Arxiv:2108.04812V1 [Cs.CL] 10 Aug 2021 from Supervised Data, Including Via Active Learn- Ing Natural Language
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
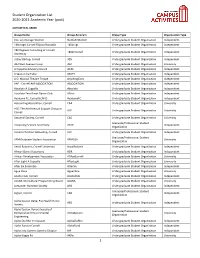
Student Organization List 2020-2021 Academic Year (Past)
Student Organization List 2020-2021 Academic Year (past) ALPHABETICAL ORDER Group Name Group Acronym Group Type Organization Type (not so) Average Women NotSoAvWomen Undergraduate Student Organization Independent 14Strings! Cornell Filipino Rondalla 14Strings Undergraduate Student Organization Independent 180 Degrees Consulting at Cornell 180dcCornell Undergraduate Student Organization Independent University 3 Day Startup, Cornell 3DS Undergraduate Student Organization Independent 302 Wait Avenue Co-op 302 Undergraduate Student Organization University A Cappella Advisory Council ACAC Undergraduate Student Organization Independent A Seat at the Table ASATT Undergraduate Student Organization Independent A.G. Musical Theatre Troupe AnythingGoes Undergraduate Student Organization Independent AAP - Cornell AAP ASSOCIATION ASSOCIATION Undergraduate Student Organization Independent Absolute A Cappella Absolute Undergraduate Student Organization Independent Absolute Zero Break Dance Club AZero Undergraduate Student Organization Independent Academy FC, Cornell (CAFC) AcademyFC Undergraduate Student Organization Independent Accounting Association, Cornell CAA Undergraduate Student Organization University ACE: The Ace/Asexual Support Group at ACE Undergraduate Student Organization University Cornell Actuarial Society, Cornell CAS Undergraduate Student Organization University Graduate/Professional Student Advancing Science And Policy ASAP Independent Organization Advent Christian Fellowship, Cornell ACF Undergraduate Student Organization Independent -

Employee Wellbeing at Cornell Re
Your guide to resources that support all the dimensions of your wellbeing. HR.CORNELL.EDU/WELLBEING 1 2 1.6.20 Dear Colleague, During your time with Cornell, we want you to be well and THRIVE. Cornell invests in benefits, programs, and services to support employee wellbeing. This guide features a wide range of university (and many community!) resources available to support you in various dimensions of your wellbeing. As you browse this guide, which is organized around Cornell’s Seven Dimensions of Wellbeing model pictured below, you’ll find many resources cross-referenced in multiple dimensions. This illustrates the multifaceted nature of wellbeing. It is often non-linear in nature, and our most important elements shift as our work and Mary Opperman personal lives evolve. CHRO and Vice President Division of Human Resources We experience wellbeing both personally and as members of our various communities, including our work community. We each have opportunities to positively contribute to Cornell’s culture of wellbeing as we celebrate our colleagues’ life events, support one another during difficult times, share resources, and find creative approaches to how, where, and when work gets done. Behind this page is a “quick start directory” of Cornell wellbeing-related contacts. Please save this page and reach out any time you need assistance! Although some of these resources are specific to Cornell’s Ithaca campus, we recognize and are continuing to focus on expanding offerings to our employees in all locations. Thank you for all of your contributions -

'54 Class Notes Names, Topics, Months, Years, Email: Ruth Whatever
Use Ctrl/F (Find) to search for '54 Class Notes names, topics, months, years, Email: Ruth whatever. Scroll up or down to May - Dec. '10 Jan. – Dec. ‘16 Carpenter Bailey: see nearby information. Click Jan. - Dec. ‘11 Jan. - Dec. ‘17 [email protected] the back arrow to return to the Jan. – Dec. ‘12 Jan. - Dec. ‘18 or Bill Waters: class site. Jan. – Dec ‘13 July - Dec. ‘19 [email protected] Jan. – Dec. ‘14 Jan. – Dec. ‘20 Jan. – Dec. ‘15 Jan. – Aug. ‘21 Class website: classof54.alumni.cornell.edu July 2021 – August 2021 Since this is the last hard copy class notes column we will write before CAM goes digital, it is only fitting that we received an e-mail from Dr Bill Webber (WCMC’60) who served as our class’s first correspondent from 1954 to 1959. Among other topics, Webb advised that he was the last survivor of the three “Bronxville Boys” who came to Cornell in 1950 from that village in Westchester County. They roomed together as freshmen, joined Delta Upsilon together and remained close friends through graduation and beyond. They even sat side by side in the 54 Cornellian’s group photo of their fraternity. Boyce Thompson, who died in 2009, worked for Pet Milk in St. Louis for a few years after graduation and later moved to Dallas where he formed and ran a successful food brokerage specializing in gourmet mixed nuts. Ever the comedian, his business phone number (after the area code) was 223-6887, which made the letters BAD-NUTS. Thankfully, his customers did not figure it out. -

Fast Forward Shortlisted for a National Jewish Book Award for Kim Azz Arelli ’93 of Jewish American Women
OWNED AND PUBLISHED BY THE CORNELL ALUMNI ASSOCIATION JANUARY | FEBRUARY 2016 $6.00 F ast Forward Four years on, it’s full speed ahead for Cornell Tech PLUS: Winter in ithaca: embracing the inevitable Change.org’s Jennifer Dulski ’93, MBA ’99 Danger: asteroids! c1-c1 CAM jf16 cover.indd 1 12/18/15 2:36 PM Only on Kiawah Island. THE OCEAN COURSE CASSIQUE AND RIVER COURSE AND BEACH CLUB SANCTUARY HOTEL OCEAN PARK 2012 PGA CHAMPIONSHIP SPORTS PAVILION FRESHFIELDS VILLAGE SASANQUA SPA HISTORIC CHARLESTON Kiawah Island has been named Condé Nast Traveler’s #1 island in the USA (and #2 in the world) for a myriad of reasons – 10 miles of uncrowded beach, iconic golf and resort, the allure of nearby Charleston, KiawahIsland.com | 866.312.1791 | 1 Kiawah Island Parkway | Kiawah Island, South Carolina and a superb private Club and community to name a few. For a recharge, for a holiday, or for a lifetime, KIAWAH’S EXCLUSIVE ONISLAND REAL ESTATE SALES OFFICES SINCE 1976 your discovery of Kiawah Island can be the rst day of the best of your life. homes • homesites • villas • cottages | from about $300,000 to over $20 million Obtain the Property Report required by Federal law and read it before signing anything. No Federal agency has judged the merits or value, if any, of this property. approval of the sale or lease or offer for sale or lease by the Department of State or any offi cer thereof, or that the Department of State has in any way passed upon Void where prohibited by law. -

Read the K–12 Program Profiles
PLUGGING IN PROFILES FROM NYC'S K–12 TECH AND STEAM SKILLS-BUILDING ECOSYSTEM nycfuture.org FEBRUARY 2020 Plugging In: Building NYC's Tech Education and Training Ecosystem 1 K–12 PROGRAM PROFILES Cornell Tech: Teachers in Residence 23 Genspace Biorocket Research Internship 24 Rockaway Waterfront Alliance Environmentor Internship 25 Girls Who Code: Summer Immersion Program 26 P-TECH / CUNY Early College Initiative 27 Code Nation 29 The Knowledge House: Exploring Technology 30 Schools That Can: Maker Fellows Program 31 BEAM (Bridge to Enter Advanced Mathematics) 32 NYC FIRST STEM Centers and Robotics Programs 34 STEM From Dance 35 Sunset Spark 36 City Parks Foundation: Green Girls 37 BioBus: Mobile Lab 38 CAMBA After School 39 ELiTE Education 40 Beam Center 42 American Museum of Natural History – BridgeUp: STEM 43 Genesys Works 44 DIVAS for Social Justice: STEAM for Social Change + STEAM Camp 46 HYPOTHEkids: HK Maker Lab 47 TEALS 48 New York Hall of Science: Science Career Ladder/Explainers 49 New York on Tech: TechFlex Leaders/360 Squad 51 New York Academy of Sciences: Scientist-in-Residence 52 Global Kids: Digital Learning & Leadership 53 Consortium for Research & Robotics (CRR) 54 CodeScty 55 Cooper Union STEM Saturdays 56 iMentor 57 Citizen Schools: Apprenticeships 58 STEM Kids NYC -- In School and After School Programs 60 Rocking the Boat 61 NYU Tandon: Innovative Technology Experiences for Students and Teachers 62 Upperline Code 63 Brooklyn STEAM Center 64 Verizon Innovative Learning Schools 65 22 K–12 Programs Cornell Tech: Teachers in Residence Teachers in Residence is a free professional development program offered by Cornell Tech that trains non-CS teachers in underserved elementary and middle schools in Manhattan, Queens, and the Bronx to integrate CS into their classrooms. -

University Policy 4.3, Sales Activities
CORNELL UNIVERSITY POLICY 4.3 POLICY LIBRARY Volume: 4, Governance/Legal Chapter: 3, Sales Activities On Campus Responsible Executive: Vice President for University Relations Responsible Office: University Sales Activities On Campus Relations Originally Issued: September, 1992 Last Full Review:January 24, 2017 Last Updated: August 6, 2021 POLICY STATEMENT For the convenience of its community, Cornell University allows limited sales to be conducted on its campus in ways that are consistent with the university’s mission, take account of off-campus businesses, and comply with applicable laws and regulations. ◆ Note: Units established to provide materials or specialized services to campus units (i.e., recharge operations, service facilities, and specialized service facilities) must be established in accordance with University Policy 3.10, Recharge Operations and Service Facilities. Please contact University Relations, where such a unit proposes to provide sales or services for personal use or to the general public, or that would be in competition with local commercial providers offering the same goods or services to determine whether this policy also applies to that operation REASON FOR POLICY Cornell regulates the use of its property for sales and other commercial activities in order to maintain a safe, attractive environment for instruction, research, and public service; to facilitate opportunities for its faculty, students, and staff to engage in course-related sales experiences; to encourage activities that support charitable endeavors; to promote off-campus local and regional economies; and to comply with all applicable regulations, including those governing the university’s tax-exempt status. ENTITIES AFFECTED BY THIS POLICY Ithaca-based locations Cornell Tech campus ☐ Weill Cornell Medicine campuses WHO SHOULD READ THIS POLICY ‒ All members of the university community, excluding those at the Weill Cornell Medicine. -

How to Calibrate Your Adversary's Capabilities? Inverse Filtering for Counter-Autonomous Systems
1 How to Calibrate your Adversary’s Capabilities? Inverse Filtering for Counter-Autonomous Systems Vikram Krishnamurthy, Fellow IEEE and Muralidhar Rangaswamy, Fellow IEEE Manuscript dated July 9, 2019 Abstract—We consider an adversarial Bayesian signal process- wish to estimate the adversary’s sensor’s capabilities and ing problem involving “us” and an “adversary”. The adversary predict its future actions (and therefore guard against these observes our state in noise; updates its posterior distribution of actions). the state and then chooses an action based on this posterior. Given knowledge of “our” state and sequence of adversary’s actions observed in noise, we consider three problems: (i) How can the A. Problem Formulation adversary’s posterior distribution be estimated? Estimating the posterior is an inverse filtering problem involving a random The problem formulation involves two players; we refer to measure - we formulate and solve several versions of this the two players as “us” and “adversary”. With k = 1; 2;::: problem in a Bayesian setting. (ii) How can the adversary’s observation likelihood be estimated? This tells us how accurate denoting discrete time, the model has the following dynamics: the adversary’s sensors are. We compute the maximum likelihood x ∼ P = p(xjx ); x ∼ π estimator for the adversary’s observation likelihood given our k xk−1;x k−1 0 0 measurements of the adversary’s actions where the adversary’s yk ∼ Bx ;y = p(yjxk) k (1) actions are in response to estimating our state. (iii) How can π = T (π ; y ) the state be chosen by us to minimize the covariance of the k k−1 k estimate of the adversary’s observation likelihood? “Our” state ak ∼ Gπk;a = p(ajπk) can be viewed as a probe signal which causes the adversary to act; so choosing the optimal state sequence is an input Let us explain the notation in (1): p(·) denotes a generic design problem. -

2020 Annual Security Report 2 West Loop Road New York, NY 10044
2020 Annual Security Report 2 West Loop Road New York, NY 10044 Published October 2020 Jeanne Clery Disclosure of Campus Security Policy and Campus Crime Statistics Act Contents Introduction 3 Safety and Security at Cornell Tech 3 Preparation of the Annual Security Report 4 Annual Fire Safety Report 5 Reporting Crime and Requesting Assistance 5 Missing Students 7 Access Control and Building Security 7 Emergency Notifications 8 Campus Safety and Crime Prevention Outreach Programs 9 Alcohol and Drug Use 10 Weapons Prohibition on Campus 11 Sexual Violence 11 Sexual Assault, Domestic Violence, Intimate Partner Violence, and Stalking 11 Seeking Medical Help 14 Reporting the Incident 14 Adjudication of a Complaint under Policy 6.4 15 Procedure for Formal Complaint Against Students 17 Procedure for Formal Complaint Against Employees 18 Privacy and Confidentiality 19 Resources for Victims 20 Prevention and Awareness Education 21 Sexual Offender Notice 23 Reporting Hate Crimes and Bias Incidents 23 Campus Code and Grievance Procedures 24 Office of the Judicial Administrator 24 Sanctions & Remedies Under Campus Code of Conduct 25 Grievance Procedures 26 Related University Policies 26 Crime Statistics 29 2020 Annual Security Report 2 Cornell Tech – 2 West Loop Rd, New York, New York Cornell Tech Introduction Cornell Tech produces pioneering leaders and technologies for the digital age. Cornell Tech brings together like-minded faculty, business leaders, tech entrepreneurs, and students in a catalytic environment to produce visionary ideas grounded in significant needs that will reinvent the way we live. It is also home to the Joan & Irwin Jacobs Technion-Cornell Institute, which embodies the academic partnership between the Technion-Israel Institute of Technology and Cornell University on the New York City campus. -

Cornell Tech COVID-19 Reopening Safety Plan July 2020
Cornell Tech COVID-19 Reopening Safety Plan July 2020 EXECUTIVE SUMMARY In response to the COVID-19 global pandemic, on March 13, 2020, Cornell Tech swiftly shifted its operations to a remote / virtual environment. In accordance with public health officials’ guidance and recommendations, all academic instruction was migrated to online platforms, staff remote work contingencies were implemented, and all non-essential operations were suspended. Strict guidelines were enacted to safely support the necessary personnel remaining on campus to sustain essential campus functions. As the New York State (NYS) COVID-19 infection rate continues to decline, the NYS Governor’s Office has published a guide for reopening businesses and economic activity. The State has identified seven (7) benchmarks necessary for reopening by region and established four (4) phases of reopening. The full report can be viewed at: https://www.governor.ny.gov/sites/governor.ny.gov/files/atoms/files/NYForwardReopeningGuide.pdf Currently, education is part of the businesses or sectors eligible for reopening during phase IV. However, higher education research and higher education administration have been included in phases I & II, respectively. On June 8th, the New York City (NYC) region met the aforementioned benchmarks and entered phase I, on June 22nd it entered phase II, and on July 20th it entered phase IV. Cornell Tech is preparing this plan to enable the eventual safe return of faculty, staff, students, and visitors to the campus. To the extent possible, given its geographic and infection rate disparities, Cornell Tech will coordinate its reopening strategy with Cornell University to ensure compliance with overall university policies. -

INDUSTRY ADVISORY GROUP Annual Meeting November 3, 2016 Weiss/Manfredi | New U.S
INDUSTRY ADVISORY GROUP ANNUAL MEETING November 3, 2016 Weiss/Manfredi | New U.S. Embassy in New Delhi, India AGENDA AGENDA AGENDA 2:00 OPENING REMARKS Lydia Muniz 2:15 INDUSTRY PARTICIPATION Thomas Mitchell 2:30 ON THE BOARDS PRESENTATION Casey Jones 3:00 NEW U.S EMBASSY PROJECT IN NEW DELHI, INDIA INTRODUCTION Manpreet Singh Anand DEPUTY ASSISTANT SECRETARY, BUREAU OF SOUTH AND CENTRAL ASIAN AFFAIRS PRESENTATION Weiss/Manfredi Architecture/Landscape/Urbanism Marion Weiss CO-FOUNDER & DESIGN PARTNER Michael A. Manfredi CO-FOUNDER & DESIGN PARTNER Patrick Armacost SENIOR PROJECT MANAGER Weiss/Manfredi is a New York City-based multidisciplinary design practice known for the dynamic integration of architecture, landscape, infrastructure, and art. The firm’s award-winning projects, including the Seattle Art Museum: Olympic Sculpture Park, the Center for Nanotechnology at the University of Pennsylvania, the Barnard College Diana Center, and the Brooklyn Botanic Garden Visitor Center, exemplify the potential of architecture and landscape design to transform public space. The firm is currently working on the design of a corporate co-location building for Cornell Tech’s groundbreaking new campus on Roosevelt Island in New York City. The firm’s distinct vision has been recognized with an Academy Award for Architecture from the American Academy of Arts and Letters, Harvard university’s International V.R. Green Prize for Urban Design, and a Gold Medal of Honor from the American Institute of Architects. Their work has been published extensively and exhibited at the Museum of Modern Art, the Solomon R. Guggenheim Museum, the National Building Museum, the Essen Design Centre in Germany, the Louvre, and the Venice Architecture Biennale. -
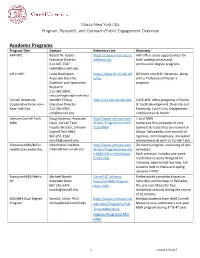
Academic Programs Program Title Contact Reference Link Overview AAP NYC Robert W
Ithaca-New York City Program, Research, and Outreach/Public Engagement Overview Academic Programs Program Title Contact Reference Link Overview AAP NYC Robert W. Balder https://aap.cornell.edu/ac AAP offers study opportunities for Executive Director ademics/nyc both undergraduate and 212-497-7597 professional degree programs. [email protected] ILR in NYC Linda Barrington https://www.ilr.cornell.ed ILR hosts nine NYC initiatives, along Associate Dean for u/nyc with a Professional Master’s Outreach and Sponsored program. Research 212-340-2849 [email protected] Cornell University Jennifer Tiffany http://nyc.cce.cornell.edu CUCE-NYC offers programs in Family Cooperative Extension – Executive Director & Youth development, Diversity and New York City 212-340-2905 Parenting, Youth Civic Engagement, [email protected] and Nutrition & Health. Johnson Cornell Tech Doug Stayman, Associate http://www.johnson.corn 1 year MBA. MBA Dean, Cornell Tech ell.edu/Programs/Cornell- Immersive first semester of core Faculty director, Johnson Tech-MBA business & leadership coursework in Cornell Tech MBA Ithaca, followed by nine months of 607-255-1122 rigorous, interdisciplinary, innovative [email protected] entrepreneurial work at Cornell Tech. Executive MBA/MS in Information mailbox http://www.johnson.corn 20-month program, consisting of two Healthcare Leadership [email protected] ell.edu/Programs/Executiv semesters. e-MBA-MS-in-Healthcare- Each semester includes one-week Leadership residential sessions designed for intensive, experiential learning. Fall sessions held in Ithaca and spring sessions in NYC. Executive MBA Metro Michael Nowlis Cornell SC Johnson: Professionals complete classes on NY Associate Dean Executive MBA Program Saturdays and Sundays in Palisades, 607-255-6425 Metro NYC NY, and visit Ithaca for four [email protected] residential sessions during the course of 22 months. -

April 17, 2020: Coronavirus (Covid-19) Special Report
APRIL 17, 2020: CORONAVIRUS (COVID-19) SPECIAL REPORT Dear Neighbor, This week, we delivered vital Personal Protective Equipment (PPE) including masks, gloves, gowns, and 3-D printed face shields from Cornell Tech students to Coler Hospital on Roosevelt Island to protect its workers and vulnerable patients. On the Upper East Side, we delivered meals to senior citizens through Isaacs Center. With a shortage of volunteers, the center is seeking additional volunteers to support homebound seniors who would otherwise go without food and nutrition in a pandemic. Sign-up with our office to volunteer! We sent a letter with the Offices of Manhattan Borough President Gale Brewer and Senator Serrano to Dr. Katz, President of the Health and Hospitals Corporation to ask for information on the housing of COVID positive patients at the hospital and to request testing for long-term residents of Coler. Additionally, we requested the guidelines for contacting the loved ones of “persons of interest” who are isolated and when they are moved to ICU. We understand that this pandemic has thrown the entire system into a “war” footing, but we must be vigilant to protect the people who call Coler home. The statewide total of confirmed COVID-19 cases is 222,284 across our state with 123,146 cases in New York City. We are advised to continue to "PAUSE" for the health of ourselves and others until May 15. Further, the Governor issued an Executive Order, effective 8pm this evening, requiring all people in New York to wear a mask or face covering when out in public, especially in situations where social distancing cannot be maintained.