Le Linked Data À L'université: La Plateforme Linkedwiki
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Návrh a Implementace Rozšíření Do Systému Phabricator
Masarykova univerzita Fakulta informatiky Návrh a implementace rozšíření do systému Phabricator Diplomová práce Lukáš Jagoš Brno, podzim 2019 Masarykova univerzita Fakulta informatiky Návrh a implementace rozšíření do systému Phabricator Diplomová práce Lukáš Jagoš Brno, podzim 2019 Na tomto místě se v tištěné práci nachází oficiální podepsané zadání práce a prohlášení autora školního díla. Prohlášení Prohlašuji, že tato diplomová práce je mým původním autorským dílem, které jsem vypracoval samostatně. Všechny zdroje, prameny a literaturu, které jsem při vypracování používal nebo z nich čerpal, v práci řádně cituji s uvedením úplného odkazu na příslušný zdroj. Lukáš Jagoš Vedoucí práce: Martin Komenda i Poděkování Srdečně chci na tomto místě poděkovat vedoucímu mé diplomové práce RNDr. Martinu Komendovi, Ph.D. za cenné náměty a odborné vedení. Dále chci poděkovat Mgr. Matěji Karolyi za všestrannou po- moc při implementaci praktické části práce a Ing. Mgr. Janu Krejčímu za zpřístupnění testovacího serveru a technickou podporu. iii Shrnutí Diplomová práce se zabývá nástroji pro projektové řízení. V teore- tické části jsou vymezeny pojmy projekt a projektové řízení. Poté jsou představeny vybrané softwarové nástroje pro projektové řízení a je provedeno jejich srovnání. Pozornost je zaměřena na systém Phabrica- tor, který je v práci detailně popsán. V praktické části je navrženo rozšíření Phabricatoru na základě analýzy potřeb a sběru požadavků. Výsledkem je rozšířující modul po- skytující přehledné informace o úkolech z pohledu času a náročnosti, čímž zefektivní jejich plánování a proces týmové spolupráce. iv Klíčová slova projektové řízení, Phabricator, PHP, reportovací modul, SCRUM v Obsah 1 Projektové řízení 3 1.1 Projekt a projektové řízení ..................3 1.2 SW nástroje pro projektové řízení ...............4 1.3 Přehled nástrojů z oblasti řízení projektů ...........6 1.3.1 Phabricator . -

Easysitewizard Professional User Guide
User Guide Version 8.7 EasySiteWizard Professional 8.7 Chapter 1—2 Table of Contents 1 INTRODUCTION ..................................................................................................................... 1—3 2 NAVIGATING EASYSITEWIZARD .............................................................................................. 2—4 2.1 USING MENU TABS ....................................................................................................................................... 2—4 2.2 USING SUPPORTING LINKS .............................................................................................................................. 2—4 2.3 USING WIZARD NAVIGATION ........................................................................................................................... 2—4 3 CREATING A NEW SITE ........................................................................................................... 3—5 3.1 CREATING A LANDING PAGE SITE ...................................................................................................................... 3—5 3.1.1 Creating your Website ........................................................................................................................................... 3—5 3.1.2 Using the Site Editor .............................................................................................................................................. 3—7 3.1.3 Wizard Complete ................................................................................................................................................ -

Q1'21 FB Follow up Call Transcript
Facebook, Inc. (FB) First Quarter 2021 Follow Up Call April 28th, 2021 Operator: Good afternoon, my name is France, and I will be your conference operator today. At this time, I would like to welcome everyone to Facebook’s First Quarter Results Follow-Up Q&A Call. All lines have been placed on mute to prevent any background noise. To ask a question, please press “one” and then number “four” on your telephone keypad. This call is recorded. Thank you very much. Ms. Deborah Crawford, Facebook’s Vice President of Investor Relations, you may begin. Deborah Crawford: Thank you. Good afternoon, and welcome to the follow-up Q&A call. With me on today’s call is Dave Wehner CFO, and Susan Li VP of Finance. Before we get started, I would like to take this opportunity to remind you that our remarks today will include forward-looking statements. Actual results may differ materially from those contemplated by these forward- looking statements. Factors that could cause these results to differ materially are set forth in today’s press release and in our annual report on the form 10-K filed with the SEC. Any forward-looking statements that we make on this call are based on assumptions as of today and we undertake no obligation to update these statements as a result of new information or future events. During this call, we may present both GAAP and certain non-GAAP financial measures. The reconciliation of GAAP to non-GAAP measures is included in today’s earning’s press release. The press release and an accompanying investor presentation are available on our website at investor.fb.com. -

Jellyfish Merkle Tree
Jellyfish Merkle Tree Zhenhuan Gao, Yuxuan Hu, Qinfan Wu* Abstract. This paper presents Jellyfish Merkle Tree (JMT), a space-and-computation-efficient sparse Merkle tree optimized for Log-Structured Merge-tree (LSM-tree) based key-value storage, which is designed specially for the Diem Blockchain. JMT was inspired by Patricia Merkle Tree (PMT), a sparse Merkle tree structure that powers the widely known Ethereum network. JMT further makes quite a few optimizations in node key, node types and proof format to find the ideal balance between the complexity of data structure, storage, I/O overhead and computation efficiency, to cater to the needs of the Diem Blockchain. JMT has been implemented in Rust, but it is language- independent such that it could be implemented in other programming languages. Also, the JMT structure presented is of great flexibility in implementation details for fitting various practical use cases. 1 Introduction Merkle tree, since introduced by Ralph Merkle [1], has been a de facto solution to productionized account-model blockchain systems. Ethereum [2] and HyperLedger [3], are examples with various versions of Merkle trees. Although Merkle tree fits pretty well as an authenticated key-value store holding a huge amountof data in a tamper-proof way, its performance in terms of computation cost and storage footprint are two major concerns where people have been trying to achieve some enhancements. Among them, the sparseness of Merkle trees [2], [4], [5] has been aptly leveraged to cut off unnecessary complexity in more compact and efficient Merkle tree design. Virtually, a Merkle tree in reality has far fewer leaf nodes at the bottom level, a far cry from the intractable size that can be held by a perfect Merkle tree. -

Rodney's Take 8-23-21 FINAL Facebook Take Over World
Rodney’s Take August 23, 2021 Will Facebook Own the World? Months ago, I heard a DJ on the radio say that while he’s glad people love their kids and want them to have happy birthdays, he has no interest in reading gushy birthday wishes from parents to children, especially to infants and toddlers who have no idea what day it is. The DJ said that if you wouldn’t call to tell him something, don’t post it on Facebook (NYSE: FB). That makes sense to me, and it explains why I’m not a frequent user of the platform. I don’t care that much about the daily happenings in my own life, so sharing them with others seems out of place. I use Facebook to keep up with friends and family, but that’s about it. But that doesn’t mean I’m blind to the appeal. I understand enough about socialization to see how the connectivity, even if ephemeral, can be intoxicating and how Facebook specifically designs algorithms to draw us in and keep us there with things like nudges and photo posting alerts. It’s sort of creepy but definitely drives digital advertising and revenue and is what makes Facebook a money-printing machine. Now the company is preparing to launch a digital currency, Diem, which will be a stablecoin tied to basket of currencies. Central bankers and government regulators are right to be concerned. While around $70 billion worth of Tether, currently the big dog among stablecoins, trades hands every day, that’s just a drop in the bucket of the $5 trillion currency market and daily financial transactions around the world. -

Nfap Policy Brief » September 2 0 1 5
NATIONAL FOUNDATION FOR AMERICAN POLICY NFAP POLICY BRIEF » SEPTEMBER 2 0 1 5 THE WORLD HAS CHANGED SINCE 1990, U.S. IMMIGRATION POLICY HAS NOT BY STUART ANDERSON EXECUTIVE SUMMARY Changes in technology over the past 25 years have increased the demand for high-skilled labor in America at the same time U.S. limits on high-skilled immigration have remained stuck at levels set in 1990. Before the iPhone, the iPad, YouTube, Netflix, Amazon and Google, back when Mark Zuckerberg was still in kindergarten, Congress passed its last major piece of legislation on high-skill immigration. The 1990 Immigration Act set in law the 140,000 quota on employment-based green cards, the per country limits that restrict Indian and Chinese immigrants, the 65,000 numerical limit on H-1B visas, along with other measures that, with only minor modifications, have not changed in 25 years. In the meantime, fundamental changes in technology and commerce – the Internet becoming a part of daily life, for example – have greatly expanded the demand for skilled technical labor as America’s immigration laws have restricted access to much of that labor at levels established 25 years ago. Many of today’s major technologies and companies did not exist nor could have been imagined by lawmakers when Congress debated the 1990 Act. The research documents the enormous changes in the U.S. economy and technology since 1990 and contrasts that with the lack of change in America’s policies on employment-based immigration. Table 1 Technological Advances Since 1990 TECHNOLOGICAL ADVANCE 1990 2015 World Wide Web * Did not exist 3.2 billion users worldwide, integrated into operations of all major companies. -
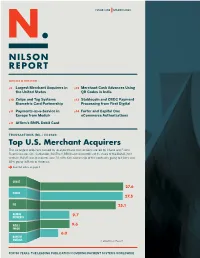
Top U.S. Merchant Acquirers the Six Largest Acquirers Ranked by Total Purchase Transactions Are Led by Chase and Fiserv
ISSUE 1193 MARCH 2021 ARTICLES IN THIS ISSUE p5 Largest Merchant Acquirers in p12 Merchant Cash Advances Using the United States QR Codes in India p10 Zwipe and Tag Systems p13 Stablecoin and CBDC Payment Biometric Card Partnership Processing from First Digital p11 Payments-as-a-Service in p14 Forter and Capital One Europe from Modulr eCommerce Authorizations p11 Affirm’s BNPL Debit Card TRANSACTIONS (BIL.) IN 2020 Top U.S. Merchant Acquirers The six largest acquirers ranked by total purchase transactions are led by Chase and Fiserv. Fiserv includes Citi, Santander, SunTrust, BBVA and six months of its share of the BAMS joint venture. BAMS was dissolved June 30, with 51% ownership of the contracts going to Fiserv and 49% going to Bank of America. Read full article on page 5 CHASE 27.6 FISERV 27.5 FIS 25.1 GLOBAL 9.7 PAYMENTS WELLS 9.6 FARGO 6.0 BANK OF AMERICA © 2021 Nilson Report FOR 50 YEARS, THE LEADING PUBLICATION COVERING PAYMENT SYSTEMS WORLDWIDE CONTENTS COVER STORY Top U.S. Merchant Acquirers Merchant Cash Advances The 63 largest acquirers of payment card transactions in the U.S. are ranked on Using QR Codes in India pages 6 and 7 based on their Mastercard and Visa volume handled in 2020. As an incentive for merchants to accept p5 payments via QR codes rather than cash, BharatPe will loan them up to $10,000. p12 Diem Networks U.S. is expected to Stablecoin and CBDC Payment Processing launch its private stablecoin-based from First Digital payment system by midyear. -

Practice Guide – Swiss M&A, July 2020
Reproduced with permission from Law Business Research Ltd. This content was first published in Lexology GTDT: Practice Guide – Swiss M&A, July 2020. For further information please visit https://www.lexology.com/gtdt/guides/swiss-m-and-a 1 SWISS M&A PRACTICE GUIDES PRACTICE GUIDE PRACTICE Swiss M&A First Edition Contributing Editors Ueli Studer, Kelsang Tsün and Sophie Stählin © Law Business Research 2020 Swiss M&A Practice Guide Contributing Editors Ueli Studer, Kelsang Tsün and Sophie Stählin Reproduced with permission from Law Business Research Ltd This article was first published in July 2020 For further information please contact [email protected] © Law Business Research 2020 Publisher Edward Costelloe [email protected] Subscriptions Claire Bagnall [email protected] Senior business development managers Adam Sargent [email protected] Dan Brennan [email protected] Published by Law Business Research Ltd Meridian House, 34-35 Farringdon Street London, EC4A 4HL, UK Tel: +44 20 7234 0606 Fax: +44 20 7234 0808 © Law Business Research Ltd 2020 No photocopying without a CLA licence. First published 2020 First edition ISBN 978-1-83862-427-9 The information provided in this publication is general and may not apply in a specific situation. Legal advice should always be sought before taking any legal action based on the information provided. This information is not intended to create, nor does receipt of it constitute, a lawyer–client relationship. The publishers and authors accept no responsibility for any acts or omissions contained herein. The information provided was verified between April and June 2020. Be advised that this is a developing area. -

Antitrust Implications of Progressive Decentralization in Blockchain Platforms
Washington and Lee Law Review Online Volume 77 Issue 2 Article 6 3-29-2021 A Tale of Two Regulators: Antitrust Implications of Progressive Decentralization in Blockchain Platforms Evan Miller Vinson & Elkins LLP, [email protected] Follow this and additional works at: https://scholarlycommons.law.wlu.edu/wlulr-online Part of the Antitrust and Trade Regulation Commons, Science and Technology Law Commons, and the Securities Law Commons Recommended Citation Evan Miller, A Tale of Two Regulators: Antitrust Implications of Progressive Decentralization in Blockchain Platforms, 77 WASH. & LEE L. REV. ONLINE 387 (2021), https://scholarlycommons.law.wlu.edu/wlulr-online/ vol77/iss2/6 This Development is brought to you for free and open access by the Law School Journals at Washington & Lee University School of Law Scholarly Commons. It has been accepted for inclusion in Washington and Lee Law Review Online by an authorized editor of Washington & Lee University School of Law Scholarly Commons. For more information, please contact [email protected]. A Tale of Two Regulators: Antitrust Implications of Progressive Decentralization in Blockchain Platforms Evan Miller* Abstract Competition regulators have identified the potential for blockchain technology to disrupt traditional sponsor-led platforms, like app stores, that have received increased antitrust scrutiny. Enforcement actions by securities regulators, however, have forced blockchain-based platforms to adopt a strategy of progressive decentralization, delaying decentralization objectives in favor of the centralized model that competition regulators hope they will disrupt. This regulatory tension, and the implications for blockchain’s procompetitive potential, have yet to be explored. This Article first identifies the origin of this tension and its consequences through a competition law lens, and then recommends that competition regulators account for this tension in monitoring the blockchain industry and strive to resolve it moving forward. -

Towards Left Duff S Mdbg Holt Winters Gai Incl Tax Drupal Fapi Icici
jimportneoneo_clienterrorentitynotfoundrelatedtonoeneo_j_sdn neo_j_traversalcyperneo_jclientpy_neo_neo_jneo_jphpgraphesrelsjshelltraverserwritebatchtransactioneventhandlerbatchinsertereverymangraphenedbgraphdatabaseserviceneo_j_communityjconfigurationjserverstartnodenotintransactionexceptionrest_graphdbneographytransactionfailureexceptionrelationshipentityneo_j_ogmsdnwrappingneoserverbootstrappergraphrepositoryneo_j_graphdbnodeentityembeddedgraphdatabaseneo_jtemplate neo_j_spatialcypher_neo_jneo_j_cyphercypher_querynoe_jcypherneo_jrestclientpy_neoallshortestpathscypher_querieslinkuriousneoclipseexecutionresultbatch_importerwebadmingraphdatabasetimetreegraphawarerelatedtoviacypherqueryrecorelationshiptypespringrestgraphdatabaseflockdbneomodelneo_j_rbshortpathpersistable withindistancegraphdbneo_jneo_j_webadminmiddle_ground_betweenanormcypher materialised handaling hinted finds_nothingbulbsbulbflowrexprorexster cayleygremlintitandborient_dbaurelius tinkerpoptitan_cassandratitan_graph_dbtitan_graphorientdbtitan rexter enough_ram arangotinkerpop_gremlinpyorientlinkset arangodb_graphfoxxodocumentarangodborientjssails_orientdborientgraphexectedbaasbox spark_javarddrddsunpersist asigned aql fetchplanoriento bsonobjectpyspark_rddrddmatrixfactorizationmodelresultiterablemlibpushdownlineage transforamtionspark_rddpairrddreducebykeymappartitionstakeorderedrowmatrixpair_rddblockmanagerlinearregressionwithsgddstreamsencouter fieldtypes spark_dataframejavarddgroupbykeyorg_apache_spark_rddlabeledpointdatabricksaggregatebykeyjavasparkcontextsaveastextfilejavapairdstreamcombinebykeysparkcontext_textfilejavadstreammappartitionswithindexupdatestatebykeyreducebykeyandwindowrepartitioning -

Framing on Facebook: Examining an Issues Management Approach to Obesity
Page 169 The Journal of Social Media in Society 5(2) Framing on Facebook: Examining an Issues Management Approach to Obesity Shereen Sarthou McCall, Sora Kim, & John Brummette Abstract This study utilized a quantitative content analysis to ex- amine how ten major food corporations are managing and framing the obesity issue on Facebook. Despite the poten- tial for communicating about issues with large numbers of active stakeholders on social media, corporations in our study are not maximizing their issues management efforts on this medium. This study reveals that the overall strat- egy used by these corporations involves providing individ- ual-focused information about living healthy lifestyles. Food corporations are taking a very positive and empower- Shereen Sarthou McCall is Associate Communication Manager at Raymond James Financial, Inc. Dr. Sora Kim is an associate professor at the School of Journalism and Communication, The Chinese University of Hong Kong, and Dr. John Brummette is an associate professor at the School of Communication at Rad- ford University. Correspondence can be directed to Dr. Kim at [email protected]. Page 170 ing approach to the issue by refraining from using the term “obesity” in their messages and frames, providing personalized information related to empowering a healthy lifestyle, and using the product nutrition frame, all of which were found to be the more effective tactics in gener- ating dialogue and positive reaction from stakeholders. besity is a prevalent health concern in the United States. Research conducted by the Centers for Disease Control and Prevention O indicates that adult obesity is common, with about one-third of all U.S. -

Client Description Project Description Key Results Carpe Diem Education
C A S E S T U D Y CLIENT: Client Description Carpe Diem Carpe Diem Education provides unique “gap year” opportunities for students ranging from new high school graduates to sophomores in college. Gap years are growing in Education popularity in the United States, and Carpe Diem Education stands out from other programs by focusing on growth and transformation through experiential education, community and intercultural exchange. 48 out of the top Project Description 50 Instagram In October of 2017, Carpe Diem Education approached A.wordsmith with the goal of posts for creating an official strategy for their social media platforms and leveraging their word-of- engagement in mouth-power. A.wordsmith created a 12 month plan targeting Carpe Diem Education’s the last 2 years three distinct audiences: students, parents, and educators. The strategy ties the were during our organization’s social channels to their larger marketing goals. Each month, A.wordsmith crafts a full content calendar, implements the content and works to build the community initial 12-month on the channels. campaign Key Results In the initial year long campaign: Facebook • 268% increase in engagement, exceeding our goal of a 10% increase (778 monthly engaged users in October 2017 to 2,867 in October 2018) • Followers grew 13% • 13.3% increase in organic impressions, exceeding our goal of a 10% increase (9957 in October 2017 to 11,283 in October 2018) Instagram • Followers grew 26% • We implemented a successful Instagram Stories initiative, featuring content directly from students and educators in the field: • Stories have an average completion rate of 74% • 48 out of the top 50 posts for engagement in the last 2 years were during our initial 12-month campaign Twitter • Twitter followers grew 18% • 140% increase in engagement, exceeding our goal of 10% (0.5% engagement rate in October 2017 to 1.2% engagement rate in October 2018) © 2017, A.wordsmith, Inc.