola. In this section we state the standard equations for these three conic sections without any derivation. For an alternated approach where definitions are given in terms of sums and differences of certain distances (and the derivation of our formulae follow from these definitions) see my online Calculus 3 notes: http://faculty.etsu.edu/gardnerr/2110/notes -12e/c11s6.pdf. 8.2 Applications to Geometry 2 Note. The equation of an ellipse in standard form (that is, with center at (0, 0)) is x2 y2 + = 1. a2 b2 If the center of the ellipse is at the point (h, k) then the equation is (x h)2 (y k)2 − + − = 1. a2 b2 See Figure 8.3. 2 2 Note. Every polynomial equation of the form c1x + c2y + c3x + c4y = d, where nonzero c1 an c2 are of the same sign, determines an ellipse. The center can be found by completing the square of the x2 and x terms and of the y2 and y terms. (x h)2 (y k)2 It’s possible for the equation to become of the form − + − = 0 in a2 b2 which case the solution set is the single point (h, k); this is called a degenerate (x h)2 (y k)2 ellipse. -

Mehedi Sir Note on Coordinate Geometry.Pdf
Faculty of Science and Information Technology Department of Natural Sciences Coordinate geometry is the branch of mathematics in which geometry is studied with the help of algebra. The great France mathematician and philosopher Rene Descartes (1596-1650) first applied algebraic formulae in geometry. A system of geometry where the position of points on the plane is described using two numbers called an ordered pair of numbers or coordinates. The first element of the ordered pair represents the distance of that point on x-axis called abscissa and second element on y-axis called ordinate. This abscissa and ordinate makes coordinates of that point. The method of describing the location of points in this way was proposed by the French mathematician René Descartes (1596 - 1650). (Pronounced "day CART"). He proposed further that curves and lines could be described by equations using this technique, thus being the first to link algebra and geometry. In honor of his work, the coordinates of a point are often referred to as its Cartesian coordinates and the coordinate plane as the Cartesian Coordinate Plane and coordinate geometry sometimes called Cartesian geometry. 1 Cartesian/Rectangular Coordinates System: Every plane is two dimensional so to locate the position of a point in a plane there is needed two coordinates. The Mathematician Rene Descartes first considered two perpendicular intersecting fixed straight lines in a plane as axes of coordinates. These two straight lines are named as rectangular axes and intersecting point as the origin denotes by the symbol O and the symbol O comes from the first letter of the word origin. -
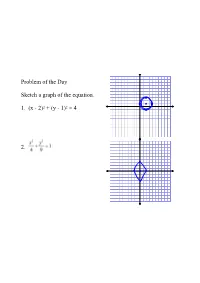
Problem of the Day Sketch a Graph of The
Problem of the Day Sketch a graph of the equation. 1. (x 2)2 + (y 1)2 = 4 2. Problem of the Day Sketch a graph of the equation. 1. 16(x 1)2 9(y + 2)2 = 144 Problem of the Day Write the equation. Ellipse with center (4,5), major axis length 10 and a focus at (6,5) Hyperbola with center (1, 2), conjugate axis length 16, and a transverse axis length 8 and along the line y = 2 Problem of the Day Write the equation of the conic section in standard form x2 + y2 10x + 4y 7 = 0 4x2 + y2 8x + 4y 4 = 0 Standard Equations of Translated Conic Sections Hyperbolas Hyperbolas Transverse Axis Conjugate Axis Foci Graph the following conic section. Graph the following conic section. Find the coordinates of the foci. Find the length of the transverse and conjugate axes. Graph the following conic section. Find the coordinates of the foci. Find the length of the transverse and conjugate axes. Use completing the square to write the equation of the hyperbola in standard form. y2 4x2 + 8x 2y = 67 5x2 y2 + 30x 4y = 84 Use completing the square to write the equation of the hyperbola in standard form. Then find the coordinates of the foci. x2 9y2 + 16x 72y 161 = 0 Use completing the square to write the equation of the hyperbola in standard form. Then find the coordinates of the foci. 8y2 7x2 32y + 42x 87 = 0 Write the equation of the hyperbola using the following information. Center (5,6), Vertex at (9,6) and conjugate axis length 10 Vertices (4,1) and (4,5) and Foci (4,0) and (4,6) Standard Equations of Translated Conic Sections Parabolas (y k)2 = 4a(x h) (x h)2 = 4a(y k) Circle (x h)2 + (y k)2 = r2 Ellipses Translation of Axes Identify the conic section as a parabola, circle, ellipse, or hyperbola based on the equation.