Improved Nucleosome-Positioning Algorithm Inps for Accurate Nucleosome Positioning from Sequencing Data
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

4-6 Weeks Old Female C57BL/6 Mice Obtained from Jackson Labs Were Used for Cell Isolation
Methods Mice: 4-6 weeks old female C57BL/6 mice obtained from Jackson labs were used for cell isolation. Female Foxp3-IRES-GFP reporter mice (1), backcrossed to B6/C57 background for 10 generations, were used for the isolation of naïve CD4 and naïve CD8 cells for the RNAseq experiments. The mice were housed in pathogen-free animal facility in the La Jolla Institute for Allergy and Immunology and were used according to protocols approved by the Institutional Animal Care and use Committee. Preparation of cells: Subsets of thymocytes were isolated by cell sorting as previously described (2), after cell surface staining using CD4 (GK1.5), CD8 (53-6.7), CD3ε (145- 2C11), CD24 (M1/69) (all from Biolegend). DP cells: CD4+CD8 int/hi; CD4 SP cells: CD4CD3 hi, CD24 int/lo; CD8 SP cells: CD8 int/hi CD4 CD3 hi, CD24 int/lo (Fig S2). Peripheral subsets were isolated after pooling spleen and lymph nodes. T cells were enriched by negative isolation using Dynabeads (Dynabeads untouched mouse T cells, 11413D, Invitrogen). After surface staining for CD4 (GK1.5), CD8 (53-6.7), CD62L (MEL-14), CD25 (PC61) and CD44 (IM7), naïve CD4+CD62L hiCD25-CD44lo and naïve CD8+CD62L hiCD25-CD44lo were obtained by sorting (BD FACS Aria). Additionally, for the RNAseq experiments, CD4 and CD8 naïve cells were isolated by sorting T cells from the Foxp3- IRES-GFP mice: CD4+CD62LhiCD25–CD44lo GFP(FOXP3)– and CD8+CD62LhiCD25– CD44lo GFP(FOXP3)– (antibodies were from Biolegend). In some cases, naïve CD4 cells were cultured in vitro under Th1 or Th2 polarizing conditions (3, 4). -

Transcriptional Control of Tissue-Resident Memory T Cell Generation
Transcriptional control of tissue-resident memory T cell generation Filip Cvetkovski Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2019 © 2019 Filip Cvetkovski All rights reserved ABSTRACT Transcriptional control of tissue-resident memory T cell generation Filip Cvetkovski Tissue-resident memory T cells (TRM) are a non-circulating subset of memory that are maintained at sites of pathogen entry and mediate optimal protection against reinfection. Lung TRM can be generated in response to respiratory infection or vaccination, however, the molecular pathways involved in CD4+TRM establishment have not been defined. Here, we performed transcriptional profiling of influenza-specific lung CD4+TRM following influenza infection to identify pathways implicated in CD4+TRM generation and homeostasis. Lung CD4+TRM displayed a unique transcriptional profile distinct from spleen memory, including up-regulation of a gene network induced by the transcription factor IRF4, a known regulator of effector T cell differentiation. In addition, the gene expression profile of lung CD4+TRM was enriched in gene sets previously described in tissue-resident regulatory T cells. Up-regulation of immunomodulatory molecules such as CTLA-4, PD-1, and ICOS, suggested a potential regulatory role for CD4+TRM in tissues. Using loss-of-function genetic experiments in mice, we demonstrate that IRF4 is required for the generation of lung-localized pathogen-specific effector CD4+T cells during acute influenza infection. Influenza-specific IRF4−/− T cells failed to fully express CD44, and maintained high levels of CD62L compared to wild type, suggesting a defect in complete differentiation into lung-tropic effector T cells. -
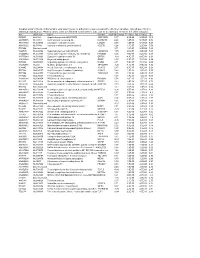
Supplementary File 2A Revised
Supplementary file 2A. Differentially expressed genes in aldosteronomas compared to all other samples, ranked according to statistical significance. Missing values were not allowed in aldosteronomas, but to a maximum of five in the other samples. Acc UGCluster Name Symbol log Fold Change P - Value Adj. P-Value B R99527 Hs.8162 Hypothetical protein MGC39372 MGC39372 2,17 6,3E-09 5,1E-05 10,2 AA398335 Hs.10414 Kelch domain containing 8A KLHDC8A 2,26 1,2E-08 5,1E-05 9,56 AA441933 Hs.519075 Leiomodin 1 (smooth muscle) LMOD1 2,33 1,3E-08 5,1E-05 9,54 AA630120 Hs.78781 Vascular endothelial growth factor B VEGFB 1,24 1,1E-07 2,9E-04 7,59 R07846 Data not found 3,71 1,2E-07 2,9E-04 7,49 W92795 Hs.434386 Hypothetical protein LOC201229 LOC201229 1,55 2,0E-07 4,0E-04 7,03 AA454564 Hs.323396 Family with sequence similarity 54, member B FAM54B 1,25 3,0E-07 5,2E-04 6,65 AA775249 Hs.513633 G protein-coupled receptor 56 GPR56 -1,63 4,3E-07 6,4E-04 6,33 AA012822 Hs.713814 Oxysterol bining protein OSBP 1,35 5,3E-07 7,1E-04 6,14 R45592 Hs.655271 Regulating synaptic membrane exocytosis 2 RIMS2 2,51 5,9E-07 7,1E-04 6,04 AA282936 Hs.240 M-phase phosphoprotein 1 MPHOSPH -1,40 8,1E-07 8,9E-04 5,74 N34945 Hs.234898 Acetyl-Coenzyme A carboxylase beta ACACB 0,87 9,7E-07 9,8E-04 5,58 R07322 Hs.464137 Acyl-Coenzyme A oxidase 1, palmitoyl ACOX1 0,82 1,3E-06 1,2E-03 5,35 R77144 Hs.488835 Transmembrane protein 120A TMEM120A 1,55 1,7E-06 1,4E-03 5,07 H68542 Hs.420009 Transcribed locus 1,07 1,7E-06 1,4E-03 5,06 AA410184 Hs.696454 PBX/knotted 1 homeobox 2 PKNOX2 1,78 2,0E-06 -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Deep Multiomics Profiling of Brain Tumors Identifies Signaling Networks
ARTICLE https://doi.org/10.1038/s41467-019-11661-4 OPEN Deep multiomics profiling of brain tumors identifies signaling networks downstream of cancer driver genes Hong Wang 1,2,3, Alexander K. Diaz3,4, Timothy I. Shaw2,5, Yuxin Li1,2,4, Mingming Niu1,4, Ji-Hoon Cho2, Barbara S. Paugh4, Yang Zhang6, Jeffrey Sifford1,4, Bing Bai1,4,10, Zhiping Wu1,4, Haiyan Tan2, Suiping Zhou2, Laura D. Hover4, Heather S. Tillman 7, Abbas Shirinifard8, Suresh Thiagarajan9, Andras Sablauer 8, Vishwajeeth Pagala2, Anthony A. High2, Xusheng Wang 2, Chunliang Li 6, Suzanne J. Baker4 & Junmin Peng 1,2,4 1234567890():,; High throughput omics approaches provide an unprecedented opportunity for dissecting molecular mechanisms in cancer biology. Here we present deep profiling of whole proteome, phosphoproteome and transcriptome in two high-grade glioma (HGG) mouse models driven by mutated RTK oncogenes, PDGFRA and NTRK1, analyzing 13,860 proteins and 30,431 phosphosites by mass spectrometry. Systems biology approaches identify numerous master regulators, including 41 kinases and 23 transcription factors. Pathway activity computation and mouse survival indicate the NTRK1 mutation induces a higher activation of AKT down- stream targets including MYC and JUN, drives a positive feedback loop to up-regulate multiple other RTKs, and confers higher oncogenic potency than the PDGFRA mutation. A mini-gRNA library CRISPR-Cas9 validation screening shows 56% of tested master regulators are important for the viability of NTRK-driven HGG cells, including TFs (Myc and Jun) and metabolic kinases (AMPKa1 and AMPKa2), confirming the validity of the multiomics inte- grative approaches, and providing novel tumor vulnerabilities. -

3989.Full.Pdf
Published OnlineFirst April 25, 2016; DOI: 10.1158/0008-5472.CAN-15-3174 Cancer Tumor and Stem Cell Biology Research Molecular Insights of Pathways Resulting from Two Common PIK3CA Mutations in Breast Cancer Poornima Bhat-Nakshatri1, Chirayu P. Goswami2, Sunil Badve3, Luca Magnani4, Mathieu Lupien5, and Harikrishna Nakshatri1,6,7 Abstract The PI3K pathway is activated in approximately 70% of kers of response to PI3K inhibitors. Using a variety of phys- breast cancers. PIK3CA gene mutations or amplifications that iologically relevant model systems with defined natural or affect the PI3K p110a subunit account for activation of this knock-in PIK3CA mutations and/or PI3K hyperactivation, we pathway in 20% to 40% of cases, particularly in estrogen show that PIK3CA-E545K mutations (found in 20% of receptor alpha (ERa)-positive breast cancers. AKT family of PIK3CA-mutant breast cancers), but not PIK3CA-H1047R kinases, AKT1–3, are the downstream targets of PI3K and these mutations (found in 55% of PIK3CA-mutant breast cancers), kinases activate ERa. Although several inhibitors of PI3K have preferentially activate AKT1. Our findings argue that AKT1 been developed, none has proven effective in the clinic, partly signaling is needed to respond to estrogen and PI3K inhibitors due to an incomplete understanding of the selective routing of in breast cancer cells with PIK3CA-E545K mutation, but not in PI3K signaling to specific AKT isoforms. Accordingly, we breast cancer cells with other PIK3CA mutations. This study investigated in this study the contribution of specific AKT offers evidence that personalizing treatment of ER-positive isoforms in connecting PI3K activation to ERa signaling, breast cancers to PI3K inhibitor therapy may benefitfroman and we also assessed the utility of using the components of analysis of PIK3CA–E545K–AKT1–estrogen signaling path- PI3K–AKT isoform–ERa signaling axis as predictive biomar- ways. -

Bioinformatics Analysis of Potential Key Genes and Mechanisms in Type 2 Diabetes Mellitus Basavaraj Vastrad1, Chanabasayya Vastrad*2
bioRxiv preprint doi: https://doi.org/10.1101/2021.03.28.437386; this version posted March 29, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Bioinformatics analysis of potential key genes and mechanisms in type 2 diabetes mellitus Basavaraj Vastrad1, Chanabasayya Vastrad*2 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karnataka, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India bioRxiv preprint doi: https://doi.org/10.1101/2021.03.28.437386; this version posted March 29, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract Type 2 diabetes mellitus (T2DM) is etiologically related to metabolic disorder. The aim of our study was to screen out candidate genes of T2DM and to elucidate the underlying molecular mechanisms by bioinformatics methods. Expression profiling by high throughput sequencing data of GSE154126 was downloaded from Gene Expression Omnibus (GEO) database. The differentially expressed genes (DEGs) between T2DM and normal control were identified. And then, functional enrichment analyses of gene ontology (GO) and REACTOME pathway analysis was performed. Protein–protein interaction (PPI) network and module analyses were performed based on the DEGs. Additionally, potential miRNAs of hub genes were predicted by miRNet database . Transcription factors (TFs) of hub genes were detected by NetworkAnalyst database. Further, validations were performed by receiver operating characteristic curve (ROC) analysis and real-time polymerase chain reaction (RT-PCR). -

WO 2019/089592 Al 09 May 2019 (09.05.2019) W 1 P O PCT
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization III International Bureau (10) International Publication Number (43) International Publication Date WO 2019/089592 Al 09 May 2019 (09.05.2019) W 1 P O PCT (51) International Patent Classification: (72) Inventors; and A61K 35/12 (2015.01) C07K 16/30 (2006.01) (71) Applicants: JAN, Max [US/US]; c/o The Broad Institute, A61K 5/7 7 (2015.01) C07K 14/705 (2006.01) Inc., 45 1 Main Street, Cambridge, Massachusetts 02142 (US). SIEVERS, Quinlan [US/US]; c/o The Broad In¬ (21) International Application Number: stitute, Inc., 451 Main Street, Cambridge, Massachusetts PCT/US2018/058210 02142 (US). EBERT, Benjamin [US/US]; c/o The Broad (22) International Filing Date: Institute, Inc., 451 Main Street, Cambridge, Massachusetts 30 October 2018 (30. 10.2018) 02142 (US). MAUS, Marcela [US/US]; c/o The Broad In¬ stitute, Inc., 451 Main Street, Cambridge, Massachusetts (25) Filing Language: English 02142 (US). (26) Publication Language: English (74) Agent: COWLES, Christopher R. et al; Burns & Levin- (30) Priority Data: son, LLP, 125 Summer Street, Boston, Massachusetts 62/579,454 3 1 October 2017 (3 1. 10.2017) U S 021 10 (US). 62/633,725 22 February 2018 (22.02.2018) U S (81) Designated States (unless otherwise indicated, for every (71) Applicants: THE GENERAL HOSPITAL CORPO¬ kind of national protection available): AE, AG, AL, AM, RATION [US/US]; 55 Fruit Street, Boston, Massachu¬ AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, BZ, setts 021 14 (US) BRIGHAM & WOMEN'S HOSPITAL CA, CH, CL, CN, CO, CR, CU, CZ, DE, DJ, DK, DM, DO, [US/US]; 75 Francis Street, Boston, Massachusetts 021 15 DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, (US) PRESIDENT AND FELLOWS OF HARVARD HR, HU, ID, IL, IN, IR, IS, JO, JP, KE, KG, KH, KN, KP, COLLEGE [US/US]; 17 Quincy Street, Cambridge, Mass¬ KR, KW, KZ, LA, LC, LK, LR, LS, LU, LY, MA, MD, ME, achusetts 02138 (US). -

Human Induced Pluripotent Stem Cell–Derived Podocytes Mature Into Vascularized Glomeruli Upon Experimental Transplantation
BASIC RESEARCH www.jasn.org Human Induced Pluripotent Stem Cell–Derived Podocytes Mature into Vascularized Glomeruli upon Experimental Transplantation † Sazia Sharmin,* Atsuhiro Taguchi,* Yusuke Kaku,* Yasuhiro Yoshimura,* Tomoko Ohmori,* ‡ † ‡ Tetsushi Sakuma, Masashi Mukoyama, Takashi Yamamoto, Hidetake Kurihara,§ and | Ryuichi Nishinakamura* *Department of Kidney Development, Institute of Molecular Embryology and Genetics, and †Department of Nephrology, Faculty of Life Sciences, Kumamoto University, Kumamoto, Japan; ‡Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Hiroshima, Japan; §Division of Anatomy, Juntendo University School of Medicine, Tokyo, Japan; and |Japan Science and Technology Agency, CREST, Kumamoto, Japan ABSTRACT Glomerular podocytes express proteins, such as nephrin, that constitute the slit diaphragm, thereby contributing to the filtration process in the kidney. Glomerular development has been analyzed mainly in mice, whereas analysis of human kidney development has been minimal because of limited access to embryonic kidneys. We previously reported the induction of three-dimensional primordial glomeruli from human induced pluripotent stem (iPS) cells. Here, using transcription activator–like effector nuclease-mediated homologous recombination, we generated human iPS cell lines that express green fluorescent protein (GFP) in the NPHS1 locus, which encodes nephrin, and we show that GFP expression facilitated accurate visualization of nephrin-positive podocyte formation in -

Supplementary Table 1: Differentially Methylated Genes and Functions of the Genes Before/After Treatment with A) Doxorubicin and B) FUMI and in C) Responders Vs
Supplementary Table 1: Differentially methylated genes and functions of the genes before/after treatment with a) doxorubicin and b) FUMI and in c) responders vs. non- responders for doxorubicin and d) FUMI Differentially methylated genes before/after treatment a. Doxo GENE FUNCTION CCL5, CCL8, CCL15, CCL21, CCR1, CD33, IL5, immunoregulatory and inflammatory processes IL8, IL24, IL26, TNFSF11 CCNA1, CCND2, CDKN2A cell cycle regulators ESR1, FGF2, FGF14, FGF18 growth factors WT1, RASSF5, RASSF6 tumor suppressor b. FUMI GENE FUNCTION CCL7, CCL15, CD28, CD33, CD40, CD69, TNFSF18 immunoregulatory and inflammatory processes CCND2, CDKN2A cell cycle regulators IGF2BP1, IGFBP3 growth factors HOXB4, HOXB6, HOXC8 regulation of cell transcription WT1, RASSF6 tumor suppressor Differentially methylated genes in responders vs. non-responders c. Doxo GENE FUNCTION CBR1, CCL4, CCL8, CCR1, CCR7, CD1A, CD1B, immunoregulatory and inflammatory processes CD1D, CD1E, CD33, CD40, IL5, IL8, IL20, IL22, TLR4 CCNA1, CCND2, CDKN2A cell cycle regulators ESR2, ERBB3, FGF11, FGF12, FGF14, FGF17 growth factors WNT4, WNT16, WNT10A implicated in oncogenesis TNFSF12, TNFSF15 apoptosis FOXL1, FOXL2, FOSL1,HOXA2, HOXA7, HOXA11, HOXA13, HOXB4, HOXB6, HOXB8, HOXB9, HOXC8, regulation of cell transcription HOXD8, HOXD9, HOXD11 GSTP1, MGMT DNA repair APC, WT1 tumor suppressor d. FUMI GENE FUNCTION CCL1, CCL3, CCL5,CCL14, CD1B, CD33, CD40, CD69, immunoregulatory and inflammatory IL20, IL32 processes CCNA1, CCND2, CDKN2A cell cycle regulators IGF2BP1, IGFBP3, IGFBP7, EGFR, ESR2,RARB2 -

Table SII. Significantly Differentially Expressed Mrnas of GSE23558 Data Series with the Criteria of Adjusted P<0.05 And
Table SII. Significantly differentially expressed mRNAs of GSE23558 data series with the criteria of adjusted P<0.05 and logFC>1.5. Probe ID Adjusted P-value logFC Gene symbol Gene title A_23_P157793 1.52x10-5 6.91 CA9 carbonic anhydrase 9 A_23_P161698 1.14x10-4 5.86 MMP3 matrix metallopeptidase 3 A_23_P25150 1.49x10-9 5.67 HOXC9 homeobox C9 A_23_P13094 3.26x10-4 5.56 MMP10 matrix metallopeptidase 10 A_23_P48570 2.36x10-5 5.48 DHRS2 dehydrogenase A_23_P125278 3.03x10-3 5.40 CXCL11 C-X-C motif chemokine ligand 11 A_23_P321501 1.63x10-5 5.38 DHRS2 dehydrogenase A_23_P431388 2.27x10-6 5.33 SPOCD1 SPOC domain containing 1 A_24_P20607 5.13x10-4 5.32 CXCL11 C-X-C motif chemokine ligand 11 A_24_P11061 3.70x10-3 5.30 CSAG1 chondrosarcoma associated gene 1 A_23_P87700 1.03x10-4 5.25 MFAP5 microfibrillar associated protein 5 A_23_P150979 1.81x10-2 5.25 MUCL1 mucin like 1 A_23_P1691 2.71x10-8 5.12 MMP1 matrix metallopeptidase 1 A_23_P350005 2.53x10-4 5.12 TRIML2 tripartite motif family like 2 A_24_P303091 1.23x10-3 4.99 CXCL10 C-X-C motif chemokine ligand 10 A_24_P923612 1.60x10-5 4.95 PTHLH parathyroid hormone like hormone A_23_P7313 6.03x10-5 4.94 SPP1 secreted phosphoprotein 1 A_23_P122924 2.45x10-8 4.93 INHBA inhibin A subunit A_32_P155460 6.56x10-3 4.91 PICSAR P38 inhibited cutaneous squamous cell carcinoma associated lincRNA A_24_P686965 8.75x10-7 4.82 SH2D5 SH2 domain containing 5 A_23_P105475 7.74x10-3 4.70 SLCO1B3 solute carrier organic anion transporter family member 1B3 A_24_P85099 4.82x10-5 4.67 HMGA2 high mobility group AT-hook 2 A_24_P101651