Cybercrime in the Deep Web Black Hat EU, Amsterdam 2015
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

UC Santa Barbara UC Santa Barbara Electronic Theses and Dissertations
UC Santa Barbara UC Santa Barbara Electronic Theses and Dissertations Title A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz Permalink https://escholarship.org/uc/item/6w76f8x7 Author Swift, Kathy Publication Date 2017 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA Santa Barbara A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Education by Kathleen Anne Swift Committee in charge: Professor Richard Duran, Chair Professor Diana Arya Professor William Robinson September 2017 The dissertation of Kathleen Anne Swift is approved. ................................................................................................................................ Diana Arya ................................................................................................................................ William Robinson ................................................................................................................................ Richard Duran, Committee Chair June 2017 A Web of Extended Metaphors in the Guerilla Open Access Manifesto of Aaron Swartz Copyright © 2017 by Kathleen Anne Swift iii ACKNOWLEDGEMENTS I would like to thank the members of my committee for their advice and patience as I worked on gathering and analyzing the copious amounts of research necessary to -

Cryptography
56 Protecting Information With Cryptography Chapter by Peter Reiher (UCLA) 56.1 Introduction In previous chapters, we’ve discussed clarifying your security goals, determining your security policies, using authentication mechanisms to identify principals, and using access control mechanisms to enforce poli- cies concerning which principals can access which computer resources in which ways. While we identified a number of shortcomings and prob- lems inherent in all of these elements of securing your system, if we re- gard those topics as covered, what’s left for the operating system to worry about, from a security perspective? Why isn’t that everything? There are a number of reasons why we need more. Of particular im- portance: not everything is controlled by the operating system. But per- haps you respond, you told me the operating system is all-powerful! Not really. It has substantial control over a limited domain – the hardware on which it runs, using the interfaces of which it is given control. It has no real control over what happens on other machines, nor what happens if one of its pieces of hardware is accessed via some mechanism outside the operating system’s control. But how can we expect the operating system to protect something when the system does not itself control access to that resource? The an- swer is to prepare the resource for trouble in advance. In essence, we assume that we are going to lose the data, or that an opponent will try to alter it improperly. And we take steps to ensure that such actions don’t cause us problems. -

How to Get the Daily Stormer Be Found on the Next Page
# # Publishing online In print because since 2013, offline Stormer the (((internet))) & Tor since 2017. is censorship! The most censored publication in history Vol. 97 Daily Stormer ☦ Sunday Edition 23–30 Jun 2019 What is the Stormer? No matter which browser you choose, please continue to use Daily Stormer is the largest news publication focused on it to visit the sites you normally do. By blocking ads and track- racism and anti-Semitism in human history. We are signifi- ers your everyday browsing experience will be better and you cantly larger by readership than many of the top 50 newspa- will be denying income to the various corporate entities that pers of the United States. The Tampa Tribune, Columbus Dis- have participated in the censorship campaign against the Daily patch, Oklahoman, Virginian-Pilot, and Arkansas Democrat- Stormer. Gazette are all smaller than this publication by current read- Also, by using the Tor-based browsers, you’ll prevent any- ership. All of these have dozens to hundreds of employees one from the government to antifa from using your browsing and buildings of their own. All of their employees make more habits to persecute you. This will become increasingly rele- than anyone at the Daily Stormer. We manage to deliver im- vant in the years to come. pact greater than anyone in this niche on a budget so small you How to support the Daily Stormer wouldn’t believe. The Daily Stormer is 100% reader-supported. We do what Despite censorship on a historically unique scale, and The we do because we are attempting to preserve Western Civiliza- Daily Stormer becoming the most censored publication in his- tion. -

An Evolving Threat the Deep Web
8 An Evolving Threat The Deep Web Learning Objectives distribute 1. Explain the differences between the deep web and darknets.or 2. Understand how the darknets are accessed. 3. Discuss the hidden wiki and how it is useful to criminals. 4. Understand the anonymity offered by the deep web. 5. Discuss the legal issues associated withpost, use of the deep web and the darknets. The action aimed to stop the sale, distribution and promotion of illegal and harmful items, including weapons and drugs, which were being sold on online ‘dark’ marketplaces. Operation Onymous, coordinated by Europol’s Europeancopy, Cybercrime Centre (EC3), the FBI, the U.S. Immigration and Customs Enforcement (ICE), Homeland Security Investigations (HSI) and Eurojust, resulted in 17 arrests of vendors andnot administrators running these online marketplaces and more than 410 hidden services being taken down. In addition, bitcoins worth approximately USD 1 million, EUR 180,000 Do in cash, drugs, gold and silver were seized. —Europol, 20141 143 Copyright ©2018 by SAGE Publications, Inc. This work may not be reproduced or distributed in any form or by any means without express written permission of the publisher. 144 Cyberspace, Cybersecurity, and Cybercrime THINK ABOUT IT 8.1 Surface Web and Deep Web Google, Facebook, and any website you can What Would You Do? find via traditional search engines (Internet Explorer, Chrome, Firefox, etc.) are all located 1. The deep web offers users an anonym- on the surface web. It is likely that when you ity that the surface web cannot provide. use the Internet for research and/or social What would you do if you knew that purposes you are using the surface web. -

Cyber Laws for Dark Web: an Analysis of the Range of Crimes and the Level of Effectiveness of Law Over It
An Open Access Journal from The Law Brigade Publishers 1 CYBER LAWS FOR DARK WEB: AN ANALYSIS OF THE RANGE OF CRIMES AND THE LEVEL OF EFFECTIVENESS OF LAW OVER IT Written by Sanidhya Mahendra 5th Year B.A.LL.B.(Hons.) Student, Uttaranchal University, Dehradun, India ABSTRACT In the 21st century, when we say “The future is now”, we mean that everything is possible, everything is accessible, everything is on our fingertips. This is because our entire world today is connected and controlled by the internet. This world wide connectivity offers us everything to use, like from shopping to travelling, from eating to feeding, and even for connecting to the people virtually, however the internet is not just limited to the millions of websites available for our daily use, rather it is far beyond that. We just access the 5 per cent of the entire internet and the rest of it is what may be a true horror for those who have been affected by it. This domain of internet is popularly known as the Dark Web. In this article the author has described the disturbing truths of the Dark Web. The author has described about its history and has pointed out the usage of the same by the criminals. The author further discusses the types of crime that are committed behind the veil of internet. The article thereafter defines the remedies available in various laws of India for the victims of cyber crimes. The author concludes the article with suggestions of improvement in the present laws. KEYWORDS: Dark Net, Dark web, Deep Web, TOR, Onion, Cryptocurrency, privacy, anonymous, VPN, ARPANET, Crawlers, Silk Road, Phishing INTRODUCTION Today the most significant invention is the invention Internet, and it has taken the eyes of all the generation in one go. -

PCI Assessment Evidence of PCI Policy Compliance
PCI Assessment Evidence of PCI Policy Compliance CONFIDENTIALITY NOTE: The information contained in this report document is for the Prepared for: exclusive use of the client specified above and may contain confidential, privileged and non-disclosable information. If the recipient of this report is not the client or Prospect or Customer addressee, such recipient is strictly prohibited from reading, photocopying, distributing or otherwise using this report or its contents in any way. Prepared by: Your Company Name Evidence of PCI Policy Compliance PCI ASSESSMENT Table of Contents 1 - Overview 1.1 - Security Officer 1.2 - Overall Risk 2 - PCI DSS Evidence of Compliance 2.1 - Install and maintain firewall to protect cardholder data 2.1.1.1 - Requirements for firewall at each Internet connections and between DMZ and internal network zone 2.1.1.2 - Business justification for use of all services, protocols and ports allowed 2.1.2 - Build firewall and router configurations that restrict connections between untrusted networks and the cardholder data environment 2.1.2.1 - Restrict inbound and outbound to that which is necessary for the cardholder data environment 2.1.2.3 - Do not allow unauthorized outbound traffic from the cardholder data environment to the Internet 2.1.2.4 - Implement stateful inspection (also known as dynamic packet filtering) 2.1.2.5 - Do not allow unauthorized outbound traffic from the cardholder data environment to the Internet 2.2 - Prohibition of vendor-supplied default password for systems and security parameters 2.2.1 -
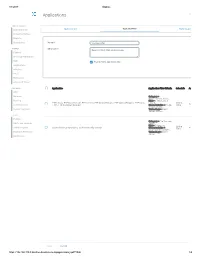
Applications Log Viewer
4/1/2017 Sophos Applications Log Viewer MONITOR & ANALYZE Control Center Application List Application Filter Traffic Shaping Default Current Activities Reports Diagnostics Name * Mike App Filter PROTECT Description Based on Block filter avoidance apps Firewall Intrusion Prevention Web Enable Micro App Discovery Applications Wireless Email Web Server Advanced Threat CONFIGURE Application Application Filter Criteria Schedule Action VPN Network Category = Infrastructure, Netw... Routing Risk = 1-Very Low, 2- FTPS-Data, FTP-DataTransfer, FTP-Control, FTP Delete Request, FTP Upload Request, FTP Base, Low, 4... All the Allow Authentication FTPS, FTP Download Request Characteristics = Prone Time to misuse, Tra... System Services Technology = Client Server, Netwo... SYSTEM Profiles Category = File Transfer, Hosts and Services Confe... Risk = 3-Medium Administration All the TeamViewer Conferencing, TeamViewer FileTransfer Characteristics = Time Allow Excessive Bandwidth,... Backup & Firmware Technology = Client Server Certificates Save Cancel https://192.168.110.3:4444/webconsole/webpages/index.jsp#71826 1/4 4/1/2017 Sophos Application Application Filter Criteria Schedule Action Applications Log Viewer Facebook Applications, Docstoc Website, Facebook Plugin, MySpace Website, MySpace.cn Website, Twitter Website, Facebook Website, Bebo Website, Classmates Website, LinkedIN Compose Webmail, Digg Web Login, Flickr Website, Flickr Web Upload, Friendfeed Web Login, MONITOR & ANALYZE Hootsuite Web Login, Friendster Web Login, Hi5 Website, Facebook Video -

Self-Encrypting Deception: Weaknesses in the Encryption of Solid State Drives
Self-encrypting deception: weaknesses in the encryption of solid state drives Carlo Meijer Bernard van Gastel Institute for Computing and Information Sciences School of Computer Science Radboud University Nijmegen Open University of the Netherlands [email protected] and Institute for Computing and Information Sciences Radboud University Nijmegen Bernard.vanGastel@{ou.nl,ru.nl} Abstract—We have analyzed the hardware full-disk encryption full-disk encryption. Full-disk encryption software, especially of several solid state drives (SSDs) by reverse engineering their those integrated in modern operating systems, may decide to firmware. These drives were produced by three manufacturers rely solely on hardware encryption in case it detects support between 2014 and 2018, and are both internal models using the SATA and NVMe interfaces (in a M.2 or 2.5" traditional form by the storage device. In case the decision is made to rely on factor) and external models using the USB interface. hardware encryption, typically software encryption is disabled. In theory, the security guarantees offered by hardware encryp- As a primary example, BitLocker, the full-disk encryption tion are similar to or better than software implementations. In software built into Microsoft Windows, switches off software reality, we found that many models using hardware encryption encryption and completely relies on hardware encryption by have critical security weaknesses due to specification, design, and implementation issues. For many models, these security default if the drive advertises support. weaknesses allow for complete recovery of the data without Contribution. This paper evaluates both internal and external knowledge of any secret (such as the password). -

Cryptographic Control Standard, Version
Nuclear Regulatory Commission Office of the Chief Information Officer Computer Security Standard Office Instruction: OCIO-CS-STD-2009 Office Instruction Title: Cryptographic Control Standard Revision Number: 2.0 Issuance: Date of last signature below Effective Date: October 1, 2017 Primary Contacts: Kathy Lyons-Burke, Senior Level Advisor for Information Security Responsible Organization: OCIO Summary of Changes: OCIO-CS-STD-2009, “Cryptographic Control Standard,” provides the minimum security requirements that must be applied to the Nuclear Regulatory Commission (NRC) systems which utilize cryptographic algorithms, protocols, and cryptographic modules to provide secure communication services. This update is based on the latest versions of the National Institute of Standards and Technology (NIST) Guidance and Federal Information Processing Standards (FIPS) publications, Committee on National Security System (CNSS) issuances, and National Security Agency (NSA) requirements. Training: Upon request ADAMS Accession No.: ML17024A095 Approvals Primary Office Owner Office of the Chief Information Officer Signature Date Enterprise Security Kathy Lyons-Burke 09/26/17 Architecture Working Group Chair CIO David Nelson /RA/ 09/26/17 CISO Jonathan Feibus 09/26/17 OCIO-CS-STD-2009 Page i TABLE OF CONTENTS 1 PURPOSE ............................................................................................................................. 1 2 INTRODUCTION .................................................................................................................. -

How to Use Encryption and Privacy Tools to Evade Corporate Espionage
How to use Encryption and Privacy Tools to Evade Corporate Espionage An ICIT White Paper Institute for Critical Infrastructure Technology August 2015 NOTICE: The recommendations contained in this white paper are not intended as standards for federal agencies or the legislative community, nor as replacements for enterprise-wide security strategies, frameworks and technologies. This white paper is written primarily for individuals (i.e. lawyers, CEOs, investment bankers, etc.) who are high risk targets of corporate espionage attacks. The information contained within this briefing is to be used for legal purposes only. ICIT does not condone the application of these strategies for illegal activity. Before using any of these strategies the reader is advised to consult an encryption professional. ICIT shall not be liable for the outcomes of any of the applications used by the reader that are mentioned in this brief. This document is for information purposes only. It is imperative that the reader hires skilled professionals for their cybersecurity needs. The Institute is available to provide encryption and privacy training to protect your organization’s sensitive data. To learn more about this offering, contact information can be found on page 41 of this brief. Not long ago it was speculated that the leading world economic and political powers were engaged in a cyber arms race; that the world is witnessing a cyber resource buildup of Cold War proportions. The implied threat in that assessment is close, but it misses the mark by at least half. The threat is much greater than you can imagine. We have passed the escalation phase and have engaged directly into full confrontation in the cyberwar. -

A Framework for Identifying Host-Based Artifacts in Dark Web Investigations
Dakota State University Beadle Scholar Masters Theses & Doctoral Dissertations Fall 11-2020 A Framework for Identifying Host-based Artifacts in Dark Web Investigations Arica Kulm Dakota State University Follow this and additional works at: https://scholar.dsu.edu/theses Part of the Databases and Information Systems Commons, Information Security Commons, and the Systems Architecture Commons Recommended Citation Kulm, Arica, "A Framework for Identifying Host-based Artifacts in Dark Web Investigations" (2020). Masters Theses & Doctoral Dissertations. 357. https://scholar.dsu.edu/theses/357 This Dissertation is brought to you for free and open access by Beadle Scholar. It has been accepted for inclusion in Masters Theses & Doctoral Dissertations by an authorized administrator of Beadle Scholar. For more information, please contact [email protected]. A FRAMEWORK FOR IDENTIFYING HOST-BASED ARTIFACTS IN DARK WEB INVESTIGATIONS A dissertation submitted to Dakota State University in partial fulfillment of the requirements for the degree of Doctor of Philosophy in Cyber Defense November 2020 By Arica Kulm Dissertation Committee: Dr. Ashley Podhradsky Dr. Kevin Streff Dr. Omar El-Gayar Cynthia Hetherington Trevor Jones ii DISSERTATION APPROVAL FORM This dissertation is approved as a credible and independent investigation by a candidate for the Doctor of Philosophy in Cyber Defense degree and is acceptable for meeting the dissertation requirements for this degree. Acceptance of this dissertation does not imply that the conclusions reached by the candidate are necessarily the conclusions of the major department or university. Student Name: Arica Kulm Dissertation Title: A Framework for Identifying Host-based Artifacts in Dark Web Investigations Dissertation Chair: Date: 11/12/20 Committee member: Date: 11/12/2020 Committee member: Date: Committee member: Date: Committee member: Date: iii ACKNOWLEDGMENT First, I would like to thank Dr. -

Introduction Points
Introduction Points Ahmia.fi - Clearnet search engine for Tor Hidden Services (allows you to add new sites to its database) TORLINKS Directory for .onion sites, moderated. Core.onion - Simple onion bootstrapping Deepsearch - Another search engine. DuckDuckGo - A Hidden Service that searches the clearnet. TORCH - Tor Search Engine. Claims to index around 1.1 Million pages. Welcome, We've been expecting you! - Links to basic encryption guides. Onion Mail - SMTP/IMAP/POP3. ***@onionmail.in address. URSSMail - Anonymous and, most important, SECURE! Located in 3 different servers from across the globe. Hidden Wiki Mirror - Good mirror of the Hidden Wiki, in the case of downtime. Where's pedophilia? I WANT IT! Keep calm and see this. Enter at your own risk. Site with gore content is well below. Discover it! Financial Services Currencies, banks, money markets, clearing houses, exchangers. The Green Machine Forum type marketplace for CCs, Paypals, etc.... Some very good vendors here!!!! Paypal-Coins - Buy a paypal account and receive the balance in your bitcoin wallet. Acrimonious2 - Oldest escrowprovider in onionland. BitBond - 5% return per week on Bitcoin Bonds. OnionBC Anonymous Bitcoin eWallet, mixing service and Escrow system. Nice site with many features. The PaypalDome Live Paypal accounts with good balances - buy some, and fix your financial situation for awhile. EasyCoin - Bitcoin Wallet with free Bitcoin Mixer. WeBuyBitcoins - Sell your Bitcoins for Cash (USD), ACH, WU/MG, LR, PayPal and more. Cheap Euros - 20€ Counterfeit bills. Unbeatable prices!! OnionWallet - Anonymous Bitcoin Wallet and Bitcoin Laundry. BestPal BestPal is your Best Pal, if you need money fast. Sells stolen PP accounts.