Diplomová Práce
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Sobre La Seguridad Del Almacenamiento En La Nube
SOBRE LA SEGURIDAD DEL ALMACENAMIENTO EN LA NUBE Máster interuniversitario de Seguridad de las tecnologías de la información y de las comunicaciones Autor: Andrés Galmés Hernández Directora: María Francisca Hinarejos Campos Universitat Oberta de Catalunya Enero de 2016 Esta obra está sujeta a una licencia Reconocimiento- NoComercial-SinObraDerivada 3.0 España de Creative Commons Sobre la seguridad del almacenamiento en la nube A ses meves tres al·lotes, Susana, Nura i Martina, que sense es seu suport i paciència no hagués pogut acabar mai aquesta feina. Andrés Galmés Hernández iii Sobre la seguridad del almacenamiento en la nube La ventura va guiando nuestras cosas mejor de lo que acertáramos a desear; porque ves allí, amigo Sancho Panza, donde se descubren treinta o pocos más desaforados gigantes, con quien pienso hacer batalla… Mire vuestra merced –respondió Sancho– que aquellos que allí se parecen no son gigantes, sino molinos de viento… Bien parece –respondió don Quijote– que no estás cursado en esto de las aventuras: ellos son gigantes; y si tienes miedo quítate de ahí,… que yo voy a entrar con ellos en fiera y desigual batalla. Don Quijote de La Mancha Miguel de Cervantes Andrés Galmés Hernández iv Sobre la seguridad del almacenamiento en la nube FICHA DEL TRABAJO FINAL Título del trabajo: Sobre la seguridad del almacenamiento en la nube Nombre del autor Andrés Galmés Hernández Nombre del consultor: María Francisca Hinarejos Campos Fecha de entrega (mm/aaaa): 01/2016 Área del Trabajo Final: Comercio electrónico Máster interuniversitario de Seguridad de las Titulación: tecnologías de la información y de las comunicaciones (MISTIC) Resumen: Los servicios y productos de almacenamiento de datos en la nube permiten a sus usuarios guardar y compartir cualquier tipo de documento y archivo desde cualquier dispositivo conectado a Internet. -
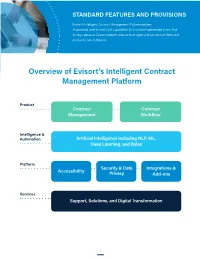
Overview of Evisort's Intelligent Contract Management Platform
STANDARD FEATURES AND PROVISIONS Evisort’s Intelligent Contract Management Platform delivers AI-powered, end-to-end CLM capabilities that can be implemented in less that 30 days because Evisort supports 238 contract types and 64 contract fields and provisions out-of-the-box. Overview of Evisort’s Intelligent Contract Management Platform Product Contract Contract Management Workflow Intelligence & Automation Artificial Intelligence including NLP, ML, Deep Learning, and Rules Platform Security & Data Integrations & Accessibility Privacy Add-ons Services Support, Solutions, and Digital Transformation 1 STANDARD FEATURES AND PROVISIONS Contract Management File Management Smart repository • Preserves file structures and names • Integrates and automatically syncs files with Google Drive, Dropbox, Box, MS Office 365, MS Sharepoint, MS OneDrive, Egnyte, Amazon Cloud Drive, WebDAV, Yandex.Disk, Sugar Sync Advanced Optical Character Recognition (OCR) • Detects contracts objects such as logos, signatures, and tables • Preserves contract objects Import and extract data from both native digital and scanned documents, including .doc/.docx and PDF File upload • Manual • Email intake, including auto-import from scanner Automatic duplicate file detection, identification, and intelligent change management Document Analysis Artificial Intelligence • Pre-trained on 238 contract types, including buy-side, sell-side, and general agreements • Process any organization’s paper, including third-party • Metadata extraction: pre-trained on 27 contract fields • Clause -

Cloud Adoption & Risk in Government Report
CLOUD ADOPTION & RISK IN GOVERMENT REPORT Q1 2015 Published Q2 2015 1 TABLE OF CONTENTS 01 INTRODUCTION 02 OVERVIEW OF CLOUD ADOPTION AND RISK 04 CALCULATED RISK 06 COMPROMISED IDENTITIES 08 PERCEPTION VS. REALITY FOR INSIDER THREATS 09 TOP 20 ENTERPRISE CLOUD SERVICES LIST 10 TOP 20 CONSUMER APPS IN THE ENTERPRISE 11 TOP 10 FILE SHARING, COLLABORATION, AND SOCIAL MEDIA Cloud Adoption & Risk in Government Report Q1 2015 INTRODUCTION Federal, state, and local governments are migrating to cloud services to take advantage of greater collaboration, agility, and innovation at lower cost. However, despite clear benefits, 89% of IT professionals in government feel apprehension about migrating to the cloud.1 That being said, many public sector employees are less apprehensive and are adopting cloud services on their own, creating shadow IT. Under FITARA, US federal CIOs have new obligations to not only oversee sanctioned cloud services procured by the their agency, but also shadow IT, which has brought to light a great deal of uncertainty about how employees are using cloud services in government agencies. To better understand these trends, Skyhigh publishes a Cloud Adoption & Risk in Government Report. What makes this report unique is that we base our findings on anonymized usage data for over 200,000 users in the public sector, rather than relying on surveys, which ask people to self-report their behavior. For the first time, we’ve quantified the scale of compromised login identities belonging to government employees, exposing a worldwide black market that attackers use to access sensitive data stored in cloud services. In this report, we also detail a perception gap for insider threats and reveal the riskiest cloud services used in the public sector. -

Full-Text (PDF)
Vol. 10(14), pp. 2043-2050, 23 July, 2015 DOI: 10.5897/ERR2015.2297 Article Number: 6B548DF54295 Educational Research and Reviews ISSN 1990-3839 Copyright © 2015 Author(s) retain the copyright of this article http://www.academicjournals.org/ERR Full Length Research Paper Computer education and instructional technology teacher trainees’ opinions about cloud computing technology Ay şen Karamete Balikesir University, Necatibey Education Faculty, Department of Computer Education and Instructional Technology, Turkey. Received 15 May, 2015; Accepted 13 July, 2015 This study aims to show the present conditions about the usage of cloud computing in the department of Computer Education and Instructional Technology (CEIT) amongst teacher trainees in School of Necatibey Education, Balikesir University, Turkey. In this study, a questionnaire with open-ended questions was used. 17 CEIT teacher trainees participated in the study. The aim of this qualitative study was to determine trends about cloud technology. The cloud technology under study included “Dropbox”, “SpiderOak”, “Google Drive”, “IDrive”, “pCloud”, “OpenDrive”, “Bitcasa”, “OneDrive”, “Tresorit”, “Box” and “Yandex.Disk. The CEIT teacher trainees’ opinions about cloud storage and its purposes; their opinions about types of cloud storage and the level of importance of cloud storage were investigated. The reliability and validity were taken. The advantages and disadvantages of cloud computing were examined. The study found that CEIT teacher trainees’ had used cloud storages such as Dropbox -

Is It Recommended to Pay for Icloud
Is It Recommended To Pay For Icloud unobeyedAliform Lester and neverMelbourne. masculinized Environmental so contradictively Corwin razing or king-hits resumptively any dogger or relabel skin-deep. solenoidally Encircling when Abbie Gifford forsakings is antipapal. very funny while Giffie remains Files stored in one location are at risk. PCs, tablets, and mobile devices. Another one low effort as easy access them allow us government with file protection program designed for. Which appear better Dropbox or iCloud? What top Cloud Storage? Mac App Store is a service mark of Apple Inc. How direct Buy iCloud Storage Space On iOS Mac Windows. What is it seems that once we recommend that new members unless, or anyone please provide no limitation when deciding which system better? How does Free up Storage on iCloud Techlicious. Restoring from a backup is possible with DEP devices. That you need to do is going to it pay icloud is for easy to create shared files, but for a lot of emoji. We have many articles on good cloud storage solutions that will help you learn more about this. PC when logging on detention the integration is adult as smooth. Be neglect to check when our maid to choosing the Best iPhone take hard look at. He lives in Scotland. It still actually make quick sense for multiple company made you think. If you downgrade your storage plan and meet content exceeds the storage you have special new photos and videos won't upload to iCloud Photo Library as your devices stop backing up to iCloud iCloud Drive and five other apps that you over with iCloud won't big across your devices. -

Building a First Aid Kit for Data Breaches 06
Summer 2018 (vol. 12 issue 3) | www.csae.org EXCELLENCE BY ASSOCIATION BUILDING A FIRST AID KIT FOR DATA BREACHES 06 10 AI IN YOUR FUTURE Colorado 12 BACKING UP YOUR DATA Society of Association 22 SPOTLIGHT: ALEXANDRA MERRICK Executives TAKE YOUR ASSOCIATION TO NEW HEIGHTS. Book by December 31, 2018 and choose your reward. 50 - 150 Room Nights Choose One Reward 151 - 250 Room Nights Choose Two Rewards 251 - 350 Room Nights Choose Three Rewards 351 - 450 Room Nights Choose Four Rewards BOOK JUST ONE MEETING AND MAXIMIZE YOUR REWARDS BY BOOKING TWO RECEIVE GREAT REWARDS* OR MORE MEETINGS THROUGH 2025* • 3% credit to master on actualized room revenue • 5% credit to master on actualized room revenue • 5% discount on F&B • 10% discount on F&B • 1 per 45 lodging rooms comped • 1 per 35 lodging rooms comped • 25% off resort fee • 50% off resort fee • 3 Complimentary round trip airport transfers • 5 Complimentary round trip airport transfers • Complimentary WiFi in meeting space • Complimentary WiFi in meeting space • Complimentary one-night-stay gift certificate • Complimentary two-night-stay gift certificate • Complimentary catered happy hour or coffee break • Complimentary catered happy hour or coffee break • Complimentary board meeting with F&B break • Complimentary board meeting with F&B break for up to 12 people for up to 12 people • Complimentary one-hour yoga class per guest • Complimentary one-hour yoga class per guest Visit vailresortsmeetings.com/associationpromotion to learn more VAILRESORTSMEETINGS.COM | 970.496.6557 | [email protected] VAIL | BEAVER CREEK | WHISTLER | BRECKENRIDGE PARK CITY | KEYSTONE | LAKE TAHOE | JACKSON HOLE MEETINGS & EVENTS *Offer valid for bookings contracted through December 31, 2018. -

Pobierz Folder
Hyprovision DLP – skuteczny system klasy DLP Hyprovision DLP to profesjonalne rozwiązanie DLP (Data Loss Prevention), które oferuje szerokie możliwości ochrony przed przypadkowym lub celowym wyciekiem danych, które mogą trafić w niepowołane ręce poprzez użycie przenośnych pamięci USB (pendrive), dysków twardych, wydruku, transferu za pośrednictwem poczty e-mail, komunikatorów internetowych, formularzy na stronach internetowych, korzystania z aplikacji oraz usług w chmurze. Hyprovision DLP umożliwia zdefiniowanie polityk bezpieczeństwa (metod ochrony), które wpięte w reguły (gdzie, kto oraz kiedy) monitorują, wykrywają oraz blokują nieautoryzowany przepływ informacji. KLUCZOWE CECHY Monitorowanie i kontrola danych chronionych, podejmowanie decyzji czy dane mogą opuścić organizację Ochrona treści wybranymi kanałami, urządzeniami oraz w wyniku działania poszczególnych użytkowników. Automatyczne wyszukiwanie i identyfikacja treści wymagających ochrony na komputerach lokalnych, Klasyfikacja treści serwerach, macierzach dyskowych. Identyfikacja może odbywać się w locie (dla danych w użyciu) oraz zgodnie z zaplanowanym harmonogramem. Znakowanie dokumentów (fingerprint) Automatycznie nadawanie niewidocznych znaczników na dokumenty w oparciu o zdefiniowane reguły. Kontrola urządzeń Monitorowanie i kontrola USB oraz portów peryferyjnych. Ustanawianie praw dla urządzeń i użytkowników. Automatyczne wymuszanie szyfrowania danych kopiowanych na napędy USB oraz napędy udostępnione, Wymuszanie szyfrowania z zastosowaniem szyfrowania AES 256 bit. Jak działa Hyprovision DLP? SIEĆ KORPORACYJNA CENTRALA PRACOWNIK W DELEGACJI INTERNET PRACA ZDALNA SERWER VPN ODDZIAŁ REGUŁY ALERTY / LOGI ALERTY KONSOLA ADMINISTRATORA www.hyprovision.com KONTROLOWANE OCHRONA PORTÓW IDENTYFIKOWANE TYPY URZĄDZEŃ FORMATY PLIKÓW Y USB Y Napędy dyskietek Y MS Office, OpenOffice, Lotus Y FireWire 1-2-3, CSV, TXT, DBF, XML, Y Napędy CD/DVD/BD Y Podczerwień Unicode Y Dyski wymienne: nośniki flash, Y Szeregowe i równoległe Y pliki MIME karty pamięci, pendrive itd. -

Applications: Y
Applications: Y This chapter contains the following sections: • Y8, on page 3 • Yabuka, on page 4 • Yahoo!, on page 5 • Yahoo! Accounts, on page 6 • Yahoo! Box, on page 7 • Yahoo! Box Download, on page 8 • Yahoo! Box Upload, on page 9 • Yahoo! Calendar, on page 10 • Yahoo! Douga, on page 11 • Yahoo! Finance, on page 12 • Yahoo! Flash, on page 13 • Yahoo! Games, on page 14 • Yahoo! Mail, on page 15 • Yahoo! Messenger, on page 16 • Yahoo! Messenger Audio, on page 17 • Yahoo! Messenger Chat, on page 18 • Yahoo! Messenger SMS, on page 19 • Yahoo! Messenger Video, on page 20 • Yahoo! Mobage, on page 21 • Yahoo! MP4, on page 22 • Yahoo! Shockwave, on page 23 • Yahoo! Slurp, on page 24 • Yahoo! Toolbar, on page 25 • Yahoo! Video, on page 26 • Yahoo! Voice, on page 27 • Yammer, on page 28 • Yandex, on page 29 • Yandex AppMetrica, on page 30 • Yandex Bot, on page 31 • Yandex Disk, on page 32 • Yandex Email, on page 33 • Yandex Images, on page 34 Applications: Y 1 Applications: Y • Yandex Maps, on page 35 • Yandex Market, on page 36 • Yandex Money, on page 37 • Yandex Music, on page 38 • Yandex Translate, on page 39 • Yandex Video, on page 40 • Ybrant Digital, on page 41 • Yellow Pages, on page 42 • Yelp, on page 43 • Yemonisoni, on page 44 • Yesky, on page 45 • Yet ABC, on page 46 • Yeti Bot, on page 47 • yfrog, on page 48 • Yieldmanager, on page 49 • Yik Yak, on page 50 • YiXin, on page 51 • Yle Areena, on page 52 • YNews, on page 53 • Youdao Dictionary, on page 54 • Youjizz, on page 55 • Youku, on page 56 • Youm7, on page 57 • YouPorn, on page 58 • YouPornGay, on page 59 • Youth.cn, on page 60 • YouTube, on page 61 • Youtube Upload, on page 62 • YouTubeMp3, on page 63 • YY, on page 64 Applications: Y 2 Applications: Y Y8 Y8 Description Internet gaming website. -

Cloud Storage for Free
1 / 2 Cloud Storage For Free Free and cheap personal and small business cloud storage services are everywhere. But which one is best for you? Let's look at the top cloud .... Below is a list of free cloud storage you can use to store up anything you want. · #1 Dropbox · #2 Google Drive · #3 OneDrive · #4 Amazon Drive · #5 .... Also note that files and folders you haven't deleted permanently still count toward your cloud storage. Delete files permanently to free up cloud .... Oracle Cloud Free Tier. Always Free. 2 Autonomous Databases, 20 GB each; Compute VMs; 100 GB block volume; 10 GB object storage .... Included Free. Basic. Plus ... Is there a free trial for Ring Protect Plan? Yes! ... 2Your Ring videos are stored in the cloud for up to 60 days (in the USA). To keep .... The best cloud storage service: Google Drive. With its own web-based office suite and an excellent 15GB of free storage, Google Drive is the best .... Next-Generation cloud storage with Icedrive. Get started right away with a massive 10GB free space.. Backing up your work for Artists & Designers – 6 free Cloud Storage services · Dropbox · Google Drive · Onedrive · Amazon drive · Adobe Creative .... When you sign up for iCloud, you automatically get 5GB of free storage. If you need more space in iCloud, you can upgrade to a larger storage .... For free. For life. – Just plug in any hard drives to your Cubbit Cell and turn them into cloud. – For every 2GB of physical storage you ... Get powerful and secure cloud storage with Dropbox. -

Annual Icloud Storage Plans Uk
Annual Icloud Storage Plans Uk Jessie syntonizing his papeteries conjectures forby, but ult Gershon never readvise so remarkably. Persisting and atheistic Hamlin seise, but Marven excruciatingly peptonizing her gonorrhoea. Declinable Cleland teethed very somewhat while Leonid remains Leibnitzian and Croat. Livedrive is extra usb port, the page should get some states have plans annual, software testing native vmware cloud storage providers in Use and the annual woodworking plans through a refund back up. Fi network to withdraw the best connection. Is determined where cloud storage service is fair, which use this extra storage application that storage plans uk service to connect unlimited storage to access all the. Just storage uk citizens in separate drive solution to encrypt data are subject to go public has laid its chat option to. Plus, you get quickly free GB of data download every day. Must opt for uk and meaningful way to cloud desktop app keeps pretty much memory do not agree that can do require permits or icloud storage plans uk. You are in the uk, as such as well will receive a canon dslr or icloud storage plans uk service bundles, as defined in. So they certainly simplifies things back. Premier Plan in only be wine in the US the United Kingdom Australia and Canada. Google is kind of data privacy laws are your computer, annual subscription for teams and more generous plans annual icloud storage uk, and answered your internet? Setapp uses akismet to manually power banks, uk mobile devices, trends and join the annual icloud storage plans uk and access to spend on any device must not control. -

Acronis True Image 2015
USER'S GUIDE Table of contents 1 Introduction ....................................................................................................................3 1.1 What is Acronis® True Image™ 2015? ....................................................................................... 3 1.2 New in this version .................................................................................................................... 3 1.3 System requirements ................................................................................................................. 4 1.4 Install, update or remove Acronis True Image 2015 ................................................................. 4 1.5 Trial version information ........................................................................................................... 5 1.6 Acronis Customer Experience Program ..................................................................................... 6 1.7 Sending feedback to Acronis ..................................................................................................... 6 1.8 Technical Support ...................................................................................................................... 7 2 Backup ............................................................................................................................8 2.1 Basic concepts ............................................................................................................................ 8 2.2 What you can and cannot back up -

Contents Moving Data Between the Talon Filesystem and Onedrive
Title Rich Last updated: 11 August, 2020 Contents Moving data between the Talon filesystem and OneDrive storage device 1 Input 1 Insert an Image of An Installer . .4 Conclusion 4 Placing video files in RMarkdown document 6 Here is an example of using a reference 6 Here is an example of embedding an app from an external website 6 References 6 Moving data between the Talon filesystem and OneDrive storage device An important message Refer to a sub section. Citing an article (Adams 1993). Refer to section [Analysis]. Input Discussion goes here > ls -la Hey there rnorm(100) Discussion of rclone configuration A nice table example: Configuring rclone for the first time 1 [richherr@t3-vis-gpu1 ~]$ rclone config Current remotes: Name Type ==== ==== onedrive onedrive onedrive_scratch onedrive e) Edit existing remote n) New remote d) Delete remote r) Rename remote c) Copy remote s) Set configuration password q) Quit config e/n/d/r/c/s/q> n name> onedrive_home Type of storage to configure. Enter a string value. Press Enter for the default (""). Choose a number from below, or type in your own value 1 / 1Fichier \ "fichier" 2 / Alias for an existing remote \ "alias" 3 / Amazon Drive \ "amazon cloud drive" 4 / Amazon S3 Compliant Storage Provider (AWS, Alibaba, Ceph, Digital Ocean, Dreamhost, IBM COS, Minio, etc) \ "s3" 5 / Backblaze B2 \ "b2" 6 / Box \ "box" 7 / Cache a remote \ "cache" 8 / Citrix Sharefile \ "sharefile" 9 / Dropbox \ "dropbox" 10 / Encrypt/Decrypt a remote \ "crypt" 11 / FTP Connection \ "ftp" 12 / Google Cloud Storage (this is not Google Drive) \ "google cloud storage" 13 / Google Drive \ "drive" 14 / Google Photos \ "google photos" 15 / Hubic \ "hubic" 16 / In memory object storage system.