Geocoding of Worldwide Patent Data Descriptor Data Gaétan De Rassenfosse 1, Jan Kozak1 & Florian Seliger 2*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Print Management at “Mega-Scale”: a Regional Perspective on Print Book Collections in North America
Print Management at “Mega-scale”: A Regional Perspective on Print Book Collections in North America Brian Lavoie Research Scientist Constance Malpas Program Officer JD Shipengrover Senior Web & User Interface Designer OCLC Research A publication of OCLC Research Print Management at “Mega-scale”: A Regional Perspective on Print Book Collections in North America Brian Lavoie, Constance Malpas, and JD Shipengrover, for OCLC Research © 2012 OCLC Online Computer Library Center, Inc. Reuse of this document is permitted as long as it is consistent with the terms of the Creative Commons Attribution-Noncommercial-Share Alike 3.0 (USA) license (CC-BY-NC-SA): http://creativecommons.org/licenses/by-nc-sa/3.0/. July 2012 OCLC Research Dublin, Ohio 43017 USA www.oclc.org ISBN: 1-55653-450-7 (13-digit) 978-1-55653-450-8 OCLC (WorldCat): 799083301 Please direct correspondence to: Brian Lavoie Research Scientist [email protected] Suggested citation: Lavoie, Brian, Constance Malpas and JD Shipengrover. 2012. Print Management at “Mega- scale”: A Regional Perspective on Print Book Collections in North America. Dublin, Ohio: OCLC Research. http://www.oclc.org/research/publications/library/2012/2012-05.pdf. Print Management at “Mega-Scale”: A Regional Perspective on Print Book Collections in North America Contents Acknowledgements ........................................................................................ 6 Introduction ................................................................................................ 7 Context .................................................................................................... -

Pgeocode Documentation Release 0.3.0
pgeocode Documentation Release 0.3.0 Roman Yurchak Apr 07, 2021 Contents: 1 pgeocode 1 1.1 Installation................................................1 1.2 Quickstart................................................1 1.3 Geocoding format............................................2 1.4 Configuration and defaults........................................2 1.5 License..................................................3 1.6 Supported countries...........................................3 2 Contributing 5 2.1 Testing..................................................5 2.2 Code style................................................5 3 API Reference 7 3.1 pgeocode.Nominatim...........................................7 3.2 pgeocode.GeoDistance..........................................8 3.3 pgeocode.haversine_distance......................................8 Index 11 i ii CHAPTER 1 pgeocode Postal code geocoding and distance calculations pgeocode is a Python library for high performance off-line querying of GPS coordinates, region name and municipality name from postal codes. Distances between postal codes as well as general distance queries are also supported. The used GeoNames database includes postal codes for 83 countries. Currently, only queries within the same country are supported. For additional documentation see pgeocode.readthedocs.io. 1.1 Installation pgeocode requires Python 3.6+ as well as numpy and pandas packages. It can be installed with, pip install pgeocode or conda install-c conda-forge pgeocode 1.2 Quickstart Postal code queries >>> -

International Out-Of-Delivery-Area and Out-Of-Pickup-Area Surcharges
INTERNATIONAL OUT-OF-DELIVERY-AREA AND OUT-OF-PICKUP-AREA SURCHARGES International shipments (subject to service availability) delivered to or picked up from remote and less-accessible locations are assessed an out-of-delivery area or out-of-pickup-area surcharge. Refer to local service guides for surcharge amounts. The following is a list of postal codes and cities where these surcharges apply. Effective: July 13, 2015 Albania Daireaux Puan 0880 3154 3509 3785-3789 Berat Diamante Puerto Santa Cruz 0885-0886 3158-3160 3512 3791-3793 Durres Dolores Puerto Tirol 0909 3230-3232 3515-3518 3795-3797 Elbasan Dorrego Quequen 2327-2329 3233 3520 3799 Fier El Bolson Reconquista 2331 3235 3521-3523 3804-3810 Kavaje El Durazno Retiro San Pablo 2333-2347 3236-3239 3525 3812-3814 Kruje El Trebol Rincon De Los Sauces 2350-2360 3240-3241 3527 3815 Kucove Embalse Rio Ceballos 2365 3242-3243 3529-3531 3816 Lac Emilio Lamarca Rio Segundo 2369-2372 3249-3251 3533 3818 Lezha Esquel Rio Tala 2379-2382 3254 3537 3820-3822 Lushnje Fair Rojas 2385-2388 3260 3540 3823-3825 Shkodra Famailla Rosario De Lerma 2390 3264-3274 3542 3831 Vlore Firmat Rufino 2394-2411 3276-3282 3544 3833 Florentino Ameghino Russel 2415 3284 3546 3835 Andorra* Franck Salina De Piedra 2420-2431 3286-3287 3549 3840 Andorra General Alvarado Salsipuedes 2439-2441 3289 3557-3559 3842 Andorra La Vella General Belgrano Salto 2443-2450 3292-3294 3561-3568 3844 El Serrat General Galarza Samborombon 2452-2456 3300-3305 3570-3573 3847 Encamp General Guemes San Andres De Giles 2460 3309-3312 3575-3576 -

BASIC DATA SERIES DOMESTIC IN-FLIGHT SURVEY, 2016 Documentation Report
Beyond Information. Intelligence. Established 1960 Database Marketing Economic & Social Impact Studies Evaluations Research Modeling/Forecasting BASIC DATA SERIES DOMESTIC IN-FLIGHT SURVEY, 2016 SMS 1042 Fort Street Mall Suite 200 Honolulu, HI 96813 Ph: (808) 537-3356 Documentation Report Toll Free (877) 535-5767 E-mail: [email protected] Website: www.smshawaii.com Prepared for: The Hawai‘i Tourism Authority July 2017 CONTENTS INTRODUCTION ....................................................................................................................... 1 PURPOSE AND OBJECTIVES OF THE RESEARCH ............................................................ 1 POLICIES PERTAINING TO PROJECT RESPONSIBILITIES ............................................... 1 DATA ACQUISITION PROCEDURES ....................................................................................... 3 SURVEY INSTRUMENT ........................................................................................................ 3 DISTRIBUTION OF FORMS .................................................................................................. 3 DATA COLLECTION .............................................................................................................. 7 LOGGING AND PREPARATION ........................................................................................ 8 PRE-SCANNING RULES ................................................................................................ 8 SCANNING IN-FLIGHT FORMS ........................................................................................ -

Service Guide Fedex.Com/Serviceguide January 6, 2020 Updated September 28, 2020
Service Guide fedex.com/serviceguide January 6, 2020 Updated September 28, 2020 Services Rates Terms Index CONTENTS SERVICES RATES TERMS INDEX Contents This book includes an overview of FedEx® services; FedEx Express and FedEx Ground standard list rates effective January 6, 2020, for U.S., U.S. export and U.S. import services; FedEx One Rate® pricing for FedEx Express® U.S. services; FedEx Express Terms and Conditions; the FedEx Ground Tariff; and the FedEx SameDay® City Tariff. This information, along with U.S. retail rates1 and the service information at fedex.com/serviceguide, constitutes the FedEx Service Guide. The FedEx Express Terms and Conditions, the FedEx Ground Tariff, the FedEx SameDay City Tariff, as applicable, and rates in this book and at fedex.com/serviceguide make up the contract of carriage under which your shipments are transported, unless modified under a separate agreement. Overview of Services 2–20 Standard List Rate, Surcharge and Fee Changes 23 How to Calculate Your Rate 24 Zone Charts 25 International Express Package 25–27 International Express Freight 28 Canada 29 U.S. Express Package Rates 30 Zones 2–8 30–50 To Alaska and Hawaii 51–53 From Alaska and Hawaii 54–55 Within Hawaii 56 Multiweight 57–58 FedEx SameDay® and FedEx SameDay® Freight 59–60 FedEx SameDay City Rates 61–63 FedEx One Rate 64 U.S. Express Freight Rates 65 International Express Package Rates 66 U.S. Export 66–82 Multiweight, U.S. Export 83 U.S. Import 84–98 Multiweight, U.S. Import 99 FedEx® International Next Flight, U.S. -

The Organisation of Trade Data for Inclusion in a Social Accounting Matrix
Technical Paper Series Technical Paper 2004:2 The Organisation of Trade Data for inclusion in a Social Accounting Matrix Elsenburg December 2004 Overview The Provincial Decision-Making Enabling (PROVIDE) Project aims to facilitate policy design by supplying policymakers with provincial and national level quantitative policy information. The project entails the development of a series of databases (in the format of Social Accounting Matrices) for use in Computable General Equilibrium models. The National and Provincial Departments of Agriculture are the stakeholders and funders of the PROVIDE Project. The research team is located at Elsenburg in the Western Cape. PROVIDE Research Team Project Leader: Cecilia Punt Senior Researchers: Kalie Pauw Melt van Schoor Junior Researchers: Lillian Rantho Benedict Gilimani Technical Expert: Scott McDonald Associate Researchers: Lindsay Chant Christine Valente PROVIDE Contact Details Private Bag X1 Elsenburg, 7607 South Africa [email protected] +27-21-8085191 +27-21-8085210 For the original project proposal and a more detailed description of the project, please visit www.elsenburg.com/provide PROVIDE Project Technical Paper 2004: 2 December 2004 The Organisation of Trade Data for inclusion in a Social Accounting Matrix1 Abstract This paper describes the procedure followed to organise trade data obtained from the South African Revenue Service for inclusion in the PROVIDE Project Social Accounting Matrices. The data is aggregated in order to determine the custom’s value of imports and exports, respectively, for each of the commodity groups identified in the Social Accounting Matrices. With regard to trading partners the trade data for South Africa is organized in such a way that it allows for the inclusion of multiple trading partners in the Social Accounting Matrices and that international trade at provincial level can be distinguished. -

2018 Fedex Service Guide
Front Cover SERVICE GUIDE fedex.com/serviceguide January 1, 2018 SERVICES RATES TERMS INDEX Contents E Services E Rates E Terms E Index E Contents This book includes an overview of FedEx® services; FedEx Express and FedEx Ground standard list rates effective Jan. 1, 2018, for U.S., U.S. export and U.S. import services; FedEx One Rate® pricing for FedEx Express® U.S. services; FedEx Express Terms and Conditions; the FedEx Ground Tariff; and the FedEx SameDay® City Tariff. This information, along with U.S. retail rates1 and the service information at fedex.com/serviceguide, constitutes the FedEx Service Guide. The service information at fedex.com/serviceguide (excluding rates, the FedEx Express Terms and Conditions, the FedEx Ground Tariff, and the FedEx SameDay City Tariff) and the overview of services in this book are not part of the contract of carriage. Overview of Services 2–19 Standard List Rate, Surcharge and Fee Changes 22 How to Calculate Your Rate 23 Zone Charts 24 International Express Package 24–26 International Express Freight 27 Canada 28 U.S. Express Package Rates 29 Zones 2–8 29–49 To Alaska and Hawaii 50–52 From Alaska and Hawaii 53–54 Within Hawaii 55 Multiweight 56–57 FedEx SameDay® and FedEx SameDay® Freight 58–59 FedEx SameDay City Rates 60–62 FedEx One Rate 63 U.S. Express Freight Rates 64 International Express Package Rates 65 U.S. Export 65–81 Multiweight, U.S. Export 82 U.S. Import 83–97 Multiweight, U.S. Import 98 FedEx® International Next Flight, U.S. -

List of Postal Codes
List of postal codes This list shows an overview of postal code notation schemes for all countries that have postal or ZIP code systems. Key • A: Letters. • 9: Digits. • *: Postal code placed to the right of the region, city, suburb or town. A-B • Afghanistan : No postal code used. • Åland : (AX-)99999 Note: Country code: AX even though part of the Finnish postal code system. • Albania : (AL-)9999. Introduced in 2006, gradually implemented throughout 2007. • Algeria : 99999 http://www.postal-codes.net/Algeria%20_Postal_Codes.html • American Samoa : 99999* or 99999-9999*. US territory - part of the US zip-code system. • Andorra : AD999 each parish now has its own post code. See http://www.postal- codes.net/Andorra_Postal_Codes.html • Angola : No postal code used. • Anguilla : AI-2640. Single code used for all addresses. • Antigua and Barbuda : No postal code used. • Argentina : A9999AAA. The first letter (A) indicates the province, the four numbers (9999) are the old postal codes, the three last letters (AAA) indicate a side of the block. Previously 9999 which remains the minimum requirement as of 2006. See also Argentine postal code. • Armenia : 9999 since April 1, 2006. Previously used 999999 system inherited from former Soviet Union. See Armenian postal codes. • Aruba : No postal code used. • Ascension Island : ASCN 1ZZ. Single code used for all addresses. • Australia : known as the "postcode": 9999*. In general, the first digit identifies the state or territory. See List of postal codes in Australia • Australian Antarctic Territory : 9999*. Part of the Australian postcode system. • Austria : (A- or AT-)9999 (the first digit denotes one of the nine provinces -- called Bundesländer --, the last the nearest post office in the area) • Azerbaijan : AZ9999 Previously used 999999 system inherited from former Soviet Union. -
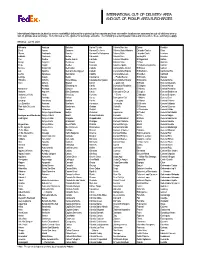
Out of Delivery Area
INTERNATIONAL OUT-OF-DELIVERY-AREA AND OUT-OF-PICKUP-AREA SURCHARGES International shipments (subject to service availability) delivered to or picked up from remote and less-accessible locations are assessed an out-of-delivery area or out-of-pickup-area surcharge. Refer to local service guides for surcharge amounts. The following is a list of postal codes and cities where these surcharges apply. Effective: Jul 19, 2021 Albania Anatuya Baterias Carlos Tejedor Colonia San Jose Ducos Franklin Berat Ancon Bayauca Carmen De Areco Colonia Santa Mariana Eduardo Castex Frias Durres Andalgala Beazley Carmen De Patagones Colonia Sello Eduardo Costa Frontera Elbasan Anderson Belloq Carmensa Colonia Sere Egusquiza Fuentes Fier Andino Benito Juarez Carrilobo Colonia Valentina El Algarrobal Gahan Kavaje Angelica Berabevu Casas Colonia Velaz El Alva Gaiman Kruje Anguil Berdier Cascada Colonia Zapata El Arbolito Pergamino Galvan Kucove Anquincila Bermudez Casilda Comandante Arnold El Bolson Galvez Lac Aparicio Bernardo De Irigoyen Castelli Comandante Espora El Borbollon Garcia Del Rio Lezha Apostoles Berrotaran Castilla Comandante Luis El Calden Garibaldi Lushnje Araujo Beruti Catamarca - Piedra Buena El Dorado Garupa Shkodra Arbolito Bialet Masse Cataratas Del Iguazu Comandante Nicanor El Durazno General Acha Vlore Arbuco Bigand Catriel - Otamendi El Fortin General Alvarado Arcadia Blandengues Catrilo Comodoro Rivadavia El Galpon General Alvear Andorra* Arenaza Blaquier Caucete Concepcion El Hueco General Arenales Andorra Argerich Blas Duranona Cauta -

The Pennsylvania State University the Graduate School
The Pennsylvania State University The Graduate School Department of Geography EXPLORING REGIONAL VARIATION IN SPATIAL LANGUAGE: A CASE STUDY ON SPATIAL ORIENTATION BY USING VOLUNTEERED SPATIAL LANGUAGE DATA A Thesis in Geography by Sen Xu ©2010 Sen Xu Submitted in Partial Fulfillment of the Requirements for the Degree of Master of Science August 2010 ii The Thesis of Sen Xu was reviewed and approved* by the following: Alexander Klippel Assistant Professor of Geography Thesis Advisor Alan MacEachren Professor of Geography Karl Zimmerer Professor of Geography Head of the Department of Geography *Signatures are on file in the Graduate School iii ABSTRACT This thesis seeks to answer the question of how spatial language varies regionally within the same language on a geographic scale. Spatial language, such as route directions, is language pertaining to spatial situations and spatial relationships between objects. Spatial language is an important medium through which we study humans’ representation, perception, and communication of spatial information. Existing spatial language studies mostly use data collected via time-consuming experiments, which are therefore limited to a small sample size—thus limiting the detection of how spatial language varies from one region to another. More recently, larger sample sizes have become possible due to the abundance of volunteered spatial language data on the World Wide Web (WWW), such as directions on hotels’ websites. This data is a potential source for scaling up the analysis of spatial language data. Sourcing from the WWW, a spatial language data collection scheme has been developed. Automated web- crawling, spatial language text document classification based on computational linguistic methods, and geo-referencing of text documents are used to build a spatially- stratified corpus. -

International Out-Of-Delivery-Area and Out-Of-Pickup-Area Surcharges
INTERNATIONAL OUT-OF-DELIVERY-AREA AND OUT-OF-PICKUP-AREA SURCHARGES International shipments (subject to service availability) delivered to or picked up from remote and less-accessible locations are assessed an out-of-delivery area or out-of-pickup-area surcharge. Refer to local service guides for surcharge amounts. The following is a list of postal codes and cities where these surcharges apply. Effective: July 18, 2016 Albania Daireaux Puerto Tirol 0909 3230-3232 3515-3518 3795-3797 Berat Diamante Quequen 2327-2329 3233 3520 3799 Durres Dolores Reconquista 2331 3235 3521-3523 3804-3810 Elbasan Dorrego Retiro San Pablo 2333-2347 3236-3239 3525 3812-3814 Fier El Bolson Rincon De Los Sauces 2350-2360 3240-3241 3527 3815 Kavaje El Durazno Rio Ceballos 2365 3242-3243 3529-3531 3816 Kruje El Trebol Rio Segundo 2369-2372 3249-3251 3533 3818 Kucove Embalse Rio Tala 2379-2382 3254 3537 3820-3822 Lac Emilio Lamarca Rojas 2385-2388 3260 3540 3823-3825 Lezha Esquel Rosario De Lerma 2390 3264-3274 3542 3831 Lushnje Fair Rufino 2394-2411 3276-3282 3544 3833 Shkodra Famailla Russel 2415 3284 3546 3835 Vlore Firmat Salina De Piedra 2420-2431 3286-3287 3549 3840 Florentino Ameghino Salsipuedes 2439-2441 3289 3557-3559 3842 Andorra* Franck Salto 2443-2450 3292-3294 3561-3568 3844 Andorra General Alvarado Samborombon 2452-2456 3300-3305 3570-3573 3847 Andorra La Vella General Belgrano San Andres De Giles 2460 3309-3312 3575-3576 3850-3852 El Serrat General Galarza San Bernardo Del Tuyu 2462-2466 3314-3315 3578-3581 3854 Encamp General Guemes San Clemente -

Fedex Service Guide
SERVICE GUIDE fedex.com/serviceguide January 7, 2019 Updated November 1, 2019 SERVICES RATES TERMS INDEX CONTENTS SERVICES RATES TERMS INDEX Contents This book includes an overview of FedEx® services; FedEx Express and FedEx Ground standard list rates effective January 7, 2019, for U.S., U.S. export and U.S. import services; FedEx One Rate® pricing for FedEx Express® U.S. services; FedEx Express Terms and Conditions; the FedEx Ground Tariff; and the FedEx SameDay® City Tariff. This information, along with U.S. retail rates1 and the service information at fedex.com/serviceguide, constitutes the FedEx Service Guide. The service information at fedex.com/serviceguide (excluding rates, the FedEx Express Terms and Conditions, the FedEx Ground Tariff, and the FedEx SameDay City Tariff) and the overview of services in this book are not part of the contract of carriage. Overview of Services 2–19 Standard List Rate, Surcharge and Fee Changes 22 How to Calculate Your Rate 23 Zone Charts 24 International Express Package 24–26 International Express Freight 27 Canada 28 U.S. Express Package Rates 29 Zones 2–8 29–49 To Alaska and Hawaii 50–52 From Alaska and Hawaii 53–54 Within Hawaii 55 Multiweight 56–57 FedEx SameDay® and FedEx SameDay® Freight 58–59 FedEx SameDay City Rates 60–62 FedEx One Rate 63 U.S. Express Freight Rates 64 International Express Package Rates 65 U.S. Export 65–81 Multiweight, U.S. Export 82 U.S. Import 83–97 Multiweight, U.S. Import 98 FedEx® International Next Flight, U.S. Export 99–100 FedEx International Next Flight, U.S.