Focus on Apache Camel 23 3.1 Classification
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Oracle Takes on IBM and HP with Hardware, Software and Services Triple Play by Arif Mohamed
CW+ a whitepaper from ComputerWeekly Oracle takes on IBM and HP with hardware, software and services triple play by Arif Mohamed This has been a landmark year for Oracle, the technology company headed by the charismatic and staggeringly wealthy Larry Ellison. Ellison, who is 65, has been chief executive officer since he founded Oracle in June 1977. He was listed the sixth richest person in the world in 2010. And his personal wealth of $27bn is a clear indication of Oracle’s success as an IT supplier. Oracle began the year by completing its $7.4bn acquisition of Sun Microsystems. The deal transformed Oracle from a software and consulting company, into a company able to compete on software, hardware and services. The deal gave Oracle Sun’s MySQL database, Sparc/Solaris servers, plus Sun’s storage hardware and flagship Java portfolio of tools and technologies. 2010 also marked the conclusion of an aggressive spending spree that has seen Oracle buying over 66 technology companies since 2002. These include CRM suppliers Siebel and PeopleSoft, middleware giant BEA Systems and storage specialist StorageTek. Six years on, Oracle has announced the fruits of its integration work, which began in 2004 when it bought PeopleSoft, which owned JD Edwards. Although Oracle has integrated the suites of applications from each subsequent merger to some degree, but it has now revealed a suite of software, Fusion Applications, which promises to unite them all for the first time through a common middleware layer, and run on optimised hardware from the Sun acquisition. Its Fusion Applications range of enterprise products, due out in January, will also give an upgrade path to enterprise users of Oracle’s legacy CRM and other business packages including PeopleSoft, Siebel and JD Edwards. -

An Introduction to the Enterprise Service Bus
An Introduction to the Enterprise Service Bus Martin Breest Hasso-Plattner-Institute for IT Systems Engineering at the University of Potsdam, Prof.-Dr.-Helmert-Str. 2-3, D-14482 Potsdam, Germany [email protected] Abstract. The enterprise service bus (ESB) is the most promising ap- proach to enterprise application integration (EAI) of the last years. It promises to build up a service-oriented architecture (SOA) by itera- tively integrating all kinds of isolated applications into a decentralized infrastructure. This infrastructure combines best practices from EAI, like message-oriented middleware (MOM), (Web) services, routing and XML processing facilities, in order to provide, use and compose (Web) services. Because the term ESB is often used to name different things, for exam- ple an architecture, a product or a ”way of doing things”, I point out in this paper what exactly an ESB is. Therefore, I first describe what distinguishes the ESB from former EAI solutions. Second, I show what the key components of an ESB are. Finally, I explain how these key components function alone and how they work together to achieve the aforementioned goal. 1 Introduction Due to the ongoing globalization, enterprises all over the world have to face a fierce competition. In order to stay in business, they constantly have to automate their business processes, integrate with their business partners and provide new services to their customers. With the changing demands in business, the goal of IT has also changed. Today, IT has to actively support enterprises in global competition. Therefore, it has to make business functionality and information available across the enterprise in order to allow software engineers to create, automate and integrate business processes and company workers to access all kinds of information in a unified way via a department- or enterprise-wide portal. -
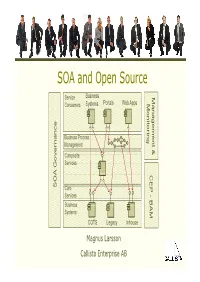
SOA and Open Source
SOA and Open Source Service Business Ma Consumers Systems Portals Web Apps M nageme onitorin g ance Business Process n nn Management t & Composite Services Gover CEP -CEP B AA SO Core Services Business AM Systems COTS Legacy Inhouse Magnus Larsson Callista Enterprise AB Vendor support of Open Source SOA • Vendors provide services for training, consulting and support on selected Open Source SOA products • MuleSource – Over 1000 mission-critical production installations worldwide! – http:// www.mu lesou rce .co m/custo me rs/casestud ies .p hp •WSO2 – http://wso2.com/about/whitepapers/ • Progress FUSE – http://fusesource.com/resources/collateral/ SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… Service Business Portals Web Apps Consumers Systems Business Systems COTS Legacy Inhouse SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… • Connectivity Service Business - SOAP, Rest, Messaging, Database, FTP… Portals Web Apps Consumers Systems • Transformation - XML, CSV, Fixed Position… • Routing - Header and/or Content based • Enterprise Integration Patterns - Splitting, Aggregation, Resequencing… Core Services Business Systems COTS Legacy Inhouse SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… Composite Services Service Business Portals Web Apps Consumers Systems ‐ Course Grained ‐ Internal Messaging High performance access to other services CitComposite Services Core Services Business Systems COTS Legacy Inhouse SOA -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

ESB and SOA Infrastructure
eBook ESB and SOA Infrastructure The Enterprise Service Bus (ESB) is a form of plumbing that enables effective SOA implementation. But understanding the ESB remains an industry-wide quest. Open source consultant Jeff Genender lists a message bus first on his list of the basic building blocks of a successful SOA infrastructure. And yet, some recent Forrester survey results show that first-time SOA infrastructure purchases maybe shifting from ESBs to other SOA technologies. Read this eBook to learn more about ESBs including: • The role of ESBs in application integration • Tips on open source and SOA infrastructure from Jeff Genender • Forrester's take on where the ESB fits in today's enterprise architecture Sponsored By: SearchSOA.com eBook ESB and SOA Infrastructure eBook ESB and SOA Infrastructure Table of Contents The ESB and its role in application integration architecture Working with ActiveMQ – Tips from TSSJS presenter Jeff Genender part one On SOA infrastructure – Tips from TSSJS presenter Jeff Genender part two Forrester analysts: SOA still strong Resources from FuseSource Sponsored By: Page 2 of 10 SearchSOA.com eBook ESB and SOA Infrastructure The ESB and its role in application integration architecture By Alan Earls Although enterprise service busses (ESBs) are not new, they can continue to be a nexus for confusion. After many years and many implementations, what they do, how they do it and whether specific products can help create a SOA are all still matters of contention. Chris Harding, a forum director for SOA and client computing at The Open Group, argues that there isn’t always clarity regarding the nature of ESBs. -

Avaliando a Dívida Técnica Em Produtos De Código Aberto Por Meio De Estudos Experimentais
UNIVERSIDADE FEDERAL DE GOIÁS INSTITUTO DE INFORMÁTICA IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Goiânia 2014 IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Dissertação apresentada ao Programa de Pós–Graduação do Instituto de Informática da Universidade Federal de Goiás, como requisito parcial para obtenção do título de Mestre em Ciência da Computação. Área de concentração: Ciência da Computação. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi Goiânia 2014 Ficha catalográfica elaborada automaticamente com os dados fornecidos pelo(a) autor(a), sob orientação do Sibi/UFG. Vieira, Igor Rodrigues Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais [manuscrito] / Igor Rodrigues Vieira. - 2014. 100 f.: il. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi. Dissertação (Mestrado) - Universidade Federal de Goiás, Instituto de Informática (INF) , Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2014. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas. 1. Dívida técnica. 2. Qualidade de software. 3. Análise estática. 4. Produto de código aberto. 5. Estudo experimental. I. Vincenzi, Auri Marcelo Rizzo, orient. II. Título. Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização da universidade, do autor e do orientador(a). Igor Rodrigues Vieira Graduado em Sistemas de Informação, pela Universidade Estadual de Goiás – UEG, com pós-graduação lato sensu em Desenvolvimento de Aplicações Web com Interfaces Ricas, pela Universidade Federal de Goiás – UFG. Foi Coordenador da Ouvidoria da UFG e, atualmente, é Analista de Tecnologia da Informação do Centro de Recursos Computacionais – CERCOMP/UFG. -

Enterprise Service Bus As Testing Sandbox for SOAP and REST Web Services Talend, Global Leader in Open Source Integra�On Solu�Ons
Enterprise Service Bus as Testing Sandbox for SOAP and REST Web Services Talend, Global Leader in Open Source Integraon Solu7ons Kai Wähner Principal Consultant [email protected] @KaiWaehner Xing / LinkedIn www.kai-waehner.de Agenda ➜ Introduc7on „Talend ESB“ ➜ Test Scenarios for Talend ESB ➜ Live Demo Agenda ➜ Introduc7on „Talend ESB“ ➜ Test Scenarios for Talend ESB ➜ Live Demo Talend Overview At a glance Talend today ➜ 400 employees in 7 countries with dual HQ in Los Altos, CA ▶ Founded in 2005 and Paris, France ➜ Over 4,000 paying customers across different industry ▶ Offers highly scalable integraon solu7ons ver7cals and company sizes addressing Data Integraon, ➜ Backed by Silver Lake Sumeru, Balderton Capital and Data Quality, MDM, ESB and Idinvest Partners BPM ▶ Provides: High growth through a proven model § Subscripons including Brand 24/7 support and Awareness indemnificaon; 20 million § Worldwide training and Downloads services ▶ Recognized as the open source Market leader in each of its market Momentum Adop-on categories +50 New 1,000,000 Customers / Users Month Mone-za-on 4,000 Customers Next Generation Solutions To address these trends in the integraon market, Talend offers a Unique Solu7on built on Next Gen Technology, presented through a disrup7ve Business Model Solution Technology Model ➜ Best-of-Breed ➜ Code Generator ➜ Open Source ➜ Unified Plaorm ➜ 100% Standards- ➜ Community-Based Based ➜ Converged ➜ Subscripon Pricing Integraon ➜ Distributed Architecture Key Differentiators of our Next Gen Architecture… ➜ No black-box -

Hypotheses Verification for High Precision Cohesion Metric
International Journal of Computer Science and EngineEngineeringering Open Access Research Paper Volume-2, Issue-4 E-ISSN: 2347-2693 Hypotheses Verification for High Precision Cohesion Metric Kayarvizhy N 1*, Kanmani S 2 and Rhymend Uthariaraj V 3 1*Department of Computer Science and Engineering, AMC Engineering College, India 2 Department of Information Technology, Pondicherry Engineering College, India 3Ramanujan Computing Centre, India www.ijcaonline.org Received: 03/03/2014 Revised: 19/03/2014 Accepted: 15/04/201x4 Published: 30/04/2014 Abstract— Metrics have been used to measure many attributes of software. For object oriented software, cohesion indicates the level of binding of the class elements. A class with high cohesion is one of the desirable properties of a good object oriented design. A highly cohesive class is less prone to faults and is easy to develop and maintain. Several object oriented cohesion metrics have been proposed in the literature. In this paper, we propose a new cohesion metric, the High Precision Cohesion Metric (HPCM) to overcome the limitations of the existing cohesion metrics. We also propose seven hypotheses to investigate the relationship between HPCM and other object oriented metrics. The hypotheses are verified with data collected from 500 classes across twelve open source Java projects. We have used Pearson’s coefficient to analyze the correlation between HPCM and the metrics in the hypotheses. To further bolster our results we have included p-value to confirm the statistical significance of the findings. Keywords—Object Oriented Metrics; Cohesion; High Precision I. INTRODUCTION values. Li and Henry [10] proposed their version of lack of Object oriented design and development continues to be the cohesion (LCOM3) as the number of connected components most widely used methodology for designing high quality in a graph with methods as node and edges between each software. -

Hänninen, Arttu Enterprise Integration Patterns in Service Oriented Systems Master of Science Thesis
CORE Metadata, citation and similar papers at core.ac.uk Provided by Trepo - Institutional Repository of Tampere University Hänninen, Arttu Enterprise Integration Patterns in Service Oriented Systems Master of Science Thesis Examiner: Prof. Tommi Mikkonen Examiners and topic approved in the council meeting of Faculty of Information Technology on April 3rd, 2013. II TIIVISTELMÄ TAMPEREEN TEKNILLINEN YLIOPISTO Tietotekniikan koulutusohjelma Hänninen, Arttu: Enterprise Integration Patterns in Service Oriented Systems Diplomityö, 58 sivua Kesäkuu 2014 Pääaine: Ohjelmistotuotanto Tarkastajat: Prof. Tommi Mikkonen Avainsanat: Enterprise Integration Patterns, Palvelukeskeinen arkkitehtuuri (SOA), Viestipohjainen integraatio Palvelupohjaisen integraation toteuttaminen mihin tahansa tietojärjestelmään on haas- tavaa, sillä integraatioon liittyvät järjestelmät voivat muuttua jatkuvasti. Integraatiototeu- tusten tulee olla tarpeeksi joustavia, jotta ne pystyvät mukautumaan mahdollisiin muu- toksiin. Toteutukseen voidaan käyttää apuna eri sovelluskehyksiä, mutta ne eivät vält- tämättä takaa mitään standardoitua tapaa tehdä integraatio. Tätä varten on luotu joukko ohjeita (Enterprise Integration Patterns, EIP), jotka kuvaavat hyväksi havaittuja tapoja tehdä integraatioita. Tässä työssä keskitytään näiden mallien tutkimiseen ja siihen, miten niitä voidaan hyödyntää yritysjärjestelmissä. Jotta tutkimukseen saadaan konkreettinen vertailutulos, erään järjestelmän integraatioratkaisu tullaan päivittämään uuteen. Uusi ratkaisu hyödyntää sovelluskehystä, -

Full-Graph-Limited-Mvn-Deps.Pdf
org.jboss.cl.jboss-cl-2.0.9.GA org.jboss.cl.jboss-cl-parent-2.2.1.GA org.jboss.cl.jboss-classloader-N/A org.jboss.cl.jboss-classloading-vfs-N/A org.jboss.cl.jboss-classloading-N/A org.primefaces.extensions.master-pom-1.0.0 org.sonatype.mercury.mercury-mp3-1.0-alpha-1 org.primefaces.themes.overcast-${primefaces.theme.version} org.primefaces.themes.dark-hive-${primefaces.theme.version}org.primefaces.themes.humanity-${primefaces.theme.version}org.primefaces.themes.le-frog-${primefaces.theme.version} org.primefaces.themes.south-street-${primefaces.theme.version}org.primefaces.themes.sunny-${primefaces.theme.version}org.primefaces.themes.hot-sneaks-${primefaces.theme.version}org.primefaces.themes.cupertino-${primefaces.theme.version} org.primefaces.themes.trontastic-${primefaces.theme.version}org.primefaces.themes.excite-bike-${primefaces.theme.version} org.apache.maven.mercury.mercury-external-N/A org.primefaces.themes.redmond-${primefaces.theme.version}org.primefaces.themes.afterwork-${primefaces.theme.version}org.primefaces.themes.glass-x-${primefaces.theme.version}org.primefaces.themes.home-${primefaces.theme.version} org.primefaces.themes.black-tie-${primefaces.theme.version}org.primefaces.themes.eggplant-${primefaces.theme.version} org.apache.maven.mercury.mercury-repo-remote-m2-N/Aorg.apache.maven.mercury.mercury-md-sat-N/A org.primefaces.themes.ui-lightness-${primefaces.theme.version}org.primefaces.themes.midnight-${primefaces.theme.version}org.primefaces.themes.mint-choc-${primefaces.theme.version}org.primefaces.themes.afternoon-${primefaces.theme.version}org.primefaces.themes.dot-luv-${primefaces.theme.version}org.primefaces.themes.smoothness-${primefaces.theme.version}org.primefaces.themes.swanky-purse-${primefaces.theme.version} -

Towards Identifying Software Project Clusters with Regard to Defect Prediction
Towards identifying software project clusters with regard to defect prediction Marian Jureczko, Wroc!aw University of Technology Lech Madeyski, Wroc!aw University of Technology Agenda •! Introduction •! Data acquisition •! Study design •! Results •! Conclusions Introduction Motivation – Why defect prediction? 20% of classes contain 80% of defects We can use the software metrics to predict error prone classes and therefore prioritize and optimize tests. Motivation – Why clustering projects? •! Defect prediction is sometime impossible because lack of training data: –! It may be the first release of a project –! The company or the project may be to small to afford collecting training data •! With well defined project clusters the cross-project defect prediction will be possible Definitions •!Defect -! Interpreted as a defect in the investigated project -! Commented in the version control system (CVS or SVN) •!Defect prediction model Values of Metrics for a given java class Estimated •!WMC = ... Number •!DIT = ... Model of •!NOC = ... •!CBO = ... Defects •!RFC = … •!LCOM = … •!Ca=... •!.... Data acquisition •! 19 different metrics were calculated with the CKJM tool (http://gromit.iiar.pwr.wroc.pl/p_inf/ckjm) •! Chidamber & Kemerer metrics suite •! QMOOD metrics suite •! Tang, Kao and Chen’s metrics (C&K quality oriented extension) •! Cyclomatic Complexity, LCOM3, Ca, Ce and LOC •! Defects were collected with BugInfo ( http://kenai.com/projects/buginfo) Compare CVS/SVN Bug CVS log against given & SVN regular expression metrics repository Data -

Kuali Student Service System: Technical Architecture Phase 1 Recommendations
Kuali Student Service System Technical Architecture Phase 1 Recommendations Kuali Student Service System Technical Architecture Phase 1 Recommendations December 31 2007 Kuali Student Technical Team Technical Architecture Phase 1 deliverables 2/14/2008 1 Kuali Student Service System Technical Architecture Phase 1 Recommendations Table of Contents 1 OVERVIEW ........................................................................................................................ 4 1.1 REASON FOR THE INVESTIGATION ................................................................................... 4 1.2 SCOPE OF THE INVESTIGATION ....................................................................................... 4 1.3 METHODOLOGY OF THE INVESTIGATION .......................................................................... 4 1.4 CONCLUSIONS ............................................................................................................... 5 1.5 DECISIONS THAT HAVE BEEN DELAYED ............................................................................ 6 2 STANDARDS ..................................................................................................................... 7 2.1 INTRODUCTION .............................................................................................................. 7 2.2 W3C STANDARDS .......................................................................................................... 7 2.3 OASIS STANDARDS ......................................................................................................