URARE: Improvement of Thin Clients Hong-Wei XIE*, Guang OUYANG
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Is Shuma the Chinese Analog of Soma/Haoma? a Study of Early Contacts Between Indo-Iranians and Chinese
SINO-PLATONIC PAPERS Number 216 October, 2011 Is Shuma the Chinese Analog of Soma/Haoma? A Study of Early Contacts between Indo-Iranians and Chinese by ZHANG He Victor H. Mair, Editor Sino-Platonic Papers Department of East Asian Languages and Civilizations University of Pennsylvania Philadelphia, PA 19104-6305 USA [email protected] www.sino-platonic.org SINO-PLATONIC PAPERS FOUNDED 1986 Editor-in-Chief VICTOR H. MAIR Associate Editors PAULA ROBERTS MARK SWOFFORD ISSN 2157-9679 (print) 2157-9687 (online) SINO-PLATONIC PAPERS is an occasional series dedicated to making available to specialists and the interested public the results of research that, because of its unconventional or controversial nature, might otherwise go unpublished. The editor-in-chief actively encourages younger, not yet well established, scholars and independent authors to submit manuscripts for consideration. Contributions in any of the major scholarly languages of the world, including romanized modern standard Mandarin (MSM) and Japanese, are acceptable. In special circumstances, papers written in one of the Sinitic topolects (fangyan) may be considered for publication. Although the chief focus of Sino-Platonic Papers is on the intercultural relations of China with other peoples, challenging and creative studies on a wide variety of philological subjects will be entertained. This series is not the place for safe, sober, and stodgy presentations. Sino- Platonic Papers prefers lively work that, while taking reasonable risks to advance the field, capitalizes on brilliant new insights into the development of civilization. Submissions are regularly sent out to be refereed, and extensive editorial suggestions for revision may be offered. Sino-Platonic Papers emphasizes substance over form. -

Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation
Last Name First Name/Middle Name Course Award Course 2 Award 2 Graduation A/L Krishnan Thiinash Bachelor of Information Technology March 2015 A/L Selvaraju Theeban Raju Bachelor of Commerce January 2015 A/P Balan Durgarani Bachelor of Commerce with Distinction March 2015 A/P Rajaram Koushalya Priya Bachelor of Commerce March 2015 Hiba Mohsin Mohammed Master of Health Leadership and Aal-Yaseen Hussein Management July 2015 Aamer Muhammad Master of Quality Management September 2015 Abbas Hanaa Safy Seyam Master of Business Administration with Distinction March 2015 Abbasi Muhammad Hamza Master of International Business March 2015 Abdallah AlMustafa Hussein Saad Elsayed Bachelor of Commerce March 2015 Abdallah Asma Samir Lutfi Master of Strategic Marketing September 2015 Abdallah Moh'd Jawdat Abdel Rahman Master of International Business July 2015 AbdelAaty Mosa Amany Abdelkader Saad Master of Media and Communications with Distinction March 2015 Abdel-Karim Mervat Graduate Diploma in TESOL July 2015 Abdelmalik Mark Maher Abdelmesseh Bachelor of Commerce March 2015 Master of Strategic Human Resource Abdelrahman Abdo Mohammed Talat Abdelziz Management September 2015 Graduate Certificate in Health and Abdel-Sayed Mario Physical Education July 2015 Sherif Ahmed Fathy AbdRabou Abdelmohsen Master of Strategic Marketing September 2015 Abdul Hakeem Siti Fatimah Binte Bachelor of Science January 2015 Abdul Haq Shaddad Yousef Ibrahim Master of Strategic Marketing March 2015 Abdul Rahman Al Jabier Bachelor of Engineering Honours Class II, Division 1 -

Ideophones in Middle Chinese
KU LEUVEN FACULTY OF ARTS BLIJDE INKOMSTSTRAAT 21 BOX 3301 3000 LEUVEN, BELGIË ! Ideophones in Middle Chinese: A Typological Study of a Tang Dynasty Poetic Corpus Thomas'Van'Hoey' ' Presented(in(fulfilment(of(the(requirements(for(the(degree(of(( Master(of(Arts(in(Linguistics( ( Supervisor:(prof.(dr.(Jean=Christophe(Verstraete((promotor)( ( ( Academic(year(2014=2015 149(431(characters Abstract (English) Ideophones in Middle Chinese: A Typological Study of a Tang Dynasty Poetic Corpus Thomas Van Hoey This M.A. thesis investigates ideophones in Tang dynasty (618-907 AD) Middle Chinese (Sinitic, Sino- Tibetan) from a typological perspective. Ideophones are defined as a set of words that are phonologically and morphologically marked and depict some form of sensory image (Dingemanse 2011b). Middle Chinese has a large body of ideophones, whose domains range from the depiction of sound, movement, visual and other external senses to the depiction of internal senses (cf. Dingemanse 2012a). There is some work on modern variants of Sinitic languages (cf. Mok 2001; Bodomo 2006; de Sousa 2008; de Sousa 2011; Meng 2012; Wu 2014), but so far, there is no encompassing study of ideophones of a stage in the historical development of Sinitic languages. The purpose of this study is to develop a descriptive model for ideophones in Middle Chinese, which is compatible with what we know about them cross-linguistically. The main research question of this study is “what are the phonological, morphological, semantic and syntactic features of ideophones in Middle Chinese?” This question is studied in terms of three parameters, viz. the parameters of form, of meaning and of use. -

Biographical Sketch of Principal Investigator: Tongguang Zhai ——————————————————————————————————————— A
Biographical Sketch of Principal Investigator: Tongguang Zhai ——————————————————————————————————————— a. Professional Preparation. • 8/1/2000-8/14/2001 Postdoctoral Research Associate University of Kentucky conducting research work on continuous cast Al • 1/21/1995-4/30/2000 Research Fellow University of Oxford, England studying short fatigue crack initiation & propagation • 10/1/1994-12/31/1994 Postdoctoral Assistant Fraunhofer Institute for NDT, Germany ultrasonic NDT and acoustic microscopy of materials • 9/1991-9/1994 Ph.D. student D.Phil (Ph.D), 9/1996 Materials Science, University of Oxford, England • 9/1979-6/1983 Undergraduate B.Sc., 6/1983 Materials Physics, University of Science & Technology Beijing, China b. Appointments. 7/2007—present Associate Professor, Department of Chemical and Materials Engineering University of Kentucky, Lexington, KY 40506-0046, USA 8/2001—6/2007 Assistant Professor, Department of Chemical and Materials Engineering University of Kentucky, Lexington, KY 40506-0046, USA 9/1983—8/1986 Research Engineer, Welding Department Institute of Building and Construction Research, Beijing, China c. Publications (SCI indexed since 2017). 1) Pei Cai, Wei Wen, T. *Zhai (2018), A physics-based model validated experimentally for simulating short fatigue crack growth in 3-D in planar slip alloys, Mater. Sci. Eng. A, vol. 743, pp. 453-463. 2) R.J. Sun, L.H. Li, W. Guo, P. Peng, T. Zhai, Z.G. Che, B. Li, .C. Guo, Y. Zhu (2018), Laser shock peening induced fatigue crack retardation in Ti-17 titanium alloy, Mater. Sci. Eng. A, vol. 737, pp. 94- 104. 3) S.X. Jin, Tungwai Ngai, G.W. Zhangb, T. Zhai, S. Jia, L.J. -
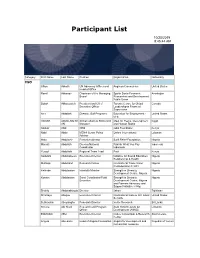
Participant List
Participant List 10/20/2019 8:45:44 AM Category First Name Last Name Position Organization Nationality CSO Jillian Abballe UN Advocacy Officer and Anglican Communion United States Head of Office Ramil Abbasov Chariman of the Managing Spektr Socio-Economic Azerbaijan Board Researches and Development Public Union Babak Abbaszadeh President and Chief Toronto Centre for Global Canada Executive Officer Leadership in Financial Supervision Amr Abdallah Director, Gulf Programs Educaiton for Employment - United States EFE HAGAR ABDELRAHM African affairs & SDGs Unit Maat for Peace, Development Egypt AN Manager and Human Rights Abukar Abdi CEO Juba Foundation Kenya Nabil Abdo MENA Senior Policy Oxfam International Lebanon Advisor Mala Abdulaziz Executive director Swift Relief Foundation Nigeria Maryati Abdullah Director/National Publish What You Pay Indonesia Coordinator Indonesia Yussuf Abdullahi Regional Team Lead Pact Kenya Abdulahi Abdulraheem Executive Director Initiative for Sound Education Nigeria Relationship & Health Muttaqa Abdulra'uf Research Fellow International Trade Union Nigeria Confederation (ITUC) Kehinde Abdulsalam Interfaith Minister Strength in Diversity Nigeria Development Centre, Nigeria Kassim Abdulsalam Zonal Coordinator/Field Strength in Diversity Nigeria Executive Development Centre, Nigeria and Farmers Advocacy and Support Initiative in Nig Shahlo Abdunabizoda Director Jahon Tajikistan Shontaye Abegaz Executive Director International Insitute for Human United States Security Subhashini Abeysinghe Research Director Verite -

Yanxi Pei Professor, Shanxi Unversity, China ORCID ID: 0000-0002-8428-3399
Yanxi Pei Professor, Shanxi Unversity, China ORCID ID: 0000-0002-8428-3399 PERSONAL INFORMATION Date of Birth: Feb. 20, 1970 Gender: male Place of Birth: Shanxi, China Nationality: P. R. China ADDRESS School of Life Science, Shanxi University Wucheng Road 92#, Taiyuan, Shanxi, 030006, China COMMUNICATION Tel: 86-351-701-8161 (O), 86-139-3455-9401 (cell phone) Email address: [email protected]; EDUCATION PhD. 9/1999-7/2002 Institute of biotechnology, Zhejiang University,China Master. 9/1993-7/1996 College of horticulture, Shanxi Agricultural University, China Bachelor. 9/1989-7/1993 College of horticulture, Shanxi Agricultural University, China EXPERIENCE Professor: Shanxi University, 2007, 9- Present Visiting scholar, Cardiovascular & Metabolic Research Unit, lakehead university, Canada;2009.12-2010.6 Postdoctoral Research Fellow: Institute of Genetics and Development Biology, Chinese Academy of Sciences, China, 2004, 12-2008, 3 Associate Professor: Shanxi University, 2004, 9-2007, 9 Lecturer Position: Shanxi University, 1999, 9-2004, 9 ONGOING PROFESSIONAL ACTIVITIES Vice Dean, School of Life Science, Shanxi University, 2008, 10- Present GRANTS (as project manager): 1 Mechnism of Ca2+ on gasotransmitter H2S to enhance the tolerance of heavy metal chromium(Cr6+) stress in Setaria italica,(National Natural Science Foundation of China (NSFC), 31671605), 2017.1-2020.12 2 The regulation and application of H2S in crucifer flowering (Research Project Supported by Shanxi Scholarship Council of China, 2016-008), 2016.6.15-2019.6.30 3 Project of Science and technology consulting in enterprise. Productivity Promotion Center of Taiyuan. 2015.8-2016.8 4 Development of new germplasm of controllable flower chrysanthemum and its supporting production technology (Scientific and technological project of Shanxi province, 20150311011-3), 2015.1-2017.12 5 The Influence of Protein Arginine Methylation on the Flowering Time Regulation by the Gasotransmitter H2S in Chinese Cabbage. -

Changes in Activities of Daily Living, Physical Fitness, And
ORIGINAL PAPER Nagoya J. Med. Sci. 71. 115 ~ 126, 2009 CHANGES IN ACTIVITIES OF DAILY LIVING, PHYSICAL FITNESS, AND DEPRESSIVE SYMPTOMS AFTER SIX-MONTH PERIODIC WELL-ROUNDED EXERCISE PROGRAMS FOR OLDER ADULTS LIVING IN NURSING HOMES OR SPECIAL NURSING FACILITIES PEI OUYANG, HIROSHI YATSUYA, HIDEAKI TOYOSHIMA, REI OTSUKA, KEIKO WADA, KUNIHIRO MATSUSHITA, MIYUKI ISHIKAWA, LI YUANYING, YO HOTTA, HIROTSUGU MITSUHASHI, TAKASHI MURAMATSU, NORIKATSU KASUGA and KOJI TAMAKOSHI Department of Public Health/Health Information Dynamics, Field of Social Life Science, Nagoya University Graduate School of Medicine ABSTRACT A 6-month, twice weekly, well-rounded exercise program (47 sessions in total) comprised of a combination of aerobic, resistance and flexibility training was provided for institutionalized older adults aged 60 to 93. We analyzed the data of 18 older adults who could stand and had attended more than 10% of the classes (mean participation rate: 54%) to examine changes in activities of daily living (ADL), physical fitness tests and depressive moods. The mean (± standard deviation, range) age of the participants was 71.3 (±15.6, 60–93) in men and 85.9 (±5.8, 72–93) in women. Significant improvement in ADL of the hand manipulation domain and borderline significant improvement in ADL of the mobility domain were observed (McNemar test p=0.011 and 0.072, respectively). A 6-minute walk distance increased significantly from 151.6 m to 236.6 m (p=0.01, paired t-test), and the result of the Soda Pop test, which tests hand-eye coordination, also improved significantly from 35.2 sec to 25.3 sec (p=0.01, paired t-test). -

Yazhou (Tim) Xie, Phd Assistant Professor, Mcgill University
Curriculum Vitae Yazhou (Tim) Xie January 2020 Yazhou (Tim) Xie, PhD Assistant Professor, McGill University Department of Civil Engineering and Applied Mechanics Macdonald Engineering Building, Room 483 817 Sherbrooke Street West, Montreal, Quebec H3A 0C3 Email:[email protected]; j Phone: 1-514-398-8681 Google Scholar j ResearchGate j Home Page EDUCATION Ph.D. Civil Engineering, University of California, Los Angeles 09/2012-03/2017 • Major: Structural Engineering; Minors: Geotechnical Engineering and Structural Mechanics • Dissertation: Seismic Modeling, Quantifying, and Protection of Highway Bridges Considering Shaking and Lateral Spreading • Advisor: Prof. Jian Zhang; Committee: Profs. Scott J. Brandenberg, Ertugrul Taciroglu, Christopher S. Lynch M.S. Bridge Engineering, Tongji University, China 09/2008-03/2011 • Thesis: Structural System Study of Long-span Arch Bridges • Advisor: Prof. Rucheng Xiao B.E. Civil Engineering, Tongji University, China 09/2004-07/2008 PROFESSIONAL EXPERIENCE Assistant Professor, McGill University 01/2020-present Assistant Professor of Structural Engineering at Department of Civil Engineering and Applied Mechanics. Postdoctoral Research Associate, Rice University 07/2017-12/2019 Postdoctoral Research Associate at Natural Hazards Mitigation Research Group under Prof. Reginald DesRoches. PhD Researcher, University of California, Los Angeles 09/2012-07/2017 Research and teaching assistant at the Department of Civil and Environmental Engineering. Technical Intern, Simpson Gumpertz & Heger 2015, 2016, 2017 Summer -

Origin Narratives: Reading and Reverence in Late-Ming China
Origin Narratives: Reading and Reverence in Late-Ming China Noga Ganany Submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the Graduate School of Arts and Sciences COLUMBIA UNIVERSITY 2018 © 2018 Noga Ganany All rights reserved ABSTRACT Origin Narratives: Reading and Reverence in Late Ming China Noga Ganany In this dissertation, I examine a genre of commercially-published, illustrated hagiographical books. Recounting the life stories of some of China’s most beloved cultural icons, from Confucius to Guanyin, I term these hagiographical books “origin narratives” (chushen zhuan 出身傳). Weaving a plethora of legends and ritual traditions into the new “vernacular” xiaoshuo format, origin narratives offered comprehensive portrayals of gods, sages, and immortals in narrative form, and were marketed to a general, lay readership. Their narratives were often accompanied by additional materials (or “paratexts”), such as worship manuals, advertisements for temples, and messages from the gods themselves, that reveal the intimate connection of these books to contemporaneous cultic reverence of their protagonists. The content and composition of origin narratives reflect the extensive range of possibilities of late-Ming xiaoshuo narrative writing, challenging our understanding of reading. I argue that origin narratives functioned as entertaining and informative encyclopedic sourcebooks that consolidated all knowledge about their protagonists, from their hagiographies to their ritual traditions. Origin narratives also alert us to the hagiographical substrate in late-imperial literature and religious practice, wherein widely-revered figures played multiple roles in the culture. The reverence of these cultural icons was constructed through the relationship between what I call the Three Ps: their personas (and life stories), the practices surrounding their lore, and the places associated with them (or “sacred geographies”). -

HÀNWÉN and TAIWANESE SUBJECTIVITIES: a GENEALOGY of LANGUAGE POLICIES in TAIWAN, 1895-1945 by Hsuan-Yi Huang a DISSERTATION S
HÀNWÉN AND TAIWANESE SUBJECTIVITIES: A GENEALOGY OF LANGUAGE POLICIES IN TAIWAN, 1895-1945 By Hsuan-Yi Huang A DISSERTATION Submitted to Michigan State University in partial fulfillment of the requirements for the degree of Curriculum, Teaching, and Educational Policy—Doctor of Philosophy 2013 ABSTRACT HÀNWÉN AND TAIWANESE SUBJECTIVITIES: A GENEALOGY OF LANGUAGE POLICIES IN TAIWAN, 1895-1945 By Hsuan-Yi Huang This historical dissertation is a pedagogical project. In a critical and genealogical approach, inspired by Foucault’s genealogy and effective history and the new culture history of Sol Cohen and Hayden White, I hope pedagogically to raise awareness of the effect of history on shaping who we are and how we think about our self. I conceptualize such an historical approach as effective history as pedagogy, in which the purpose of history is to critically generate the pedagogical effects of history. This dissertation is a genealogical analysis of Taiwanese subjectivities under Japanese rule. Foucault’s theory of subjectivity, constituted by the four parts, substance of subjectivity, mode of subjectification, regimen of subjective practice, and telos of subjectification, served as a conceptual basis for my analysis of Taiwanese practices of the self-formation of a subject. Focusing on language policies in three historical events: the New Culture Movement in the 1920s, the Taiwanese Xiāngtǔ Literature Movement in the early 1930s, and the Japanization Movement during Wartime in 1937-1945, I analyzed discourses circulating within each event, particularly the possibilities/impossibilities created and shaped by discourses for Taiwanese subjectification practices. I illustrate discursive and subjectification practices that further shaped particular Taiwanese subjectivities in a particular event. -

The Muslim Emperor of China: Everyday Politics in Colonial Xinjiang, 1877-1933
The Muslim Emperor of China: Everyday Politics in Colonial Xinjiang, 1877-1933 The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Schluessel, Eric T. 2016. The Muslim Emperor of China: Everyday Politics in Colonial Xinjiang, 1877-1933. Doctoral dissertation, Harvard University, Graduate School of Arts & Sciences. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33493602 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA The Muslim Emperor of China: Everyday Politics in Colonial Xinjiang, 1877-1933 A dissertation presented by Eric Tanner Schluessel to The Committee on History and East Asian Languages in partial fulfillment of the requirements for the degree of Doctor of Philosophy in the subject of History and East Asian Languages Harvard University Cambridge, Massachusetts April, 2016 © 2016 – Eric Schluessel All rights reserved. Dissertation Advisor: Mark C. Elliott Eric Tanner Schluessel The Muslim Emperor of China: Everyday Politics in Colonial Xinjiang, 1877-1933 Abstract This dissertation concerns the ways in which a Chinese civilizing project intervened powerfully in cultural and social change in the Muslim-majority region of Xinjiang from the 1870s through the 1930s. I demonstrate that the efforts of officials following an ideology of domination and transformation rooted in the Chinese Classics changed the ways that people associated with each other and defined themselves and how Muslims understood their place in history and in global space. -

Representing Talented Women in Eighteenth-Century Chinese Painting: Thirteen Female Disciples Seeking Instruction at the Lake Pavilion
REPRESENTING TALENTED WOMEN IN EIGHTEENTH-CENTURY CHINESE PAINTING: THIRTEEN FEMALE DISCIPLES SEEKING INSTRUCTION AT THE LAKE PAVILION By Copyright 2016 Janet C. Chen Submitted to the graduate degree program in Art History and the Graduate Faculty of the University of Kansas in partial fulfillment of the requirements for the degree of Doctor of Philosophy. ________________________________ Chairperson Marsha Haufler ________________________________ Amy McNair ________________________________ Sherry Fowler ________________________________ Jungsil Jenny Lee ________________________________ Keith McMahon Date Defended: May 13, 2016 The Dissertation Committee for Janet C. Chen certifies that this is the approved version of the following dissertation: REPRESENTING TALENTED WOMEN IN EIGHTEENTH-CENTURY CHINESE PAINTING: THIRTEEN FEMALE DISCIPLES SEEKING INSTRUCTION AT THE LAKE PAVILION ________________________________ Chairperson Marsha Haufler Date approved: May 13, 2016 ii Abstract As the first comprehensive art-historical study of the Qing poet Yuan Mei (1716–97) and the female intellectuals in his circle, this dissertation examines the depictions of these women in an eighteenth-century handscroll, Thirteen Female Disciples Seeking Instructions at the Lake Pavilion, related paintings, and the accompanying inscriptions. Created when an increasing number of women turned to the scholarly arts, in particular painting and poetry, these paintings documented the more receptive attitude of literati toward talented women and their support in the social and artistic lives of female intellectuals. These pictures show the women cultivating themselves through literati activities and poetic meditation in nature or gardens, common tropes in portraits of male scholars. The predominantly male patrons, painters, and colophon authors all took part in the formation of the women’s public identities as poets and artists; the first two determined the visual representations, and the third, through writings, confirmed and elaborated on the designated identities.