THE SPACE SHUTTLE PRIMARY COMPUTER SYSTEM IBM's Federal Systems Division Is Responsible for Supplying "Error-Free" Software for NASA's Space Shuttle Program
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The "Bug" Heard 'Round the World
ACM SIGSOFT SOFTWAREENGINEERING NOTES, Vol 6 No 5, October 1981 Page 3 THE "BUG" HEARD 'ROUND THE WORLD Discussion of the software problem which delayed the first Shuttle orbital flight JohnR. Garman Cn April 10, 1981, about 20 minutes prior to the scheduled launching of the first flight of America's Space Transportation System, astronauts and technicians attempted to initialize the software system which "backs-up" the quad-redundant primary software system ...... and could not. In fact, there was no possible way, it turns out, that the BFS (Backup Flight Control System) in the fifth onboard computer could have been initialized , Froperly with the PASS (Primary Avionics Software System) already executing in the other four computers. There was a "bug" - a very small, very improbable, very intricate, and very old mistake in the initialization logic of the PASS. It was the type of mistake that gives programmers and managers alike nightmares - and %heoreticians and analysts endless challenge. I% was the kind of mistake that "cannot happen" if one "follows all the rules" of good software design and implementation. It was the kind of mistake that can never be ruled out in the world of real systems development: a world involving hundreds of programmers and analysts, thousands of hours of testing and simulation, and millions of pages of design specifications, implementation schedules, and test plans and reports. Because in that world, software is in fact "soft" - in a large complex real time control system like the Shuttle's avionics system, software is pervasive and, in virtually every case, the last subsystem to stabilize. -
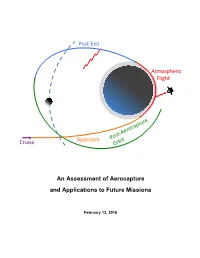
An Assessment of Aerocapture and Applications to Future Missions
Post-Exit Atmospheric Flight Cruise Approach An Assessment of Aerocapture and Applications to Future Missions February 13, 2016 National Aeronautics and Space Administration An Assessment of Aerocapture Jet Propulsion Laboratory California Institute of Technology Pasadena, California and Applications to Future Missions Jet Propulsion Laboratory, California Institute of Technology for Planetary Science Division Science Mission Directorate NASA Work Performed under the Planetary Science Program Support Task ©2016. All rights reserved. D-97058 February 13, 2016 Authors Thomas R. Spilker, Independent Consultant Mark Hofstadter Chester S. Borden, JPL/Caltech Jessie M. Kawata Mark Adler, JPL/Caltech Damon Landau Michelle M. Munk, LaRC Daniel T. Lyons Richard W. Powell, LaRC Kim R. Reh Robert D. Braun, GIT Randii R. Wessen Patricia M. Beauchamp, JPL/Caltech NASA Ames Research Center James A. Cutts, JPL/Caltech Parul Agrawal Paul F. Wercinski, ARC Helen H. Hwang and the A-Team Paul F. Wercinski NASA Langley Research Center F. McNeil Cheatwood A-Team Study Participants Jeffrey A. Herath Jet Propulsion Laboratory, Caltech Michelle M. Munk Mark Adler Richard W. Powell Nitin Arora Johnson Space Center Patricia M. Beauchamp Ronald R. Sostaric Chester S. Borden Independent Consultant James A. Cutts Thomas R. Spilker Gregory L. Davis Georgia Institute of Technology John O. Elliott Prof. Robert D. Braun – External Reviewer Jefferey L. Hall Engineering and Science Directorate JPL D-97058 Foreword Aerocapture has been proposed for several missions over the last couple of decades, and the technologies have matured over time. This study was initiated because the NASA Planetary Science Division (PSD) had not revisited Aerocapture technologies for about a decade and with the upcoming study to send a mission to Uranus/Neptune initiated by the PSD we needed to determine the status of the technologies and assess their readiness for such a mission. -

Magnetoshell Aerocapture: Advances Toward Concept Feasibility
Magnetoshell Aerocapture: Advances Toward Concept Feasibility Charles L. Kelly A thesis submitted in partial fulfillment of the requirements for the degree of Master of Science in Aeronautics & Astronautics University of Washington 2018 Committee: Uri Shumlak, Chair Justin Little Program Authorized to Offer Degree: Aeronautics & Astronautics c Copyright 2018 Charles L. Kelly University of Washington Abstract Magnetoshell Aerocapture: Advances Toward Concept Feasibility Charles L. Kelly Chair of the Supervisory Committee: Professor Uri Shumlak Aeronautics & Astronautics Magnetoshell Aerocapture (MAC) is a novel technology that proposes to use drag on a dipole plasma in planetary atmospheres as an orbit insertion technique. It aims to augment the benefits of traditional aerocapture by trapping particles over a much larger area than physical structures can reach. This enables aerocapture at higher altitudes, greatly reducing the heat load and dynamic pressure on spacecraft surfaces. The technology is in its early stages of development, and has yet to demonstrate feasibility in an orbit-representative envi- ronment. The lack of a proof-of-concept stems mainly from the unavailability of large-scale, high-velocity test facilities that can accurately simulate the aerocapture environment. In this thesis, several avenues are identified that can bring MAC closer to a successful demonstration of concept feasibility. A custom orbit code that dynamically couples magnetoshell physics with trajectory prop- agation is developed and benchmarked. The code is used to simulate MAC maneuvers for a 60 ton payload at Mars and a 1 ton payload at Neptune, both proposed NASA mis- sions that are not possible with modern flight-ready technology. In both simulations, MAC successfully completes the maneuver and is shown to produce low dynamic pressures and continuously-variable drag characteristics. -

Minotaur I User's Guide
This page left intentionally blank. Minotaur I User’s Guide Revision Summary TM-14025, Rev. D REVISION SUMMARY VERSION DOCUMENT DATE CHANGE PAGE 1.0 TM-14025 Mar 2002 Initial Release All 2.0 TM-14025A Oct 2004 Changes throughout. Major updates include All · Performance plots · Environments · Payload accommodations · Added 61 inch fairing option 3.0 TM-14025B Mar 2014 Extensively Revised All 3.1 TM-14025C Sep 2015 Updated to current Orbital ATK naming. All 3.2 TM-14025D Sep 2018 Branding update to Northrop Grumman. All 3.3 TM-14025D Sep 2020 Branding update. All Updated contact information. Release 3.3 September 2020 i Minotaur I User’s Guide Revision Summary TM-14025, Rev. D This page left intentionally blank. Release 3.3 September 2020 ii Minotaur I User’s Guide Preface TM-14025, Rev. D PREFACE This Minotaur I User's Guide is intended to familiarize potential space launch vehicle users with the Mino- taur I launch system, its capabilities and its associated services. All data provided herein is for reference purposes only and should not be used for mission specific analyses. Detailed analyses will be performed based on the requirements and characteristics of each specific mission. The launch services described herein are available for US Government sponsored missions via the United States Air Force (USAF) Space and Missile Systems Center (SMC), Advanced Systems and Development Directorate (SMC/AD), Rocket Systems Launch Program (SMC/ADSL). For technical information and additional copies of this User’s Guide, contact: Northrop Grumman -

Cosmos: a Spacetime Odyssey (2014) Episode Scripts Based On
Cosmos: A SpaceTime Odyssey (2014) Episode Scripts Based on Cosmos: A Personal Voyage by Carl Sagan, Ann Druyan & Steven Soter Directed by Brannon Braga, Bill Pope & Ann Druyan Presented by Neil deGrasse Tyson Composer(s) Alan Silvestri Country of origin United States Original language(s) English No. of episodes 13 (List of episodes) 1 - Standing Up in the Milky Way 2 - Some of the Things That Molecules Do 3 - When Knowledge Conquered Fear 4 - A Sky Full of Ghosts 5 - Hiding In The Light 6 - Deeper, Deeper, Deeper Still 7 - The Clean Room 8 - Sisters of the Sun 9 - The Lost Worlds of Planet Earth 10 - The Electric Boy 11 - The Immortals 12 - The World Set Free 13 - Unafraid Of The Dark 1 - Standing Up in the Milky Way The cosmos is all there is, or ever was, or ever will be. Come with me. A generation ago, the astronomer Carl Sagan stood here and launched hundreds of millions of us on a great adventure: the exploration of the universe revealed by science. It's time to get going again. We're about to begin a journey that will take us from the infinitesimal to the infinite, from the dawn of time to the distant future. We'll explore galaxies and suns and worlds, surf the gravity waves of space-time, encounter beings that live in fire and ice, explore the planets of stars that never die, discover atoms as massive as suns and universes smaller than atoms. Cosmos is also a story about us. It's the saga of how wandering bands of hunters and gatherers found their way to the stars, one adventure with many heroes. -
Effects of Space Exploration Objective: Students Will Be Able To: 1
Lesson Topic: Effects of Space Exploration Objective: Students will be able to: 1. Identify and describe how space exploration affects the state of Florida. 2. Describe the nature of the Kennedy Space Center. 3. Identify the components of a space shuttle 4. Apply the importance of space exploration to the Florida culture through design. Time Required: 75 minutes Materials Needed: ● Teacher computer with internet access ● Projector/Smartboard ● 1 computer/laptop/iPad per student with internet access ● Effects of Space Exploration handout (attached) ● Space Exploration Video: Escape Velocity - A Quick History of Space Exploration ● Space Shuttle Website: Human Space Flight (HSF) - Space Shuttle ● Kennedy Space Center Website: Visit Kennedy Space Center Visitor Complex at Cape Canaveral ● Coloring pencils/Markers Teacher Preparation: ● Assign a Legends of Learning Content Review Quick Play playlist for the day(s) you will be teaching the lesson. ○ Content Review - Middle School - Effects of Space Exploration ● Make copies of Effects of Space Exploration Worksheet (1 per student) Engage (10 minutes): 1. Pass out the Effects of Space Exploration Handout. 2. Ask students “What do you know about space exploration? a. Draw the words “Space Exploration” on the board with a circle around it. i. As students share their answers write their answers on the board and link them to the Space Exploration circle with a line. 3. Tell students “We are going to watch a short video about the history of space exploration and how it has evolved over time. In the space provided on the handout, jot down any notes that you find interesting or important. 4. -

International Space Station Basics Components of The
National Aeronautics and Space Administration International Space Station Basics The International Space Station (ISS) is the largest orbiting can see 16 sunrises and 16 sunsets each day! During the laboratory ever built. It is an international, technological, daylight periods, temperatures reach 200 ºC, while and political achievement. The five international partners temperatures during the night periods drop to -200 ºC. include the space agencies of the United States, Canada, The view of Earth from the ISS reveals part of the planet, Russia, Europe, and Japan. not the whole planet. In fact, astronauts can see much of the North American continent when they pass over the The first parts of the ISS were sent and assembled in orbit United States. To see pictures of Earth from the ISS, visit in 1998. Since the year 2000, the ISS has had crews living http://eol.jsc.nasa.gov/sseop/clickmap/. continuously on board. Building the ISS is like living in a house while constructing it at the same time. Building and sustaining the ISS requires 80 launches on several kinds of rockets over a 12-year period. The assembly of the ISS Components of the ISS will continue through 2010, when the Space Shuttle is retired from service. The components of the ISS include shapes like canisters, spheres, triangles, beams, and wide, flat panels. The When fully complete, the ISS will weigh about 420,000 modules are shaped like canisters and spheres. These are kilograms (925,000 pounds). This is equivalent to more areas where the astronauts live and work. On Earth, car- than 330 automobiles. -

Communications Satellites
I. I IPAGESJ i < INASA CR OR fmx OR AD NUMBER) COMMUNICATIONS SATELLITES A CONTINUING BIBLIOGRAPHY Hard copy (HC) Microfiche (MF) NATIONAL AERONAUTICS AND SPACE ADMINISTRATION .J I I, i This bibliography was prepared by the Scientific and Technical Information Facility operated for the National Aeronautics and Space Administration by Documentation Incorporated ~ ~~~ NASA SP-7004 (01) COMMUNICATIONS SATELLITES A CONTINUING BIBLIOGRAPHY A selection of annotated references to unclas- sified reports and journal articles that were introduced into the NASA Information System during the period May 1964-January 1965. Scientific and Technical In formotion Division NATIONAL AERONAUTICS AND SPACE ADMINISTRATION WASHINGTON, D.C. APRIL 1965 This document is available from the Clearinghouse for Federal Scientific and Technical Information (OTS), Springfield, Virginia, 22 1 5 1 , for $1 .OO INTRODUCTION With the publication of this first supplement, NASA SP-7004 (Ol), to the Continuing Bibliography on “Communications Satellites” (SP-7004), the National Aeronautics and Space Administration continues its program of distributing selected references to reports and articles on aerospace topics that are currently under intensive study. The references are assembled in this form to provide a convenient source of information for use by scientists and engineers who need this kind of specialized compilation. Continuing Bibliographies are updated periodically by supplements which can be appended to the original issue. All references included in SP-7004 (01) have been announced in either Scientific and Technical Aerospace Reports (STAR)or International Aerospace Abstracts (IAA) and were introduced into the NASA information system during the period May, 1964-January, 1965. The transmission of information by means of communications satellites is a new tech- nique that promises to be a powerful stimulus for effective international cooperation in the investigation of space. -

Study of a Crew Transfer Vehicle Using Aerocapture for Cycler Based Exploration of Mars by Larissa Balestrero Machado a Thesis S
Study of a Crew Transfer Vehicle Using Aerocapture for Cycler Based Exploration of Mars by Larissa Balestrero Machado A thesis submitted to the College of Engineering and Science of Florida Institute of Technology in partial fulfillment of the requirements for the degree of Master of Science in Aerospace Engineering Melbourne, Florida May, 2019 © Copyright 2019 Larissa Balestrero Machado. All Rights Reserved The author grants permission to make single copies ____________________ We the undersigned committee hereby approve the attached thesis, “Study of a Crew Transfer Vehicle Using Aerocapture for Cycler Based Exploration of Mars,” by Larissa Balestrero Machado. _________________________________________________ Markus Wilde, PhD Assistant Professor Department of Aerospace, Physics and Space Sciences _________________________________________________ Andrew Aldrin, PhD Associate Professor School of Arts and Communication _________________________________________________ Brian Kaplinger, PhD Assistant Professor Department of Aerospace, Physics and Space Sciences _________________________________________________ Daniel Batcheldor Professor and Head Department of Aerospace, Physics and Space Sciences Abstract Title: Study of a Crew Transfer Vehicle Using Aerocapture for Cycler Based Exploration of Mars Author: Larissa Balestrero Machado Advisor: Markus Wilde, PhD This thesis presents the results of a conceptual design and aerocapture analysis for a Crew Transfer Vehicle (CTV) designed to carry humans between Earth or Mars and a spacecraft on an Earth-Mars cycler trajectory. The thesis outlines a parametric design model for the Crew Transfer Vehicle and presents concepts for the integration of aerocapture maneuvers within a sustainable cycler architecture. The parametric design study is focused on reducing propellant demand and thus the overall mass of the system and cost of the mission. This is accomplished by using a combination of propulsive and aerodynamic braking for insertion into a low Mars orbit and into a low Earth orbit. -

A Conceptual Analysis of Spacecraft Air Launch Methods
A Conceptual Analysis of Spacecraft Air Launch Methods Rebecca A. Mitchell1 Department of Aerospace Engineering Sciences, University of Colorado, Boulder, CO 80303 Air launch spacecraft have numerous advantages over traditional vertical launch configurations. There are five categories of air launch configurations: captive on top, captive on bottom, towed, aerial refueled, and internally carried. Numerous vehicles have been designed within these five groups, although not all are feasible with current technology. An analysis of mass savings shows that air launch systems can significantly reduce required liftoff mass as compared to vertical launch systems. Nomenclature Δv = change in velocity (m/s) µ = gravitational parameter (km3/s2) CG = Center of Gravity CP = Center of Pressure 2 g0 = standard gravity (m/s ) h = altitude (m) Isp = specific impulse (s) ISS = International Space Station LEO = Low Earth Orbit mf = final vehicle mass (kg) mi = initial vehicle mass (kg) mprop = propellant mass (kg) MR = mass ratio NASA = National Aeronautics and Space Administration r = orbital radius (km) 1 M.S. Student in Bioastronautics, [email protected] 1 T/W = thrust-to-weight ratio v = velocity (m/s) vc = carrier aircraft velocity (m/s) I. Introduction T HE cost of launching into space is often measured by the change in velocity required to reach the destination orbit, known as delta-v or Δv. The change in velocity is related to the required propellant mass by the ideal rocket equation: 푚푖 훥푣 = 퐼푠푝 ∗ 0 ∗ ln ( ) (1) 푚푓 where Isp is the specific impulse, g0 is standard gravity, mi initial mass, and mf is final mass. Specific impulse, measured in seconds, is the amount of time that a unit weight of a propellant can produce a unit weight of thrust. -

Aerocapture Demonstration and Mars Mission Applications
Concepts and Approaches for Mars Exploration (2012) 4173.pdf AEROCAPTURE DEMONSTRATION AND MARS MISSION APPLICATIONS. M. M. Munk, NASA Lan- gley Research Center (1 N Dryden Street, M/S 489, Hampton, VA; [email protected]) Challenge Area Summary: Aerocapture is an Aerocapture saves multiple Earth launches for human aeroassist technology that can enable large robotic Mars DRA51, when coupled with high-thrust propul- payloads to be placed into Mars orbit, facilitate access sive transfers. Aerocapture’s mass benefits for histori- to Phobos and Deimos, and support human Mars ex- cal Mars missions have not been compelling due to ploration. This abstract addresses Challenge Area 2; in small scale and low arrival velocities. As we strive to particular, Concepts for low-cost demonstration of emplace more massive assets at Mars to support hu- aeroassist technologies. The information herein pre- mans or explore Phobos and Deimos, Aerocapture can sents the state-of-the-art (SOA) in aerocapture tech- play a significant, beneficial role. nology, outlines an established Earth flight demonstra- Aerocapture SOA: Aerocapture occurs in only tion concept, and offers specific uses for aerocapture at one flight regime (hypersonic) and there are no re- Mars. quired configuration changes during the maneuver, Introduction: Aerocapture, shown in Fig. 1, is the making it much less difficult than EDL. Small timing use of aerodynamic forces to slow an approaching ve- errors during EDL can result in loss of mission; during hicle and put it into a closed orbit about a planet. In aerocapture, they mean a little more propellant is contrast to aerobraking, aerocapture occurs in a single needed to adjust the final orbit. -

Report to Congress on FAA Evaluation of Commercial Human
FEDERAL AVIATION ADMINISTRATION Report to Congress: FAA Evaluation of Commercial Human Space Flight Safety Frameworks and Key Industry Indicators U.S. Commercial Space Launch Competitiveness Act (CSLCA), Public Law 114-90, Section 111(5); 51 USC § 50905(c)(5), (6) Contents I. Executive Summary ..................................................................................................................... 1 II. Introduction ................................................................................................................................ 2 III. State of the Commercial Human Space Flight Industry ........................................................... 4 IV. Safety Framework Stakeholders ............................................................................................... 6 V. Current Legislative and Regulatory Framework for Safety of Human Space Flight ................. 7 VI. Benefits of a Safety Framework ............................................................................................. 10 VII. Elements and Leadership of Safety Frameworks .................................................................. 11 VIII. Industry and Government Readiness Indicators .................................................................. 15 IX. Progress of the Industry in Developing Voluntary Industry Consensus Standards ................ 24 X. Summary .................................................................................................................................. 36 I. Executive Summary This