Genome-Wide Interrogation of Human Cancers Identifies EGLN1 Dependency in Clear Cell Ovarian Cancers
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Hypoxia and Oxygen-Sensing Signaling in Gene Regulation and Cancer Progression
International Journal of Molecular Sciences Review Hypoxia and Oxygen-Sensing Signaling in Gene Regulation and Cancer Progression Guang Yang, Rachel Shi and Qing Zhang * Department of Pathology, University of Texas Southwestern Medical Center, Dallas, TX 75390, USA; [email protected] (G.Y.); [email protected] (R.S.) * Correspondence: [email protected]; Tel.: +1-214-645-4671 Received: 6 October 2020; Accepted: 29 October 2020; Published: 31 October 2020 Abstract: Oxygen homeostasis regulation is the most fundamental cellular process for adjusting physiological oxygen variations, and its irregularity leads to various human diseases, including cancer. Hypoxia is closely associated with cancer development, and hypoxia/oxygen-sensing signaling plays critical roles in the modulation of cancer progression. The key molecules of the hypoxia/oxygen-sensing signaling include the transcriptional regulator hypoxia-inducible factor (HIF) which widely controls oxygen responsive genes, the central members of the 2-oxoglutarate (2-OG)-dependent dioxygenases, such as prolyl hydroxylase (PHD or EglN), and an E3 ubiquitin ligase component for HIF degeneration called von Hippel–Lindau (encoding protein pVHL). In this review, we summarize the current knowledge about the canonical hypoxia signaling, HIF transcription factors, and pVHL. In addition, the role of 2-OG-dependent enzymes, such as DNA/RNA-modifying enzymes, JmjC domain-containing enzymes, and prolyl hydroxylases, in gene regulation of cancer progression, is specifically reviewed. We also discuss the therapeutic advancement of targeting hypoxia and oxygen sensing pathways in cancer. Keywords: hypoxia; PHDs; TETs; JmjCs; HIFs 1. Introduction Molecular oxygen serves as a co-factor in many biochemical processes and is fundamental for aerobic organisms to maintain intracellular ATP levels [1,2]. -

Mutant IDH, (R)-2-Hydroxyglutarate, and Cancer
Downloaded from genesdev.cshlp.org on October 1, 2021 - Published by Cold Spring Harbor Laboratory Press REVIEW What a difference a hydroxyl makes: mutant IDH, (R)-2-hydroxyglutarate, and cancer Julie-Aurore Losman1 and William G. Kaelin Jr.1,2,3 1Department of Medical Oncology, Dana-Farber Cancer Institute, Brigham and Women’s Hospital, Harvard Medical School, Boston, Massachusetts 02215, USA; 2Howard Hughes Medical Institute, Chevy Chase, Maryland 20815, USA Mutations in metabolic enzymes, including isocitrate whether altered cellular metabolism is a cause of cancer dehydrogenase 1 (IDH1) and IDH2, in cancer strongly or merely an adaptive response of cancer cells in the face implicate altered metabolism in tumorigenesis. IDH1 of accelerated cell proliferation is still a topic of some and IDH2 catalyze the interconversion of isocitrate and debate. 2-oxoglutarate (2OG). 2OG is a TCA cycle intermediate The recent identification of cancer-associated muta- and an essential cofactor for many enzymes, including tions in three metabolic enzymes suggests that altered JmjC domain-containing histone demethylases, TET cellular metabolism can indeed be a cause of some 5-methylcytosine hydroxylases, and EglN prolyl-4-hydrox- cancers (Pollard et al. 2003; King et al. 2006; Raimundo ylases. Cancer-associated IDH mutations alter the enzymes et al. 2011). Two of these enzymes, fumarate hydratase such that they reduce 2OG to the structurally similar (FH) and succinate dehydrogenase (SDH), are bone fide metabolite (R)-2-hydroxyglutarate [(R)-2HG]. Here we tumor suppressors, and loss-of-function mutations in FH review what is known about the molecular mechanisms and SDH have been identified in various cancers, in- of transformation by mutant IDH and discuss their im- cluding renal cell carcinomas and paragangliomas. -

Biological and Translational Insights of Mutant IDH1/2 in Glioma
Neurosurg Focus 34 (2):E2, 2013 ©AANS, 2013 From genomics to the clinic: biological and translational insights of mutant IDH1/2 in glioma GAVIN P. DUNN, M.D., PH.D.,1 OVIDIU C. ANDRONESI, M.D., PH.D.,2 AND DANIEL P. CAHILL, M.D., PH.D.1 Departments of 1Neurosurgery and 2Radiology, Massachusetts General Hospital, Harvard Medical School, Boston, Massachusetts The characterization of the genomic alterations across all human cancers is changing the way that malignant disease is defined and treated. This paradigm is extending to glioma, where the discovery of recurrent mutations in the isocitrate dehydrogenase 1 (IDH1) gene has shed new light on the molecular landscape in glioma and other IDH- mutant cancers. The IDH1 mutations are present in the vast majority of low-grade gliomas and secondary glioblas- tomas. Rapidly emerging work on the consequences of mutant IDH1 protein expression suggests that its neomorphic enzymatic activity catalyzing the production of the oncometabolite 2-hydroxyglutarate influences a range of cellular programs that affect the epigenome, transcriptional programs, hypoxia-inducible factor biology, and development. In the brief time since its discovery, knowledge of the IDH mutation status has had significant translational implica- tions, and diagnostic tools are being used to monitor its expression and function. The concept of IDH1-mutant versus IDH1-wild type will become a critical early distinction in diagnostic and treatment algorithms. (http://thejns.org/doi/abs/10.3171/2012.12.FOCUS12355) KEY WORDS • isocitrate dehydrogenase 1 • isocitrate dehydrogenase 2 • glioblastoma • low-grade glioma • magnetic resonance spectroscopy HE comprehensive taxonomic encyclopedia of the significant because there are specific inhibitors that target genetic alterations underlying all cancers is rapidly their expressed proteins and lead to dramatic clinical re- becoming widely available.61,85,91 To date, this mo- sponse in patients with these cancers. -

NATURAL KILLER CELLS, HYPOXIA, and EPIGENETIC REGULATION of HEMOCHORIAL PLACENTATION by Damayanti Chakraborty Submitted to the G
NATURAL KILLER CELLS, HYPOXIA, AND EPIGENETIC REGULATION OF HEMOCHORIAL PLACENTATION BY Damayanti Chakraborty Submitted to the graduate degree program in Pathology and Laboratory Medicine and the Graduate Faculty of the University of Kansas in partial fulfillment ofthe requirements for the degree of Doctor of Philosophy. ________________________________ Chair: Michael J. Soares, Ph.D. ________________________________ Jay Vivian, Ph.D. ________________________________ Patrick Fields, Ph.D. ________________________________ Soumen Paul, Ph.D. ________________________________ Michael Wolfe, Ph.D. ________________________________ Adam J. Krieg, Ph.D. Date Defended: 04/01/2013 The Dissertation Committee for Damayanti Chakraborty certifies that this is the approved version of the following dissertation: NATURAL KILLER CELLS, HYPOXIA, AND EPIGENETIC REGULATION OF HEMOCHORIAL PLACENTATION ________________________________ Chair: Michael J. Soares, Ph.D. Date approved: 04/01/2013 ii ABSTRACT During the establishment of pregnancy, uterine stromal cells differentiate into decidual cells and recruit natural killer (NK) cells. These NK cells are characterized by low cytotoxicity and distinct cytokine production. In rodent as well as in human pregnancy, the uterine NK cells peak in number around mid-gestation after which they decline. NK cells associate with uterine spiral arteries and are implicated in pregnancy associated vascular remodeling processes and potentially in modulating trophoblast invasion. Failure of trophoblast invasion and vascular remodeling has been shown to be associated with pathological conditions like preeclampsia syndrome, hypertension in mother and/or fetal growth restriction. We hypothesize that NK cells fundamentally contribute to the organization of the placentation site. In order to study the in vivo role of NK cells during pregnancy, gestation stage- specific NK cell depletion was performed in rats using anti asialo GM1 antibodies. -

An Enhanced Chemopreventive Effect of Methyl Donor S-Adenosylmethionine in Combination with 25-Hydroxyvitamin D in Blocking Mammary Tumor Growth and Metastasis
Bone Research www.nature.com/boneres ARTICLE OPEN An enhanced chemopreventive effect of methyl donor S-adenosylmethionine in combination with 25-hydroxyvitamin D in blocking mammary tumor growth and metastasis Niaz Mahmood1, Ani Arakelian1, William J. Muller2, Moshe Szyf3 and Shafaat A. Rabbani1 Therapeutic targeting of metastatic breast cancer still remains a challenge as the tumor cells are highly heterogenous and exploit multiple pathways for their growth and metastatic spread that cannot always be targeted by a single-agent monotherapy regimen. Therefore, a rational approach through simultaneous targeting of several pathways may provide a better anti-cancer therapeutic effect. We tested this hypothesis using a combination of two nutraceutical agents S-adenosylmethionine (SAM) and Vitamin D (Vit. D) prohormone [25-hydroxyvitamin D; ‘25(OH)D’] that are individually known to exert distinct changes in the expression of genes involved in tumor growth and metastasis. Our results show that both SAM and 25(OH)D monotherapy significantly reduced proliferation and clonogenic survival of a panel of breast cancer cell lines in vitro and inhibited tumor growth, lung metastasis, and breast tumor cell colonization to the skeleton in vivo. However, these effects were significantly more pronounced in the combination setting. RNA-Sequencing revealed that the transcriptomic footprint on key cancer-related signaling pathways is broader in the combination setting than any of the monotherapies. Furthermore, comparison of the differentially expressed genes from our transcriptome analyses with publicly available cancer-related dataset demonstrated that the combination treatment 1234567890();,: upregulates genes from immune-related pathways that are otherwise downregulated in bone metastasis in vivo. -

Electronic Supplementary Material (ESI) for Metallomics
Electronic Supplementary Material (ESI) for Metallomics. This journal is © The Royal Society of Chemistry 2018 Uniprot Entry name Gene names Protein names Predicted Pattern Number of Iron role EC number Subcellular Membrane Involvement in disease Gene ontology (biological process) Id iron ions location associated 1 P46952 3HAO_HUMAN HAAO 3-hydroxyanthranilate 3,4- H47-E53-H91 1 Fe cation Catalytic 1.13.11.6 Cytoplasm No NAD biosynthetic process [GO:0009435]; neuron cellular homeostasis dioxygenase (EC 1.13.11.6) (3- [GO:0070050]; quinolinate biosynthetic process [GO:0019805]; response to hydroxyanthranilate oxygenase) cadmium ion [GO:0046686]; response to zinc ion [GO:0010043]; tryptophan (3-HAO) (3-hydroxyanthranilic catabolic process [GO:0006569] acid dioxygenase) (HAD) 2 O00767 ACOD_HUMAN SCD Acyl-CoA desaturase (EC H120-H125-H157-H161; 2 Fe cations Catalytic 1.14.19.1 Endoplasmic Yes long-chain fatty-acyl-CoA biosynthetic process [GO:0035338]; unsaturated fatty 1.14.19.1) (Delta(9)-desaturase) H160-H269-H298-H302 reticulum acid biosynthetic process [GO:0006636] (Delta-9 desaturase) (Fatty acid desaturase) (Stearoyl-CoA desaturase) (hSCD1) 3 Q6ZNF0 ACP7_HUMAN ACP7 PAPL PAPL1 Acid phosphatase type 7 (EC D141-D170-Y173-H335 1 Fe cation Catalytic 3.1.3.2 Extracellular No 3.1.3.2) (Purple acid space phosphatase long form) 4 Q96SZ5 AEDO_HUMAN ADO C10orf22 2-aminoethanethiol dioxygenase H112-H114-H193 1 Fe cation Catalytic 1.13.11.19 Unknown No oxidation-reduction process [GO:0055114]; sulfur amino acid catabolic process (EC 1.13.11.19) (Cysteamine -

Downloaded from the UCSC PRO-Seq Library Preparation and Sequencing
ARTICLE https://doi.org/10.1038/s41467-021-21687-2 OPEN Multi-omics analysis reveals contextual tumor suppressive and oncogenic gene modules within the acute hypoxic response ✉ ✉ Zdenek Andrysik1,2, Heather Bender1,2, Matthew D. Galbraith 1,2 & Joaquin M. Espinosa 1,2,3 Cellular adaptation to hypoxia is a hallmark of cancer, but the relative contribution of hypoxia- inducible factors (HIFs) versus other oxygen sensors to tumorigenesis is unclear. We employ 1234567890():,; a multi-omics pipeline including measurements of nascent RNA to characterize transcrip- tional changes upon acute hypoxia. We identify an immediate early transcriptional response that is strongly dependent on HIF1A and the kinase activity of its cofactor CDK8, includes indirect repression of MYC targets, and is highly conserved across cancer types. HIF1A drives this acute response via conserved high-occupancy enhancers. Genetic screen data indicates that, in normoxia, HIF1A displays strong cell-autonomous tumor suppressive effects through a gene module mediating mTOR inhibition. Conversely, in advanced malignancies, expression of a module of HIF1A targets involved in collagen remodeling is associated with poor prog- nosis across diverse cancer types. In this work, we provide a valuable resource for investi- gating context-dependent roles of HIF1A and its targets in cancer biology. 1 Department of Pharmacology, School of Medicine, University of Colorado Anschutz Medical Campus, Aurora, CO, USA. 2 Linda Crnic Institute for Down Syndrome, School of Medicine, University -
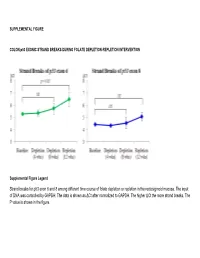
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

The Role of the Oxygen-Sensing Prolyl-4-Hydroxylase Enzyme Phd2 in Tumor Formation
Zurich Open Repository and Archive University of Zurich Main Library Strickhofstrasse 39 CH-8057 Zurich www.zora.uzh.ch Year: 2010 The role of the oxygen-sensing prolyl-4-hydroxylase enzyme phd2 in tumor formation Bordoli, Mattia R Posted at the Zurich Open Repository and Archive, University of Zurich ZORA URL: https://doi.org/10.5167/uzh-44755 Dissertation Originally published at: Bordoli, Mattia R. The role of the oxygen-sensing prolyl-4-hydroxylase enzyme phd2 in tumor formation. 2010, University of Zurich, Faculty of Science. The Role of the Oxygen-Sensing Prolyl-4-Hydroxylase Enzyme PHD2 in Tumor Formation ___________________________________________________________________ Dissertation zur Erlangung der naturwissenschaftlichen Doktorwürde (Dr.sc.nat.) vorgelegt der Mathematisch-naturwissenschaftlichen Fakultät der Universität Zürich von Mattia Renato Bordoli von Muggio TI Promotionskomitee Prof. Dr. Roland H. Wenger (Vorsitz) Dr. Gieri Camenisch (Leitung der Dissertation) Prof. Dr. Dario Neri PD Dr. Lubor Borsig Zürich, 2010 This doctoral thesis has been performed under the supervision of Prof. Dr. Roland H. Wenger and Dr. Gieri Camenisch at the Institute of Physiology and Zürich Center for Integrative Human Physiology (ZIHP), University of Zürich, CH-8057 Zürich, Switzerland. -i- TABLE OF CONTENTS Table of contents 1 ABBREVIATIONS ..............................................................................................1 2 ZUSAMMENFASSUNG......................................................................................3 -

Original Article Association of EGLN1 and EGLN3 Single-Nucleotide Polymorphisms with Chronic Obstructive Pulmonary Disease Risk in a Chinese Population
Int J Clin Exp Med 2017;10(7):10866-10873 www.ijcem.com /ISSN:1940-5901/IJCEM0046332 Original Article Association of EGLN1 and EGLN3 single-nucleotide polymorphisms with chronic obstructive pulmonary disease risk in a Chinese population Si Fang*, Jinfan Qiu*, Huapeng Yu, Huizhen Fan, Xiping Wu, Zekui Fang, Qixiao Shen, Shuyu Chen Department of Respiration, Zhujiang Hospital, Southern Medical University, Guangzhou, China. *Equal contribu- tors. Received December 11, 2016; Accepted March 31, 2017; Epub July 15, 2017; Published July 30, 2017 Abstract: Hypoxia is implicated in the process of chronic inflammation, which is the characteristic pathogenesis of COPD (chronic obstructive pulmonary disease). EGLNs (EglN prolyl hydroxylase) that connect oxygen sensing to the activation of HIF-1 (hypoxia inducible factor-1) have been proven to play a role in the development of COPD. The ob- jective of this study was to explore the role of EGLN1 and EGLN3 SNPs (single-nucleotide polymorphisms) in suscep- tibility and development of COPD in a Chinese cohort. Seven SNPs were chosen from two genes (EGLN1 and EGLN3) in 217 cases and 447 controls. The relationship between SNPs and COPD risk was analyzed by using genetic model analysis. Among the seven SNPs, rs11156819 in EGLN3 exhibited a significant association with COPD risk with an OR of 1.392 (95% CI=1.085-1.787, P=0.009). In the log-additive model, the minor allele T of rs11156819 in EGLN3 significantly increased the risk of COPD (OR=1.58, 95% CI=1.14-2.19,P =0.006) after adjusting for gender, age and smoking status. -

UCLA Electronic Theses and Dissertations
UCLA UCLA Electronic Theses and Dissertations Title A Liquid Chromatography-Mass Spectrometry Platform for Identifying Protein Targets of Small-Molecule Binding Relevant to Disease and Metabolism Permalink https://escholarship.org/uc/item/8pn170t7 Author O'Brien Johnson, Reid Publication Date 2018 Peer reviewed|Thesis/dissertation eScholarship.org Powered by the California Digital Library University of California UNIVERSITY OF CALIFORNIA Los Angeles A Liquid Chromatography-Mass Spectrometry Platform for Identifying Protein Targets of Small-Molecule Binding Relevant to Disease and Metabolism A dissertation submitted in partial satisfaction of the requirements for the degree Doctor of Philosophy in Biochemistry and Molecular Biology by Reid Lee O’Brien Johnson 2018 ABSTRACT OF THE DISSERTATION A Liquid Chromatography-Mass Spectrometry Platform for Identifying Protein Targets of Small-Molecule Binding Relevant to Disease and Metabolism by Reid Lee O’Brien Johnson Doctor of Philosophy in Biochemistry and Molecular Biology University of California, Los Angeles, 2018 Professor Joseph Ambrose Loo, Chair Identifying small-molecule binders to protein targets remains a daunting task due to the huge diversity in compound structure, activity, and mechanisms of action. Affinity- based target identification techniques are limited by the necessity to modify each drug individually (without losing bioactivity), while non-affinity based approaches are dependent on the drug’s ability to induce specific biochemical/cellular readouts. To overcome these limitations, we have developed a high-throughput liquid chromatography- mass spectrometry (LC-MS) platform coupled to a universally applicable target identification approach that analyzes direct small-molecule binding to its protein target(s). DARTS (drug affinity responsive target stability) relies on a well-known phenomenon in which ligand binding causes thermodynamic stabilization of its target protein’s structure such that the protein becomes resistant to a variety of insults, including proteolysis. -

Induction of Therapeutic Tissue Tolerance Foxp3 Expression Is
Downloaded from http://www.jimmunol.org/ by guest on October 2, 2021 is online at: average * The Journal of Immunology , 13 of which you can access for free at: 2012; 189:3947-3956; Prepublished online 17 from submission to initial decision 4 weeks from acceptance to publication September 2012; doi: 10.4049/jimmunol.1200449 http://www.jimmunol.org/content/189/8/3947 Foxp3 Expression Is Required for the Induction of Therapeutic Tissue Tolerance Frederico S. Regateiro, Ye Chen, Adrian R. Kendal, Robert Hilbrands, Elizabeth Adams, Stephen P. Cobbold, Jianbo Ma, Kristian G. Andersen, Alexander G. Betz, Mindy Zhang, Shruti Madhiwalla, Bruce Roberts, Herman Waldmann, Kathleen F. Nolan and Duncan Howie J Immunol cites 35 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription http://www.jimmunol.org/content/suppl/2012/09/17/jimmunol.120044 9.DC1 This article http://www.jimmunol.org/content/189/8/3947.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2012 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of October 2, 2021.