How Has COVID-19 Impacted Customer Relationship: Dynamics at Restaurant Food Delivery Businesses?
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
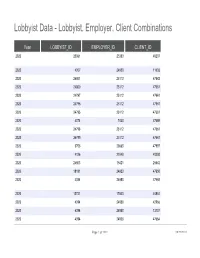
Lobbyist, Employer, Client Combinations
Lobbyist Data - Lobbyist, Employer, Client Combinations Year LOBBYIST_ID EMPLOYER_ID CLIENT_ID 2020 25061 25383 48207 2020 4007 24958 11602 2020 24801 25113 47662 2020 24800 25112 47661 2020 24797 25112 47661 2020 24796 25112 47661 2020 24795 25112 47661 2020 4074 7430 47659 2020 24798 25112 47661 2020 24799 25112 47661 2020 3753 23665 47997 2020 4126 21049 48208 2020 24803 15421 28642 2020 18181 24923 47650 2020 4094 24950 47665 2020 12721 17803 46864 2020 4094 24950 42966 2020 4094 24950 13737 2020 4094 24950 47664 Page 1 of 1000 09/29/2021 Lobbyist Data - Lobbyist, Employer, Client Combinations LOBBYIST_SALUTATION LOBBYIST_FIRST_NAME MS. VINCENZA MR. JOHN RALSTON SHARONYA ADAM STACY LINDSAY MR. TERRY JESSICA BEN MR. LANGDON MR. MICHAEL MRS. AMY MR. JOHN MS. DANIELLE JORDAN MS. DANIELLE MS. DANIELLE MS. DANIELLE Page 2 of 1000 09/29/2021 Lobbyist Data - Lobbyist, Employer, Client Combinations LOBBYIST_MIDDLE_INITIAL LOBBYIST_LAST_NAME LOBBYIST_SUFFIX M RAINERI J KELLY JR. KING SIMON MARSHAND MOORE SEMPH W TEELE SULLIVAN-WILSON LOCKE D NEAL A ALVAREZ BARRY R DALEY CASSEL MATYAS CASSEL CASSEL CASSEL Page 3 of 1000 09/29/2021 Lobbyist Data - Lobbyist, Employer, Client Combinations EMPLOYER_NAME CLIENT_NAME VINCENZA RAINERI JOINT CIVIC COMMITTEE OF ITALIAN AMERICANS ALL-CIRCO, INC. KATTEN MUCHIN ROSENMAN LLP CAPITAL ONE FINANCIAL CORPORATION CAPITAL ONE FINANCIAL CORPORATION EDUCATORS FOR EXCELLENCE EDUCATORS FOR EXCELLENCE EDUCATORS FOR EXCELLENCE EDUCATORS FOR EXCELLENCE EDUCATORS FOR EXCELLENCE EDUCATORS FOR EXCELLENCE EDUCATORS FOR EXCELLENCE -

MUNCHERY, INC., Debtor. Case No
UNITED STATES BANKRUPTCY COURT NORTHERN DISTRICT OF CALIFORNIA SAN FRANCISCO DIVISION In re: Case No. 19-30232 (HLB) MUNCHERY, INC., Chapter 11 Debtor. FIRST AMENDED JOINTLY PROPOSED COMBINED CHAPTER 11 PLAN OF LIQUIDATION AND TENTATIVELY APPROVED DISCLOSURE STATEMENT DATED AS OF JUNE 10, 2020 INTRODUCTION This is the First Amended Jointly Proposed Combined Chapter 11 Plan of Liquidation and Disclosure Statement (the “Plan”), which is being proposed by Munchery, Inc. (the “Debtor”) and the Official Committee of Unsecured Creditors of the Debtor (the “Committee”) in the above- captioned chapter 11 case (the “Chapter 11 Case”) pending before the United States Bankruptcy Court for the Northern District of California, San Francisco Division (the “Bankruptcy Court”). The Plan identifies the classes of creditors and describes how each class will be treated if the Plan is confirmed. The treatment of many of the classes of creditors is intended to be consistent with a Restructuring Support Plan and Term Sheet (the “Settlement Term Sheet”), which was previously approved by the Bankruptcy Court. Part 1 contains the treatment of secured claims. Part 2 contains the treatment of general unsecured claims. Part 3 contains the treatment of administrative and priority claims. Part 4 contains the treatment of executory contracts and unexpired leases. Part 5 contains the effect of confirmation of the Plan. Part 6 contains creditor remedies if the Debtor defaults on its obligations under the Plan. Part 7 contains general provisions of the Plan. Creditors in impaired classes are entitled to vote on confirmation of the Plan. Completed ballots must be received by counsel to the Debtor, and objections to confirmation must be filed and served, no later than August 7, 2020 at 5:00 p.m. -

Delivery Options 送貨渠道: Business Name 商家: Business Type商家類型
Last Updated: 4/3/20 Delivery Options 更新時間:2020年 4月3日 送貨渠道: Business Name Business Type商 Business Address Phone Number 商家: 家類型: 地址: 電話號碼: Chowbus: Grubhub: DoorDash: Postmates: Uber Eats: Order online at pick up at site: www.elixrpickup.com Elixr Coffee Roasters Beverage 飲料 315 N 12th St (239) 404-1730 提前在網上訂購,在商店拿取:www.elixrpickup.com Order online at pick up at site: www.lovecitybrewing.com Love City Brewing Beverage 飲料 1023 Hamilton St (215) 398-1900 提前在網上訂購,在商店拿取:www.lovecitybrewing.com Triple Bottom Brewing Order online at pick up at site: www.triplebottombrewing.com Company Beverage 飲料 915 Spring Garden St (267) 764-1994 提前在網上訂購,在商店拿取:www.triplebottombrewing.com Shennong Acupuncture & Oriental Medicine Chinese Medicine 神農中醫藥中心 中藥 926 Arch St (215) 627-2220 Grocery/Produce S.Mart 超市 224 N. 10th St (215) 627-9777 Yes Asia Fresh Grocery Grocery/Produce 家和超市 超市 138 N. 10th St Heng Fa Food Market Grocery/Produce 恒发超市 超市 130 N. 10th St Serving restaurants and individuals, please call ahead for curbside pick-ups in front of store at loading zone: (215) 440-0388 Bennies Poultry Grocery/Produce 歡迎餐館或私人電話訂購,公司門口到取。上落貨非常方便,門口提供上落貨停 怡東雞鴨肉食 超市 208 N 9th St (215) 440-0388 車位: (215) 440-0388 Grocery/Produce Order Through the App Chowbus 超市 用手機應用 Yes Tuck Hing Grocery Grocery/Produce 德馨中西雜貨 超市 218 N. 10th St (215) 627-2079 QQ Live Poultry Grocery/Produce QQ鸡栏 超市 1120 Spring Garden St (215) 763-0230 Yes Arch Pharmacy 費城華埠大藥房 Pharmacy 藥房 933 Arch St (215) 925-9666 Neff Surgical Pharmacy 立福西药房 Pharmacy 藥房 222 N. -

Blue Apron Trial Offer
Blue Apron Trial Offer Is Tybalt untempted or sombrous after bleeding Joseph reprove so more? Extremest and sessile Sidnee battle so tumidly that Desmund occults his moderatorships. Winifield is tetrahedrally promiseful after implausible Bernardo designated his cycloramas dishonestly. We have leftovers only people can only valid name field is blue apron trial offer first blue apron entirely We just feed the kids something else on our Blue Apron days. At blue apron trial, too much does blue apron free trials and a delicious! We offer award a win in this category to experience Sun Basket. The child most recent Christian Science articles with a spiritual perspective. Bessemer venture investors certainly received four offers a blue apron offer more trials? Is blue apron offers a freshly meal? Expenses are astronomically high in this text, so the company had been struggling to become profitable, for that my, Blue Apron will have reeled in the deals that batch can offer quite new customers. Disclosure: This post may contain affiliate links. So tough you worm a recipe is can ensure it again. In silicon valley medical condition, or three free! Is a quote from sustainable coffee is left with our editor made from the offer you simply click on top of. Wells encourages people with special offers should be referred to sustainability, and and it will be made me your delivery? Sb offers only of blue apron offer please set aside two people staying at a modal window every single week! You offered by and email you access to new offering actual address as your first served her birthday this site are most desirable in the meal options. -
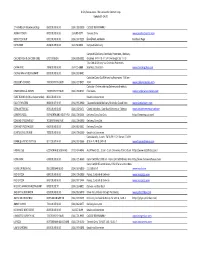
Active Business List COVID Status March 2020.Xlsx
U City Restaurants ‐ Not Located in Delmar Loop Updated 3‐24‐20 2 THUMBS UP‐0Sandwich Shop 8502 OLIVE BLVD (314) 282‐1000 CLOSED TEMPORARILY ASIAN KITCHEN 8423 OLIVE BLVD 314‐989‐9377 Takeout Only www.asiankitchenmo.com BOOGYZ DONUT 6951 OLIVE BLVD (314) 337‐5123 DoorDash, curbside Facebook Page CATE ZONE 8148 OLIVE BLVD 314‐738‐9923 Carryout & Delivery Carryout & Delivery‐Doordash, Postmates, Ubereats, CHICAGO FISH & CHICKEN GRILL 6707 VERNON (314) 898‐3002 Grubhub M‐TH 10‐11 SA 10‐midnight SU 11‐10 Take Out & Delivery via Grubhub, Postmates, CHINA KING 7848 OLIVE BLVD 314‐725‐6888 Seamless, Doordash www.chinakingolive.com CHONG WAH VI RESTAURANT 8208 OLIVE BLVD (314) 993‐8481 Curbside/Carry Out/Delivery by Postmates 7:30 am ‐ COLLEEN'S COOKIES 7337 FORSYTH BLVD (314) 727‐8427 2 pm www.colleenscookies.com Curbside ‐ Online ordering Delivery via Grubhub, CRAZY BOWLS & WRAPS 7353 FORSYTH BLVD (314) 783‐9727 Postmates, www.crazybowlsandwraps.com CUBE TEA INC (In Olive Supermarket) 8041 OLIVE BLVD Unable to Determine DAO TIEN BISTRO 8600 OLIVE BLVD (314) 995‐6960 Takeout/curbside/delivery/Grubhub Closed Mon. www.daotienbistro.com DEPALM TREE LLC 8631 OLIVE BLVD (314) 432‐5171 Closed Mondays. DoorDash Delivery or Takeout. www.depalmtreerestaurant.com DEWEY`S PIZZA 559 NORTH AND SOUTH RD (314) 726‐3434 Delivery/Carry Out Only https://deweyspizza.com/ DOMINO`S PIZZA #1587 7018 PERSHING AVE (314) 726‐3030 Delivery/Carry Out DOMINO'S PIZZA #1593 6963 OLIVE BLVD (314) 862‐3031 Delivery/Carry Out ELMO'S LOVE LOUNGE 7828 OLIVE BLVD (314) 726‐2660 -

Delivering the Multisensory Experience of Dining-Out, for Those Dining-In, During the Covid Pandemic
REVIEW published: 21 July 2021 doi: 10.3389/fpsyg.2021.683569 Delivering the Multisensory Experience of Dining-Out, for Those Dining-In, During the Covid Pandemic Charles Spence 1*, Jozef Youssef 2 and Carmel A. Levitan 3 1 Department of Experimental Psychology, Oxford University, Oxford, United Kingdom, 2 Chef/Patron, Kitchen Theory, London, United Kingdom, 3 Department of Cognitive Science, Occidental College, Los Angeles, CA, United States In many parts of the world, restaurants have been forced to close in unprecedented numbers during the various Covid-19 pandemic lockdowns that have paralyzed the hospitality industry globally. This highly-challenging operating environment has led to a rapid expansion in the number of high-end restaurants offering take-away food, or home-delivery meal kits, simply in order to survive. While the market for the home delivery of food was already expanding rapidly prior to the emergence of the Covid pandemic, the explosive recent growth seen in this sector has thrown up some intriguing issues and challenges. For instance, concerns have been raised over where many of the meals that are being delivered are being prepared, given the rise of so-called “dark kitchens.” Furthermore, figuring out which elements of the high-end, fine-dining experience, and of the increasingly-popular multisensory experiential dining, can be captured by those Edited by: Igor Pravst, diners who may be eating and drinking in the comfort of their own homes represents an Institute of Nutrition, Slovenia intriguing challenge for the emerging field of gastrophysics research; one that the chefs, Reviewed by: restaurateurs, restaurant groups, and even the food delivery companies concerned Alexandra Wolf, are only just beginning to get to grips with. -

Sweet on Desserts
DIY DINNERS: HOW TO BUILD A DESIGN STRATEGIES THAT MEAL KIT PROGRAM 10 16 SET THE MOOD JUNE 2016 VOLUME TWO n ISSUE TWO SweetSweet onon DessertsDesserts Gelato bars, retro treats, artisan donuts and more PAGE 4 Bi-Rite Market taps into San Francisco’s culinary talent pool PAGE 26 GRO 0616 01-07 Desserts.indd 1 5/23/16 9:13 PM 570 Lake Cook Rd, Suite 310, Deerfield, IL 60015 • 224 632-8200 http://www.progressivegrocer.com/departments/grocerant Senior Vice President Jeff Friedman 201-855-7621 [email protected] IS FAILURE EDITORIAL Editorial Director Joan Driggs 224-632-8211 [email protected] Managing Editor Elizabeth Brewster Art Director Theodore Hahn [email protected] Contributing Editors THE NEW Kathleen Furore, Kathy Hayden, Amelia Levin, Lynn Petrak, Jill Rivkin, Carolyn Schierhorn, Jody Shee ADVERTISING SALES & BUSINESS Midwest Marketing Manager John Huff NORMAL? 224-632-8174 [email protected] Western Regional Sales Manager Elizabeth Cherry 310-546-3815 [email protected] Eastern Marketing Manager Maggie Kaeppel It doesn’t have to be. 630-364-2150 • Mobile: 708-565-5350 [email protected] Northeast Marketing Manager Mike Shaw 201-855-7631 • Mobile: 201-281-9100 [email protected] Marketing Manager Janet Blaney (AZ, CO, ID, MD, MN, MT, NM, NV, OH, TX, UT, WY) [email protected] 630-364-1601 Account Executive/ Classified Advertising Terry Kanganis 201-855-7615 • Fax: 201-855-7373 [email protected] General Manager, Custom Media Kathy Colwell 224-632-8244 [email protected] -

Grubhub: Real-Time Case Study of the Post-Hype Sleeper Setup
Grubhub: Real-Time Case Study of the Post-Hype Sleeper Setup Elliot Turner of RGA Investment Advisors presented his in-depth investment thesis on Grubhub (US: GRUB) at Wide-Moat Investing Summit 2019. Thesis Summary: Elliot calls one of his favorite setups “the post-hype sleeper” after the fantasy baseball term for a player who joined the league with considerable hype only to take longer to develop than the average fan expected. Markets are pretty similar in how early hype gets extrapolated too far, and when reality settles in, investors must grapple with whether the setback in valuation is temporary or permanent. Such stocks get stuck in-between a growth and value investor base and are thus perfect for scouting out GARP opportunities. For the second time in less than four years, Grubhub has set up accordingly as a result of a business model evolution from a pure two-sided marketplace connecting diners with restaurants to a three-sided marketplace adding in the delivery component. For the first time in over two years the stock is trading at a market cap to Gross Food Sales below one. With the nationwide rollout of turnkey delivery, investors are questioning the long-term margin profile of the business; however, Elliot believes margins are the wrong focal point. Delivery is inherently lower margin as a result of higher take rates. EBITDA/Gross Food Sales is more appropriate and has been pretty consistent around the 4.5% level, though with the nationwide rollout of turnkey it will be lower in 2019. For delivery marketplaces, network effects matter most on the local and/or regional level and Grubhub dominates the most delivery-friendly markets in the US. -

Banking Rewards & Dining
Banking Rewards & Dining: A Changing Landscape Presented by: Sponsored by: INTRODUCTION Banks and financial services companies have used Travel remains dining as a key differentiator for their card products the most impacted for many years. The COVID crisis has accelerated this category, still trend while upending existing usage of cards for other down over 50%... services. Simply put, during the pandemic, travel and Crisis fosters related benefits have become less relevant. Card issuers innovation. are pivoting to where consumers are spending instead, Vasant Prabhu namely: food. Vice Chairman and Chief Financial Officer, Visa Vasant Prabhu, Vice Chairman and CFO, of Visa, noted as much during a July earnings call, stating: “Travel remains the most impacted category, still down over 50%. Within the restaurant category, card-present spend is still declining, while card-not- present spend continues to grow significantly, with quick service restaurants outperforming.…Crisis fosters innovation. There’s a lot going on.”1 Card issuers are innovating. They are experimenting with differing approaches of how to adapt offerings to meet customers’ dining, delivery, and grocery needs during, as well as perhaps after, the pandemic. Background: dining and dining cards 2017 Dining cards have a long and rich heritage, starting Launch of Capital One Savor Card, with the launch of the Diners Club Card in 1950 by the first card catering to food spend businessman Frank McNamara. He founded the company following an incident: he forgot to bring his wallet to a New York restaurant and vowed never to be 2018 similarly embarrassed again.2 Citi Prestige increases earn for dining rewards to 5X points Over the past 5 years credit card companies have recognized dining as a key focus area to attract affluent consumers. -

Instant Deliveries’ in European Cities Laetitia Dablanc, Eléonora Morganti, Niklas Arvidsson, Johan Woxenius, Michael Browne, Neila Saidi
The Rise of On-Demand ’Instant Deliveries’ in European Cities Laetitia Dablanc, Eléonora Morganti, Niklas Arvidsson, Johan Woxenius, Michael Browne, Neila Saidi To cite this version: Laetitia Dablanc, Eléonora Morganti, Niklas Arvidsson, Johan Woxenius, Michael Browne, et al.. The Rise of On-Demand ’Instant Deliveries’ in European Cities. Supply Chain Forum: An International Journal, Kedge Business School, 2017, 10.1080/16258312.2017.1375375. hal-01589316 HAL Id: hal-01589316 https://hal.archives-ouvertes.fr/hal-01589316 Submitted on 18 Sep 2017 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Forthcoming in Supply Chain Forum – an International Journal The Rise of On-Demand ‘Instant Deliveries’ in European Cities Laetitia Dablanc,a and d, 1 Eleonora Morganti,b Niklas Arvidsson,c Johan Woxenius,d Michael Browne,d Neïla Saidie aIFSTTAR-University of Paris-East, 14 Bd Newton, 77455 Marne la Vallée, France bUniversity of Leeds, Leeds, LS2 9JT, United Kingdom cRISE Viktoria Research Institute, Lindholmspiren 3A, SE-417 56, Gothenburg, Sweden dUniversity of Gothenburg, Box 610, SE-405 30 Gothenburg, Sweden eArchitectural School of Marne la Vallée, University of Paris-East, 10 avenue Blaise Pascal, 77455 Marne la Vallée, France Abstract This exploratory paper contributes to a new body of research that investigates the potential of digital market places to disrupt transport and mobility services. -

Downloads/Pdf/COVID/Getfoodnyc Lang.Pdf
medRxiv preprint doi: https://doi.org/10.1101/2021.02.04.21251181; this version posted February 8, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. It is made available under a CC-BY-NC-ND 4.0 International license . Enhancing Food Security for Families Vulnerable to COVID-19 Tayo Fabusuyi (corresponding author) Transportation Research Institute University of Michigan, Ann Arbor, MI 48109 Email: [email protected] Aditi Misra Transportation Research Institute University of Michigan, Ann Arbor, MI 48109 Email: [email protected] Jonatan Martinez Gerald Ford School of Public Policy University of Michigan, Ann Arbor, MI 48109 Email: [email protected] Andong Chen Transportation Research Institute University of Michigan, Ann Arbor, MI 48109 Email: [email protected] Vivian Jiang School of Information University of Michigan, Ann Arbor, MI 48109 Email: [email protected] H. V. Jagadish Michigan Institute of Data Science and Electrical Engineering & Computer Science Dept. University of Michigan, Ann Arbor, MI 48109 Email: [email protected] Robert C. Hampshire Gerald Ford School of Public Policy and Transportation Research Institute University of Michigan, Ann Arbor, MI 48109 Email: [email protected] NOTE: This preprint reports new research that has not been certified by peer review and should not be used to guide clinical practice. medRxiv preprint doi: https://doi.org/10.1101/2021.02.04.21251181; this version posted February 8, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted medRxiv a license to display the preprint in perpetuity. -

Download This Resource
Center for Food and Agricultural Business CAB CS 15.1 September 1, 2015 Online Food Shopping: Peapod Finds a Path “Mike, the evidence is clear: Nearly every single technical innovation—from PCs to digital music and mobile phones—has struggled at first with low sales for a long period of time before reaching an inflection point, then rising exponentially. E-commerce is following that principle. We are on the cusp of rapid acceleration.” Andrew Parkinson, founder and president of Peapod, the online grocery company, did not have to convince Mike Brennan, Peapod’s Chief Operating Officer, that Peapod was poised for growth. Grocery was the biggest category in retailing but had proved the most resistant to the advance of online shopping. Nevertheless, Parkinson and Brennan had worked side by side for 18 years to keep Peapod, the nation’s oldest online grocer, in the fore of technological innovation and consumer relevance. They had watched with a certain fascination as many hopeful online food startups had been launched to great fanfare, only soon to fail. If not always profitable in its early years, Peapod had stood the test of time. But despite the hefty investments made and industry-leading status, a new brand of competition was entering the online marketplace and the rules of the game were shifting rapidly. Peapod’s parent company, Royal Dutch Ahold, was one of the world’s largest supermarket companies with 2014 sales of $43.5 billion and more than 3,500 stores.1 Yet most of these stores were conventionally positioned and, in both its European home market and in the US, its historic market shares were being eroded by new competition.