Edge-To-Business Value Chain Delivery Via Elastic Telemetry of Cyber-Physical Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Trinity Iot Product Catalogue
IoT Devices TRINITY IOT PRODUCT CATALOGUE Teltonika Device Range 2021 TABLE OF CONTENTS 1 RUT950 27 TRB142 3 RUT955 29 TRB145 5 RUTX09 31 RUTX10 7 RUTX11 33 RUTX12 9 TRB141 35 RUTX08 11 RUT230 37 TRB255 13 RUT240 39 FMB920 15 RUT850 41 RUTXR1 17 RUT900 43 FM130 19 GH5200 45 BLUE SLIM ID 21 TRB245 47 BLUE COIN MAG 23 TSW100 49 BLUE COIN T 25 TRB140 PRODUCT SHEET / RUT950 ROUTER INTRODUCING RUT950 TRINITY APPROVED & SMART™ COMPATIBLE RUT950 is a highly reliable and secure LTE router for professional applications. Router delivers high performance, mission-critical cellular communication. RUT950 is equipped with connectivity redundancy through dual SIM failover. External antenna connectors make it possible to attach desired antennas and to easily find the best signal location. LTE LTE Cat4 Cat4 LTE Cat 4 with Dual SIM – significantly speeds up to 150 Mps reduce roaming costs WANLTE 4 LTEX failoverCat4 Cat4 Automatic switch to available 4x Ethernet ports backup connection with VLAN functionality LTE LTE Cat4 Cat4 Wireless Access Point Linux Powered with Hotspot functionality Simply order, and we’ll take care of the rest Source Import Test ICASA Management Onboarding 24/7 Platform Support www.trinity.co.za 1 PRODUCT SHEET / RUT950 ROUTER LAN Ethernet Ports WAN Ethernet Ports LTE antenna connectors Power socket WiFi antenna SIM card connectors slots Hardware Weight 256 g CPU Atheros Wasp, MIPS 74Kc, 550 MHz Memory 16 MBytes Flash, 128 MBytes DDR2 RAM Ethernet 4 x 10/100 Ethernet ports: 1 x WAN (configurable as LAN), 3 x LAN ports Power supply 9 -

Focus on Apache Camel 23 3.1 Classification
Institute of Architecture of Application Systems University of Stuttgart Universitätsstraße 38 D–70569 Stuttgart Diploma Thesis No. 3480 Complete Enterprise Topologies with routing information of Enterprise Services Buses to enable Cloud-migration Andre Grund Course of Study: Software Engineering Examiner: Prof. Dr. Frank Leymann Supervisor: Dipl.-Inf. Tobias Binz Commenced: May 01, 2013 Completed: October 28, 2013 CR-Classification: E.1, K.6 Abstract The Enterprise Service Bus is an important part of todays enterprise IT landscape. It offers the integration of applications build on different platforms without adaptation. This is accomplished by offering message transformation and routing capabilities of client requests to the designated endpoint service. However, Enterprise Service Buses also introduce an additional indirection between the client and the called backend application. Enterprise Topology Graphs capture a snapshot of the whole enterprise IT and are used in various use cases for analysis, migration, adaptation, and optimization of IT. The focus of this work is to enhance the ETG model with structural and statistical information about an enterprise. However, due to the decoupled architecture the information is hidden inside the ESB and not directly accessible. Furthermore, the arrangement and semantics of the routing entities are unknown. The existing ETG Framework includes the automated discovery and maintenance of ETGs, but offers no solution for ESB components in the enterprise IT. This thesis provides an in depth analysis of the ESBs Apache Camel and Apache Synapse. It applies information gathering concepts and evaluate them with a prototypical implementation of an ETG Framework plugin. Using tailored information gathering and presentation methods to enhance ETGs with routing information. -
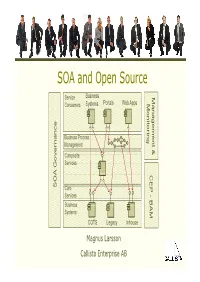
SOA and Open Source
SOA and Open Source Service Business Ma Consumers Systems Portals Web Apps M nageme onitorin g ance Business Process n nn Management t & Composite Services Gover CEP -CEP B AA SO Core Services Business AM Systems COTS Legacy Inhouse Magnus Larsson Callista Enterprise AB Vendor support of Open Source SOA • Vendors provide services for training, consulting and support on selected Open Source SOA products • MuleSource – Over 1000 mission-critical production installations worldwide! – http:// www.mu lesou rce .co m/custo me rs/casestud ies .p hp •WSO2 – http://wso2.com/about/whitepapers/ • Progress FUSE – http://fusesource.com/resources/collateral/ SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… Service Business Portals Web Apps Consumers Systems Business Systems COTS Legacy Inhouse SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… • Connectivity Service Business - SOAP, Rest, Messaging, Database, FTP… Portals Web Apps Consumers Systems • Transformation - XML, CSV, Fixed Position… • Routing - Header and/or Content based • Enterprise Integration Patterns - Splitting, Aggregation, Resequencing… Core Services Business Systems COTS Legacy Inhouse SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… Composite Services Service Business Portals Web Apps Consumers Systems ‐ Course Grained ‐ Internal Messaging High performance access to other services CitComposite Services Core Services Business Systems COTS Legacy Inhouse SOA -

Technical Proposal for One Day Workshop on Fog and Edge
1 Technical Proposal for One Day Workshop on Fog and Edge Computing for Beyond IoT Services and Opportunities IEEE 7th World Forum on Internet of Things New Orleans, Louisiana, USA Workshop Title: Fog and Edge Computing for 6G Networks/IoT Services and Opportunities 1. Preamble As we evolve toward the Internet of Things (IoT), our 5G/6G and future mobile networks must support a much wider range of applications, including vehicular networking, automated man- ufacturing, smart cities, drones, smart grids, e-health, and the many emerging AI-enabled applications such as Virtual Reality (VR) and Augmented Reality (AR). The cloud computing plus communication pipe model is no longer adequate for supporting these emerging appli- cations. Connecting every device directly to the cloud can often be impractical due to factors such as limited resources on the devices, software and management complexity, limited net- work agility and cognition, and system scalability. In such scenarios, users will desire local services. Future mobile networks will also require computing capabilities inside or close to the radio access networks (RANs) to enable advanced networking capabilities, such as estab- lishing radio connections more timely and adjusting radio channel coding dynamically in re- sponse to changing user needs and communication environments, and allow user applica- tions to be hosted in the RANs that are closer to the users. These and the many other new requirements call for a new computing paradigm – fog/edge computing and networking. Fog/Edge envisions an open and standards-based horizontal ar- chitecture for distributing functions (from computing to storage to control and to networking functions) closer to users, not just to any specific type of network edge device but anywhere along the cloud-to-thing continuum that can best meet user requirements. -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Edge Computing in the Context of Open Manufacturing
Edge Computing in the Context of Open Manufacturing 01.07.2021 LEGAL DISCLAIMERS © 2021 Joint Development Foundation Projects, LLC, OMP Series and its contributors. All rights reserved. THESE MATERIALS ARE PROVIDED ”AS IS.” The parties expressly disclaim any warranties (express, implied, or otherwise), including implied warranties of merchantability, non- infringement, fitness for a particular purpose, or title, related tothe materials. The entire risk as to implementing or otherwise using the materials is assumed by the implementer and user. IN NO EVENT WILL THE PARTIES BE LIABLE TO ANY OTHER PARTY FOR LOST PROFITS OR ANY FORM OF INDIRECT, SPECIAL, INCIDENTAL, OR CONSEQUENTIAL DAMAGES OF ANY CHARACTER FROM ANY CAUSES OF ACTION OF ANY KIND WITH RESPECT TO THIS DELIVERABLE OR ITS GOVERNING AGREEMENT, WHETHER BASED ON BREACH OF CONTRACT, TORT (INCLUDING NEGLIGENCE), OR OTHERWISE, AND WHETHER OR NOT THE OTHER MEMBER HAS BEEN ADVISED OF THE POSSIBILITY OF SUCH DAMAGE. 2 ACKNOWLEDGMENTS This document is a work product of the Open Manufacturing Platform – IoT Connectivity Working Group, chaired by Sebastian Buckel (BMW Group) and co-chaired by Dr. Veit Hammerstingl (BMW Group). AUTHORS Anhalt, Christopher, Dr. (Softing) Buckel, Sebastian (BMW Group) Hammerstingl, Veit, Dr. (BMW Group) Köpke, Alexander (Microsoft) Müller, Michael (Capgemini) Muth, Manfred (Red Hat) Ridl, Jethro (Reply) Rummel, Thomas (Softing) Weber Martins, Thiago, Dr. (SAP) FURTHER CONTRIBUTION BY Attrey, Kapil (Cognizant) Kramer, Michael (ZF) Krapp, Chiara (BMW Group) Krebs, Jeremy (Microsoft) McGrath, Daniel (Cognizant) Title Image by Possessed Photography from unsplash.com 3 Contents Contents 1 Introduction: The Importance of Edge Computing 5 2 Definition of Edge Computing 6 3 Reference Use Case 6 4 Views on Edge Computing 8 4.1 Infrastructural View . -

Avaliando a Dívida Técnica Em Produtos De Código Aberto Por Meio De Estudos Experimentais
UNIVERSIDADE FEDERAL DE GOIÁS INSTITUTO DE INFORMÁTICA IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Goiânia 2014 IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Dissertação apresentada ao Programa de Pós–Graduação do Instituto de Informática da Universidade Federal de Goiás, como requisito parcial para obtenção do título de Mestre em Ciência da Computação. Área de concentração: Ciência da Computação. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi Goiânia 2014 Ficha catalográfica elaborada automaticamente com os dados fornecidos pelo(a) autor(a), sob orientação do Sibi/UFG. Vieira, Igor Rodrigues Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais [manuscrito] / Igor Rodrigues Vieira. - 2014. 100 f.: il. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi. Dissertação (Mestrado) - Universidade Federal de Goiás, Instituto de Informática (INF) , Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2014. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas. 1. Dívida técnica. 2. Qualidade de software. 3. Análise estática. 4. Produto de código aberto. 5. Estudo experimental. I. Vincenzi, Auri Marcelo Rizzo, orient. II. Título. Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização da universidade, do autor e do orientador(a). Igor Rodrigues Vieira Graduado em Sistemas de Informação, pela Universidade Estadual de Goiás – UEG, com pós-graduação lato sensu em Desenvolvimento de Aplicações Web com Interfaces Ricas, pela Universidade Federal de Goiás – UFG. Foi Coordenador da Ouvidoria da UFG e, atualmente, é Analista de Tecnologia da Informação do Centro de Recursos Computacionais – CERCOMP/UFG. -

C:\Andrzej\PDF\ABC Nagrywania P³yt CD\1 Strona.Cdr
IDZ DO PRZYK£ADOWY ROZDZIA£ SPIS TREFCI Wielka encyklopedia komputerów KATALOG KSI¥¯EK Autor: Alan Freedman KATALOG ONLINE T³umaczenie: Micha³ Dadan, Pawe³ Gonera, Pawe³ Koronkiewicz, Rados³aw Meryk, Piotr Pilch ZAMÓW DRUKOWANY KATALOG ISBN: 83-7361-136-3 Tytu³ orygina³u: ComputerDesktop Encyclopedia Format: B5, stron: 1118 TWÓJ KOSZYK DODAJ DO KOSZYKA Wspó³czesna informatyka to nie tylko komputery i oprogramowanie. To setki technologii, narzêdzi i urz¹dzeñ umo¿liwiaj¹cych wykorzystywanie komputerów CENNIK I INFORMACJE w ró¿nych dziedzinach ¿ycia, jak: poligrafia, projektowanie, tworzenie aplikacji, sieci komputerowe, gry, kinowe efekty specjalne i wiele innych. Rozwój technologii ZAMÓW INFORMACJE komputerowych, trwaj¹cy stosunkowo krótko, wniós³ do naszego ¿ycia wiele nowych O NOWOFCIACH mo¿liwoYci. „Wielka encyklopedia komputerów” to kompletne kompendium wiedzy na temat ZAMÓW CENNIK wspó³czesnej informatyki. Jest lektur¹ obowi¹zkow¹ dla ka¿dego, kto chce rozumieæ dynamiczny rozwój elektroniki i technologii informatycznych. Opisuje wszystkie zagadnienia zwi¹zane ze wspó³czesn¹ informatyk¹; przedstawia zarówno jej historiê, CZYTELNIA jak i trendy rozwoju. Zawiera informacje o firmach, których produkty zrewolucjonizowa³y FRAGMENTY KSI¥¯EK ONLINE wspó³czesny Ywiat, oraz opisy technologii, sprzêtu i oprogramowania. Ka¿dy, niezale¿nie od stopnia zaawansowania swojej wiedzy, znajdzie w niej wyczerpuj¹ce wyjaYnienia interesuj¹cych go terminów z ró¿nych bran¿ dzisiejszej informatyki. • Komunikacja pomiêdzy systemami informatycznymi i sieci komputerowe • Grafika komputerowa i technologie multimedialne • Internet, WWW, poczta elektroniczna, grupy dyskusyjne • Komputery osobiste — PC i Macintosh • Komputery typu mainframe i stacje robocze • Tworzenie oprogramowania i systemów komputerowych • Poligrafia i reklama • Komputerowe wspomaganie projektowania • Wirusy komputerowe Wydawnictwo Helion JeYli szukasz ]ród³a informacji o technologiach informatycznych, chcesz poznaæ ul. -

Hypotheses Verification for High Precision Cohesion Metric
International Journal of Computer Science and EngineEngineeringering Open Access Research Paper Volume-2, Issue-4 E-ISSN: 2347-2693 Hypotheses Verification for High Precision Cohesion Metric Kayarvizhy N 1*, Kanmani S 2 and Rhymend Uthariaraj V 3 1*Department of Computer Science and Engineering, AMC Engineering College, India 2 Department of Information Technology, Pondicherry Engineering College, India 3Ramanujan Computing Centre, India www.ijcaonline.org Received: 03/03/2014 Revised: 19/03/2014 Accepted: 15/04/201x4 Published: 30/04/2014 Abstract— Metrics have been used to measure many attributes of software. For object oriented software, cohesion indicates the level of binding of the class elements. A class with high cohesion is one of the desirable properties of a good object oriented design. A highly cohesive class is less prone to faults and is easy to develop and maintain. Several object oriented cohesion metrics have been proposed in the literature. In this paper, we propose a new cohesion metric, the High Precision Cohesion Metric (HPCM) to overcome the limitations of the existing cohesion metrics. We also propose seven hypotheses to investigate the relationship between HPCM and other object oriented metrics. The hypotheses are verified with data collected from 500 classes across twelve open source Java projects. We have used Pearson’s coefficient to analyze the correlation between HPCM and the metrics in the hypotheses. To further bolster our results we have included p-value to confirm the statistical significance of the findings. Keywords—Object Oriented Metrics; Cohesion; High Precision I. INTRODUCTION values. Li and Henry [10] proposed their version of lack of Object oriented design and development continues to be the cohesion (LCOM3) as the number of connected components most widely used methodology for designing high quality in a graph with methods as node and edges between each software. -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Towards Identifying Software Project Clusters with Regard to Defect Prediction
Towards identifying software project clusters with regard to defect prediction Marian Jureczko, Wroc!aw University of Technology Lech Madeyski, Wroc!aw University of Technology Agenda •! Introduction •! Data acquisition •! Study design •! Results •! Conclusions Introduction Motivation – Why defect prediction? 20% of classes contain 80% of defects We can use the software metrics to predict error prone classes and therefore prioritize and optimize tests. Motivation – Why clustering projects? •! Defect prediction is sometime impossible because lack of training data: –! It may be the first release of a project –! The company or the project may be to small to afford collecting training data •! With well defined project clusters the cross-project defect prediction will be possible Definitions •!Defect -! Interpreted as a defect in the investigated project -! Commented in the version control system (CVS or SVN) •!Defect prediction model Values of Metrics for a given java class Estimated •!WMC = ... Number •!DIT = ... Model of •!NOC = ... •!CBO = ... Defects •!RFC = … •!LCOM = … •!Ca=... •!.... Data acquisition •! 19 different metrics were calculated with the CKJM tool (http://gromit.iiar.pwr.wroc.pl/p_inf/ckjm) •! Chidamber & Kemerer metrics suite •! QMOOD metrics suite •! Tang, Kao and Chen’s metrics (C&K quality oriented extension) •! Cyclomatic Complexity, LCOM3, Ca, Ce and LOC •! Defects were collected with BugInfo ( http://kenai.com/projects/buginfo) Compare CVS/SVN Bug CVS log against given & SVN regular expression metrics repository Data -

Kuali Student Service System: Technical Architecture Phase 1 Recommendations
Kuali Student Service System Technical Architecture Phase 1 Recommendations Kuali Student Service System Technical Architecture Phase 1 Recommendations December 31 2007 Kuali Student Technical Team Technical Architecture Phase 1 deliverables 2/14/2008 1 Kuali Student Service System Technical Architecture Phase 1 Recommendations Table of Contents 1 OVERVIEW ........................................................................................................................ 4 1.1 REASON FOR THE INVESTIGATION ................................................................................... 4 1.2 SCOPE OF THE INVESTIGATION ....................................................................................... 4 1.3 METHODOLOGY OF THE INVESTIGATION .......................................................................... 4 1.4 CONCLUSIONS ............................................................................................................... 5 1.5 DECISIONS THAT HAVE BEEN DELAYED ............................................................................ 6 2 STANDARDS ..................................................................................................................... 7 2.1 INTRODUCTION .............................................................................................................. 7 2.2 W3C STANDARDS .......................................................................................................... 7 2.3 OASIS STANDARDS ......................................................................................................