Meaningful Method Names
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Java Management Extension Didier DONSEZ
http://www-adele.imag.fr/users/Didier.Donsez/cours JMX Java Management eXtension Didier DONSEZ Université Joseph Fourier –Grenoble 1 PolyTech’Grenoble LIG/ADELE [email protected], [email protected] 19/02/2008 Outline Motivation Architecture MBeans Standard, Dynamic Monitor Notification Utilities Remote Management Connector & Adaptor API Tools JSR Bibliography (c)Donsez,JMX Didier 2003-2008, 2 19/02/2008 Under Translation Motivations fr->en Service d’administration d’applications Ressources matérielles accessibles depuis une JVM Ressources logiciels s’exécutant sur une JVM S’inspire de SNMP Instrumentations des ressources au moyen de composants appelés MBean (Manageable Bean) Adopté initialement par J2EE et maintenant J2SE 1.5 (c)Donsez,JMX Didier 2003-2008, 3 19/02/2008 Usage Get and set applications configuration (Pull) Collect statistics (Pull) Performance Ressources usage Problems Notify events (Push) Faults State changes (c)Donsez,JMX Didier 2003-2008, 4 19/02/2008 JMX 3-Level Architecture JMX Web SNMP Specific Browser Console Console Console JConsole HTML/HTTP SNMP Remote RMI HTTP/SOAP Management Level C C’ A A’ Agent MBeanServer Level Probe MBean1 MBean2 MXBean3 (c)Donsez,JMX Didier 2003-2008, Level 5 19/02/2008 JMX 3-Level Architecture JMX Web SNMP Specific Browser Console Console Console JConsole HTML/HTTP SNMP Remote RMI HTTP/SOAP Management Level Connector Connector’ Adaptor Adaptor’ Agent MBeanServer Level Standard Dynamic Probe MXBean3 (c)Donsez,JMX Didier 2003-2008, Level MBean1 MBean2 For Wikipedia 6 19/02/2008 JMX 3-Level Architecture Probe level JMX Web SNMP Specific Browser Console Console Console Resources,JConsole such as applications, devices, or services, are instrumentedHTML/HTTP using JavaSNMP objects called Managed Beans (MBeans). -
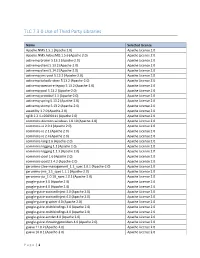
TLC 7.3.0 Use of Third Party Libraries
TLC 7.3.0 Use of Third Party Libraries Name Selected License Apache.NMS 1.5.1 (Apache 2.0) Apache License 2.0 Apache.NMS.ActiveMQ 1.5.6 (Apache 2.0) Apache License 2.0 activemq-broker 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.13.2 (Apache-2.0) Apache License 2.0 activemq-client 5.14.2 (Apache-2.0) Apache License 2.0 activemq-jms-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-kahadb-store 5.13.2 (Apache-2.0) Apache License 2.0 activemq-openwire-legacy 5.13.2 (Apache-2.0) Apache License 2.0 activemq-pool 5.13.2 (Apache-2.0) Apache License 2.0 activemq-protobuf 1.1 (Apache-2.0) Apache License 2.0 activemq-spring 5.13.2 (Apache-2.0) Apache License 2.0 activemq-stomp 5.13.2 (Apache-2.0) Apache License 2.0 awaitility 1.7.0 (Apache-2.0) Apache License 2.0 cglib 2.2.1-v20090111 (Apache 2.0) Apache License 2.0 commons-daemon-windows 1.0.10 (Apache-2.0) Apache License 2.0 commons-io 2.0.1 (Apache 2.0) Apache License 2.0 commons-io 2.1 (Apache 2.0) Apache License 2.0 commons-io 2.4 (Apache 2.0) Apache License 2.0 commons-lang 2.6 (Apache-2.0) Apache License 2.0 commons-logging 1.1 (Apache 2.0) Apache License 2.0 commons-logging 1.1.3 (Apache 2.0) Apache License 2.0 commons-pool 1.6 (Apache 2.0) Apache License 2.0 commons-pool2 2.4.2 (Apache-2.0) Apache License 2.0 geronimo-j2ee-management_1.1_spec 1.0.1 (Apache-2.0) Apache License 2.0 geronimo-jms_1.1_spec 1.1.1 (Apache-2.0) Apache License 2.0 geronimo-jta_1.0.1B_spec 1.0.1 (Apache-2.0) Apache License 2.0 google-guice 3.0 (Apache 2.0) Apache License 2.0 google-guice 4.0 (Apache -

Coremedia Operations Basics Coremedia Operations Basics |
CoreMedia 6 //Version 5.3.27 CoreMedia Operations Basics CoreMedia Operations Basics | CoreMedia Operations Basics Copyright CoreMedia AG © 2012 CoreMedia AG Ludwig-Erhard-Straße 18 20459 Hamburg International All rights reserved. No part of this manual or the corresponding program may be reproduced or copied in any form (print, photocopy or other process) without the written permission of CoreMedia AG. Germany Alle Rechte vorbehalten. CoreMedia und weitere im Text erwähnte CoreMedia Produkte sowie die entsprechenden Logos sind Marken oder eingetragene Marken der CoreMedia AG in Deutschland. Alle anderen Namen von Produkten sind Marken der jeweiligen Firmen. Das Handbuch bzw. Teile hiervon sowie die dazugehörigen Programme dürfen in keiner Weise (Druck, Fotokopie oder sonstige Verfahren) ohne schriftliche Genehmigung der CoreMedia AG reproduziert oder vervielfältigt werden. Unberührt hiervon bleiben die gesetzlich erlaubten Nutzungsarten nach dem UrhG. Licenses and Trademarks All trademarks acknowledged. 12.Feb 2013 CoreMedia Operations Basics 2 CoreMedia Operations Basics | 1. Introduction ...................................................................... 1 1.1. Audience ................................................................ 2 1.2. Typographic Conventions ........................................... 3 1.3. Change Chapter ....................................................... 4 2. System Requirements .......................................................... 5 2.1. Hardware Requirements ........................................... -

Open Source Acknowledgements
This document acknowledges certain third‐parties whose software is used in Esri products. GENERAL ACKNOWLEDGEMENTS Portions of this work are: Copyright ©2007‐2011 Geodata International Ltd. All rights reserved. Copyright ©1998‐2008 Leica Geospatial Imaging, LLC. All rights reserved. Copyright ©1995‐2003 LizardTech Inc. All rights reserved. MrSID is protected by the U.S. Patent No. 5,710,835. Foreign Patents Pending. Copyright ©1996‐2011 Microsoft Corporation. All rights reserved. Based in part on the work of the Independent JPEG Group. OPEN SOURCE ACKNOWLEDGEMENTS 7‐Zip 7‐Zip © 1999‐2010 Igor Pavlov. Licenses for files are: 1) 7z.dll: GNU LGPL + unRAR restriction 2) All other files: GNU LGPL The GNU LGPL + unRAR restriction means that you must follow both GNU LGPL rules and unRAR restriction rules. Note: You can use 7‐Zip on any computer, including a computer in a commercial organization. You don't need to register or pay for 7‐Zip. GNU LGPL information ‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐‐ This library is free software; you can redistribute it and/or modify it under the terms of the GNU Lesser General Public License as published by the Free Software Foundation; either version 2.1 of the License, or (at your option) any later version. This library is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU Lesser General Public License for more details. You can receive a copy of the GNU Lesser General Public License from http://www.gnu.org/ See Common Open Source Licenses below for copy of LGPL 2.1 License. -

Translation of Idiomatic Expressions Across Different Languages: a Study of the Effectiveness of Transsearch Stéphane Huet, Philippe Langlais
Translation of Idiomatic Expressions Across Different Languages: A Study of the Effectiveness of TransSearch Stéphane Huet, Philippe Langlais To cite this version: Stéphane Huet, Philippe Langlais. Translation of Idiomatic Expressions Across Different Languages: A Study of the Effectiveness of TransSearch. Amy Neustein and Judith A. Markowitz. Where Humans Meet Machines: Innovative Solutions to Knotty Natural Language Problems, Springer New York, pp.185-209, 2013. hal-02021924 HAL Id: hal-02021924 https://hal.archives-ouvertes.fr/hal-02021924 Submitted on 16 Feb 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Translation of Idiomatic Expressions across Different Languages: A Study of the Effectiveness of TRANSSEARCH Stephane´ Huet and Philippe Langlais Abstract This chapter presents a case study relating how a user of TRANSSEARCH, a translation spotter as well as a bilingual concordancer available over the Web, can use the tool for finding translations of idiomatic expressions. We show that by paying close attention to the queries made to the system, TRANSSEARCH can effectively identify a fair number of idiomatic expressions and their translations. For indicative purposes, we compare the translations identified by our application to those returned by GOOGLE TRANSLATE and conduct a survey of recent Computer- Assisted Translation tools with similar functionalities to TRANSSEARCH. -

Apache Geronimo Uncovered a View Through the Eyes of a Websphere Application Server Expert
Apache Geronimo uncovered A view through the eyes of a WebSphere Application Server expert Skill Level: Intermediate Adam Neat ([email protected]) Author Freelance 16 Aug 2005 Discover the Apache Geronimo application server through the eyes of someone who's used IBM WebSphere® Application Server for many years (along with other commercial J2EE application servers). This tutorial explores the ins and outs of Geronimo, comparing its features and capabilities to those of WebSphere Application Server, and provides insight into how to conceptually architect sharing an application between WebSphere Application Server and Geronimo. Section 1. Before you start This tutorial is for you if you: • Use WebSphere Application Server daily and are interested in understanding more about Geronimo. • Want to gain a comparative groundwork understanding of Geronimo and WebSphere Application Server. • Are considering sharing applications between WebSphere Application Server and Geronimo. • Simply want to learn and understand what other technologies are out there (which I often do). Prerequisites Apache Geronimo uncovered © Copyright IBM Corporation 1994, 2008. All rights reserved. Page 1 of 23 developerWorks® ibm.com/developerWorks To get the most out of this tutorial, you should have a basic familiarity with the IBM WebSphere Application Server product family. You should also posses a general understanding of J2EE terminology and technologies and how they apply to the WebSphere Application Server technology stack. System requirements If you'd like to implement the two technologies included in this tutorial, you'll need the following software and components: • IBM WebSphere Application Server. The version I'm using as a base comparison is IBM WebSphere Application Server, Version 6.0. -

Translating and Learning Quick Start Guide
Quick Start Guide Translating and Learning Contents ABBYY Lingvo x5 Main Window ..................................................................................3 Quick Lookup of Words and Phrases ......................................................................... 4 Lingvo.Pro Language Portal .......................................................................................6 Learning New Languages with ABBYY Lingvo Tutor x5 ............................................ 9 Grammar in ABBYY Lingvo x5 ..................................................................................14 Phrase Book with Sound ..........................................................................................16 Sample Letters ..........................................................................................................17 Illustrated Dictionary ................................................................................................18 Dictionaries ...............................................................................................................19 Keyboard Shortcuts ..................................................................................................32 Technical Support .....................................................................................................33 ABBYY Lingvo x5 Main Window Selects source Reverses Selects Closes language translation target language unpinned windows direction Enables/disables the “always on top” mode Selects bookshelf Shows current bookshelf List of words from -

Workshop Variation and Change in the Verb Phrase Book of Abstracts
Workshop Variation and Change in the Verb Phrase University of Oslo, 5–6 December 2019 Book of Abstracts Keynotes Elena Anagnostopoulou Datives, genitives and passives in the history of Greek Peter Petré Many people’s grammars, nobody’s grammar. Grammaticalization of auxiliary constructions as emergent in the community Thursday 5th December Tanja Mortelmans & Elena German Reflexive Constructions: an exploration into the diachronic Smirnova dimension Michelle Troberg From derived to lexically specified Result: Change in the French verb phrase Yela Schauwecker Resultative constructions in Medieval French as a contact phenomenon Dennis Wegner All roads lead to eventive past participles: on similarities and constrasts in the grammaticalisation of passive and perfect(ive) participles in Germanic and Romance Katarzyna Janic Auxiliary verb constructions Imola-Ágnes Farkas Variation and Change in the Romanian and Hungarian Verb Phrase Karin Harbusch & Gerard Verb frequency and verb placement in three Germanic languages: A Kempen diachronic corpus study Petr Biskup Grammaticalization of Prepositions in Slavic Anna Pompei From Verb-Particle Constructions to Prefixed Verbs: a diachronic perspective Friday 6th December Malka Rappaport Hovav Modern Hebrew in transit: the shift from a V-framed to an S-framed profile Kari Kinn & Ida Larsson Scandinavian argument shift in time and space Björn Lundquist & Maud On the subtle and ephemeral effects effects of reflexives on verb and subject Westendorp placement Guro Fløgstad Aspectual simplification in a normative source: The Perfect in Argentinian Spanish school grammars Datives, Genitives and passives in the history of Greek Elena Anagnostopoulou University of Crete Joint work with Christina Sevdali, Ulster University In this talk, I will compare the properties of dative and genitive objects in Classical vs. -

A New Model for a Foreign Langu Age Learner's
A NEW MODEL FOR A FOREIGN LANGU AGE LEARNER’S DIGTIONARY by Philippe R. M/HumWé A thesis siibBiitted in pariial Mfilmenl of the requirements for the degree of Doutor em Letras Univeráidade Federal de Santa Catarina 1997 Approved by Prof. Dr. José Luiz Meiarer Chairman of the Supervisory' Committee Pós-GrâduaçSo de Literatura e Língua Inglesa November Í997 Esta tese foi julgada adequada e aprovada em sua forma final pelo Programa de Pós-Graduação em Inglês para a obtenção do grau de DOUTOR EM LETRAS Opção Língua Inglesa e Lingüística Aplicada ao Inglês tíkJlfhOLff) Dr®. BarbaraOughtonBaptísta Coordenadora Dr. José Luiz Meurer Orientador Banca Examinadora: Dr. José Luiz Meurer Orientador ‘. Rosa Weingòld Ko|lhder Dr. Jean Binon (Uili:i^. Católica de Leuven, Bélgica) V D|r“. SilAyia Serrai i ^ (UNICAMP) Dr. Richard Malcolm Coulthard (Univ. de Birmingham, Inglaterra) FlorianópoHs, 19 de dezembro de 1997. Every author may aspire to praise, the lexicographer can only hope to escape reproach, and even this negative recompense has been granted to very few. Johnson in the Preface to the English Dictionary. Voor Femand Humblé, In memoriam UNIVERSIDADE FEDERAL DE SANTA CATARINA A NEW MODEL FOR A FOREIGN LANGUAGE LEARNER’S DICTIONARY by Philippe R. M. Humble Chairperson of the Supervisory Committee: Professor Dr. José Luiz Meurer Pós-graduação em Lingua e Literatura Inglesa n Abstract This thesis deals with the problem of foreign language lexicography proposing a new dictionary model. It is concerned with the lack of adequacy between, on the one hand, current reference works and, on the other, the learners’ needs. These needs have been insufficiently investigated and this thesis suggests that the lack of substantial results in the area is due to a flawed research methodology. -

Once More on the Notion of the Unit of Translation
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by Siberian Federal University Digital Repository Journal of Siberian Federal University. Humanities & Social Sciences 2 (2015 8) 218-228 ~ ~ ~ УДК 81.347.78.034 Once More on the Notion of the Unit of Translation Olga I. Brodovich* Institute of Foreign Languages 13, 12 Linija, Vasilievsky Island, St. Petersburg, 199178, Russia Received 16.11.2014, received in revised form 14.12.2014, accepted 23.01.2015 The paper has two main goals. Firstly, it is aimed at proving that there is a single principle governing the choice of any portion of the original – from morpheme to the entire text – for the role of the unit of translation (UT). It is based on the role a linguistic unit plays in the bigger form of which it is an integral part. If it makes its individual input into the meaning of the whole then it should be given special attention in translation, i.e. at some stage of re-coding made a UT. But if the meaning of the whole larger construction is such that it is not made up by putting together the meanings of its composite pars – a situation termed idiomatic – then (and only then) the entire whole is taken as a unit of translation. The paper also shows that when theorists declare that there is only one linguistic entity which can be qualified as a UT – in some works this is the sentence, in others, the entire text – they are using the term in their own interpretation and not in the meaning that was give the term by its authors. -

Berlitz: Italian Phrase Book & Dictionary Pdf, Epub, Ebook
BERLITZ: ITALIAN PHRASE BOOK & DICTIONARY PDF, EPUB, EBOOK Berlitz Publishing | 224 pages | 01 Apr 2012 | Berlitz Publishing Company | 9789812689634 | English | London, United Kingdom Berlitz: Italian Phrase Book & Dictionary PDF Book This item doesn't belong on this page. To see what your friends thought of this book, please sign up. Friend Reviews. Books by Berlitz Publishing Company. Stock photo. Members save with free shipping everyday! Berlitz Picture Dictionary Chinese With over essential words and phrases, this stylish, pocket-sized Chinese picture dictionary from Berlitz's trusted language experts makes communicating quick and easy. Apa Publications UK, Ltd. Home 1 Books 2. To see what your friends thought of this book, please sign up. Be the first to ask a question about Berlitz Italian Phrase Book. Other editions. Lists with This Book. Out of stock. In that case, we can't All Languages. Lisa rated it really liked it Jun 03, Tommy Verhaegen marked it as to-read Apr 14, Welcome back. The Berlitz Flash cards are designed to teach children aged 3 to 6 years the words they need to know, such as numbers, colours, animals, and more. Tclaret23 rated it it was amazing Sep 18, Details if other :. Enter Location. Customer Service. Tanja added it Sep 25, With its completely redesigned interior making the book even more accessible than before, the Berlitz Italian Phrase Book is ideal for travellers of all ages who are looking for a…. See more details at Online Price Match. Here at Walmart. Pickup not available. Original Title. The phrase books will help you troubleshoot various situations: losing baggage, asking directions, reserving accommodations, visiting the Berlitz Phrase Books, the unparalleled market leaders, feature 1, current expressions visitors will hear during their travels plus cultural tips and cautions to guide visitors through social situation and provide valuable safety tips. -

PDF Download Greek Phrase Book and Dictionary
GREEK PHRASE BOOK AND DICTIONARY PDF, EPUB, EBOOK Berlitz | 224 pages | 26 Nov 1998 | Apa Publications | 9782831562377 | English, Greek, Modern (1453-) | United Kingdom Greek Phrase Book and Dictionary PDF Book This handy guide provides key phrases for use in everyday circumstances, complete with phonetic spelling; an English-Italian and Italian-English dictionary; the latest information on European currency and rail transportation, and even a tear-out cheat sheet for continued language practice as you wait in line at the Sistine Chapel. Not registered? The phrases have a simple guide to help with pronunciation. See details. How are you? Find the best beaches and order local specialties with ease -all Google Doodle celebrates basketball inventor. Your order is now being processed and we have sent a confirmation email to you at. Ideal for practicing your pronunciation and polishing your accent either before you travel or while on the road. Adding the "af-TOH" just means "How much is it? Lonely Planet Global Limited. Do you speak English? Berlitz Japanese Pocket Dictionary. It is possible to listen to the pronunciation of each phrase! Please sign in to write a review. Skip Navigation and go to main content Bestsellers Books. Paperback Published 11 Oct Adobe Photoshop CC. Following the initial email, you will be contacted by the shop to confirm that your item is available for collection. Let's Explore Ocean. Category Education. Lonely Planet: The world's number one travel guide publisher Whether exploring your own backyard or The 4-colour layout allows easy access to key information. Reserve online, pay on collection.