WO 2017/015637 Al 26 January 2017 (26.01.2017) P O P C T
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oxidative Stress-Induced Chromosome Breaks Within
Tan et al. Human Genomics (2018) 12:29 https://doi.org/10.1186/s40246-018-0160-8 PRIMARY RESEARCH Open Access Oxidative stress-induced chromosome breaks within the ABL gene: a model for chromosome rearrangement in nasopharyngeal carcinoma Sang-Nee Tan1, Sai-Peng Sim1* and Alan Soo-Beng Khoo2 Abstract Background: The mechanism underlying chromosome rearrangement in nasopharyngeal carcinoma (NPC) remains elusive. It is known that most of the aetiological factors of NPC trigger oxidative stress. Oxidative stress is a potent apoptotic inducer. During apoptosis, chromatin cleavage and DNA fragmentation occur. However, cells may undergo DNA repair and survive apoptosis. Non-homologous end joining (NHEJ) pathway has been known as the primary DNA repair system in human cells. The NHEJ process may repair DNA ends without any homology, although region of microhomology (a few nucleotides) is usually utilised by this DNA repair system. Cells that evade apoptosis via erroneous DNA repair may carry chromosomal aberration. Apoptotic nuclease was found to be associated with nuclear matrix during apoptosis. Matrix association region/scaffold attachment region (MAR/SAR) is the binding site of the chromosomal DNA loop structure to the nuclear matrix. When apoptotic nuclease is associated with nuclear matrix during apoptosis, it potentially cleaves at MAR/SAR. Cells that survive apoptosis via compromised DNA repair may carry chromosome rearrangement contributing to NPC tumourigenesis. The Abelson murine leukaemia (ABL) gene at 9q34 was targeted in this study as 9q34 is a common region of loss in NPC. This study aimed to identify the chromosome breakages and/or rearrangements in the ABL gene in cells undergoing oxidative stress-induced apoptosis. -

Human Regulatory T Cells Mediate Transcriptional Modulation of Dendritic Cell Function
Human Regulatory T Cells Mediate Transcriptional Modulation of Dendritic Cell Function This information is current as Emily Mavin, Lindsay Nicholson, Syed Rafez Ahmed, Fei of September 24, 2021. Gao, Anne Dickinson and Xiao-nong Wang J Immunol published online 28 November 2016 http://www.jimmunol.org/content/early/2016/11/26/jimmun ol.1502487 Downloaded from Supplementary http://www.jimmunol.org/content/suppl/2016/11/26/jimmunol.150248 Material 7.DCSupplemental http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication by guest on September 24, 2021 *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2016 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. Published November 28, 2016, doi:10.4049/jimmunol.1502487 The Journal of Immunology Human Regulatory T Cells Mediate Transcriptional Modulation of Dendritic Cell Function Emily Mavin,*,1 Lindsay Nicholson,*,1 Syed Rafez Ahmed,* Fei Gao,† Anne Dickinson,* and Xiao-nong Wang* Regulatory T cells (Treg) attenuate dendritic cell (DC) maturation and stimulatory function. Current knowledge on the functional impact of semimature DC is limited to CD4+ T cell proliferation and cytokine production. -

Regulation of Neuronal Gene Expression and Survival by Basal NMDA Receptor Activity: a Role for Histone Deacetylase 4
The Journal of Neuroscience, November 12, 2014 • 34(46):15327–15339 • 15327 Cellular/Molecular Regulation of Neuronal Gene Expression and Survival by Basal NMDA Receptor Activity: A Role for Histone Deacetylase 4 Yelin Chen,1 Yuanyuan Wang,1 Zora Modrusan,3 Morgan Sheng,1 and Joshua S. Kaminker1,2 Departments of 1Neuroscience, 2Bioinformatics and Computational Biology, and 3Molecular Biology, Genentech Inc., South San Francisco, California 94080 Neuronal gene expression is modulated by activity via calcium-permeable receptors such as NMDA receptors (NMDARs). While gene expression changes downstream of evoked NMDAR activity have been well studied, much less is known about gene expression changes that occur under conditions of basal neuronal activity. In mouse dissociated hippocampal neuronal cultures, we found that a broad NMDAR antagonist, AP5, induced robust gene expression changes under basal activity, but subtype-specific antagonists did not. While some of the gene expression changes are also known to be downstream of stimulated NMDAR activity, others appear specific to basal NMDARactivity.ThegenesalteredbyAP5treatmentofbasalcultureswereenrichedforpathwaysrelatedtoclassIIahistonedeacetylases (HDACs), apoptosis, and synapse-related signaling. Specifically, AP5 altered the expression of all three class IIa HDACs that are highly expressed in the brain, HDAC4, HDAC5, and HDAC9, and also induced nuclear accumulation of HDAC4. HDAC4 knockdown abolished a subset of the gene expression changes induced by AP5, and led to neuronal death under -

Single-Cell RNA Sequencing Identifies Senescent Cerebromicrovascular Endothelial Cells in the Aged Mouse Brain
GeroScience (2020) 42:429–444 https://doi.org/10.1007/s11357-020-00177-1 ORIGINAL ARTICLE/UNDERSTANDING SENESCENCE IN BRAIN AGING AND ALZHEIMER’SDISEASE Single-cell RNA sequencing identifies senescent cerebromicrovascular endothelial cells in the aged mouse brain Tamas Kiss & Ádám Nyúl-Tóth & Priya Balasubramanian & Stefano Tarantini & Chetan Ahire & Jordan DelFavero & Andriy Yabluchanskiy & Tamas Csipo & Eszter Farkas & Graham Wiley & Lori Garman & Anna Csiszar & Zoltan Ungvari Received: 31 January 2020 /Accepted: 1 March 2020 /Published online: 31 March 2020 # American Aging Association 2020 Abstract Age-related phenotypic changes of therapeutic exploitation of senolytic drugs in preclinical cerebromicrovascular endothelial cells lead to dysregula- studies. However, difficulties with the detection of senes- tion of cerebral blood flow and blood-brain barrier dis- cent endothelial cells in wild type mouse models of aging ruption, promoting the pathogenesis of vascular cognitive hinder the assessment of the efficiency of senolytic treat- impairment (VCI). In recent years, endothelial cell senes- ments. To detect senescent endothelial cells in the aging cence has emerged as a potential mechanism contributing mouse brain, we analyzed 4233 cells in fractions enriched to microvascular pathologies opening the avenue to the for cerebromicrovascular endothelial cells and other cells Tamas Kiss, Ádám Nyúl-Tóth, Priya Balasubramanian and Stefano Tarantini contributed equally to this work. T. Kiss : Á. Nyúl-Tóth : P. Balasubramanian : S. Tarantini : S. Tarantini : A. Yabluchanskiy : Z. Ungvari C. Ahire : J. DelFavero : A. Yabluchanskiy : T. Csipo : Department of Public Health, International Training Program in A. Csiszar (*) : Z. Ungvari Geroscience, Doctoral School of Basic and Translational Medicine, Department of Biochemistry and Molecular Biology, Reynolds Semmelweis University, Budapest, Hungary Oklahoma Center on Aging/Center for Geroscience and Healthy Brain Aging, Vascular Cognitive Impairment and T. -

IER3 Is a Crucial Mediator of Tap73b-Induced Apoptosis In
OPEN IER3 is a crucial mediator of SUBJECT AREAS: TAp73b-induced apoptosis in cervical CELL DEATH TUMOUR SUPPRESSORS cancer and confers etoposide sensitivity Hanyong Jin1*, Dae-Shik Suh2*, Tae-Hyoung Kim3, Ji-Hyun Yeom4, Kangseok Lee4 & Jeehyeon Bae5 Received 14 September 2014 1Department of Pharmacy, CHA University, Seongnam, 463-836, Korea, 2Department of Obstetrics and Gynecology, Asan Accepted Medical Center, University of Ulsan College of Medicine, 3Department of Biochemistry, Chosun University School of Medicine, 4 5 9 January 2015 Gwangju 501-759, Korea, Department of Life Science, Chung-Ang University, Seoul, 156-756, Korea, School of Pharmacy, Chung-Ang University, Seoul, 156-756, Korea. Published 10 February 2015 Infection with high-risk human papillomaviruses (HPVs) causes cervical cancer. E6 oncoprotein, an HPV gene product, inactivates the major gatekeeper p53. In contrast, its isoform, TAp73b, has become increasingly important, as it is resistant to E6. However, the intracellular signaling mechanisms that account Correspondence and for TAp73b tumor suppressor activity in cervix are poorly understood. Here, we identified that IER3 is a requests for materials novel target gene of TAp73b. In particular, TAp73b exclusively transactivated IER3 in cervical cancer cells, should be addressed to whereas p53 and TAp63 failed to do. IER3 efficiently induced apoptosis, and its knockdown promoted K.L. (kangseok@cau. survival of HeLa cells. In addition, TAp73b-induced cell death, but not p53-induced cell death, was inhibited ac.kr) or J.B. upon IER3 silencing. Moreover, etoposide, a DNA-damaging chemotherapeutics, upregulated TAp73b and IER3 in a c-Abl tyrosine kinase-dependent manner, and the etoposide chemosensitivity of HeLa cells was ([email protected]) largely determined by TAp73b-induced IER3. -

S41467-020-18249-3.Pdf
ARTICLE https://doi.org/10.1038/s41467-020-18249-3 OPEN Pharmacologically reversible zonation-dependent endothelial cell transcriptomic changes with neurodegenerative disease associations in the aged brain Lei Zhao1,2,17, Zhongqi Li 1,2,17, Joaquim S. L. Vong2,3,17, Xinyi Chen1,2, Hei-Ming Lai1,2,4,5,6, Leo Y. C. Yan1,2, Junzhe Huang1,2, Samuel K. H. Sy1,2,7, Xiaoyu Tian 8, Yu Huang 8, Ho Yin Edwin Chan5,9, Hon-Cheong So6,8, ✉ ✉ Wai-Lung Ng 10, Yamei Tang11, Wei-Jye Lin12,13, Vincent C. T. Mok1,5,6,14,15 &HoKo 1,2,4,5,6,8,14,16 1234567890():,; The molecular signatures of cells in the brain have been revealed in unprecedented detail, yet the ageing-associated genome-wide expression changes that may contribute to neurovas- cular dysfunction in neurodegenerative diseases remain elusive. Here, we report zonation- dependent transcriptomic changes in aged mouse brain endothelial cells (ECs), which pro- minently implicate altered immune/cytokine signaling in ECs of all vascular segments, and functional changes impacting the blood–brain barrier (BBB) and glucose/energy metabolism especially in capillary ECs (capECs). An overrepresentation of Alzheimer disease (AD) GWAS genes is evident among the human orthologs of the differentially expressed genes of aged capECs, while comparative analysis revealed a subset of concordantly downregulated, functionally important genes in human AD brains. Treatment with exenatide, a glucagon-like peptide-1 receptor agonist, strongly reverses aged mouse brain EC transcriptomic changes and BBB leakage, with associated attenuation of microglial priming. We thus revealed tran- scriptomic alterations underlying brain EC ageing that are complex yet pharmacologically reversible. -

Role of RUNX1 in Aberrant Retinal Angiogenesis Jonathan D
Page 1 of 25 Diabetes Identification of RUNX1 as a mediator of aberrant retinal angiogenesis Short Title: Role of RUNX1 in aberrant retinal angiogenesis Jonathan D. Lam,†1 Daniel J. Oh,†1 Lindsay L. Wong,1 Dhanesh Amarnani,1 Cindy Park- Windhol,1 Angie V. Sanchez,1 Jonathan Cardona-Velez,1,2 Declan McGuone,3 Anat O. Stemmer- Rachamimov,3 Dean Eliott,4 Diane R. Bielenberg,5 Tave van Zyl,4 Lishuang Shen,1 Xiaowu Gai,6 Patricia A. D’Amore*,1,7 Leo A. Kim*,1,4 Joseph F. Arboleda-Velasquez*1 Author affiliations: 1Schepens Eye Research Institute/Massachusetts Eye and Ear, Department of Ophthalmology, Harvard Medical School, 20 Staniford St., Boston, MA 02114 2Universidad Pontificia Bolivariana, Medellin, Colombia, #68- a, Cq. 1 #68305, Medellín, Antioquia, Colombia 3C.S. Kubik Laboratory for Neuropathology, Massachusetts General Hospital, 55 Fruit St., Boston, MA 02114 4Retina Service, Massachusetts Eye and Ear Infirmary, Department of Ophthalmology, Harvard Medical School, 243 Charles St., Boston, MA 02114 5Vascular Biology Program, Boston Children’s Hospital, Department of Surgery, Harvard Medical School, 300 Longwood Ave., Boston, MA 02115 6Center for Personalized Medicine, Children’s Hospital Los Angeles, Los Angeles, 4650 Sunset Blvd, Los Angeles, CA 90027, USA 7Department of Pathology, Harvard Medical School, 25 Shattuck St., Boston, MA 02115 Corresponding authors: Joseph F. Arboleda-Velasquez: [email protected] Ph: (617) 912-2517 Leo Kim: [email protected] Ph: (617) 912-2562 Patricia D’Amore: [email protected] Ph: (617) 912-2559 Fax: (617) 912-0128 20 Staniford St. Boston MA, 02114 † These authors contributed equally to this manuscript Word Count: 1905 Tables and Figures: 4 Diabetes Publish Ahead of Print, published online April 11, 2017 Diabetes Page 2 of 25 Abstract Proliferative diabetic retinopathy (PDR) is a common cause of blindness in the developed world’s working adult population, and affects those with type 1 and type 2 diabetes mellitus. -

HIV-1 TAR Mirna Protects Against Apoptosis by Altering Cellular Gene
Retrovirology BioMed Central Research Open Access HIV-1 TAR miRNA protects against apoptosis by altering cellular gene expression Zachary Klase1, Rafael Winograd1, Jeremiah Davis1, Lawrence Carpio1, Richard Hildreth1, Mohammad Heydarian2, Sidney Fu2, Timothy McCaffrey2, Eti Meiri3, Mila Ayash-Rashkovsky3, Shlomit Gilad3, Zwi Bentwich3 and Fatah Kashanchi*1 Address: 1The Department of Microbiology, Immunology and Tropical Medicine program, The George Washington University School of Medicine, Washington, District of Columbia 20037, USA, 2The Department of Biochemistry and Molecular Biology, The George Washington University School of Medicine, Washington, District of Columbia 20037, USA and 3Rosetta Genomics Ltd., Rehovot, Israel Email: Zachary Klase - [email protected]; Rafael Winograd - [email protected]; Jeremiah Davis - [email protected]; Lawrence Carpio - [email protected]; Richard Hildreth - [email protected]; Mohammad Heydarian - [email protected]; Sidney Fu - [email protected]; Timothy McCaffrey - [email protected]; Eti Meiri - [email protected]; Mila Ayash- Rashkovsky - [email protected]; Shlomit Gilad - [email protected]; Zwi Bentwich - [email protected]; Fatah Kashanchi* - [email protected] * Corresponding author Published: 16 February 2009 Received: 15 August 2008 Accepted: 16 February 2009 Retrovirology 2009, 6:18 doi:10.1186/1742-4690-6-18 This article is available from: http://www.retrovirology.com/content/6/1/18 © 2009 Klase et al; licensee BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited. Abstract Background: RNA interference is a gene regulatory mechanism that employs small RNA molecules such as microRNA. -

Identification of Potential Key Genes and Pathway Linked with Sporadic Creutzfeldt-Jakob Disease Based on Integrated Bioinformatics Analyses
medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Identification of potential key genes and pathway linked with sporadic Creutzfeldt-Jakob disease based on integrated bioinformatics analyses Basavaraj Vastrad1, Chanabasayya Vastrad*2 , Iranna Kotturshetti 1. Department of Biochemistry, Basaveshwar College of Pharmacy, Gadag, Karnataka 582103, India. 2. Biostatistics and Bioinformatics, Chanabasava Nilaya, Bharthinagar, Dharwad 580001, Karanataka, India. 3. Department of Ayurveda, Rajiv Gandhi Education Society`s Ayurvedic Medical College, Ron, Karnataka 562209, India. * Chanabasayya Vastrad [email protected] Ph: +919480073398 Chanabasava Nilaya, Bharthinagar, Dharwad 580001 , Karanataka, India NOTE: This preprint reports new research that has not been certified by peer review and should not be used to guide clinical practice. medRxiv preprint doi: https://doi.org/10.1101/2020.12.21.20248688; this version posted December 24, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. All rights reserved. No reuse allowed without permission. Abstract Sporadic Creutzfeldt-Jakob disease (sCJD) is neurodegenerative disease also called prion disease linked with poor prognosis. The aim of the current study was to illuminate the underlying molecular mechanisms of sCJD. The mRNA microarray dataset GSE124571 was downloaded from the Gene Expression Omnibus database. Differentially expressed genes (DEGs) were screened. -

Supplementary Materials
Supplementary materials Supplementary Table S1: MGNC compound library Ingredien Molecule Caco- Mol ID MW AlogP OB (%) BBB DL FASA- HL t Name Name 2 shengdi MOL012254 campesterol 400.8 7.63 37.58 1.34 0.98 0.7 0.21 20.2 shengdi MOL000519 coniferin 314.4 3.16 31.11 0.42 -0.2 0.3 0.27 74.6 beta- shengdi MOL000359 414.8 8.08 36.91 1.32 0.99 0.8 0.23 20.2 sitosterol pachymic shengdi MOL000289 528.9 6.54 33.63 0.1 -0.6 0.8 0 9.27 acid Poricoic acid shengdi MOL000291 484.7 5.64 30.52 -0.08 -0.9 0.8 0 8.67 B Chrysanthem shengdi MOL004492 585 8.24 38.72 0.51 -1 0.6 0.3 17.5 axanthin 20- shengdi MOL011455 Hexadecano 418.6 1.91 32.7 -0.24 -0.4 0.7 0.29 104 ylingenol huanglian MOL001454 berberine 336.4 3.45 36.86 1.24 0.57 0.8 0.19 6.57 huanglian MOL013352 Obacunone 454.6 2.68 43.29 0.01 -0.4 0.8 0.31 -13 huanglian MOL002894 berberrubine 322.4 3.2 35.74 1.07 0.17 0.7 0.24 6.46 huanglian MOL002897 epiberberine 336.4 3.45 43.09 1.17 0.4 0.8 0.19 6.1 huanglian MOL002903 (R)-Canadine 339.4 3.4 55.37 1.04 0.57 0.8 0.2 6.41 huanglian MOL002904 Berlambine 351.4 2.49 36.68 0.97 0.17 0.8 0.28 7.33 Corchorosid huanglian MOL002907 404.6 1.34 105 -0.91 -1.3 0.8 0.29 6.68 e A_qt Magnogrand huanglian MOL000622 266.4 1.18 63.71 0.02 -0.2 0.2 0.3 3.17 iolide huanglian MOL000762 Palmidin A 510.5 4.52 35.36 -0.38 -1.5 0.7 0.39 33.2 huanglian MOL000785 palmatine 352.4 3.65 64.6 1.33 0.37 0.7 0.13 2.25 huanglian MOL000098 quercetin 302.3 1.5 46.43 0.05 -0.8 0.3 0.38 14.4 huanglian MOL001458 coptisine 320.3 3.25 30.67 1.21 0.32 0.9 0.26 9.33 huanglian MOL002668 Worenine -
Supplementary Figures and Tables
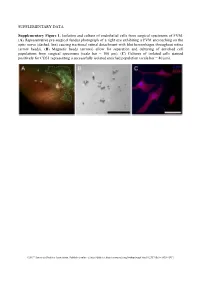
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Macrophage Activation JUNB Is a Key Transcriptional Modulator Of
JUNB Is a Key Transcriptional Modulator of Macrophage Activation Mary F. Fontana, Alyssa Baccarella, Nidhi Pancholi, Miles A. Pufall, De'Broski R. Herbert and Charles C. Kim This information is current as of October 2, 2021. J Immunol 2015; 194:177-186; Prepublished online 3 December 2014; doi: 10.4049/jimmunol.1401595 http://www.jimmunol.org/content/194/1/177 Downloaded from Supplementary http://www.jimmunol.org/content/suppl/2014/12/03/jimmunol.140159 Material 5.DCSupplemental References This article cites 40 articles, 7 of which you can access for free at: http://www.jimmunol.org/content/194/1/177.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists by guest on October 2, 2021 • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2014 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology JUNB Is a Key Transcriptional Modulator of Macrophage Activation Mary F. Fontana,* Alyssa Baccarella,* Nidhi Pancholi,* Miles A.