Fuss, Futexes and Furwocks: Fast Userlevel Locking in Linux
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Filesystem Hierarchy Standard
Filesystem Hierarchy Standard LSB Workgroup, The Linux Foundation Filesystem Hierarchy Standard LSB Workgroup, The Linux Foundation Version 3.0 Publication date March 19, 2015 Copyright © 2015 The Linux Foundation Copyright © 1994-2004 Daniel Quinlan Copyright © 2001-2004 Paul 'Rusty' Russell Copyright © 2003-2004 Christopher Yeoh Abstract This standard consists of a set of requirements and guidelines for file and directory placement under UNIX-like operating systems. The guidelines are intended to support interoperability of applications, system administration tools, development tools, and scripts as well as greater uniformity of documentation for these systems. All trademarks and copyrights are owned by their owners, unless specifically noted otherwise. Use of a term in this document should not be regarded as affecting the validity of any trademark or service mark. Permission is granted to make and distribute verbatim copies of this standard provided the copyright and this permission notice are preserved on all copies. Permission is granted to copy and distribute modified versions of this standard under the conditions for verbatim copying, provided also that the title page is labeled as modified including a reference to the original standard, provided that information on retrieving the original standard is included, and provided that the entire resulting derived work is distributed under the terms of a permission notice identical to this one. Permission is granted to copy and distribute translations of this standard into another language, under the above conditions for modified versions, except that this permission notice may be stated in a translation approved by the copyright holder. Dedication This release is dedicated to the memory of Christopher Yeoh, a long-time friend and colleague, and one of the original editors of the FHS. -
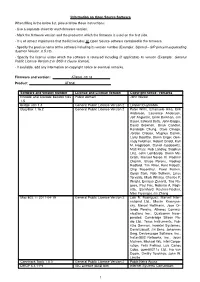
Information on Open Source Software When Filling in The
Information on Open Source Software When filling in the below list, please follow these instructions: - Use a separate sheet for each firmware version. - Mark the firmware version and the product in which the firmware is used on the first side. - It is of utmost importance that the list includes all Open Source software contained in the firmware. - Specify the precise name of the software including its version number (Example: Siproxd – SIP proxy/masquerading daemon Version: 0.5.10). - Specify the license under which the software is released including (if applicable) its version (Example: General Public License Version 2 or BSD-3 clause license). - If available, add any information on copyright notice or eventual remarks. Firmware and version: AT904L-03.18 Product: AT904L Software and version number License and License Version Copyright notice / remarks Encode and Decode base64 files Public domain John Walker 1.5 bridge-utils 1.4 General Public License Version 2 Lennert Buytenhek BusyBox 1.16.2 General Public License Version 2 Peter Willis, Emanuele Aina, Erik Andersen, Laurence Anderson, Jeff Angielski, Enrik Berkhan, Jim Bauer, Edward Betts, John Beppu, David Brownell, Brian Candler, Randolph Chung, Dave Cinege, Jordan Crouse, Magnus Damm, Larry Doolittle, Glenn Engel, Gen- nady Feldman, Robert Griebl, Karl M. Hegbloom, Daniel Jacobowitz, Matt Kraai, Rob Landley, Stephan Linz, John Lombardo, Glenn Mc- Grath, Manuel Novoa III, Vladimir Oleynik, Bruce Perens, Rodney Radford, Tim Riker, Kent Robotti, Chip Rosenthal, Pavel Roskin, Gyepi Sam, Rob Sullivan, Linus Torvalds, Mark Whitley, Charles P. Wright, Enrique Zanardi, Tito Ra- gusa, Paul Fox, Roberto A. Fogli- etta, Bernhard Reutner-Fischer, Mike Frysinger, Jie Zhang Mac 802.11 2011-04-19 General Public License Version 2 Luis R. -

(C) 1995 Microsoft Corporation. All Rights Reserved
(c) 1995 Microsoft Corporation. All rights reserved. Developed by ActiveWare Internet Corp., http://www.ActiveWare.com (C) 2000-2002 by the netfilter coreteam <[email protected]>: Paul 'Rusty' Russell <[email protected]> Marc Boucher <[email protected]> James Morris <[email protected]> Harald Welte <[email protected]> Jozsef Kadlecsik <[email protected]> (c) 2002-2008 Erik de Castro Lopo" ; src_get_version */ (c) 2003, 2004 Phil Blundell <[email protected]> (c) 2004 Mihnea Stoenescu, under the same license: (c) 2009-2013 Zoltan Herczeg All rights reserved. (C) 2016 Panasonic System Networks Co., Ltd. (c) allow anyone who receives a copy of the Modified Version to make the Source form of the Modified Version available to others under (c) allow anyone who receives a copy of the Modified Version to make the Source form of the Modified Version available to others under i) the Original License or ii) a license that permits the licensee to freely copy, modify and redistribute the Modified Version using the same licensing terms that apply to the copy that the licensee received, and requires that the Source form of the Modified Version, and of any works derived from it, be made freely available in that license fees are prohibited but Distributor Fees are allowed. Distribution of Compiled Forms of the Standard Version or Modified Versions without the Source (c) any litigation relating to this Agreement shall be subject to the jurisdiction of the Federal Courts of the Northern District of California, with venue lying in Santa Clara County, California, with the losing party responsible for costs, including without limitation, court costs and reasonable attorneys fees and expenses. -

Fault Injection Test Harness a Tool for Validating Driver Robustness
Fault Injection Test Harness a tool for validating driver robustness Louis Zhuang Stanley Wang Intel Corp. Intel Corp. [email protected], [email protected] [email protected] Kevin Gao Intel Corp. [email protected] Abstract 1 Introduction FITH (Fault Injection Test Harness) is a tool High-availability (HA) systems must respond for validating driver robustness. Without gracefully to fault conditions and remain oper- changing existing code, it can intercept arbi- ational during unexpected software and hard- trary MMIO/PIO access and IRQ handler in ware failures. Each layer of the software stack driver. of a HA system must be fault tolerant, produc- ing acceptable output or results when encoun- Firstly I’ll first list the requirements and design tering system, software or hardware faults, in- for Fault Injection. Next, we discuss a cou- cluding faults that theoretically should not oc- ple of new generally useful implementation in cur. An empirical study [2] shows that 60- FITH 70% of kernel space defects can be attributed to device driver software. Some defect con- 1. KMMIO - the ability to dynamically hook ditions (such as hardware failure, system re- into arbitrary MMIO operations. source shortages, and so forth) seldom hap- pen, however, it is difficult to simulate and reproduce without special assistant hardware, 2. KIRQ - the ability to hook into an arbi- such as an In-Circuit Emulator. In these situa- trary IRQ handler, tions, it is difficult to predict what would hap- pen should such a fault occur at some time in the future. Consequently, device drivers that Then I’ll demonstrate how the FITH can help are highly available or hardened are designed developers to trace and identify tricky issues to minimize the impact of failures to a system’s in their driver. -

Université De Montréal Low-Impact Operating
UNIVERSITE´ DE MONTREAL´ LOW-IMPACT OPERATING SYSTEM TRACING MATHIEU DESNOYERS DEPARTEMENT´ DE GENIE´ INFORMATIQUE ET GENIE´ LOGICIEL ECOLE´ POLYTECHNIQUE DE MONTREAL´ THESE` PRESENT´ EE´ EN VUE DE L’OBTENTION DU DIPLOMEˆ DE PHILOSOPHIÆ DOCTOR (Ph.D.) (GENIE´ INFORMATIQUE) DECEMBRE´ 2009 c Mathieu Desnoyers, 2009. UNIVERSITE´ DE MONTREAL´ ECOL´ E POLYTECHNIQUE DE MONTREAL´ Cette th`ese intitul´ee : LOW-IMPACT OPERATING SYSTEM TRACING pr´esent´ee par : DESNOYERS Mathieu en vue de l’obtention du diplˆome de : Philosophiæ Doctor a ´et´edˆument accept´ee par le jury constitu´ede : Mme. BOUCHENEB Hanifa, Doctorat, pr´esidente M. DAGENAIS Michel, Ph.D., membre et directeur de recherche M. BOYER Fran¸cois-Raymond, Ph.D., membre M. STUMM Michael, Ph.D., membre iii I dedicate this thesis to my family, to my friends, who help me keeping balance between the joy of sharing my work, my quest for knowledge and life. Je d´edie cette th`ese `ama famille, `ames amis, qui m’aident `aconserver l’´equilibre entre la joie de partager mon travail, ma quˆete de connaissance et la vie. iv Acknowledgements I would like to thank Michel Dagenais, my advisor, for believing in my poten- tial and letting me explore the field of operating systems since the beginning of my undergraduate studies. I would also like to thank my mentors, Robert Wisniewski from IBM Research and Martin Bligh, from Google, who have been guiding me through the internships I have done in the industry. I keep a good memory of these experiences and am honored to have worked with them. A special thanks to Paul E. -

Linux IPCHAINS-HOWTO
Linux IPCHAINS−HOWTO Linux IPCHAINS−HOWTO Table of Contents Linux IPCHAINS−HOWTO..............................................................................................................................1 Rusty Russell...........................................................................................................................................1 1.Introduction...........................................................................................................................................1 2.Packet Filtering Basics..........................................................................................................................1 3.I'm confused! Routing, masquerading, portforwarding, ipautofw.......................................................1 4.IP Firewalling Chains...........................................................................................................................1 5.Miscellaneous.......................................................................................................................................2 6.Common Problems...............................................................................................................................2 7.A Serious Example...............................................................................................................................2 8.Appendix: Differences between ipchains and ipfwadm.......................................................................2 9.Appendix: Using the ipfwadm−wrapper script.....................................................................................3 -

Unreliable Guide to Locking
Unreliable Guide To Locking Paul Rusty Russell [email protected] Unreliable Guide To Locking by Paul Rusty Russell Copyright © 2000 by Paul Russell This documentation is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 2 of the License, or (at your option) any later version. This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details. You should have received a copy of the GNU General Public License along with this program; if not, write to the Free Software Foundation, Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA For more details see the file COPYING in the source distribution of Linux. Table of Contents 1. Introduction............................................................................................................................................5 The Problem With Concurrency ........................................................................................................5 2. Two Main Types of Kernel Locks: Spinlocks and Semaphores.........................................................7 Locks and Uniprocessor Kernels .......................................................................................................7 Read/Write Lock Variants..................................................................................................................7 -

Virtio PCI Card Specification V0.9.5 DRAFT
Virtio PCI Card Specication v0.9.5 DRAFT - Rusty Russell <[email protected]> IBM Corporation (Editor) 2012 May 7. Chapter 1 Purpose and Description This document describes the specications of the virtio family of PCI de- vices. These are devices are found in virtual environments, yet by design they are not all that dierent from physical PCI devices, and this document treats them as such. This allows the guest to use standard PCI drivers and discovery mechanisms. The purpose of virtio and this specication is that virtual environments and guests should have a straightforward, ecient, standard and extensible mecha- nism for virtual devices, rather than boutique per-environment or per-OS mech- anisms. Straightforward: Virtio PCI devices use normal PCI mechanisms of inter- rupts and DMA which should be familiar to any device driver author. There is no exotic page-ipping or COW mechanism: it's just a PCI de- vice.1 Ecient: Virtio PCI devices consist of rings of descriptors for input and out- put, which are neatly separated to avoid cache eects from both guest and device writing to the same cache lines. Standard: Virtio PCI makes no assumptions about the environment in which it operates, beyond supporting PCI. In fact the virtio devices specied in the appendices do not require PCI at all: they have been implemented on non-PCI buses.2 1This lack of page-sharing implies that the implementation of the device (e.g. the hyper- visor or host) needs full access to the guest memory. Communication with untrusted parties (i.e. inter-guest communication) requires copying. -

Open Source Software License Information
Open Source Software license information This document contains an open source software license information for the product VACUU·SELECT. The product VACUU·SELECT contains open source components which are licensed under the applicable open source licenses. The applicable open source licenses are listed below. The open source software licenses are granted by the respective right holders directly. The open source licenses prevail all other license information with regard to the respective open source software components contained in the product. Modifications of our programs which are linked to LGPL libraries are permitted for the customer's own use and reverse engineering for debugging such modifications. However, forwarding the information acquired during reverse engineering or debugging to third parties is prohibited. Furthermore, it is prohibited to distribute modified versions of our programs. In any case, the warranty for the product VACUU·SELECT will expire, as long as the customer cannot prove that the defect would also occur without these modification. WARRANTY DISCLAIMER THE OPEN SOURCE SOFTWARE IN THIS PRODUCT IS DISTRIBUTED IN THE HOPE THAT IT WILL BE USEFUL, BUT WITHOUT ANY WARRANTY, WITHOUT EVEN THE IMPLIED WARRANTY OF MERCHANTABILITY OR FITNESS FOR A PARTICULAR PURPOSE. See the applicable licenses for more details. Written offer This product VACUU·SELECT contains software components that are licensed by the holder of the rights as free software, or Open Source software, under GNU General Public License, Versions 2 and 3, or GNU Lesser General Public License, Versions 2.1, or GNU Library General Public License, Version 2, respectively. The source code for these software components can be obtained from us on a data carrier (e.g. -

Rusty's Unreliable Guide to Kernel Hacking
Rusty’s Unreliable Guide To Kernel Hacking Paul ‘Rusty’ Russell IBM Copyright (c) 2002 Paul ‘Rusty’ Russell, IBM. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.1 or any later version published by the Free Software Foundation; with no Invariant Sections being LIST THEIR TITLES, with no Front-Cover Texts, and with no Back-Cover Texts. Revision History Revision 1 Tue Aug 27 2002 The Linux Kernel contains 5 million lines of source. It is difficult to know where to start, when you want to modify it in some way. This tutorial will cover various kernel programming conceps in depth: you will gain an appreciation for the Linux kernel by reading some of the code some of the great programmers, including of Linus Torvalds and Ingo Molnar, and an insight into Linux kernel development methods and politics (this is a preliminary version, the final version for the Congress may still suffer some changes. The Editors). Table of Contents 1. Target Audience ............................................................................... 2 2. Principles ..................................................................................... 2 2.1. The Kernel Tree ........................................................................ 2 2.2. Overview .............................................................................. 3 2.3. Fundamental Constraints ................................................................ 3 2.4. The Three Kernel Entry Points .......................................................... -

Linux Advanced Routing & Traffic Control HOWTO
Linux Advanced Routing & Traffic Control HOWTO Bert Hubert Netherlabs BV <[email protected]> Gregory Maxwell <[email protected]> Remco van Mook <[email protected]> Martijn van Oosterhout <[email protected]> Paul B Schroeder <[email protected]> Jasper Spaans <[email protected]> Revision History Revision 1.1 2002−07−22 DocBook Edition A very hands−on approach to iproute2, traffic shaping and a bit of netfilter. Linux Advanced Routing & Traffic Control HOWTO Table of Contents Chapter 1. Dedication.........................................................................................................................................1 Chapter 2. Introduction......................................................................................................................................2 2.1. Disclaimer & License.......................................................................................................................2 2.2. Prior knowledge................................................................................................................................2 2.3. What Linux can do for you...............................................................................................................3 2.4. Housekeeping notes..........................................................................................................................3 2.5. Access, CVS & submitting updates..................................................................................................3 2.6. Mailing list........................................................................................................................................4 -

Buried Alive in Patches: 6 Months of Picking up the Pieces of the Linux 2.5 Kernel
Buried alive in patches: 6 months of picking up the pieces of the Linux 2.5 kernel Dave Jones SuSE Labs [email protected], http://www.codemonkey.org.uk Abstract would then push known good parts to Linus at such a time that he is ready for them. When development began on the 2.5 Linux ker- When the 2.4 kernel diverged to the 2.5 devel- nel, I volunteered to forward port 2.4 fixes to opment branch, there was still a considerable 2.5, and keep them in sync ready for when Li- number of fixes going into 2.4. Alan was busy nus was ready to accept them. Additionally, I with other projects at the time, and so it was collected the small bits Linus frequently over- suggested that ‘someone’ should pick up the looked, and perhaps more importantly, tried to bits going into 2.4 and make sure they don’t keep the 2.5-dj tree in a usable, bootable state get left behind for 2.5. even when 2.5 mainline wasn’t. Without fully thinking through the conse- quences, I decided to step forward, and got a 1 Introduction lot more than I bargained for, but learned a lot, and had a lot of fun on the way. With the advent of a new development series of the Linux kernel, Linus Torvalds typically 2 The problems hands off the current tree to someone else, who becomes maintainer of that stable series, and The easy part of the job looks something like work on the development branch accelerates, this: whilst the stable branch collects fixes and up- dates rather than new features.