Towards Identifying Software Project Clusters with Regard to Defect Prediction
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

FREE DOWNLOAD COMPONENTS/THIRD PARTY TERMS and CONDITIONS PROGRAM: Sybase® Replication Server® - Data Assurance Option Version 15.6.X (All Platforms)
FREE DOWNLOAD COMPONENTS/THIRD PARTY TERMS AND CONDITIONS PROGRAM: Sybase® Replication Server® - Data Assurance Option version 15.6.x (all platforms) The Program contains open source and other free download components as identified below. Third party license terms and other third party-required notices are provided below. Apache Software Foundation Components: Derby, Commons Digester and Commons Logging The Program includes software developed by the Apache Software Foundation. The Apache components are provided subject to the Apache License v2.0. Copyright© 1999-2010 The Apache Software Foundation. All rights reserved. A copy of the Apache License v2.0 is attached as Attachment 1. The Derby includes the third party components listed in Attachment 2. Sun Microsystems Component: Java Runtime Environment 1.6 The Java Runtime Environment includes the third party components listed in Attachment 3. Flexera Software Component: InstallAnywhere No third party license terms or additional notices required. Startertool.com Component: Startertool No third party license terms or additional notices required. Sun Microsystems Component: Java Servlets No third party license terms or additional notices required. Sybase Common Security Infrastructure Components This version of the Program includes Common Security Infrastructure v3.1 which contains the following additional open source and free download components: Apache Software Foundation Components: Apache xml-sec, Commons BeanUtils, Commons Digester, Commons Validator, Commons Logging, Commons FileUpload and Struts The Program includes software developed by the Apache Software Foundation. Copyright© 1999- 2004 The Apache Software Foundation. All rights reserved. A copy of the Apache License v2.0 is at Attachment 1. OpenSAML.org Component: OpenSAML The Program includes software made available by OpenSAML.org. -

Merchandise Planning and Optimization Licensing Information
Oracle® Retail Merchandise Planning and Optimization Licensing Information July 2009 This document provides licensing information for all the third-party applications used by the following Oracle Retail applications: ■ Oracle Retail Clearance Optimization Engine ■ Oracle Retail Markdown Optimization ■ Oracle Retail Place ■ Oracle Retail Plan ■ Oracle Retail Promote (PPO and PI) Prerequisite Softwares and Licenses Oracle Retail products depend on the installation of certain essential products (with commercial licenses), but the company does not bundle these third-party products within its own installation media. Acquisition of licenses for these products should be handled directly with the vendor. The following products are not distributed along with the Oracle Retail product installation media: ® ■ BEA WebLogic Server (http://www.bea.com) ™ ■ MicroStrategy Desktop (http://www.microstrategy.com) ■ MicroStrategy Intelligence Server™ and Web Universal (http://www.microstrategy.com) ® ■ Oracle Database 10g (http://www.oracle.com) ® ■ Oracle Application Server 10g (http://www.oracle.com) ® ■ Oracle Business Intelligence Suite Enterprise Edition Version 10 (http://www.oracle.com) ■ rsync (http://samba.anu.edu.au/rsync/). See rsync License. 1 Softwares and Licenses Bundled with Oracle Retail Products The following third party products are bundled along with the Oracle Retail product code and Oracle has acquired the necessary licenses to bundle the software along with the Oracle Retail product: ■ addObject.com NLSTree Professional version 2.3 -

Coldfusion Server and Performance Management Suite 2018
ColdFusion Server and Performance Management Suite 2018 Third Party Software Notices and/or Additional Terms and Conditions Date Generated: 2018/09/10 LibJPEG ID: 54 Thomas G. Lane This software is based in part on the work of the Independent JPEG Group. _________________________________________________________________________________________________________ Adobe modified Zlib ID: 823 Jean-loup Gailly and Mark Adler Portions include technology used under license from Jean-loup Gailly and Mark Adler, and are copyrighted. _________________________________________________________________________________________________________ Apache Commons Collections ID: 306 Apache Foundation and Contributors This product includes software licensed under the Apache License, Version 2.0 http://www.apache.org/licenses/LICENSE-2.0 _________________________________________________________________________________________________________ Apache Commons Collections ID: 1132 The Apache Software Foundation The Apache Software License, Version 1.1 Copyright (c) 1999-2001, 1999-2003 The Apache Software Foundation. All rights reserved. Redistribution and use in source and binary forms, with or without modification, are permitted provided that the following conditions are met: 1. Redistributions of source code must retain the above copyright notice, this list of conditions and the following disclaimer. 2. Redistributions in binary form must reproduce the above copyright notice, this list of conditions and the following disclaimer in the documentation and/or other -

Open Source Used in Cisco Unity Connection 11.5 SU 1
Open Source Used In Cisco Unity Connection 11.5 SU 1 Cisco Systems, Inc. www.cisco.com Cisco has more than 200 offices worldwide. Addresses, phone numbers, and fax numbers are listed on the Cisco website at www.cisco.com/go/offices. Text Part Number: 78EE117C99-132949842 Open Source Used In Cisco Unity Connection 11.5 SU 1 1 This document contains licenses and notices for open source software used in this product. With respect to the free/open source software listed in this document, if you have any questions or wish to receive a copy of any source code to which you may be entitled under the applicable free/open source license(s) (such as the GNU Lesser/General Public License), please contact us at [email protected]. In your requests please include the following reference number 78EE117C99-132949842 Contents 1.1 ace 5.3.5 1.1.1 Available under license 1.2 Apache Commons Beanutils 1.6 1.2.1 Notifications 1.2.2 Available under license 1.3 Apache Derby 10.8.1.2 1.3.1 Available under license 1.4 Apache Mina 2.0.0-RC1 1.4.1 Available under license 1.5 Apache Standards Taglibs 1.1.2 1.5.1 Available under license 1.6 Apache STRUTS 1.2.4. 1.6.1 Available under license 1.7 Apache Struts 1.2.9 1.7.1 Available under license 1.8 Apache Xerces 2.6.2. 1.8.1 Notifications 1.8.2 Available under license 1.9 axis2 1.3 1.9.1 Available under license 1.10 axis2/cddl 1.3 1.10.1 Available under license 1.11 axis2/cpl 1.3 1.11.1 Available under license 1.12 BeanUtils(duplicate) 1.6.1 1.12.1 Notifications Open Source Used In Cisco Unity Connection -

Focus on Apache Camel 23 3.1 Classification
Institute of Architecture of Application Systems University of Stuttgart Universitätsstraße 38 D–70569 Stuttgart Diploma Thesis No. 3480 Complete Enterprise Topologies with routing information of Enterprise Services Buses to enable Cloud-migration Andre Grund Course of Study: Software Engineering Examiner: Prof. Dr. Frank Leymann Supervisor: Dipl.-Inf. Tobias Binz Commenced: May 01, 2013 Completed: October 28, 2013 CR-Classification: E.1, K.6 Abstract The Enterprise Service Bus is an important part of todays enterprise IT landscape. It offers the integration of applications build on different platforms without adaptation. This is accomplished by offering message transformation and routing capabilities of client requests to the designated endpoint service. However, Enterprise Service Buses also introduce an additional indirection between the client and the called backend application. Enterprise Topology Graphs capture a snapshot of the whole enterprise IT and are used in various use cases for analysis, migration, adaptation, and optimization of IT. The focus of this work is to enhance the ETG model with structural and statistical information about an enterprise. However, due to the decoupled architecture the information is hidden inside the ESB and not directly accessible. Furthermore, the arrangement and semantics of the routing entities are unknown. The existing ETG Framework includes the automated discovery and maintenance of ETGs, but offers no solution for ESB components in the enterprise IT. This thesis provides an in depth analysis of the ESBs Apache Camel and Apache Synapse. It applies information gathering concepts and evaluate them with a prototypical implementation of an ETG Framework plugin. Using tailored information gathering and presentation methods to enhance ETGs with routing information. -

Oracle Java Composite Application Platform Suite 6.3 Release Notes
Oracle® Java Composite Application Platform Suite 6.3 Release Notes Part No: 821–2528 December 2011 Copyright © 2009, 2011, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS. Programs, software, databases, and related documentation and technical data delivered to U.S. Government customers are "commercial computer software" or "commercial technical data" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, duplication, disclosure, modification, and adaptation shall be subject to the restrictions and license terms setforth in the applicable Government contract, and, to the extent applicable by the terms of the Government contract, the additional rights set forth in FAR 52.227-19, Commercial Computer Software License (December 2007). Oracle America, Inc., 500 Oracle Parkway, Redwood City, CA 94065. -
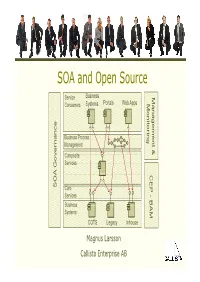
SOA and Open Source
SOA and Open Source Service Business Ma Consumers Systems Portals Web Apps M nageme onitorin g ance Business Process n nn Management t & Composite Services Gover CEP -CEP B AA SO Core Services Business AM Systems COTS Legacy Inhouse Magnus Larsson Callista Enterprise AB Vendor support of Open Source SOA • Vendors provide services for training, consulting and support on selected Open Source SOA products • MuleSource – Over 1000 mission-critical production installations worldwide! – http:// www.mu lesou rce .co m/custo me rs/casestud ies .p hp •WSO2 – http://wso2.com/about/whitepapers/ • Progress FUSE – http://fusesource.com/resources/collateral/ SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… Service Business Portals Web Apps Consumers Systems Business Systems COTS Legacy Inhouse SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… • Connectivity Service Business - SOAP, Rest, Messaging, Database, FTP… Portals Web Apps Consumers Systems • Transformation - XML, CSV, Fixed Position… • Routing - Header and/or Content based • Enterprise Integration Patterns - Splitting, Aggregation, Resequencing… Core Services Business Systems COTS Legacy Inhouse SOA and Open Source Copyright 2009, Callista Enterprise AB Building a SOA Reference Model… Composite Services Service Business Portals Web Apps Consumers Systems ‐ Course Grained ‐ Internal Messaging High performance access to other services CitComposite Services Core Services Business Systems COTS Legacy Inhouse SOA -

Return of Organization Exempt from Income
OMB No. 1545-0047 Return of Organization Exempt From Income Tax Form 990 Under section 501(c), 527, or 4947(a)(1) of the Internal Revenue Code (except black lung benefit trust or private foundation) Open to Public Department of the Treasury Internal Revenue Service The organization may have to use a copy of this return to satisfy state reporting requirements. Inspection A For the 2011 calendar year, or tax year beginning 5/1/2011 , and ending 4/30/2012 B Check if applicable: C Name of organization The Apache Software Foundation D Employer identification number Address change Doing Business As 47-0825376 Name change Number and street (or P.O. box if mail is not delivered to street address) Room/suite E Telephone number Initial return 1901 Munsey Drive (909) 374-9776 Terminated City or town, state or country, and ZIP + 4 Amended return Forest Hill MD 21050-2747 G Gross receipts $ 554,439 Application pending F Name and address of principal officer: H(a) Is this a group return for affiliates? Yes X No Jim Jagielski 1901 Munsey Drive, Forest Hill, MD 21050-2747 H(b) Are all affiliates included? Yes No I Tax-exempt status: X 501(c)(3) 501(c) ( ) (insert no.) 4947(a)(1) or 527 If "No," attach a list. (see instructions) J Website: http://www.apache.org/ H(c) Group exemption number K Form of organization: X Corporation Trust Association Other L Year of formation: 1999 M State of legal domicile: MD Part I Summary 1 Briefly describe the organization's mission or most significant activities: to provide open source software to the public that we sponsor free of charge 2 Check this box if the organization discontinued its operations or disposed of more than 25% of its net assets. -

Server Administration Guide
Oracle Utilities Mobile Workforce Management, Version 2.3.0.3 Server Administration Guide Oracle Utilities Mobile Workforce Management Version 2.3.0.3 (OUAF 4.3.0.6.0) F11043-01 November 2018 1 - Server Administration Guide Oracle Utilities Mobile Workforce Management, Version 2.3.0.3 Server Administration Guide, Oracle Utilities Mobile Workforce Management, Version 2.3.0.3 (OUAF 4.3.0.6.0) F11043-01 Copyright © 2007-2018 Oracle. All rights reserved. Primary Author: Oracle Utilitie Global Business Unit The Programs (which include both the software and documentation) contain proprietary information; they are provided under a license agreement containing restrictions on use and disclosure and are also protected by copyright, patent, and other intellectual and industrial property laws. Reverse engineering, disassembly, or decompilation of the Programs, except to the extent required to obtain interoperability with other independently created software or as specified by law, is prohibited. The information contained in this document is subject to change without notice. If you find any problems in the documentation, please report them to us in writing. This document is not warranted to be error-free. Except as may be expressly permitted in your license agreement for these Programs, no part of these Programs may be reproduced or transmitted in any form or by any means, electronic or mechanical, for any purpose. If the Programs are delivered to the United States Government or anyone licensing or using the Programs on behalf of the United States Government, the following notice is applicable: U.S. GOVERNMENT RIGHTS Programs, software, databases, and related documentation and technical data delivered to U.S. -

Oncommand Core Package Software Products
Notices About this information The following copyright statements and licenses apply to software components that are distributed with various versions of the OnCommand Core package software products. Your product does not necessarily use all the software components referred to below. Where required, source code is published at the following location: ftp://ftp.netapp.com/frm-ntap/opensource/ Copyrights and licenses The following components are subject to the Apache License 1.1: ◆ Apache Tomcat - 5.0.20 Copyright © 2004 The Apache Software Foundation. All rights reserved. ◆ Apache-HTTP Server - 1.1.1 Copyright © 2000-2002 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta BCEL 5 Copyright © 2001 The Apache Software Foundation. All rights reserved. ◆ Apache Xerces Java XML Parser 2.6.1 Copyright © 1999- 2003 The Apache Software Foundation. All rights reserved. ◆ Apache Base64 functions 1.1 Copyright © 2000- 2002 The Apache Software Foundation. All rights reserved. ◆ Apache HTTP Server 1.1.1 Copyright © 2000- 2002 The Apache Software Foundation. All rights reserved. ◆ Apache Xerces Java XML Parser 2.6.2 Copyright © 2000- 2002 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta Commons CLI - 1.0 Copyright © 2002-2010 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta Commons Collections - 2.1 Copyright © 2001-2008 The Apache Software Foundation. All rights reserved. ◆ Apache Jakarta Commons Discovery - 0.2 Copyright © 2002-2011 The Apache Software Foundation . ◆ Apache Jakarta Commons FileUpload - 1.0 Copyright © 2002-2010 The Apache Software Foundation . All rights reserved. ◆ Apache log4j - 1.2.8 Notices 1 215-05829_A0—Copyright © 2011 NetApp, Inc. All rights reserved. Copyright 2007 The Apache Software Foundation. -

Avaliando a Dívida Técnica Em Produtos De Código Aberto Por Meio De Estudos Experimentais
UNIVERSIDADE FEDERAL DE GOIÁS INSTITUTO DE INFORMÁTICA IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Goiânia 2014 IGOR RODRIGUES VIEIRA Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais Dissertação apresentada ao Programa de Pós–Graduação do Instituto de Informática da Universidade Federal de Goiás, como requisito parcial para obtenção do título de Mestre em Ciência da Computação. Área de concentração: Ciência da Computação. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi Goiânia 2014 Ficha catalográfica elaborada automaticamente com os dados fornecidos pelo(a) autor(a), sob orientação do Sibi/UFG. Vieira, Igor Rodrigues Avaliando a dívida técnica em produtos de código aberto por meio de estudos experimentais [manuscrito] / Igor Rodrigues Vieira. - 2014. 100 f.: il. Orientador: Prof. Dr. Auri Marcelo Rizzo Vincenzi. Dissertação (Mestrado) - Universidade Federal de Goiás, Instituto de Informática (INF) , Programa de Pós-Graduação em Ciência da Computação, Goiânia, 2014. Bibliografia. Apêndice. Inclui algoritmos, lista de figuras, lista de tabelas. 1. Dívida técnica. 2. Qualidade de software. 3. Análise estática. 4. Produto de código aberto. 5. Estudo experimental. I. Vincenzi, Auri Marcelo Rizzo, orient. II. Título. Todos os direitos reservados. É proibida a reprodução total ou parcial do trabalho sem autorização da universidade, do autor e do orientador(a). Igor Rodrigues Vieira Graduado em Sistemas de Informação, pela Universidade Estadual de Goiás – UEG, com pós-graduação lato sensu em Desenvolvimento de Aplicações Web com Interfaces Ricas, pela Universidade Federal de Goiás – UFG. Foi Coordenador da Ouvidoria da UFG e, atualmente, é Analista de Tecnologia da Informação do Centro de Recursos Computacionais – CERCOMP/UFG. -

SL150 Licensing Information User Manual
1[StorageTek] SL150 Modular Tape Library Licensing Information User Manual E72038-04 December 2018 StorageTek SL150 Modular Tape Library Licensing Information User Manual E72038-04 Copyright © 2016, 2018, Oracle and/or its affiliates. All rights reserved. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, delivered to U.S. Government end users are "commercial computer software" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, use, duplication, disclosure, modification, and adaptation of the programs, including any operating system, integrated software, any programs installed on the hardware, and/or documentation, shall be subject to license terms and license restrictions applicable to the programs.