The Big Book of Data Science Use Cases a Collection of Technical Blogs, Including Code Samples and Notebooks the BIG BOOK of DATA SCIENCE USE CASES
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

February 26, 2021 Amazon Warehouse Workers In
February 26, 2021 Amazon warehouse workers in Bessemer, Alabama are voting to form a union with the Retail, Wholesale and Department Store Union (RWDSU). We are the writers of feature films and television series. All of our work is done under union contracts whether it appears on Amazon Prime, a different streaming service, or a television network. Unions protect workers with essential rights and benefits. Most importantly, a union gives employees a seat at the table to negotiate fair pay, scheduling and more workplace policies. Deadline Amazon accepts unions for entertainment workers, and we believe warehouse workers deserve the same respect in the workplace. We strongly urge all Amazon warehouse workers in Bessemer to VOTE UNION YES. In solidarity and support, Megan Abbott (DARE ME) Chris Abbott (LITTLE HOUSE ON THE PRAIRIE; CAGNEY AND LACEY; MAGNUM, PI; HIGH SIERRA SEARCH AND RESCUE; DR. QUINN, MEDICINE WOMAN; LEGACY; DIAGNOSIS, MURDER; BOLD AND THE BEAUTIFUL; YOUNG AND THE RESTLESS) Melanie Abdoun (BLACK MOVIE AWARDS; BET ABFF HONORS) John Aboud (HOME ECONOMICS; CLOSE ENOUGH; A FUTILE AND STUPID GESTURE; CHILDRENS HOSPITAL; PENGUINS OF MADAGASCAR; LEVERAGE) Jay Abramowitz (FULL HOUSE; GROWING PAINS; THE HOGAN FAMILY; THE PARKERS) David Abramowitz (HIGHLANDER; MACGYVER; CAGNEY AND LACEY; BUCK JAMES; JAKE AND THE FAT MAN; SPENSER FOR HIRE) Gayle Abrams (FRASIER; GILMORE GIRLS) 1 of 72 Jessica Abrams (WATCH OVER ME; PROFILER; KNOCKING ON DOORS) Kristen Acimovic (THE OPPOSITION WITH JORDAN KLEPPER) Nick Adams (NEW GIRL; BOJACK HORSEMAN; -

As Writers of Film and Television and Members of the Writers Guild Of
July 20, 2021 As writers of film and television and members of the Writers Guild of America, East and Writers Guild of America West, we understand the critical importance of a union contract. We are proud to stand in support of the editorial staff at MSNBC who have chosen to organize with the Writers Guild of America, East. We welcome you to the Guild and the labor movement. We encourage everyone to vote YES in the upcoming election so you can get to the bargaining table to have a say in your future. We work in scripted television and film, including many projects produced by NBC Universal. Through our union membership we have been able to negotiate fair compensation, excellent benefits, and basic fairness at work—all of which are enshrined in our union contract. We are ready to support you in your effort to do the same. We’re all in this together. Vote Union YES! In solidarity and support, Megan Abbott (THE DEUCE) John Aboud (HOME ECONOMICS) Daniel Abraham (THE EXPANSE) David Abramowitz (CAGNEY AND LACEY; HIGHLANDER; DAUGHTER OF THE STREETS) Jay Abramowitz (FULL HOUSE; MR. BELVEDERE; THE PARKERS) Gayle Abrams (FASIER; GILMORE GIRLS; 8 SIMPLE RULES) Kristen Acimovic (THE OPPOSITION WITH JORDAN KLEEPER) Peter Ackerman (THINGS YOU SHOULDN'T SAY PAST MIDNIGHT; ICE AGE; THE AMERICANS) Joan Ackermann (ARLISS) 1 Ilunga Adell (SANFORD & SON; WATCH YOUR MOUTH; MY BROTHER & ME) Dayo Adesokan (SUPERSTORE; YOUNG & HUNGRY; DOWNWARD DOG) Jonathan Adler (THE TONIGHT SHOW STARRING JIMMY FALLON) Erik Agard (THE CHASE) Zaike Airey (SWEET TOOTH) Rory Albanese (THE DAILY SHOW WITH JON STEWART; THE NIGHTLY SHOW WITH LARRY WILMORE) Chris Albers (LATE NIGHT WITH CONAN O'BRIEN; BORGIA) Lisa Albert (MAD MEN; HALT AND CATCH FIRE; UNREAL) Jerome Albrecht (THE LOVE BOAT) Georgianna Aldaco (MIRACLE WORKERS) Robert Alden (STREETWALKIN') Richard Alfieri (SIX DANCE LESSONS IN SIX WEEKS) Stephanie Allain (DEAR WHITE PEOPLE) A.C. -

Our Conspiratorial Cartoon President During Almost Comically
Our Conspiratorial Cartoon President During Almost Comically Consequential Times December 2018, latest revisions June 12, 2020 "What we are before is like a strait, a tricky road, a passage where we need courage and reason. The courage to go on, not to try to turn back; and the reason to use reason; not fear, not jealousy, not envy, but reason. We must steer by reason, and jettison -- because much must go -- by reason." --- John Fowles, The Aristos (1970) I, Dr. Tiffany B. Twain, am convinced that we Americans could easily create a healthier, happier, fairer and more inclusive country that would give us greater cause for hope for a better future, and a country much more secure for its citizens. A main obstacle to this providentially positive potentiality is the strong opposition to such an eminently salubrious status by “conservative” rich people who want our economic and political systems to remain rigged astonishingly generously in their favor, so that they are able to gain an ever increasing monopoly on the profits made through the exploitation of working people and natural resources. A well-informed electorate is a prerequisite for ensuring that a democracy is healthy, and thereby offers all its citizens truly reasonable representation. This simple understanding makes both humorous and viscerally provocative a political cartoon by David Sipress that appeared in New Yorker magazine soon after the 2016 elections. In this cartoon, a woman ruefully observes to her male companion, "My desire to be well-informed is currently at odds with my desire to remain sane." Ha! Tens of millions of Americans find themselves in this predicament today, as the Donald Trump soap opera, crime saga, healthcare treachery, and interlude of authority abuses becomes increasingly dysfunctional, anxiety inducing and deadly -- and as Trump becomes more unhinged, sinisterly authoritarian and threatening to individual liberties, national security and our greatest American values. -

Star Channels, July 15-21
JULY 15 - 21, 2018 staradvertiser.com COLLISION COURSE Loyalties will be challenged as humanity sits on the brink of Earth’s potential extinction. Learn if order can continue to suppress chaos on a new episode of Salvation. Airs Monday, July 16, on CBS Let’s bring over 70 candidates into view. Watch Candidates In Focus on ¶ũe^eh<aZgg^e-2' ?hk\Zg]b]Zm^bg_h%]^[Zm^lZg]_hknfl%oblbmolelo.org/vote JULY 16AUGUST 10 olelo.org MF, 7AM & 7PM | SA & SU, 7AM, 2PM & 7PM ON THE COVER | SALVATION Impending doom Multiple threats plague Armed with this new, time-sensitive informa- narrative. The actress notes that, while “the tion, Darius and Liam head to the Pentagon show is mostly about this impeding asteroid — season 2 of ‘Salvation’ and deliver the news to the Department of the sort of scaring, impending doom of that,” Defense’s deputy secretary, Harris Edwards people are “still living [their lives],” as the truth By K.A. Taylor (Ian Anthony Dale, “Hawaii Five-0”). Harris makes it difficult for people to accept, which TV Media and DOD public affairs press secretary Grace leads them to set out a course of action that Barrows (Jennifer Finnigan, “Tyrant”) have no reveals what’s truly important to them. Now cience fiction is increasingly becoming choice but to let these two skilled scientists that “the public knows” and “the secret is out science fact. The dreams of golden era into a covert operation called Sampson, re- ... people go bananas.” An event such as this Swriters and directors, while perhaps a vealing that the government was already well will no doubt “bring out the best” or to “bring bit exaggerated, are more prevalent now than aware of the threat but had chosen to keep it out the worst [in us],” but ultimately, Finnigan ever before. -

Bottom Line Inside Happy Mother’S Day! 021 •
NEWS Local news and entertainment since 1969 Bottom Line A look at the color Happy Mother’s Day! Inside and sights of local GREATER LAS CRUCES CHAMBER OF COMMERCE • MAY 2021 • WWW.LASCRUCES.ORG TABLE OF CONTENTS A year like no other From the GLCC President premier of “Walking By BRANDI MISQUEZ It’s Mother’s Day..............................2 The pressures of main- A Mom’s 10 Rules for taining a household during the future workforce .......................3 a pandemic are intense on their own. 2020 brought 2021 Annual Chamber additional pressures to Gala Winners ................................4-5 millions of households with parents being tasked with Herb.” to uphold their own work 2021 Annual Chamber responsibilities, while Awards Video ................................6 also ensuring their kids are learning effectively. 2021 LCHBA Parents wanting to instill Casa for a Cause .............................7 some sense of normalcy into their kids’ lives while page 3 New/rewewing upholding these tasks can members ........................................8 simply be summed up by FRIDAY, one word for me: balance. It’s clear that being a par- COURTESY PHOTO MAY ent during COVID-19 times The pandemic changed everything for families like that of Brandi Misquez and Matthew Arguello. GREATER LAS CRUCES has not been an easy feat. 7, 2021 CHAMBER OF COMMERCE From my perspective, this for their virtual school- the Greater Las Cruces walls. It’s been both terrible I Volume 53, Number 19 150 E. LOHMAN AVE. has awarded us a unique ing once the quarantine Chamber of Commerce. and amazing all at the same LAS CRUCES, NM 88001 challenge mixed with a phase was lifted. -
US VERSUS VIRUS Marathon Bombing Wounds Reopened
WEDNESDAY, AUGUST 26, 2020 Marblehead and Swampscott Police rescue child at sea ITEM STAFF REPORT the child until police from Marblehead and Swampscott and Harbormaster patrol boats A 5-year-old girl MARBLEHEAD — A 5-year-old girl who from both communities responded, police said. who was strand- was stranded on a raft in the water off Preston “With an of cer on the beach vectoring the ed on a raft in Beach was rescued by authorities from Mar- rescue boats into the area, the child was res- the water off blehead and Swampscott Tuesday afternoon. cued unharmed and the father who was in Preston Beach Shortly before 3 p.m., police began receiving a separate raft trying to reach her, was also was rescued by numerous emergency calls for a young child picked up,” Marblehead Police said in a Face- authorities from who was alone on an orange raft. The callers book post. Marblehead and relayed that the child was being blown off by Following the rescue, father and child were Swampscott Tues- high winds, according to Marblehead Police. taken to the pier at the Swampscott Fish day afternoon. Adults on shore and the child’s father, who was in a separate raft, tried in vain to reach RESCUE, A5 PHOTO | SWAMPSCOTT POLICE Marathon US bombing VERSUS wounds VIRUS City of Lynn reopened taking steps By Steve Krause ITEM STAFF to address LYNN — Beth Bourgault wasn’t in favor of sentencing Dzhokhar Tsar- COVID naev to death for the 2013 bombing at the Boston Marathon that killed three By Gayla Cawley people and seriously wounded and ITEM STAFF maimed hundreds of others, including LYNN — With numbers herself and her husband. -

February 26, 2021 Amazon Warehouse Workers in Bessemer
February 26, 2021 Amazon warehouse workers in Bessemer, Alabama are voting to form a union with the Retail, Wholesale and Department Store Union (RWDSU). We are the writers of feature films and television series. All of our work is done under union contracts whether it appears on Amazon Prime, a different streaming service, or a television network. Unions protect workers with essential rights and benefits. Most importantly, a union gives employees a seat at the table to negotiate fair pay, scheduling and more workplace policies. Amazon accepts unions for entertainment workers, and we believe warehouse workers deserve the same respect in the workplace. We strongly urge all Amazon warehouse workers in Bessemer to VOTE UNION YES. In solidarity and support, Megan Abbott (DARE ME) Chris Abbott (LITTLE HOUSE ON THE PRAIRIE; CAGNEY AND LACEY; MAGNUM, PI; HIGH SIERRA SEARCH AND RESCUE; DR. QUINN, MEDICINE WOMAN; LEGACY; DIAGNOSIS, MURDER; BOLD AND THE BEAUTIFUL; YOUNG AND THE RESTLESS) Melanie Abdoun (BLACK MOVIE AWARDS; BET ABFF HONORS) John Aboud (HOME ECONOMICS; CLOSE ENOUGH; A FUTILE AND STUPID GESTURE; CHILDRENS HOSPITAL; PENGUINS OF MADAGASCAR; LEVERAGE) Jay Abramowitz (FULL HOUSE; GROWING PAINS; THE HOGAN FAMILY; THE PARKERS) David Abramowitz (HIGHLANDER; MACGYVER; CAGNEY AND LACEY; BUCK JAMES; JAKE AND THE FAT MAN; SPENSER FOR HIRE) Gayle Abrams (FRASIER; GILMORE GIRLS) 1 of 72 Jessica Abrams (WATCH OVER ME; PROFILER; KNOCKING ON DOORS) Kristen Acimovic (THE OPPOSITION WITH JORDAN KLEPPER) Nick Adams (NEW GIRL; BOJACK HORSEMAN; BLACKISH) -
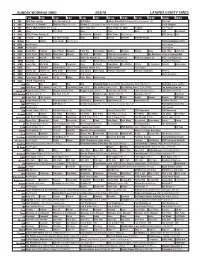
Sunday Morning Grid 2/25/18 Latimes.Com/Tv Times
SUNDAY MORNING GRID 2/25/18 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Face the Nation (N) Bull Riding College Basketball Michigan State at Wisconsin. (N) PGA Golf 4 NBC Today in L.A. Weekend Meet the Press (N) (TVG) Hockey St. Louis Blues at Nashville Predators. (N) Å 2018 Olympics 5 CW KTLA 5 Morning News at 7 (N) Å KTLA News at 9 KTLA 5 News at 10am In Touch Paid Program 7 ABC News This Week News News News Paid NBA Basketball 9 KCAL KCAL 9 News Sunday (N) Joel Osteen Schuller Mike Webb Paid Program REAL-Diego Paid 11 FOX In Touch Paid Fox News Sunday News Weird DIY Sci NASCAR NASCAR Racing 13 MyNet Paid Matter Fred Jordan Paid Program Formosa Betrayed (2009) 18 KSCI Paid Program Paid Program 22 KWHY Paid Program Paid Program 24 KVCR Paint With Painting Joy of Paint Wyland’s Paint This Oil Painting Kitchen Mexican Martha Jazzy Julia Child Chefs Life 28 KCET 1001 Nights 1001 Nights Mixed Nutz Edisons Biz Kid$ Biz Kid$ Pavlo Live in Kastoria Å Joe Bonamassa Live at Carnegie Hall 30 ION Jeremiah Youseff In Touch NCIS: Los Angeles Å NCIS: Los Angeles Å NCIS: Los Angeles Å NCIS: Los Angeles Å 34 KMEX Conexión Paid Program Fútbol Fútbol Mexicano Primera División (N) República Deportiva 40 KTBN James Mac Win Walk Prince Carpenter Jesse In Touch PowerPoint It Is Written Jeffress K. -

Television Academy Awards
2018 Primetime Emmy® Awards Ballot Outstanding Single-Camera Picture Editing For A Drama Series Altered Carbon Force Of Evil February 02, 2018 Tortured by his captor, Kovacs taps into his Envoy training to survive. Ortega springs a surprise on her family for Día de los Muertos. Amy Fleming, Editor The Americans Dead Hand March 28, 2018 In the season 6 premiere of The Americans: it’s autumn, 1987, and as a major arms control summit looms, Elizabeth is pushed to her limits as never before. Philip, meanwhile, has settled into running the newly expanded travel agency – until an unexpected visitor makes a disquieting request. Amanda Pollack, Editor The Americans Start May 30, 2018 In the series finale, the Jennings face a choice that will change their lives forever. Dan Valverde, Editor Being Mary Jane Feeling Seen September 12, 2017 Mary Jane uncovers information about Justin's past that spins their love into a entirely new phase. Kara and Justin go head to head for the executive producer slot; Mary Jane learns that she has to become the deciding vote of choosing between Kara and Justin. Nena Erb, ACE, Editor Berlin Station Right Of Way November 05, 2017 The Station’s sting operation to catch the Far Right in an arms deal goes horribly awry, with Otto Ganz (Thomas Kretschmann) escaping. Meanwhile, Robert (Leland Orser) and Frost (Richard Jenkins) make plans to investigate the money trail behind the PfD’s nefarious dealings. David Ray, Editor Billions Redemption May 27, 2018 Axe explores an unappealing investment at a desperate moment. Taylor makes a personal compromise for business. -

8.12.21 LIB Comedy Announcement FINAL
FOR IMMEDIATE RELEASE August 12, 2021 LIFE IS BEAUTIFUL ANNOUNCES 2021 COMEDY LINEUP The stellar lineup features headlining acts from Sarah Cooper, Sibling Rivalry podcast hosts Bob the Drag Queen and Monét X Change, Ziwe and more LAS VEGAS - Life is Beautiful, Las Vegas’ premier three-day music, art, culinary and comedy festival has announced its full comedy line up for “The Kicker” featuring comedian and best-selling author Sarah Cooper, the hit “Sibling Rivalry” podcast featuring Bob the Drag Queen and Monét X Change, as well as performances from Ziwe, iconic star and executive producer of her self-titled Showtime variety series, Emmy-nominated writer and comedian Sam Jay and “Crazy Rich Asians” actor Nico Santos. The laugh-packed lineup of top and upcoming standup comedians, dazzling drag queens, acclaimed podcast shows and more adds an additional layer to the festival’s already impressive collection of musical acts and experiences. Open to all festival goers, The Kicker stage is located at Venue Vegas and will feature stand-up, variety shows, and podcasts from the top actors and comedians in the industry. Fans can also catch a live episode of hit comedy podcasts, “Stiff Socks” with Trevor Wallace and “The Bitch Bible” with Jackie Schimmel. Each evening, Venue Vegas will transform into every millennial’s dream party with nostalgia-filled themed nights including 90's, Y2K, and Emo Night dance parties presented by the Emo Night Tour. The Kicker’s full lineup includes: Sarah Cooper In April 2020, Sarah went viral with her brilliant satirical lip-sync impressions of the former president. -

Satirical Politics and Late-Night Television Ratings Tanner Johnson Honors College, Pace University
Pace University DigitalCommons@Pace Honors College Theses Pforzheimer Honors College Summer 7-2018 Satirical Politics and Late-Night Television Ratings Tanner Johnson Honors College, Pace University Follow this and additional works at: https://digitalcommons.pace.edu/honorscollege_theses Part of the Social Influence and Political Communication Commons, and the Television Commons Recommended Citation Johnson, Tanner, "Satirical Politics and Late-Night Television Ratings" (2018). Honors College Theses. 185. https://digitalcommons.pace.edu/honorscollege_theses/185 This Thesis is brought to you for free and open access by the Pforzheimer Honors College at DigitalCommons@Pace. It has been accepted for inclusion in Honors College Theses by an authorized administrator of DigitalCommons@Pace. For more information, please contact [email protected]. Satirical Politics and Late-Night Television Ratings Tanner Johnson Pforzheimer Honors College Dyson College of Arts and Sciences Bachelor of Arts, Communication Studies April 4, 2018 Dr. Adam Klein Department of Communication Studies Pace University Johnson 2 Abstract Since the 2016 Presidential election, it has become increasingly difficult to turn on the television or log onto social media without being informed of everything happening at The White House. This includes late-night television. What once was meant for humorous jokes and celebrity interviews suitable for any pop culture follower has not gotten less funny, but nowadays, the jokes are not always jokes. Satirical news has been around for -

As WGA Members in Scripted Film and Television, We Stand in Solidarity with Our Colleagues at Vox Media
As WGA members in scripted film and television, we stand in solidarity with our colleagues at Vox Media - including Curbed, Eater, Polygon, Recode, SB Nation, The Goods, The Verge, Vox.com, and Vox Studios - as they bargain their first union contract. Film, television, and other parts of the media and entertainment industries have long been unionized because creative workers fought for a seat at the table to negotiate fair wages, good benefits, and just working conditions. Particularly as Vox Media expands further into television and film production, we call on the company to agree to a union contract that lives up to its status as a leader in this industry. Nick Adrian The Savages, Man on a Ledge, Best Man Holiday Suzanne Allain Mr. Malcom’s List Ericon Aronson Mortdecai, On the Line Benjamin August Remember Kemp Baldwin Don’t Walk Kia Barbee Evolve the Series Tanya Barfield Ray Donovan, The Americans, Mrs. America Kristen Bartlett Full Frontal with Samantha Bee, Saturday Night Live Susan Batten Showing Roots Henry Bean The OA, The Believer Dan Beers Premature Christopher Belair The Tonight Show Starring Jimmy Fallon Stephen Belber Law & Order: Special Victims Unit, Tape, The Laramie Project, Match Monica Lee Bellais Tri Jim Benton Dear Dumb Diary Andrew Bergman The Freshman Brooke Berman Uggs for Gaza Flora Birnbaum Russian Doll, Angelyne Harry Bissinger NYPD Blue, author of Friday Night Lights Steve Bodow The Daily Show with Trevor Noah Sage Boggs The Tonight Show Starring Jimmy Fallon Sebastian Boneta Speed Kills, Replicas Joel Booster The Other Two, Big Mouth, Birthright Molly Boylan Sesame Street Kyle Bradstreet Mr.