Understanding Users' Satisfaction Towards Public Transit System In
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Lost Childhoods Report
Lost Childhoods A study on platform children and other children in distress in India Prepared by Udita Das Submitted to the Paul Hamlyn Foundation India programme March 2013 1 Contents Contents Background 2 Methodology 5 Research findings 6 Future strategy ideas 34 Appendices I. Interventions on justice for children 36 II. NCPCR: Perspectives on protection of child rights 42 III. Khushboo Jain vs. Ministry of Railways 44 Forward > 2 Lost Childhoods: A study on platform children and other children in distress Background India is home to over 400 million children under 18 years old. These children make up more than 55 per cent of the population. Based on state police records in 2005, the National Human Rights Commission (NHRC) stated that, on average, more than 44,000 children are reported missing in India each year. Around 11,000 of these children remain untraced.1 This number could actually be much higher, as many cases are never reported because the families of these children are from a marginalised background and do not have the ability to report the incident. It is estimated that there are 11 million street children living in India, most of whom live in and around railway stations. In Delhi, Mumbai and Kolkata, approximately 100,000–125,000 street children figure in the lists of missing, runaway, abandoned or trafficked children.2 Without support, these children are at risk of various forms of abuse and a lack of rights that not only denies them a childhood, but also forces them to grow up fast. Approximately 70,000 children arrive on station platforms in India per year. -

India 2020 Crime & Safety Report: Mumbai
India 2020 Crime & Safety Report: Mumbai This is an annual report produced in conjunction with the Regional Security Office at the U.S. Consulate General in Mumbai. OSAC encourages travelers to use this report to gain baseline knowledge of security conditions in India. For more in-depth information, review OSAC’s India-specific webpage for original OSAC reporting, consular messages, and contact information, some of which may be available only to private-sector representatives with an OSAC password. Travel Advisory The current U.S. Department of State Travel Advisory at the date of this report’s publication assesses most of India at Level 2, indicating travelers should exercise increased caution due to crime and terrorism. Some areas have increased risk: do not travel to the state of Jammu and Kashmir (except the eastern Ladakh region and its capital, Leh) due to terrorism and civil unrest; and do not travel to within ten kilometers of the border with Pakistan due to the potential for armed conflict. Review OSAC’s report, Understanding the Consular Travel Advisory System Overall Crime and Safety Situation The Consulate represents the United States in Western India, including the states of Maharashtra, Gujarat, Madhya Pradesh, Chhattisgarh, and Goa. Crime Threats The U.S. Department of State has assessed Mumbai as being a MEDIUM-threat location for crime directed at or affecting official U.S. government. Although it is a city with an estimated population of more than 25 million people, Mumbai remains relatively safe for expatriates. Being involved in a traffic accident remains more probable than being a victim of a crime, provided you practice good personal security. -

Transport in India Transport in the Republic of India Is an Important
Transport in India Transport in the Republic of India is an important part of the nation's economy. Since theeconomic liberalisation of the 1990s, development of infrastructure within the country has progressed at a rapid pace, and today there is a wide variety of modes of transport by land, water and air. However, the relatively low GDP of India has meant that access to these modes of transport has not been uniform. Motor vehicle penetration is low with only 13 million cars on thenation's roads.[1] In addition, only around 10% of Indian households own a motorcycle.[2] At the same time, the Automobile industry in India is rapidly growing with an annual production of over 2.6 million vehicles[3] and vehicle volume is expected to rise greatly in the future.[4] In the interim however, public transport still remains the primary mode of transport for most of the population, and India's public transport systems are among the most heavily utilised in the world.[5] India's rail network is the longest and fourth most heavily used system in the world transporting over 6 billionpassengers and over 350 million tons of freight annually.[5][6] Despite ongoing improvements in the sector, several aspects of the transport sector are still riddled with problems due to outdated infrastructure, lack of investment, corruption and a burgeoning population. The demand for transport infrastructure and services has been rising by around 10% a year[5] with the current infrastructure being unable to meet these growing demands. According to recent estimates by Goldman Sachs, India will need to spend $1.7 Trillion USD on infrastructure projects over the next decade to boost economic growth of which $500 Billion USD is budgeted to be spent during the eleventh Five-year plan. -

A Comparative Analysis of High-Speed Rail Station Development Into Destination and Multi-Use Facilities: the Case of San Jose Diridon
MTI A Comparative Analysis of Funded by U.S. Department of Services Transit Census California of Water 2012 High-Speed Rail Station Transportation and California Department of Transportation Development into Destination and Multi-Use Facilities: The Case of San Jose Diridon MTI ReportMTI 12-02 December 2012 MTI Report 12-75 MINETA TRANSPORTATION INSTITUTE MTI FOUNDER LEAD UNIVERSITY OF MNTRC Hon. Norman Y. Mineta The Mineta Transportation Institute (MTI) was established by Congress in 1991 as part of the Intermodal Surface Transportation MTI/MNTRC BOARD OF TRUSTEES Equity Act (ISTEA) and was reauthorized under the Transportation Equity Act for the 21st century (TEA-21). MTI then successfully competed to be named a Tier 1 Center in 2002 and 2006 in the Safe, Accountable, Flexible, Efficient Transportation Equity Act: A Founder, Honorable Norman Joseph Boardman (Ex-Officio) Diane Woodend Jones (TE 2019) Richard A. White (Ex-Officio) Legacy for Users (SAFETEA-LU). Most recently, MTI successfully competed in the Surface Transportation Extension Act of 2011 to Mineta (Ex-Officio) Chief Executive Officer Principal and Chair of Board Interim President and CEO be named a Tier 1 Transit-Focused University Transportation Center. The Institute is funded by Congress through the United States Secretary (ret.), US Department of Amtrak Lea+Elliot, Inc. American Public Transportation Transportation Association (APTA) Department of Transportation’s Office of the Assistant Secretary for Research and Technology (OST-R), University Transportation Vice Chair -

Locolines Edition 57
DIVISIONAL EXECUTIVE DIVISIONAL SECRETARY: Marc Marotta 0414 897 314 DIVISIONAL PRESIDENT: Terry Sheedy 0417 310 400 DIVISIONAL ASSIST. SECRETARY: Jim Chrysostomou 0404 814 141 DIVISIONAL VICE PRESIDENT: John Marotta 0414 864 702 DIVISIONAL DELEGATES Metropolitan Sub-division: Kevin Duggan 0404 811 589 Paris Jolly 0422 790 624 Pacific National Sub-division: Peter Laux 0417 526 544 Pacific National (ex Freight) Sub-division: James Styles 0427 018 963 Passenger Sub-division: Wayne Hicks 0407 035 282 Judge says train driver breached duty of care . Full article Page 3 JUNE 2013 LOCO LINES Conten ts LLOCOOCO LLINESINES EDITION 57 Marc Marotta—Loco Div Secretary 3 JUNE 2013 Loco Lines is published by the Terry Sheedy—Branch / Div President 8 Locomotive Division of the Australian Rail, Tram & Bus Industry Union – Victorian Branch. See the bottom of this Jim Chrysostomou— Assist. Secretary 10 page for the Locomotive Division’s business address, telephone, e-mail and website Paris Jolly— Metro. Sub-Div Sec. 11 details. Loco Lines is distributed free to all financial members of the Wayne Hicks— V/ Line Pass Report 13 Locomotive Division. Retired Enginemen also receive the magazine for free. It is made available to non-members at a Nelsons Column 14 cost of $20.00 per year. Advertisements offering a specific benefit to Locomotive Signal Sighting Reports 28 Division members are published free of charge. Heritage groups are generally not charged for advertising or tour information. Talkback from Hinch 30 Views or opinions expressed in published contributions to Loco Scholarships 31 Lines are not necessarily those of the Union Office. We also reserve the right to alter or delete text for legal or other Where Is It …? 32 purposes. -

The Urban Rail Development Handbook
DEVELOPMENT THE “ The Urban Rail Development Handbook offers both planners and political decision makers a comprehensive view of one of the largest, if not the largest, investment a city can undertake: an urban rail system. The handbook properly recognizes that urban rail is only one part of a hierarchically integrated transport system, and it provides practical guidance on how urban rail projects can be implemented and operated RAIL URBAN THE URBAN RAIL in a multimodal way that maximizes benefits far beyond mobility. The handbook is a must-read for any person involved in the planning and decision making for an urban rail line.” —Arturo Ardila-Gómez, Global Lead, Urban Mobility and Lead Transport Economist, World Bank DEVELOPMENT “ The Urban Rail Development Handbook tackles the social and technical challenges of planning, designing, financing, procuring, constructing, and operating rail projects in urban areas. It is a great complement HANDBOOK to more technical publications on rail technology, infrastructure, and project delivery. This handbook provides practical advice for delivering urban megaprojects, taking account of their social, institutional, and economic context.” —Martha Lawrence, Lead, Railway Community of Practice and Senior Railway Specialist, World Bank HANDBOOK “ Among the many options a city can consider to improve access to opportunities and mobility, urban rail stands out by its potential impact, as well as its high cost. Getting it right is a complex and multifaceted challenge that this handbook addresses beautifully through an in-depth and practical sharing of hard lessons learned in planning, implementing, and operating such urban rail lines, while ensuring their transformational role for urban development.” —Gerald Ollivier, Lead, Transit-Oriented Development Community of Practice, World Bank “ Public transport, as the backbone of mobility in cities, supports more inclusive communities, economic development, higher standards of living and health, and active lifestyles of inhabitants, while improving air quality and liveability. -

Contents ARROW OUTLETS
1 Contents ARROW OUTLETS .................................................................................................................................. 2 BATA OUTLET ........................................................................................................................................ 9 BENETTON OUTLET ............................................................................................................................. 61 BODY SHOP STORES ............................................................................................................................ 77 BOMBAY STORES ................................................................................................................................. 83 BOTTEGA VENETA OUTLETS ................................................................................................................ 83 CAFE COFFEE DAY ............................................................................................................................... 84 CANALI OUTLETS ............................................................................................................................... 130 COX & KING ....................................................................................................................................... 130 CROMA OUTLETS .............................................................................................................................. 140 EMPORIO ARMANI OUTLETS ............................................................................................................ -

Hospital List
NSP ID Hospital Name Address NSP City NSP State NSP Pin NSP Email NSP STD Chakraborty Multi Speciality Andaman & chakrabortyhospital 9161 Near Dollygunj Junction Diglipur 744202 3192 Hospital Nicobar Islands @gmail.com Jetty Tank Street, H. No. 12-2- srisuryapalakol@g 21577 Sri Surya Nursing Home Palakol Andhra Pradesh 534260 8814 31/2 mail.com H. No. 1-184a, Opp. Head Post drvinodent@yahoo. 12781 Neravati Hospital Nandyal Andhra Pradesh 518501 8514 Office Gandhi Chowk co.in dr.sahadev@yahoo 15106 Gelivi Nursing Home 3-155, Byrmal Street Nandyal Andhra Pradesh 518501 8514 .com Tirupati 3535 Gayatri Hospital 484 & 485, V V Mahal Road Andhra Pradesh 517501 [email protected] 877 Urban 10 - 14 - 576 / 6, Opp. Tirupati russhhospitals@gm 1303 R U S S H Hospital Pvt. Ltd. Municipal Office, Behind Petrol Andhra Pradesh 517501 877 Urban ail.com Bunk Kamineni Institute Of Medical srirish.y@kimsmedi 9238 Sreepuram, Narketpally Nalgonda Andhra Pradesh 508254 8682 Sciences & Hospital calcollege.org 5/1888, Geetha Ashramam 4923 Jaya Vishnu Nursing Home Proddatur Andhra Pradesh 516360 NA 8564 Road, Dist Kaddapa Siddhardha Orthopaedic buddhudu2010@g 6550 Devi Chowk Rajahmundry Andhra Pradesh 533104 883 Hospital mail.com Abhaya Emergency Centre/ abhayaemergency 9578 79-1-4/1, J. N. Road Rajahmundry Andhra Pradesh 533103 883 Sree Hospital @gmail.com # 77-7-7, Seelam Nookaraju info@bollinenihospi 12911 Bollineni Hospitals Rajahmundry Andhra Pradesh 533103 883 Complex Street, Katari Garden tals.com Sai Swetha Mother & Child 29-24-8, Boyapati St. sunkara_rr@yahoo. 8527 Krishna Andhra Pradesh 520002 866 Hospital Suryaraopet co.in srikalinursinghome 9230 Sri Kali Nursing Home 19-9-14, Gurdhar Road Pedana Andhra Pradesh 521366 8672 @gmail.com Dr. -
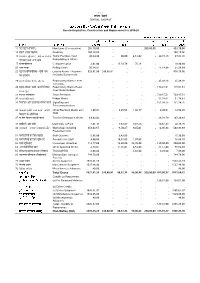
1.1.1 Ú रेलवे Central Railway
1.1.1 मय रेलवे CENTRAL RAILWAY 20192019----2020 के िलए पƗरसंपिēयĪ कƙ खरीद , िनमाϕण और बदलाव Assets-Acquisition, Construction and Replacement for 2019-20 (Figures in thousand of Rupees)(आंकड़े हजार Đ . मĞ) पूंजी पूंजी िनिध मूआिन िविन संिन रारेसंको जोड़ िववरण Particulars Capital CF DRF. DF SF RRSK TOTAL 11 (a ) New Lines (Construction) 203,70,00 .. .. .. 200,00,00 .. 403,70,00 15 ह Doubling 100,10,00 .. .. .. .. .. 100,10,00 16 - G Traffic Facilities-Yard 43,34,99 .. 80,00 4,51,02 .. 39,15,15 87,81,16 G ^ G Remodelling & Others 17 Computerisation 3,01,00 .. 15,14,78 75,16 .. .. 18,90,94 21 Rolling Stock 20,14,91 .. .. .. .. 11,14,98 31,29,89 22 * 4 - Leased Assets - Payment 629,01,09 249,68,91 .. .. .. .. 878,70,00 of Capital Component 29 E G - Road Safety Works-Level .. .. .. .. .. 45,38,28 45,38,28 Crossings. 30 E G -/ Road Safety Works-Road .. .. .. .. .. 179,21,51 179,21,51 Over/Under Bridges. 31 Track Renewals .. .. .. .. .. 739,47,51 739,47,51 32 G Bridge Works .. .. .. .. .. 51,74,61 51,74,61 33 G Signalling and .. .. .. .. .. 151,38,75 151,38,75 Telecommunication 36 ^ G - G Other Electrical Works excl 1,00,01 .. 2,25,56 1,03,77 .. 8,30,01 12,59,35 K TRD 37 G G Traction Distribution Works 69,02,03 .. .. .. .. 38,28,79 107,30,82 41 U Machinery & Plant 4,81,45 .. 7,62,07 7,07,39 . -

For Facilitating Small Sizes of Goods Traffic (Less Than Train Load Traffic)”
CENTRAL RAILWAY MUMABI DIVISION EXPRESSION OF INTEREST “FOR FACILITATING SMALL SIZES OF GOODS TRAFFIC (LESS THAN TRAIN LOAD TRAFFIC)” EOI Notification No.BB/COMM/BDU/2020 Issued By Senior Divisional Commercial Manager Mumbai Division NOTICE FOR EXPRESSION OF INTEREST (EOI) FOR SMALL GOODS TRAFFIC SIZES In order to increase share of Rail Transportation in small size of goods traffic (one wagon and above i.e. 60 tonnes & above), exclusive Business Development Unit has been set up by Mumbai Division / Central Railway. These units have been mandated with interacting with various industries, traders, logistic solution providers and offer suitable rail transportation solutions to facilitate modal shift to rail. Special efforts are being made to run freight trains for carrying small size traffic in covered wagons (BCN, BCNA, BCNHL), Open Wagons (BOX, BOST) & Flat Wagons (BRN, BFR). Thus Mumbai Division / Central Railway commits to providing: 1. Fast transit times. 2. Information on rakes during transit. 3. Competitive rates. The purpose of this EOI is to assess the demand for transportation of small sizes of goods traffic (less than train load) from various goods sheds over Mumbai Division to different parts of India and to design transportation services to meet this demand. Information for Freight Customers : a. Interested freight customers may indicate the details of their transportation requirements (origin, destination, commodity, frequency, volume etc.) in the format in Annexure-A. b. Customers will be allowed to book minimum one wagon (covered / open / flat) which carries approximately 60 tonnes & above of goods. c. Indian Railways Goods Tariff which contains information on various commodities transported by Indian Railways and their class rate is attached as Annexure-B for reference of customers. -

HDIL Dreams - Bhandup West, Mumbai Residential Apartments HDIL Dreams Is One of the Popular Residential Developments in Bhandup West Neighborhood of Mumbai
https://www.propertywala.com/hdil-dreams-mumbai HDIL Dreams - Bhandup West, Mumbai Residential Apartments HDIL Dreams is one of the popular Residential Developments in Bhandup West neighborhood of Mumbai. Project ID : J692119049 Builder: Dheeraj Group Properties: Apartments / Flats, Office Spaces Location: HDIL Dreams, Bhandup West, Mumbai - 400079 (Maharashtra) Completion Date: Jan, 2007 Status: Completed Description Housing Development & Infrastructure Limited (HDIL) has established itself as one of India’s premier real estate development companies, with significant operations in the Mumbai Metropolitan Region. HDIL is a public listed real estate company in India with shares traded on the BSE & NSE Stock Exchanges.As India’s largest slum rehabilitation company, HDIL has been awarded the Mumbai International Airport Slum Rehabilitation project in October 2007, a critical component of the modernization and expansion plan for Mumbai airport and one of the largest urban rehabilitation projects in India. HDIL Dreams is one of the popular Residential Developments in Bhandup West neighborhood of Mumbai. It is among the Completed Projects of HDIL. The landscape is beautiful with spacious 16 Blocks and over 2000 Houses.Project has various modern amenities like Garden, Swimming Pool, Play Area, 24Hr Backup, Security, Intercom, Broadband Internet, Library, Gymnasium, Bank/Atm etc. Location: Bhandup (W), Mumbai Amenities & Specifications: Garden Swimming Pool Play Area 24Hr Backup Security Intercom Broadband Internet Library Gymnasium Bank/Atm. -
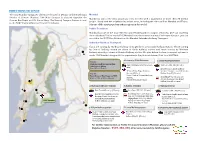
How to Reach TISS: Navigation
DIRECTIONS TO VENUE The two Mumbai Campuses of TISS are located in Deonar in the North-East Mumbai Section of Greater Mumbai. The Main Campus is situated opposite the Mumbai is one of the most populous cities in India with a population of more than 20 million Deonar Bus Depot on V.N. Purav Marg. The Naoroji Campus Annexe is next people. Along with the neighbouring urban areas, including the cities of Navi Mumbai and Thane, to the BARC Hospital Gate on Deonar Farm Road. it is one of the most populous urban regions in the world. Public Transport Mumbai has one of the most efficient and reliable public transport networks. One can travel by Auto-rickshaw/Taxi to reach TISS Mumbai from the nearest stations. For longer distance, you can use either the BEST Bus Network or the Mumbai Suburban Railway Transport. Suburban Railway Transport If you are coming by Harbour Railway Line, get down at Govandi Railway Station. Those coming by Central Railway should get down at Kurla Railway station and those coming by Western Railway should get down at Bandra Railway station. We give below the best transport options to 6 reach TISS Mumbai along with the approximate Bus/Auto-rickshaw/Taxi fare and time. 1. Lokmanya Tilak Terminus 2. DaDar Railway Junction Step S1: From GovanDi Station to TISS Auto-rickshaw Fare: INR 50 (25 Taxi Fare: INR 130 (50 min) Take Auto-rickshaw min) Fare: INR 11 (5 min) Board Train to Kurla Railway Walk to Tilak Nagar Railway Station, Change to Govandi station Step S2: Station (500 m), Follow Step S1 (50 min) From Deonar Bus Depot to TISS Board Train to Govandi Railway Station, Board Bus# 92, 93, 521, 520, Walk to TISS at 200 m (5 min) AC 592 to Deonar Bus Depot 8 Follow Step S1 (30 min) Follow Step S2 (60 min) 3.