© Copyright 2018 Nicholas Robison
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Rural Non-Farm Income and Inequality in Nigeria
2. BACKGROUND INFORMATION, DATA AND SURVEY AREA The utilized data were collected from five different villages surveyed in rural Northern Nigeria between 2004 and 2005. These villages are situated within the Hadejia-Nguru floodplain wetlands of Jigawa state in Northern Nigeria. Data were collected from 200 households selected using a multi-stage stratified random sampling approach. The first sampling stratum was selection of the dry savanna region of northern Nigeria, which comprises six states: Sokoto, Kebbi, Zamfara, Kano, Kaduna and Jigawa. The second stratum was the selection of Jigawa state. Two important elements informed this choice. First, Jigawa state, which was carved out of Kano state in August 1991, has the highest rural population in Nigeria; about 93 percent of the state’s population dwells in rural areas3. Second, agriculture is the dominant sector of the state’s economy, providing employment for over 90 percent of the active labor force. For effective grassroots coverage of the various agricultural activities in Jigawa state, the Jigawa Agricultural and Rural Development (JARDA) is divided into four operational zones that are headquartered in the cities of Birni Kudu, Gumel, Hadejia and Kazaure. Hadejia was selected for this study, forming the third stratum of sampling. Within the Hadejia emirate, there are eight Local Government Areas (LGAs): Auyo, Birniwa, Hadejia, Kaffin-Hausa, Mallam Madori, Kaugama, Kirikasamma and Guri. Kirikasamma LGA was selected for this study, representing the fourth sampling stratum. Kirikassama LGA was specifically chosen because of the area’s intensive economic development and correspondingly higher human population compared to many other parts of Nigeria. In the fifth stratum of sampling, five villages were selected from Kirikassama LGA: Jiyan, Likori, Matarar Galadima, Turabu and Madachi. -

Nigeria's Constitution of 1999
PDF generated: 26 Aug 2021, 16:42 constituteproject.org Nigeria's Constitution of 1999 This complete constitution has been generated from excerpts of texts from the repository of the Comparative Constitutions Project, and distributed on constituteproject.org. constituteproject.org PDF generated: 26 Aug 2021, 16:42 Table of contents Preamble . 5 Chapter I: General Provisions . 5 Part I: Federal Republic of Nigeria . 5 Part II: Powers of the Federal Republic of Nigeria . 6 Chapter II: Fundamental Objectives and Directive Principles of State Policy . 13 Chapter III: Citizenship . 17 Chapter IV: Fundamental Rights . 20 Chapter V: The Legislature . 28 Part I: National Assembly . 28 A. Composition and Staff of National Assembly . 28 B. Procedure for Summoning and Dissolution of National Assembly . 29 C. Qualifications for Membership of National Assembly and Right of Attendance . 32 D. Elections to National Assembly . 35 E. Powers and Control over Public Funds . 36 Part II: House of Assembly of a State . 40 A. Composition and Staff of House of Assembly . 40 B. Procedure for Summoning and Dissolution of House of Assembly . 41 C. Qualification for Membership of House of Assembly and Right of Attendance . 43 D. Elections to a House of Assembly . 45 E. Powers and Control over Public Funds . 47 Chapter VI: The Executive . 50 Part I: Federal Executive . 50 A. The President of the Federation . 50 B. Establishment of Certain Federal Executive Bodies . 58 C. Public Revenue . 61 D. The Public Service of the Federation . 63 Part II: State Executive . 65 A. Governor of a State . 65 B. Establishment of Certain State Executive Bodies . -

Survey Report for Out-Of-School Children in Jigawa
SURVEY REPORT FOR OUT-OF-SCHOOL CHILDREN IN JIGAWA STATE, NIGERIA CO-ORDINATED BY JIGAWA STATE GOVERNMENT IN COLLABORATION WITH ESSPIN August, 2014 Page | 1 Table of Contents Cover page i Acknowledgements iii Preface iv List of Tables v List of Figures vi Acronyms vii Executive Summary viii Section One: Introduction 1 1.1 Background 1 1.2 Objectives 2 1.3 Framework for Out-of-School Children 2 1.4 Profile of Jigawa State 4 Section Two: Methodology 6 2.1 Survey Planning for Out-of-School Children 6 2.2 Sampling Design 7 2.3 Data Quality and Supervision 7 2.4 Pilot Survey 8 2.5 Process of Data Collection and Analysis 9 Section Three: Results for Out-of-School Children 10 3.1 Number of Households and Population Size 10 3.2 Number of Out-of-School Children 12 3.3 Number of Children Attending Schools 20 3.4 Percentages of Out-of-School Children 24 Section Four: Possible Risk Factors for Out-of-School Children 27 4.1 Reasons for Out-of-School Children 27 4.2 Socio-Economic Relationships with Out-of-School Status 28 Section Five: Conclusion and Recommendations 42 5.1 Conclusion 42 5.2 Suggestions and the way forward 45 5.3 Limitations 46 References 47 Appendix A: Questionnaire 48 Page | 2 Appendix B: Interview Guide 52 Appendix C: Number of Children in the Sampled Household 53 Appendix D: Percentages of Children that Dropout from School 54 Appendix E: Percentages of Children that Never Attended School 55 Appendix F: Percentages of Children Attending Only Islamiyya/Quranic 56 Schools Appendix G: Percentages of Children Attending any Form of School 57 Appendix H: Population Projection (3-18) by Age, Sex and LGA, 2014 58 Appendix I: Sampling Variability and Ranges for OOS Children 59 Page | 3 Acknowledgements Education planning is incomplete without credible statistics on out-of-school children. -

A Study of Violence-Related Deaths in Nafada Local Government Area Of
# Makai DANIEL http://www.ifra-nigeria.org/IMG/pdf/violence-related-deaths-gombe-jigawa-state-nigeria.pdf A Study of Violence-Related Deaths in Nafada Local Government Area of Gombe State and Auyo, Gagarawa, Gumel, Gwiwa, Kaugama and Yankwasi Local Government Areas of Jigawa State (2006-2014) IFRA-Nigeria working papers series, n°46 20/01/2015 The ‘Invisible Violence’ Project Based in the premises of the French Institute for Research in Africa on the campus of the University of Ibadan, Nigeria Watch is a database project that has monitored fatal incidents and human security in Nigeria since 1 June 2006. The database compiles violent deaths on a daily basis, including fatalities resulting from accidents. It relies on a thorough reading of the Nigerian press (15 dailies & weeklies) and reports from human rights organisations. The two main objectives are to identify dangerous areas and assess the evolution of violence in the country. However, violence is not always reported by the media, especially in remote rural areas that are difficult to access. Hence, in the last 8 years, Nigeria Watch has not recorded any report of fatal incidents in some of the 774 Local Government Areas (LGAs) of the Nigerian Federation. There are two possibilities: either these places were very peaceful, or they were not covered by the media. This series of surveys thus investigates ‘invisible’ violence. By 1 November 2014, there were still 23 LGAs with no report of fatal incidents in the Nigeria Watch database: Udung Uko and Urue-Offong/Oruko (Akwa Ibom), Kwaya Kusar (Borno), Nafada (Gombe), Auyo, Gagarawa, Kaugama and Yankwashi (Jigawa), Ingawa and Matazu (Katsina), Sakaba (Kebbi), Bassa, Igalamela- Odolu and Mopa-Muro (Kogi), Toto (Nassarawa), Ifedayo (Osun), Gudu and Gwadabaw (Sokoto), Ussa (Taraba), and Karasuwa, Machina, Nguru and Yunusari (Yobe). -

Survey of Functional and Non-Functional Fish Hatchery in Jigawa State, Nigeria
Survey of functional and non-functional fish hatchery in Jigawa State, Nigeria Item Type conference_item Authors Nasir, M.A.; Farida, S.; Laurat, T.; Nafisat, M.D.; Awawu, D. Publisher FISON Download date 29/09/2021 05:13:55 Link to Item http://hdl.handle.net/1834/39009 94 Survey of functional and non-functional fish hatchery in Jigawa State, Nigeria Nasir, M.A. / Farida, S./ Laurai, T./ Nafisat, M. D. / Awawu, D. Abstract This study was conducted in thefive emirate zones of Jigawa. The number offunctional and non-functional fish hatcheries wereinveJo tigated in the state. The results showed that there were 35fish hatcheries in the state, and private ownership (57.J 4%) dominatethl government ownership (42.16%). all with less than 100,000fingerlings production annually. The study also indicate that out ofthl 35fish hatcheries J 5 werefound to befunctional in operation and 20 arefound existing but notfunctional in operation. Based ontilt field survey, all the respondent are of the opinion that the level of production and number of'functional hatcheries in the state arelow Recommendations were made on how to improve hatchery operation that could help to boost aquaculture development in the state. Keywords: Jigawa, fish hatchery.functional, non-functional. Introduction ish is a rich source of animal protein and its culture is an efficient protein food production system from aquatic environ ment (Olanrewaju et al., 2009). There is no doubt that fish production through aquaculture in Jigawa state is at its infan Fstage. Much attention been directed towards increasing fish production through aquaculture in Nigeria, because ofth economic and nutritional importance offish to the populace.However, it is often negligible in Jigawa state because of certai constraints which fish seed scarcity is inclusive (Adamu et al., 1993). -

Research Article Prevalence of Bovine Brucellosis and Risk Factors Assessment in Cattle Herds in Jigawa State
International Scholarly Research Network ISRN Veterinary Science Volume 2011, Article ID 132897, 4 pages doi:10.5402/2011/132897 Research Article Prevalence of Bovine Brucellosis and Risk Factors Assessment in Cattle Herds in Jigawa State Farouk U. Mohammed,1 Salisu Ibrahim,2 Ikwe Ajogi,3 and Bale J. O. Olaniyi4 1 Animal Reproduction Unit, Jigawa Research Institute, Kazaure, Jigawa State, Nigeria 2 Department of Veterinary Surgery and Medicine, Faculty of Veterinary Medicine, Ahmadu Bello University, P.O. Box 720 Zaria, Kaduna state, Nigeria 3 Department of Veterinary Public Health and Preventive Medicine, Faculty of Veterinary Medicine, Ahmadu Bello University, P.O. Box 720 Zaria, Kaduna state, Nigeria 4 National Animal Production Research Institute Shika, Ahmadu Bello University, P.O. Box 720 Zaria, Kaduna state, Nigeria Correspondence should be addressed to Salisu Ibrahim, [email protected] Received 2 November 2011; Accepted 7 December 2011 Academic Editor: I. Lopez´ Goni˜ Copyright © 2011 Farouk U. Mohammed et al. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. A serological survey of Brucella antibodies was carried out in Jigawa State, northwestern Nigeria to determine the prevalence of the disease and risk factors among some pastoralist cattle herds. A total of 570 cattle of differentagesandsexesselectedfrom 20 herds across the four agroecological zones in the state were screened using Rose Bengal Plate test and competitive enzyme immunoassay. From the results 23 cattle (4.04%) were positive by Rose Bengal Plate Test while 22(3.86%) were positive with competitive enzyme immunoassay. -
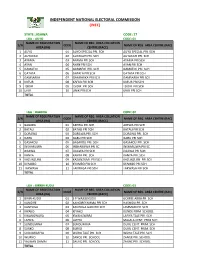
Jigawa Code: 17 Lga : Auyo Code: 01 Name of Registration Name of Reg
INDEPENDENT NATIONAL ELECTORAL COMMISSION (INEC) STATE: JIGAWA CODE: 17 LGA : AUYO CODE: 01 NAME OF REGISTRATION NAME OF REG. AREA COLLATION S/N CODE NAME OF REG. AREA CENTRE (RAC) AREA (RA) CENTRE (RACC) 1 AUYO 01 AUYO SPECIAL PRI. SCH AUYO SPECIAL PRI. SCH 2 AUYAKAYI 02 AUYAKAYI PRI. SCH AUYAKAYI PRI. SCH 3 AYAMA 03 AYAMA PRI SCH AYAMA PRI SCH 4 AYAN 04 AYAN PRI SCH AYAN PRI SCH 5 GAMAFOI 05 GAMAFOI PRI. SCH GAMAFOI PRI. SCH 6 GATAFA 06 GATAFA PRI SCH GATAFA PRI SCH 7 GAMSARKA 07 GAMSARKA PRI SCH GAMSARKA PRI SCH 8 KAFUR 08 KAFUR PRI SCH KAFUR PRI SCH 9 TSIDIR 09 TSIDIR PRI SCH TSIDIR PRI SCH 10 UNIK 10 UNIK PRI SCH UNIK PRI SCH TOTAL LGA : BABURA CODE: 02 NAME OF REGISTRATION NAME OF REG. AREA COLLATION S/N CODE NAME OF REG. AREA CENTRE (RAC) AREA (RA) CENTRE (RACC) 1 BABURA 01 AREWA PRI.SCH AREWA PRI.SCH 2 BATALI 02 BATALI PRI SCH BATALI PRI SCH 3 DORAWA 03 DORAWA PRI. SCH DORAWA PRI. SCH 4 GARU 04 GARU PRI SCH GARU PRI SCH 5 GASAKOLI 05 GASAKOLI PRI. SCH GASAKOLI PRI. SCH 6 INSHARUWA 06 INSHARUWA PRI SC INSHARUWA PRI SC 7 JIGAWA 07 JIGAWA PRI SCH JIGAWA PRI SCH 8 KANYA 08 KANYA PRI. SCH KANYA PRI. SCH 9 KAZUNZUMI 09 KAZUNZUMI PRI SCH KAZUNZUMI PRI SCH 10 KYAMBO 10 KYAMBO PRI SCH KYAMBO PRI SCH 11 TAKWASA 11 TAKWASA PRI SCH TAKWASA PRI SCH TOTAL LGA : BIRRIN-KUDU CODE: 03 NAME OF REGISTRATION NAME OF REG. -

States and Lcdas Codes.Cdr
PFA CODES 28 UKANEFUN KPK AK 6 CHIBOK CBK BO 8 ETSAKO-EAST AGD ED 20 ONUIMO KWE IM 32 RIMIN-GADO RMG KN KWARA 9 IJEBU-NORTH JGB OG 30 OYO-EAST YYY OY YOBE 1 Stanbic IBTC Pension Managers Limited 0021 29 URU OFFONG ORUKO UFG AK 7 DAMBOA DAM BO 9 ETSAKO-WEST AUC ED 21 ORLU RLU IM 33 ROGO RGG KN S/N LGA NAME LGA STATE 10 IJEBU-NORTH-EAST JNE OG 31 SAKI-EAST GMD OY S/N LGA NAME LGA STATE 2 Premium Pension Limited 0022 30 URUAN DUU AK 8 DIKWA DKW BO 10 IGUEBEN GUE ED 22 ORSU AWT IM 34 SHANONO SNN KN CODE CODE 11 IJEBU-ODE JBD OG 32 SAKI-WEST SHK OY CODE CODE 3 Leadway Pensure PFA Limited 0023 31 UYO UYY AK 9 GUBIO GUB BO 11 IKPOBA-OKHA DGE ED 23 ORU-EAST MMA IM 35 SUMAILA SML KN 1 ASA AFN KW 12 IKENNE KNN OG 33 SURULERE RSD OY 1 BADE GSH YB 4 Sigma Pensions Limited 0024 10 GUZAMALA GZM BO 12 OREDO BEN ED 24 ORU-WEST NGB IM 36 TAKAI TAK KN 2 BARUTEN KSB KW 13 IMEKO-AFON MEK OG 2 BOSARI DPH YB 5 Pensions Alliance Limited 0025 ANAMBRA 11 GWOZA GZA BO 13 ORHIONMWON ABD ED 25 OWERRI-MUNICIPAL WER IM 37 TARAUNI TRN KN 3 EDU LAF KW 14 IPOKIA PKA OG PLATEAU 3 DAMATURU DTR YB 6 ARM Pension Managers Limited 0026 S/N LGA NAME LGA STATE 12 HAWUL HWL BO 14 OVIA-NORTH-EAST AKA ED 26 26 OWERRI-NORTH RRT IM 38 TOFA TEA KN 4 EKITI ARP KW 15 OBAFEMI OWODE WDE OG S/N LGA NAME LGA STATE 4 FIKA FKA YB 7 Trustfund Pensions Plc 0028 CODE CODE 13 JERE JRE BO 15 OVIA-SOUTH-WEST GBZ ED 27 27 OWERRI-WEST UMG IM 39 TSANYAWA TYW KN 5 IFELODUN SHA KW 16 ODEDAH DED OG CODE CODE 5 FUNE FUN YB 8 First Guarantee Pension Limited 0029 1 AGUATA AGU AN 14 KAGA KGG BO 16 OWAN-EAST -

As Climate Change Responds with Terrifying Brutalities
International Journal of Environment and Climate Change 10(12): 322-330, 2020; Article no.IJECC.63814 ISSN: 2581-8627 (Past name: British Journal of Environment & Climate Change, Past ISSN: 2231–4784) As Climate Change Responds with Terrifying Brutalities Nura Jibo MRICS1* 1African Climate Change Research Centre, United Nations Climate Observer Organization, Third Floor, Block B, New Secretariat Complex, Dutse, Jigawa State, Nigeria. Author’s contribution The sole author designed, analysed, interpreted and prepared the manuscript. Article Information DOI: 10.9734/IJECC/2020/v10i1230308 Editor(s): (1) Dr. Anthony R. Lupo, University of Missouri, USA. Reviewers: (1) Ali Didevarasl, University of Sassari, Italy. (2) Atilio Efrain Bica Grondona, Universidade do Vale do Rio dos Sinos (UNISINOS), Brazil. (3) Derling Jose Mendoza Velazco, Universidad UTE & Universidad Nacional de Educación (UNAE), Ecuador. Complete Peer review History: http://www.sdiarticle4.com/review-history/63814 Received 24 October 2020 Accepted 29 December 2020 Short Research Article Published 31 December 2020 ABSTRACT Introduction: The lip service in tackling the climate change issues five years after the famous Paris Agreement on climate change is quite unwholesome to individual countries' pledges and promises that were made on reducing global carbon emissions at Le Bourget, France. The attempt to limit the global mean temperature to 1.50 Celsius preindustrial level has even resulted in warming the climate more than anticipated [1]. The bulk of the climate change adaptation and mitigation effort(s) have, generally, ended up in a tragic fiasco. The rise in sea level and temperature overshoot carry substantial and enormous risks and uncertainties that have caused the entire humanity to head towards an irreversible crossing tipping point [2]. -

Dutse Journal of Pure and Applied Sciences (Dujopas)
DUTSE JOURNAL OF PURE AND APPLIED SCIENCES (DUJOPAS) A Quarterly Publication of the Faculty of Science, Federal University Dutse, Jigawa State – Nigeria Vol. 6 No. 4 December, 2020 ISSN (Print): 2476-8316 ISSN (Online): 2635-3490 Dutse Journal of Pure and Applied Sciences (DUJOPAS) is published by: The Faculty of Science, Federal University Dutse. Jigawa State – Nigeria. Printed by: KABOD LIMITED NL 7 Lokoja Road, Kaduna State, Nigeria. +234(0)8030628933 [email protected] ISSN (Print): 2476-8316 ISSN (Online): 2635-3490 Copy rights: All right of this publication are reserved. No part of this Journal may be reproduced, stored in a retrieval system or transmitted in any form by any means without prior permission of the publisher, except for academic purposes. Note: The articles published in this Journal do not in any way reflect the views nor position of DUJOPAS. Authors are individually responsible for all issues relating to their articles. Except for publication and copy rights, any issue arising from an article in this Journal should be addressed directly to the Author. ii GUIDE TO AUTHORS DUJOPAS is a publication of the Faculty of Science, Federal University Dutse, Jigawa State, Nigeria. It is an international peer-reviewed journal that publishes four issues in a year (March, June, September & December). The Journal publishes papers with original contributions to scientific knowledge in all fields of natural, life and applied sciences. Authors submitting papers for publication must adhere strictly to the following guidelines: 1. Research articles should be in the English language. Articles in other languages are NOT entertained. Correction of English language is not the responsibility of the Editorial Board of DUJOPAS. -

JIGAWA STATE DUE PROCESS and PROJECT MONITORING BUREAU CONTRACT AWARDED June, 2021 C O N EXECUTING S/N DATE PROJECT CONTRACT NO
JIGAWA STATE DUE PROCESS AND PROJECT MONITORING BUREAU CONTRACT AWARDED June, 2021 C O N EXECUTING S/N DATE PROJECT CONTRACT NO. CONTRACTOR AMOUNT (N) COMP.PERIOD T MINISTRIES R A C 1 24/06/2021 Constr. Of Drainage at Akurya Town in Malam Madori Constituency (Lot-10) JEC/420/2021/VOL.I/6 Ramadan Constr. Nig Ltd 7,167,111.00 Min of Environment 8 weeks 2 24/06/2021 Constr. Of Drainage at Abuja Gusau Road in Gumel Constituency (Lot-2) JEC/413/2021/VOL.I/6 Pullad Global Consult Ltd 14,630,406.00 Min of Environment 12 Weeks 3 24/06/2021 Constr. Of Drainage at Dan'Ama Village in Gumel Constituency (Lot-3) JEC/414/2021/VOL.I/6 Pullad Global Consult Ltd 6,797,016.45 Min of Environment 8 weeks 4 24/06/2021 Constr. Of Drainage at Galagamma Quarters in Gumel Constituency (Lot-4) JEC/415/2021/VOL.I/6 Pullad Global Consult Ltd 1,198,450.31 Min of Environment 12 Weeks 5 Baban Doki Gen Ent Nig 24/06/2021 Purchase of 1No. Toyota Hilux Operational Vehicle 2020 Model JEC/426/2021/VOL.I/5 Ltd 28,215,500.00 Min of Health 3 weeks 6 24/06/2021 Constr. Of Emergency Operation Centre at Isolation Centre at Danmasara in Dutse LGA JEC/424/2021/VOL.I/5 Husna Constr. Nig Ltd 34,874,178.40 Min of Health 3 Months 7 24/06/2021 Constr. Of Drainge at Sarkin Baka Town in Kanya Babba Constituency of Babura LGA (Lot-5) JEC/416/2021/VOL.I/6 Deetech Nig Ltd 8,804,353.48 Min of Environment 12 Weeks 8 24/06/2021 Constr. -

Nigeria Security Situation
Nigeria Security situation Country of Origin Information Report June 2021 More information on the European Union is available on the Internet (http://europa.eu) PDF ISBN978-92-9465-082-5 doi: 10.2847/433197 BZ-08-21-089-EN-N © European Asylum Support Office, 2021 Reproduction is authorised provided the source is acknowledged. For any use or reproduction of photos or other material that is not under the EASO copyright, permission must be sought directly from the copyright holders. Cover photo@ EU Civil Protection and Humanitarian Aid - Left with nothing: Boko Haram's displaced @ EU/ECHO/Isabel Coello (CC BY-NC-ND 2.0), 16 June 2015 ‘Families staying in the back of this church in Yola are from Michika, Madagali and Gwosa, some of the areas worst hit by Boko Haram attacks in Adamawa and Borno states. Living conditions for them are extremely harsh. They have received the most basic emergency assistance, provided by our partner International Rescue Committee (IRC) with EU funds. “We got mattresses, blankets, kitchen pots, tarpaulins…” they said.’ Country of origin information report | Nigeria: Security situation Acknowledgements EASO would like to acknowledge Stephanie Huber, Founder and Director of the Asylum Research Centre (ARC) as the co-drafter of this report. The following departments and organisations have reviewed the report together with EASO: The Netherlands, Ministry of Justice and Security, Office for Country Information and Language Analysis Austria, Federal Office for Immigration and Asylum, Country of Origin Information Department (B/III), Africa Desk Austrian Centre for Country of Origin and Asylum Research and Documentation (ACCORD) It must be noted that the drafting and review carried out by the mentioned departments, experts or organisations contributes to the overall quality of the report, but does not necessarily imply their formal endorsement of the final report, which is the full responsibility of EASO.