Entity Resolution and Location Disambiguation in the Ancient Hindu Temples Domain Using Web Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Entity Resolution and Location Disambiguation in the Ancient Hindu Temples Domain Using Web Data
Entity Resolution and Location Disambiguation in the Ancient Hindu Temples Domain using Web Data Ayush Maheshwari, Vishwajeet Kumar, Ganesh Ramakrishnan Indian Institute of Technology Bombay Mumbai, India ayushm,vishwajeet,ganesh @cse.iitb.ac.in { } J. Saketha Nath ∗ IIT Hyderabad Hyderabad, India [email protected] Abstract We present a system for resolving entities and disambiguating locations based on publicly avail- able web data in the domain of ancient Hindu Temples. Scarce, unstructured information poses a challenge to Entity Resolution(ER) and snippet ranking. Additionally, because the same set of en- tities may be associated with multiple locations, Location Disambiguation(LD) is a problem. The mentions and descriptions of temples1 exist in the order of hundreds of thousands, with such data generated by various users in various forms Figure 1: Sample descriptions (posts) from YouTube such as text (Wikipedia pages), videos (YouTube videos on various temples. Irrelevant posts are videos), blogs, etc. We demonstrate an integrated snippets which cannot be associated with any temple, approach using a combination of grammar rules for parsing and unsupervised (clustering) algo- whereas the relevant posts are about Giriraj Dham, rithms to resolve entity and locations with high Ammachiveedu Muhurthi, Shivalokathyagar and confidence. A demo of our system is accessible Gorakhnath temples respectively. at tinyurl.com/templedemos2. Our system is open source and available on GitHub3. a significant fraction of such data ( 60%), is generated ∼ by the crowd over social multi-media platforms such as 1 Introduction YouTube and Twitter. This data is ridden with subjective Entity Resolution (ER) is the process of associating evaluations, opinions, and speculations. -

Secondary Indian Culture and Heritage
Culture: An Introduction MODULE - I Understanding Culture Notes 1 CULTURE: AN INTRODUCTION he English word ‘Culture’ is derived from the Latin term ‘cult or cultus’ meaning tilling, or cultivating or refining and worship. In sum it means cultivating and refining Ta thing to such an extent that its end product evokes our admiration and respect. This is practically the same as ‘Sanskriti’ of the Sanskrit language. The term ‘Sanskriti’ has been derived from the root ‘Kri (to do) of Sanskrit language. Three words came from this root ‘Kri; prakriti’ (basic matter or condition), ‘Sanskriti’ (refined matter or condition) and ‘vikriti’ (modified or decayed matter or condition) when ‘prakriti’ or a raw material is refined it becomes ‘Sanskriti’ and when broken or damaged it becomes ‘vikriti’. OBJECTIVES After studying this lesson you will be able to: understand the concept and meaning of culture; establish the relationship between culture and civilization; Establish the link between culture and heritage; discuss the role and impact of culture in human life. 1.1 CONCEPT OF CULTURE Culture is a way of life. The food you eat, the clothes you wear, the language you speak in and the God you worship all are aspects of culture. In very simple terms, we can say that culture is the embodiment of the way in which we think and do things. It is also the things Indian Culture and Heritage Secondary Course 1 MODULE - I Culture: An Introduction Understanding Culture that we have inherited as members of society. All the achievements of human beings as members of social groups can be called culture. -

Amarnath Yatra - Helicopter
Amarnath Yatra - Helicopter Starting From :Rs.:16999 Per Person 4 Days / 3 Nights Kashmir .......... Package Description Amarnath Yatra - Helicopter Srinagar is a proud part of the Kashmir Valley, which is aptly known as ' Paradise on Earth.' Surrounded by the majestic Himalayas, serene lakes, and splendid gardens, this picturesque paradise looks so stunning that you might mistake it for a painting. The thrilling shikhara rides take you to another world. This strikingly colorful city will amaze you with its unique culture and attractions. Despite the infamous communal tensions, strikes, and protests, the city continues to be one of the most famous tourist destinations in India. The Dal Lake is undoubtedly the most popular attraction in Srinagar. The presence of numerous beautiful houseboats has made the city earn its moniker ' Venice of the East.' The Mughal Gardens, Chashma Shahi, Pari Mahal, Nishat Bagh and many such marvels, boast of stunning Persian architecture. The city also houses ancient religious places, such as Hazratbal Copyright © www.makeyourticket.com Shrine, Jamia Masjid, Shankaracharya Temple and Kheer Bhawani Temple. A perfect way to conclude your visit would be to indulge in shopping at one of the numerous markets in Srinagar such as Lal Chowk, Residency Road, Polo View, Badshah Chowk and many more Twisting undulations, vibrant flower blooms, pine-fringed hillocks and the outstanding backdrop of Western Himalayas make Gulmarg a paradisiacal place to tread in. Rightly termed as the ' Meadow of Flowers,' this erstwhile summer resort of British India is a place to experience the prodigious splendidness of nature. The spanking pulchritude of this extraordinary snowscape attracts visitors from all around the world, year-round. -

Srinagar Located in the Heart of the Kashmir
Srinagar Located in the heart of the Kashmir Valley, which is called `Paradise on Earth`, Srinagar`s landscape is interspersed with greenery, lakes and hillocks. The city is spread out along the banks of the Jhelum River and is famous for its surrounding natural beauty and postcard tourist spots. The two parts of the city are connected by nine bridges. The Hari Parbat and the Shankar Acharya hills lie on either side of the city. Srinagar has a complex cultural fabric. The many historical constructions and places of worship are long-standing evidences of the historical unity of Srinagar despite the many diverse religious denominations and sects established in the valley since ancient times. There are many Hindu temples that are more than 1000 years old as well as age-old mosques that are landmarks of Srinagar. Also, numerous gurudwaras and monasteries can be found in many places throughout the city. UNESCO has recognised some of these famous buildings of the city as heritage sites. Some of the famous temples are Shankaracharya Temple, Martand Sun Temple, Kheer Bhavani Temple, Pandrethan Temple, etc. The Hazratbal shrine, Dal Lake, Wullar Lake, etc. are some prominent attractions of the destination. Srinagar is also a place for trekking and hiking. The most popular trekking route from Srinagar is to the sacred Amarnath cave. An excursion can be taken to Pahalgam and the Dachigam National Park. Another significant attraction of Srinagar is the Tulip Festival, which is organised annually from April 5 to 15 every year. Held at the Indira Gandhi Memorial Tulip Garden, located at the foothills of the Zabarwan Mountains, the entire garden comes alive with the colourful display of more than 70 varieties of tulips. -

Page1final.Qxd (Page 2)
daily Follow us: Daily Excelsior JAMMU, MONDAY, AUGUST 9, 2021 REGD. NO. JK-71/21-23 Vol No. 57 12 Pages ` 5.00 ExcelsiorRNI No. 28547/65 No. 219 NIA searches 56 premises of Jamaat in 14 J&K distts JeI cadre charged with motivating Kashmiri youth to indulge in disruptive activities Doc, Govt teacher, Retd teachers 4 former heads also raided Biggest ever crackdown among those raided in Jammu against JeI in Kashmir Sanjeev Pargal *Funds raised by outfit Fayaz Bukhari JAMMU, Aug 8: The National channelized to HM, LeT Investigation Agency (NIA) today SRINAGAR, Aug 8: The National Investigation Agency (NIA) today carried conducted raids at 56 locations spread over 14 districts of Jammu and Kashmir on out the biggest ever crackdown in Kashmir against Jamat-e-Islami leaders in a ter- residences, premises and other locations of proscribed Jamaat-e-Islami (JeI) leaders ror funding case. and activists following reports that despite ban imposed on the organization its Four former heads of the activists were indulging in collection of donations which were being used for violent banned religious organization and secessionist activities and were motivating youth were among those raided in *Watch video on of Kashmir to indulge in disruptions. Kashmir. www.excelsiornews.com Following raids, the NIA detained district president The raids were conducted this of Jamaat-e-Islami for Kishtwar and recovered large morning after several NIA teams quantity of incriminating documents, electronic devices and mobile telephones from other arrived in Srinagar for the last 10 places which were raided during the day. At all the places, the NIA teams were joined in days and they had booked around Surrounded with lush green hills and clouds hovering over the sky, a view of Bhaderwah the operation by CRPF and Jammu and Kashmir Police to ensure that there was no unto- 140 vehicles for carrying out town on Sunday. -

Amarnath Yatra
AMARNATH YATRA Yatris entering the shrine TEXT: SHYAMOLA KHANNA t was the month of July and I was standing on the threshold, gazing at the deity of Shri Amarnathji inside the cave at 14,000 ft, cold, wet and not a little FINDING Ibewildered. And then the chants of “Har Har Mahadev!” rang out! I looked back and saw the band of Shiva worshippers calling out to their Lord, saffron bands around their heads and dressed in the barest CrowdsMY in front FAITH minimum, a loin cloth and another orange of the shrine bit draped around their shoulders – men, women and young adolescents all calling out with the same fervor! The ambient temperature would have been between five and six degrees centigrade and yet these people were not cold! So is this what the burning fire of faith was all about? While I watched, I also noticed that the people were generally in the age group of fifty and sixty. There were younger ones and definitely even older ones too—they 8 Miles to go before they sleep a lone sadhu trudges on were the ones who were clad in loads of again. By the time March comes around seeps back into the mountains and flows woolens, shawls, sweaters, caps and woolen and the first nargis (daffodil) starts out in places through the mountainside. socks (probably a couple of pairs!), in the flowering through the snow blankets, then Some of this water flows into Amarnath vanyaprastha or sanyas stages of life. you can start stepping out again. Slowly, the cave and over a period of two to three poppies and irises start to flower and entire weeks, forms an ice mound in the cave, due The Cave hillsides become covered in red, yellow and to the freezing of water drops that fall from When winter sets in the Jammu and blue. -

Kashmir Architecture
Kashmir Architecture April 27, 2021 Talking of Kashmir, everyone heaps praise on its postcard- worthy scenery, its houseboats and apple trees, but not much is known about its syncretic traditions of sacred architecture. The region has long been a melting pot of cultural practices that include Hinduism, Buddhism and Islam. In news: Kashmir’s sacred architecture combines Hindu, Buddhist and Islamic influences Placing it in syllabus: Foreign Affairs Dimensions Ancient Temple Architecture Medieval Architecture Unique Features Content: Ancient Temple Architecture: A network of Hindu Temples spread across the length and breadth of the Kashmir Valley during the ancient period. Some of the important ones among them include: Shankaracharya Temple, Payar Temple, Martand Temple, Buniyar Temples, Laduv Temple, Avantisvara Temple, Avantiswami Temple, Taper Temple, Manasbal Temple, Mamal Temple, Devsar Temple, Garur Temple, Sugandesha Temple, Narag Temples, Narasthan Temple etc The ancient Hindu temples of Kashmir possess some unique features in many aspects. Ancient temple architecture of Kashmir was greatly influenced by the art of these foreign countries very much. Kashmir since antiquity has been functioning as a cultural bridge between India on the one hand and central Asia, China and Tibet This is a reason that the great ancient Kashmiri architects created a distinct temple architectural style which possesses its own features but affected by both Indian as well as Central Asian art styles The European art also imposed some influence on it because of close contact of Kashmir with Gandhara Kingdom in the early centuries. The ancient Kashmiri temple architecture is greatly affected by many foreign art styles like Bactro-Gandhra, Graeco- Egyptian and Tibetan elements than the art styles of other parts of ancient India. -
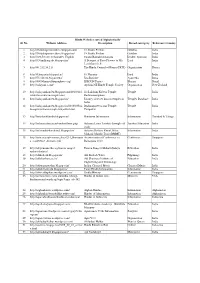
1.Hindu Websites Sorted Alphabetically
Hindu Websites sorted Alphabetically Sl. No. Website Address Description Broad catergory Reference Country 1 http://18shaktipeetasofdevi.blogspot.com/ 18 Shakti Peethas Goddess India 2 http://18shaktipeetasofdevi.blogspot.in/ 18 Shakti Peethas Goddess India 3 http://199.59.148.11/Gurudev_English Swami Ramakrishnanada Leader- Spiritual India 4 http://330milliongods.blogspot.in/ A Bouquet of Rose Flowers to My Lord India Lord Ganesh Ji 5 http://41.212.34.21/ The Hindu Council of Kenya (HCK) Organisation Kenya 6 http://63nayanar.blogspot.in/ 63 Nayanar Lord India 7 http://75.126.84.8/ayurveda/ Jiva Institute Ayurveda India 8 http://8000drumsoftheprophecy.org/ ISKCON Payers Bhajan Brazil 9 http://aalayam.co.nz/ Ayalam NZ Hindu Temple Society Organisation New Zealand 10 http://aalayamkanden.blogspot.com/2010/11/s Sri Lakshmi Kubera Temple, Temple India ri-lakshmi-kubera-temple.html Rathinamangalam 11 http://aalayamkanden.blogspot.in/ Journey of lesser known temples in Temples Database India India 12 http://aalayamkanden.blogspot.in/2010/10/bra Brahmapureeswarar Temple, Temple India hmapureeswarar-temple-tirupattur.html Tirupattur 13 http://accidentalhindu.blogspot.in/ Hinduism Information Information Trinidad & Tobago 14 http://acharya.iitm.ac.in/sanskrit/tutor.php Acharya Learn Sanskrit through self Sanskrit Education India study 15 http://acharyakishorekunal.blogspot.in/ Acharya Kishore Kunal, Bihar Information India Mahavir Mandir Trust (BMMT) 16 http://acm.org.sg/resource_docs/214_Ramayan An international Conference on Conference Singapore -

5 Nights / 6 Days
Kashmir Package 5 Nights / 6 Days • Hotel Category: 3 Star • All Inclusions Srinagar - HB Srinagar – Local Sightseeing Srinagar - Pahalgam Pahalgam to Gulmarg Gulmarg – Srinagar Departure All transfers and sightseeing’s on Private Basis • Hotel Details Srinagar Houseboat Category: 3 Star Includes: Breakfast and Lunch or Breakfast and Dinner Srinagar Hotel Category: 3 Star Includes: Breakfast and Lunch or Breakfast and Dinner Pahalgam Hotel Category: 3 Star Includes: Breakfast and Lunch or Breakfast and Dinner Gulmarg Hotel Category: 3 Star Includes: Breakfast and Lunch or Breakfast and Dinner • Price Breakup Hotel with inclusions as mentioned. For more packages please visit http://www.ittkashmir.co.in • Sightseeing • 5 Sightseeing activities Srinagar - Local Sightseeing Srinagar to Pahalgam Srinagar - Srinagar Houseboat Pahalgam to Gulmarg Gulmarg – Srinagar • Taxes 3.65% Govt service tax •Itinerary • 5 Nights 6 Days Day 1 Schedule Arrival & welcome Srinagar - Srinagar Houseboat Transfer to a jetty, from where you will be transferred to the houseboat on a shikara. These are usually moored at the edges of the Dal Lake and Nageen lakes. Some of the houseboats there were built in the early 1900s, and are still being rented out to tourists. These houseboats are made of wood, and usually have intricately carved wood paneling. The houseboats are of different sizes, some having up to three bedrooms apart from a living room and kitchen. Many tourists are attracted to Srinagar by the charm of staying on a houseboat, which provides the unique experience of living on the water in a cedar-paneled elegant bedroom, with all the conveniences of a luxury hotel. -

A Study of the Pilgrimage Tourism of Kashmir
1 A STUDY OF THE PILGRIMAGE TOURISM OF KASHMIR ABSTRACT THESIS SUBMITTED FOR THE AWARD OF THE DEGREE OF doctor of $f)tlQSfopf)j^ IN COMMERCE By SHAHNAWAZ AHMAD DAR UNDER THE SUPERVISION OF DR. S.M. IMAMUL HAQUE READER DEPARTMENT OF COMMERCE ALIGARH MUSLIM UNIVERSITY AllGARH (INDIA) 2008 ABSTRACT Tourism is a phenomenon which was a strong motive behind the movement of people in ancient time and is still the strongest motive for causing the movement of millions of people across the regional, national and international boundaries. Travel which initially started with the intention to fulfil the religious/spiritual/pilgrimage needs of a person is again becoming the largest motivator to undertake travel. India recorded 4.43 million international tourist arrivals and over 400 million domestic tourists in 2006. In the same year, Indian tourism generated US$ 6 billion foreign exchange and contributed 5.83% to the GDP. Tourism to India means the third largest foreign exchange earner and one of the largest employment generating industry. India is gifted by a miniature India in the form of State of Jammu and Kashmir. The State comprises three divisions namely, Jammu, Kashmir and Ladakh. Each division has its own unique climate, geographical setting, religious beliefs, food pattern, art, culture and traditions and is full of tourism assets which are also distinctive. Jammu division is a Hindu dominant area. It has innumerable temples spread through out its length and breadth. Jammu is also called as ''City of Temples'". Ladakh, also called as the ''Land of Lamas", is a mountainous country. It is dominated by Buddhist population. -
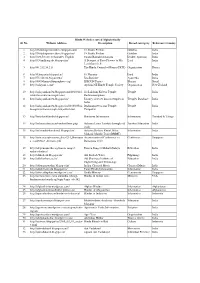
Hindu Websites Sorted Alphabetically Sl
Hindu Websites sorted Alphabetically Sl. No. Website Address Description Broad catergory Reference Country 1 http://18shaktipeetasofdevi.blogspot.com/ 18 Shakti Peethas Goddess India 2 http://18shaktipeetasofdevi.blogspot.in/ 18 Shakti Peethas Goddess India 3 http://199.59.148.11/Gurudev_English Swami Ramakrishnanada Leader- Spiritual India 4 http://330milliongods.blogspot.in/ A Bouquet of Rose Flowers to My Lord India Lord Ganesh Ji 5 http://41.212.34.21/ The Hindu Council of Kenya (HCK) Organisation Kenya 6 http://63nayanar.blogspot.in/ 63 Nayanar Lord India 7 http://75.126.84.8/ayurveda/ Jiva Institute Ayurveda India 8 http://8000drumsoftheprophecy.org/ ISKCON Payers Bhajan Brazil 9 http://aalayam.co.nz/ Ayalam NZ Hindu Temple Society Organisation New Zealand 10 http://aalayamkanden.blogspot.com/2010/11/s Sri Lakshmi Kubera Temple, Temple India ri-lakshmi-kubera-temple.html Rathinamangalam 11 http://aalayamkanden.blogspot.in/ Journey of lesser known temples in Temples Database India India 12 http://aalayamkanden.blogspot.in/2010/10/bra Brahmapureeswarar Temple, Temple India hmapureeswarar-temple-tirupattur.html Tirupattur 13 http://accidentalhindu.blogspot.in/ Hinduism Information Information Trinidad & Tobago 14 http://acharya.iitm.ac.in/sanskrit/tutor.php Acharya Learn Sanskrit through self Sanskrit Education India study 15 http://acharyakishorekunal.blogspot.in/ Acharya Kishore Kunal, Bihar Information India Mahavir Mandir Trust (BMMT) 16 http://acm.org.sg/resource_docs/214_Ramayan An international Conference on Conference Singapore -

Starting from Rs. 6500 (Per Person Twin Sharing)
Starting From Rs. 6500 (Per Person twin sharing) PACKAGE NAME : MATA VAISHNO DEVI - KURUKSHETRA TOUR PRICE INCLUDE Hotel,All Meals,Sightseeing Day : 1 Delhi Dep. 5:00pm Night Journey Day : 2 Katra Arr. 8:00am (Rest for 1hr ) (14 km trekking) Mata Vaishno Devi Temple & Back Katra Night Halt SIGHTSEEING Vaishno Devi Mandir, Vaishno Devi Mandir, Vaishno Devi Mandir, Vaishno Devi Mandir Day : 3 Katra to Srinagar Dep. 7:00am Srinagar - Arr. 7:00pm Night Halt Day : 4 Srinagar Sightseeing Dep. 6:00am Shalimar Garden, Nishat Bagh, Dal Lake, Sri Shankaracharya Temple Night Halt SIGHTSEEING Shalimar Bagh, Shalimar Bagh, Shalimar Bagh, Shalimar Bagh, Nishat Bagh, Nishat Bagh, Nishat Bagh, Nishat Bagh, Dal Lake, Dal Lake, Dal Lake, Dal Lake, Shankaracharya Temple, Shankaracharya Temple, Shankaracharya Temple, Shankaracharya Temple Day : 5 Srinagar Srinagar to Gulmarg Sightseeing & Back to Srinagar Night Halt Day : 6 Srinagar to Pahalgam Srinagar - Dep.6:00am Pahalgam - Arr.9:00am & Sightseeing Dep.3:00pm Kud / Katra - Arr.10:00pm Night Halt Day : 7 Amritsar Kud / Katra - Dep.6:00am Amritsar - Arr.11:00am Golden Temple, Jalianwalan Bagh & Wagha Border Night Halt SIGHTSEEING Golden Temple, Golden Temple, Golden Temple, Golden Temple, Jallianwala Bagh, Jallianwala Bagh, Jallianwala Bagh, Jallianwala Bagh, Wagah Border, Wagah Border, Wagah Border, Wagah Border Day : 8 Amritsar to Kurukshetra Amritsar - Dep.6:00am Kurukshetra - Arr.1:00am & Sightseeing Dep.5:00pm New Delhi - Arr.10:00pm INCLUSIONS Ac Transportation, Non-Ac room accommodation from day 2 to day 6 & Ac room accommodation on day 7 with vegetarian food only. Every Monday & Friday. EXCLUSIONS Pilgrims can book helicopter tickets online from katra to mata vaishno devi temple & back in advance at www.maavaishnodevi.org TERMS AND CONDITIONS 1.