Web Usage Mining: Application to an Online Educational Digital Library Service
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Searching for Privacy: How to Protect Your Search Activity
Searching for Privacy: How to Protect Your Search Activity Abstract: This guide explains how to perform searches anonymously, protecting you from increasingly intrusive tracking and analysis by corporate and governmental organizations. Toll free: 866.760.0222 Toll free: 0808.101.2678 www.ioactive.com Copyright ©2010 by IOActive, Incorporated All Rights Reserved. Contents Understanding the Problem.................................................................................................................. 2 You are not Anonymous ....................................................................................................................... 2 A Solution ............................................................................................................................................. 3 Configuring your computer to perform anonymized searches.............................................................. 5 Conclusion.......................................................................................................................................... 16 References ......................................................................................................................................... 17 About IOActive.................................................................................................................................... 17 Confidential. Proprietary. Understanding the Problem If you have something that you don't want anyone to know, maybe you shouldn't be doing it in the first place. If you -

Exploring the Feasibility of Applying Data Mining for Library Reference Service Improvement a Case Study of Turku Main Library
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by National Library of Finland DSpace Services Ming Zhan ([email protected]) Exploring the Feasibility of Applying Data Mining for Library Reference Service Improvement A Case Study of Turku Main Library Master thesis in Information and Knowledge Management Master’s Programme Supervisors: Gunilla Widén Faculty of Social Sciences, Business and Economics Åbo Akademi University Åbo 2016 Abstract Data mining, as a heatedly discussed term, has been studied in various fields. Its possibilities in refining the decision-making process, realizing potential patterns and creating valuable knowledge have won attention of scholars and practitioners. However, there are less studies intending to combine data mining and libraries where data generation occurs all the time. Therefore, this thesis plans to fill such a gap. Meanwhile, potential opportunities created by data mining are explored to enhance one of the most important elements of libraries: reference service. In order to thoroughly demonstrate the feasibility and applicability of data mining, literature is reviewed to establish a critical understanding of data mining in libraries and attain the current status of library reference service. The result of the literature review indicates that free online data resources other than data generated on social media are rarely considered to be applied in current library data mining mandates. Therefore, the result of the literature review motivates the presented study to utilize online free resources. Furthermore, the natural match between data mining and libraries is established. The natural match is explained by emphasizing the data richness reality and considering data mining as one kind of knowledge, an easy choice for libraries, and a wise method to overcome reference service challenges. -

Paid Social Trends Iprospect QUARTERLY REPORT | 2017 Q4
Paid Social Trends iPROSPECT QUARTERLY REPORT | 2017 Q4 By Brittany Richter, VP, Head of Social Media and Katherine Patton, Director, Paid Social iProspect.com COPYRIGHT 2018 © iPROSPECT, INC. ALL RIGHTS RESERVED. iProspect Quarterly Report Paid Social Trends | 2017 Q4 2 Reviewing Overarching Q4 2017 Trends While the cost of inventory continues to rise, so does the value that brands see in paid social advertising. The brands that saw the strongest Q4 business performance were the ones that leveraged the Facebook pixel, optimized toward site engagement (Retail) or Reach (CPG, branding), took advantage of Dynamic Broad Audiences (DABA), and planned content designed for the feed. Based on iProspect client data, paid social continues to drive performance in its own right while also fueling our clients’ first-party data, which can be leveraged to drive cross-channel performance. The following trends and insights are based on analysis of the data from more than 210 brands managed by iProspect U.S. (though the spend is not confined to U.S. mar- kets). The spend data is representative of Facebook, Instagram, Pinterest, Snap, Inc., and Twitter, while performance data is specific to Facebook and Instagram only. SPEND Overall, iProspect’s paid social clients’ total Q4 social spend was up 72% quarter over quarter (QoQ) compared to Q3 2017, and 86% year over year (YoY) when compared to Q4 of 2016. Q4 is consistently the busiest time of the year for many of our clients, so it’s not unusual to see an increase spend as they strive to hit annual goals and capitalize on the holiday time period. -

Longitudinal Study of Links, Linkshorteners, and Bitly Usage on Twitter Longitudinella Mätningar Av Länkar, Länkförkortare Och Bitly An- Vänding På Twitter
Linköping University | Department of Computer and Information Science Bachelor’s thesis, 16 ECTS | Link Usage 2020 | LIU-IDA/LITH-EX-G--20/001--SE Longitudinal study of links, linkshorteners, and Bitly usage on Twitter Longitudinella mätningar av länkar, länkförkortare och Bitly an- vänding på Twitter Mathilda Moström Alexander Edberg Supervisor : Niklas Carlsson Examiner : Marcus Bendtsen Linköpings universitet SE–581 83 Linköping +46 13 28 10 00 , www.liu.se Upphovsrätt Detta dokument hålls tillgängligt på Internet - eller dess framtida ersättare - under 25 år från publicer- ingsdatum under förutsättning att inga extraordinära omständigheter uppstår. Tillgång till dokumentet innebär tillstånd för var och en att läsa, ladda ner, skriva ut enstaka ko- pior för enskilt bruk och att använda det oförändrat för ickekommersiell forskning och för undervis- ning. Överföring av upphovsrätten vid en senare tidpunkt kan inte upphäva detta tillstånd. All annan användning av dokumentet kräver upphovsmannens medgivande. För att garantera äktheten, säker- heten och tillgängligheten finns lösningar av teknisk och administrativ art. Upphovsmannens ideella rätt innefattar rätt att bli nämnd som upphovsman i den omfattning som god sed kräver vid användning av dokumentet på ovan beskrivna sätt samt skydd mot att dokumentet ändras eller presenteras i sådan form eller i sådant sammanhang som är kränkande för upphovsman- nens litterära eller konstnärliga anseende eller egenart. För ytterligare information om Linköping University Electronic Press se förlagets hemsida http://www.ep.liu.se/. Copyright The publishers will keep this document online on the Internet - or its possible replacement - for a period of 25 years starting from the date of publication barring exceptional circumstances. The online availability of the document implies permanent permission for anyone to read, to down- load, or to print out single copies for his/hers own use and to use it unchanged for non-commercial research and educational purpose. -
Webtrekk Documentation
Documentation Webtrekk GmbH | Robert-Koch-Platz 4 | 10115 Berlin Webtrekk Support | [email protected] Teaser Tracking Plugin (v2) Table of Contents 1 Disclaimer 3 1.1 Introduction 4 2 Technical Requirements 5 2.1 Browser Support 5 3 Creating Teaser Parameters 6 4 Configuring and Activating the Plugin 8 4.1 Tag Integration (Web) 8 4.2 JavaScript 10 5 Initializing the Teaser Elements 13 6 Best Practices 16 6.1 View Tracking with Dynamic Teaser Insertion 16 6.2 View Tracking 17 6.3 Customizing a Website Goal 18 6.4 Customizing the Engagement Page 18 12/13/2018 2/18 Teaser Tracking Plugin (v2) 1 Disclaimer This manual is the intellectual property of Webtrekk GmbH. This includes the contents but also all images, tables, and drawings. Change or removal of copyright notices, registering mark or control numbers are not allowed. Any use not permitted by German copyright law requires the prior written consent of the respective author or creator. This applies in particular to reproduction, editing, translation, storage, processing or distribution of contents in databases or other electronic media and systems. Webtrekk GmbH allows the use of the content solely for the contractual purpose. It should be noted that the contents of this manual may be subject to changes, without that a reporting obligation on the part of Webtrekk GmbH can be derived from this. Users of this manual must independently obtain information themselves, whether modified versions or notes to the contents are present, for example on the Internet at https://docs.webtrekk.com/, and take these into account during operation. -

D:\Documents and Settings\Ana\My Documents\Biserka-Knjiga\Digital
CULTURELINK Network of Networks for Research and Cooperation in Cultural Development was established by UNESCO and the Council of Europe in 1989. Focal point of the Network is the Institute for International Relations, Zagreb, Croatia. Members Networks, associations, foundations, institutions and individuals engaged in cultural development and cooperation. Aims of the Network To strengthen communication among its members; to collect, process and disseminate information on culture and cultural development in the world; to encourage joint research projects and cultural cooperation. Philosophy Promotion and support for dialogue, questioning and debating cultural practices and policies for cultural development. Mailing address CULTURELINK/IMO Ul. Lj. F. Vukotinovića 2 P.O. Box 303, 10000 Zagreb, Croatia Tel.: +385 1 48 77 460 Fax.: +385 1 48 28 361 E-mail: clink@ irmo.hr URL: http://www.culturelink.hr http://www.culturelink.org Download address http://www.culturelink.org/publics/joint/digital_culture-en.pdf DIGITALCULTURE: THECHANGINGDYNAMICS ThisWorkhasbeenpublishedwiththefinancialsupportoftheUNESCOOfficein Venice-UNESCORegionalBureauforScienceandCultureinEurope. UNESCO-BRESCE The designations employed and the presentation of the material throughout this publication do not imply the expressing of any opinion whatsoever on the part of the UNESCO Secretariat concerning the legal status of any country or territory, city or areaorofitsauthorities,thedelimitationsofitsfrontiersorboundaries. The authors are responsible for the choice and the presentation -
Overview Trackings
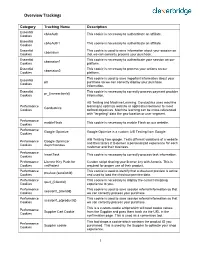
Overview Trackings Category Tracking Name Description Essential cbAcAuth This cookie is necessary to authenticate an affiliate. Cookies Essential cbAcAuth1 This cookie is necessary to authenticate an affiliate. Cookies Essential This cookie is used to save information about your session so cbsession Cookies that we can correctly process your purchase. Essential This cookie is necessary to authenticate your session on our cbsession1 Cookies platform. Essential This cookie is necessary to process your actions on our cbsession2 Cookies platform. This cookie is used to save important information about your Essential p0 purchase so we can correctly display your purchase Cookies information. Essential This cookie is necessary to correctly process payment provider pr_{transactionId} Cookies information. AB Testing and Machine Learning. Conductrics uses machine Performance learning to optimize website or application behavior to meet Conductrics Cookies defined objectives. Machine learning can be cross-referenced with "targeting" data like geo-location or user segment. Performance enableFlash This cookie is necessary to enable Flash on our website. Cookies Performance Google Optimize Google Optimize is a custom A/B Testing from Google. Cookies A/B Testing from google. Tests different variations of a website Performance Google Optimizer and then tailors it to deliver a personalized experience for each Cookies Asynchronous customer and their business. Performance InsertTask This cookie is necessary to correctly process task information. Cookies Performance License Key Push for Custom script sharing your license key with Acronis. This is Cookies vmProtect required for proper use of their product. Performance This cookie is used to identify that a checkout preview is active preview-{sessionId} Cookies and used to load the checkout preview data. -

A Self-Sustainable Peer-To-Peer Digital Library Framework for Evolving Communities Ashraf A
Old Dominion University ODU Digital Commons Computer Science Theses & Dissertations Computer Science Winter 2007 FreeLib: A Self-Sustainable Peer-to-Peer Digital Library Framework for Evolving Communities Ashraf A. Amrou Old Dominion University Follow this and additional works at: https://digitalcommons.odu.edu/computerscience_etds Part of the Computer Sciences Commons Recommended Citation Amrou, Ashraf A.. "FreeLib: A Self-Sustainable Peer-to-Peer Digital Library Framework for Evolving Communities" (2007). Doctor of Philosophy (PhD), dissertation, Computer Science, Old Dominion University, DOI: 10.25777/twrn-ya69 https://digitalcommons.odu.edu/computerscience_etds/96 This Dissertation is brought to you for free and open access by the Computer Science at ODU Digital Commons. It has been accepted for inclusion in Computer Science Theses & Dissertations by an authorized administrator of ODU Digital Commons. For more information, please contact [email protected]. FREELIB: A SELF-SUSTAINABLE PEER-TO-PEER DIGITAL LIBRARY FRAMEWORK FOR EVOLVING COMMUNITIES by Ashraf A. Amrou M.S. February 2001, Alexandria University B.S. June 1995, Alexandria University A Dissertation Submitted to the Faculty of Old Dominion University in Partial Fulfillment of the Requirement for the Degree of DOCTOR OF PHILOSOPHY COMPUTER SCIENCE OLD DOMINION UNIVERSITY December 2007 Approved by: Kurt Maly (Co-Director) Mohammad Zubair (Co-Director) rfussein Abdel-Wahab (Member) Ravi Mjjldcamala (Member) lamea (Member Reproduced with permission of the copyright owner. Further reproduction prohibited without permission. ABSTRACT FREELIB: A SELF-SUSTAINABLE PEER-TO-PEER DIGITAL LIBRARY FRAMEWORK FOR EVOLVING COMMUNITIES Ashraf Amrou Old Dominion University, 2007 Co-Directors of Advisory Committee: Dr. Kurt Maly Dr. Mohammad Zubair The need for efficient solutions to the problem of disseminating and sharing of data is growing. -

2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (Chair), Bobby Kleinberg September 14Th, 2020
2020 SIGACT REPORT SIGACT EC – Eric Allender, Shuchi Chawla, Nicole Immorlica, Samir Khuller (chair), Bobby Kleinberg September 14th, 2020 SIGACT Mission Statement: The primary mission of ACM SIGACT (Association for Computing Machinery Special Interest Group on Algorithms and Computation Theory) is to foster and promote the discovery and dissemination of high quality research in the domain of theoretical computer science. The field of theoretical computer science is the rigorous study of all computational phenomena - natural, artificial or man-made. This includes the diverse areas of algorithms, data structures, complexity theory, distributed computation, parallel computation, VLSI, machine learning, computational biology, computational geometry, information theory, cryptography, quantum computation, computational number theory and algebra, program semantics and verification, automata theory, and the study of randomness. Work in this field is often distinguished by its emphasis on mathematical technique and rigor. 1. Awards ▪ 2020 Gödel Prize: This was awarded to Robin A. Moser and Gábor Tardos for their paper “A constructive proof of the general Lovász Local Lemma”, Journal of the ACM, Vol 57 (2), 2010. The Lovász Local Lemma (LLL) is a fundamental tool of the probabilistic method. It enables one to show the existence of certain objects even though they occur with exponentially small probability. The original proof was not algorithmic, and subsequent algorithmic versions had significant losses in parameters. This paper provides a simple, powerful algorithmic paradigm that converts almost all known applications of the LLL into randomized algorithms matching the bounds of the existence proof. The paper further gives a derandomized algorithm, a parallel algorithm, and an extension to the “lopsided” LLL. -

Fordcommercialvehiclecenter.Com Privacy Statement
fordcommercialvehiclecenter.com Privacy Statement 1. General Statement: We respect your privacy and are committed to protecting it. This privacy statement explains our policies and practices regarding online customer information. It is through this disclosure that we intend to provide you with a level of comfort and confidence in how we collect, use, and safeguard personal and other information we collect or that you provide through this website, and how you can contact us if you have any questions or concerns. It is our sincere hope that by explaining our data handling practices we will develop a trusting and long-lasting relationship with you. By using the site, you agree to the terms of this privacy statement. 2. Information About Our Organization and Website and General Data Collection Practices: This Privacy Statement applies to www.fordcommercialvehiclecenter.com is administered by Marketing Associates, 777 Woodward Avenue, Detroit, MI 48226 on behalf of Ford Motor Company. The business purpose of this website is to provide Ford commercial business customers with an online Ford Commercial Vehicle Center dealer locator, and product and upfit incentive information. For added convenience, a select set of site features are accessible from web-enabled mobile devices as a mobile-optimized web experience. These site features may be limited in functionality. Online Tracking Information When you visit this site analytics providers may collect information about your online activity over time and across websites. Because there is not yet a common understanding of how to interpret web browser-based “Do Not Track” (“DNT”) signals other than cookies, Ford Motor Company does not currently respond to undefined “DNT” signals to its US websites. -

Creating and Managing a Digital Library
Creating and Managing a Digital Library 1 Agenda • Housekeeping items • Introduction of speakers – Laura Costello – Sharon Yang – Richard Jost • Questions 2 3 Creating and Managing a Digital Library Creating a digital library takes time, effort, and resources, but the tools are available, thanks to the popularity of the digital movement. In this panel discussion, three experts in the field of librarianship will share their views on the role of the librarian in providing tools and guidance to create and manage a digital library. 4 Introducing Our Panel A Climate of Demand: The shift from traditional print collections to the emergence of eBooks and demand-driven acquisitions Laura Costello, Head of Research & Emerging Technologies Stony Brook University Altmetrics and Research Support: Tips on using altmetrics to measure the impact of your digital library Sharon Q Yang, Professor and Systems Librarian Rider University Libraries, New Jersey Staffing the Library of the Future: The skills librarians need as the library transitions from a print to a more technical environment Richard Jost, Director of the Law Librarianship Program University of Washington Information School 5 ‘ A Climate of Demand 6 Hi! I’m Laura Head of Research & Emerging Technologies at Stony Brook‘ University [email protected] http://bit.ly/CostelloDDA 7 Evaluating Demand- Driven Acquisitions Chandos Publishing,‘ 2016 8 1. Context 2. Case Studies ‘ 3. New Research 4. What’s next? 9 ➔ What we talk about when we talk about monographs ◆ Serials ◆ Space ‘ ◆ Processing/Outsourcing -

Our Digital Library Brochure & User Guide
Using the app, borrowed titles appear on your shelf, where you have the option to: Branch Libraries Digital Library - Click Open Book and/or Open Audiobook & Other Services to begin reading or listening to a title. Collection - Click Manage Loan to see options like Renew, Return, or Aurora Memorial Library Send To Device to send a book to a Kindle device. 115 East Pioneer Trail Aurora, OH 44202 330-562-6502 To access your account for available information: - Loans- Your checked out titles will be listed Garrettsville Library along with their expiration dates. 10482 South Street - Holds- Any holds that you have on titles currently Garrettsville, OH 44231 checked out to other users. 330-527-4378 - Wish List- Any wish list titles that you would like to have saved for check out on a later date. Pierce Streetsboro Library 8990 Kirby Lane - Settings- Ability to change your settings to a 7 or 14-day Streetsboro, OH 44241 loan period, audience content filtering when browsing, 330-626-4458 Featuring and display options. Randolph Library Creativebug, Flipster, General Information 1639 State Route 44 Randolph, OH 44265 330-325-7003 Hoopla, Kanopy Windham Library & OverDrive Renaissance Family Center 9005 Wilverne Drive - Digital Movies, Documentaries & More To obtain operating requirements for any of these Windham, OH 44288 services, visit the Help and/or FAQ sections on the 330-326-3145 - TV Shows & Mysteries service's website. - Music Outreach Services- Home Delivery, - eBooks & Audiobooks Please note that using cellular data Library Express & The Library Box 10482 South Street - Magazines is generally not recommended for streaming Garrettsville, OH 44231 and/or downloading multimedia content.