Likability-Based Genres: Analysis and Evaluation of the Netflix Dataset
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

First-Run Smoking Presentations in U.S. Movies 1999-2006
First-Run Smoking Presentations in U.S. Movies 1999-2006 Jonathan R. Polansky Stanton Glantz, PhD CENTER FOR TOBAccO CONTROL RESEARCH AND EDUCATION UNIVERSITY OF CALIFORNIA, SAN FRANCISCO SAN FRANCISCO, CA 94143 April 2007 EXECUTIVE SUMMARY Smoking among American adults fell by half between 1950 and 2002, yet smoking on U.S. movie screens reached historic heights in 2002, topping levels observed a half century earlier.1 Tobacco’s comeback in movies has serious public health implications, because smoking on screen stimulates adolescents to start smoking,2,3 accounting for an estimated 52% of adolescent smoking initiation. Equally important, researchers have observed a dose-response relationship between teens’ exposure to on-screen smoking and smoking initiation: the greater teens’ exposure to smoking in movies, the more likely they are to start smoking. Conversely, if their exposure to smoking in movies were reduced, proportionately fewer teens would likely start smoking. To track smoking trends at the movies, previous analyses have studied the U.S. motion picture industry’s top-grossing films with the heaviest advertising support, deepest audience penetration, and highest box office earnings.4,5 This report is unique in examining the U.S. movie industry’s total output, and also in identifying smoking movies, tobacco incidents, and tobacco impressions with the companies that produced and/or distributed the films — and with their parent corporations, which claim responsibility for tobacco content choices. Examining Hollywood’s product line-up, before and after the public voted at the box office, sheds light on individual studios’ content decisions and industry-wide production patterns amenable to policy reform. -

A New Evil Awakes the ‘Mummy’ Franchise Had Its Way with Egyptian History
16 發光的城市 A R O U N D T O W N FRIDAY, AUGUST 8, 2008 • TAIPEI TIMES A new evil awakes The ‘Mummy’ franchise had its way with Egyptian history. Now it’s moved to China for more of the same BY Ian BartholomeW StAFF REPORTER hen you leave the theater believing that Dwayne “The Rock” Johnson put in a W nuanced performance in The Scorpion King, and that Rush Hour 3 is the last word on insightful cross-cultural filmmaking, you realize you THE MUMMY: TOMB OF THE have witnessed the blockbuster action film hit a new DRAGON EMPEROR low. You do not go into a film titled The Mummy: playing Tomb of the Dragon Emperor expecting much DIRECTED BY: ROB COHEN Fraser’s better subtlety. But the ham-fisted battering you receive half is a bad piece of from a production team that runs through all the STARRING: BRENDAN FRASER (RICK O’CONNELL), JET miscasting, and places further strain on the film’s genre cliches in such a cynically derivative manner LI (李連杰, AS EMPEROR HAN), MARIA BELLO (EVELYN credibility. is a sad reflection of where a reasonably entertaining O’CONNELL), JOHN HANNAH (JONATHAN CARNAHAN), Obviously, from a marketing perspective, one franchise can be taken in the interests of making MICHELLE YEOH (楊紫瓊, AS ZI JUAN), LUKE FORD (ALEX of the main interests of The Mummy: Tomb of the more money. (The film made US$101.9 million O’CONNELL), ISABELLA LEONG (梁洛施 AS LIN), ANTHONY Dragon Emperor is that it is set “in China,” and that worldwide in its opening weekend last week.) WONG (黃秋生, AS GENERAL YANG) it has several Hong Kong stars. -

The Mummy Returns Egypt
The mummy returns Egypt. Activity about the film “The mummy returns” THE MUMMY RETURNS AN ACTIVITY FOR BOTH HISTORY AND ENGLISH LESSONS (1º ESO, BILINGUAL GROUP) OBJETIVES / OBJETIVOS -Using Past Simple -Using Irregular verbs in the past -Using short answers -Using WHAT, WHO, WHY, HOW, WHERE -Using Time expressions 1. Identificar los límites cronológicos de Egipto. 2. Conocer la importancia de la civilización egipcia. 3. Conocer la forma de gobierno del Antiguo Egipto. 4. Entender la relevancia de la arqueología como medio para el conocimiento de culturas del pasado. 5. Apreciar la identificación existente entre las creencias religiosas y la producción material por medio del estudio de los monumentos funerarios: pirámides, mastabas e hipogeos. 6. Reconocer y apreciar las manifestaciones artísticas y culturales de la cultura egipcia. ASSESMENT / CRITERIOS DE EVALUACIÓN -To be able to use the Past Simple -To be able to use the Present Simple -To be able to make questions with What, How, Why, When and Where -To be able to use short answers -To be able to use Time expressions 1. Establecer las principales etapas de la civilización egipcia. 2. Poner de relieve la singularidad de la civilización egipcia frente a otras culturas de la Antigüedad. 3. Explicar el papel jugado por la figura del faraón en el Estado egipcio. 4. Relacionar el proceso de momificación y enterramiento con la proliferación de los grandes monumentos funerarios. 5. Identificar las distintas manifestaciones del arte egipcio. BEFORE THE FILM READING COMPREHENSION: Ancient Egypt. Culture and religion. o (Reading comprehension, matching exercise and Finding out more Activities) READING AND LISTENING COMPREHENSION: Princess of Death. -

Walpole Public Library DVD List A
Walpole Public Library DVD List [Items purchased to present*] Last updated: 9/17/2021 INDEX Note: List does not reflect items lost or removed from collection A B C D E F G H I J K L M N O P Q R S T U V W X Y Z Nonfiction A A A place in the sun AAL Aaltra AAR Aardvark The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.1 vol.1 The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.2 vol.2 The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.3 vol.3 The best of Bud Abbot and Lou Costello : the Franchise Collection, ABB V.4 vol.4 ABE Aberdeen ABO About a boy ABO About Elly ABO About Schmidt ABO About time ABO Above the rim ABR Abraham Lincoln vampire hunter ABS Absolutely anything ABS Absolutely fabulous : the movie ACC Acceptable risk ACC Accepted ACC Accountant, The ACC SER. Accused : series 1 & 2 1 & 2 ACE Ace in the hole ACE Ace Ventura pet detective ACR Across the universe ACT Act of valor ACT Acts of vengeance ADA Adam's apples ADA Adams chronicles, The ADA Adam ADA Adam’s Rib ADA Adaptation ADA Ad Astra ADJ Adjustment Bureau, The *does not reflect missing materials or those being mended Walpole Public Library DVD List [Items purchased to present*] ADM Admission ADO Adopt a highway ADR Adrift ADU Adult world ADV Adventure of Sherlock Holmes’ smarter brother, The ADV The adventures of Baron Munchausen ADV Adverse AEO Aeon Flux AFF SEAS.1 Affair, The : season 1 AFF SEAS.2 Affair, The : season 2 AFF SEAS.3 Affair, The : season 3 AFF SEAS.4 Affair, The : season 4 AFF SEAS.5 Affair, -

Level 2 – the Mummy Returns – Penguin Readers
Penguin Readers Factsheets Level 2 – ElementaryLevel The Mummy Returns Teacher’s Notes The Mummy Returns by John Whitman based on the motion picture screenplay written by Stephen Sommers Summary In The Mummy Returns there are characters who once lived in the in Morocco, Jordan, and in London. Brendan Fraser plays Rick past, in ancient Egypt. They are now living in the modern world. O’Connell, Rachel Weisz plays his wife Evelyn. Patricia Velazquez The archeologist, Evelyn O’Connell, (who was Nefertiri in the past) plays Anck-su-namun, and Arnold Vosloo plays her lover, Imhotep. is married to the archeologist Rick O’Connell (an important man in Freddie Boath plays Alex and adds both suspense and comedy to the past with great powers). They met in Egypt in 1923 when they the movie. The professional wrestler the Rock plays the Scorpion were working in temples in Egypt and found the mummy of King. Imhotep, who had been sleeping for 3,000 years. When Imhotep The movie uses lots of Indiana Jones-style adventures and Star woke up, he tried to kill Evelyn, but Rick saved her. Then Rick and Wars-style special effects. It is fast-paced, with lots of surprises, Evelyn returned to England, they married and had a son, Alex. battles, love scenes, and horror. And like Indiana Jones, there are Now it is 1933 and they are back in Egypt with Alex, who is eight lots of jokes and funny moments that break the suspense, years old. They are looking for the Bracelet of Anubis. Anubis is a especially when Evelyn’s brother Jonathan is around. -
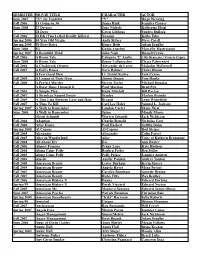
SEMESTER MOVIE TITLE CHARACTER ACTOR Sum 2007 "V
SEMESTER MOVIE TITLE CHARACTER ACTOR Sum 2007 "V" for Vendetta "V" Hugo Weaving Fall 2006 13 Going on 30 Jenna Rink Jennifer Garner Sum 2008 27 Dresses Jane Nichols Katherine Heigl ? 28 Days Gwen Gibbons Sandra Bullock Fall 2006 2LDK (Two Lethal Deadly Killers) Nozomi Koike Eiko Spring 2006 40 Year Old Virgin Andy Stitzer Steve Carell Spring 2005 50 First Dates Henry Roth Adam Sandler Sum 2008 8½ Guido Anselmi Marcello Mastroianni Spring 2007 A Beautiful Mind John Nash Russell Crowe Fall 2006 A Bronx Tale Calogero 'C' Anello Lillo Brancato / Francis Capra Sum 2008 A Bronx Tale Sonny LoSpeecchio Chazz Palmenteri Fall 2006 A Clockwork Orange Alexander de Large Malcolm McDowell Fall 2007 A Doll's House Nora Helmer Claire Bloom ? A Few Good Men Lt. Daniel Kaffee Tom Cruise Fall 2005 A League of Their Own Jimmy Dugan Tom Hanks Fall 2000 A Perfect Murder Steven Taylor Michael Douglas ? A River Runs Through It Paul Maclean Brad Pitt Fall 2005 A Simple Plan Hank Mitchell Bill Paxton Fall 2007 A Streetcar Named Desire Stanley Marlon Brando Fall 2005 A Thin Line Between Love and Hate Brandi Lynn Whitefield Fall 2007 A Time To Kill Carl Lee Haley Samuel L. Jackson Spring 2007 A Walk to Remember Landon Carter Shane West Sum 2008 A Walk to Remember Jaime Mandy Moore ? About Schmidt Warren Schmidt Jack Nickleson Fall 2004 Adaption Charlie/Donald Nicholas Cage Fall 2000 After Hours Paul Hackett Griffin Dunn Spring 2005 Al Capone Al Capone Rod Steiger Fall 2005 Alexander Alexander Colin Farrel Fall 2005 Alice in Wonderland Alice Voice of Kathryn Beaumont -

Feature Films
Libraries FEATURE FILMS The Media and Reserve Library, located in the lower level of the west wing, has over 9,000 videotapes, DVDs and audiobooks covering a multitude of subjects. For more information on these titles, consult the Libraries' online catalog. 0.5mm DVD-8746 2012 DVD-4759 10 Things I Hate About You DVD-0812 21 Grams DVD-8358 1000 Eyes of Dr. Mabuse DVD-0048 21 Up South Africa DVD-3691 10th Victim DVD-5591 24 Hour Party People DVD-8359 12 DVD-1200 24 Season 1 (Discs 1-3) DVD-2780 Discs 12 and Holding DVD-5110 25th Hour DVD-2291 12 Angry Men DVD-0850 25th Hour c.2 DVD-2291 c.2 12 Monkeys DVD-8358 25th Hour c.3 DVD-2291 c.3 DVD-3375 27 Dresses DVD-8204 12 Years a Slave DVD-7691 28 Days Later DVD-4333 13 Going on 30 DVD-8704 28 Days Later c.2 DVD-4333 c.2 1776 DVD-0397 28 Days Later c.3 DVD-4333 c.3 1900 DVD-4443 28 Weeks Later c.2 DVD-4805 c.2 1984 (Hurt) DVD-6795 3 Days of the Condor DVD-8360 DVD-4640 3 Women DVD-4850 1984 (O'Brien) DVD-6971 3 Worlds of Gulliver DVD-4239 2 Autumns, 3 Summers DVD-7930 3:10 to Yuma DVD-4340 2 or 3 Things I Know About Her DVD-6091 30 Days of Night DVD-4812 20 Million Miles to Earth DVD-3608 300 DVD-9078 20,000 Leagues Under the Sea DVD-8356 DVD-6064 2001: A Space Odyssey DVD-8357 300: Rise of the Empire DVD-9092 DVD-0260 35 Shots of Rum DVD-4729 2010: The Year We Make Contact DVD-3418 36th Chamber of Shaolin DVD-9181 1/25/2018 39 Steps DVD-0337 About Last Night DVD-0928 39 Steps c.2 DVD-0337 c.2 Abraham (Bible Collection) DVD-0602 4 Films by Virgil Wildrich DVD-8361 Absence of Malice DVD-8243 -

Queen's Banner
QUEEN’S BANNER Issue 14 Fall 2014 MRHS Welcomes Mrs. Reidy Chatting with Cristina When asking our new principal, Mrs. Valerie Reidy how she likes it at Maria Regina so far, she responded: “I LOVE IT, write that down in all caps.” Being the first student to have met Mrs. Reidy and welcome her to our school community, I must say her love for Maria Regina shows tremendously. At first Mrs. Reidy was leary about coming to a small all girls school, from a large co- ed school, but her experience here so far is not what she had ex- pected. The girls at Maria Regina are not typical of what you might think of teenage girls; at MRHS they are caring, friendly, helpful, and spirited. When one walks into the doors of Maria Regina, Mrs. Inside our Reidy says, there is such a wonderful feeling of community and home. This feeling is a fantastic gift. Fall Issue… Something that Mrs. Reidy is not used to is working with such an intimate number of staff members who seem to really enjoy What's hot and what's not this being here. She said “I have never seen a staff be here so early and season leave so late, they must love it here”.Mrs. Reidy feels that it is re- Fall Sports updates freshing being able to make decisions based on the collaboration of the whole school community with the goal of benefitting the stu- Hear about Women of the World dents. Mrs. Reidy wants to fit the needs of the students, staff, and What to watch on Netflix parents. -

Friday Bestbets
Saturday, June 21, 2014 • Waynesboro, VA • THE NEWS VIRGINIAN 15 CB<'0H E8E,<,A 9;,E :+) :#=4 Friday . F/ .$7# + F/ +$7# ( F/ ($7# % F/ %$7# =# F/ =#$7# == F/ ==$7# '<@? '>8 TV-3 News ABC World Wheel of Jeopardy! Shark Tank A pill to use in What Would You Do? 20/20 TV-3 News (:35) Jimmy 5?@8 (3) (3) 7 7 at 6 News Fortune place of food. at 11 Kimmel Live bestbets NBC 29 NBC Nightly Wheel of Jeopardy! Dateline NBC Dateline NBC Crossbones 'Antoinette' NBC 29 (:35) Jimmy 58<B (4) & & News News Fortune (N) News Fallon FOX 5 News TMZ Modern Modern Masterchef 'Top 17 Rake 'Mammophile' Fox 5 News Local news, News Edge TMZ 5>>A (5) (5) & & Family Family Compete' weather and sports. CBS 6 News CBS Evening CBS 6 News Access Undercover Boss 'Hudson Hawaii Five-0 'Ma Lalo o Blue Bloods 'Mistaken CBS 6 News (:35) David 5>8B (6) & & News at 7 p.m. Hollywood Group' ka 'ili' Identity' Letterman 9 News at 6 CBS Evening 9 News at 7 Entertainm- Undercover Boss 'Hudson Hawaii Five-0 'Ma Lalo o Blue Bloods 'Mistaken 9 News at Game On/D. 5;@0 (9) (9) % % p.m. News p.m. ent Tonight Group' ka 'ili' Identity' 11 pm Letterman WSLS 10 at NBC Nightly WSLS 10 at Inside Dateline NBC Dateline NBC Crossbones 'Antoinette' WSLS 10 at (:35) Jimmy 5@3@ (10) & & 6 p.m. News 7 p.m. Edition (N) 11 p.m. Fallon PBS NewsHour Business (N) Virginia Washington Charlie Rose Great Performances at the Met 'La Bohème' An exciting young cast Charlie Rose 58F> (11) (11) 1= 1= Farming Week (N) (N) in Zeffirelli’s lavish production of Puccini’s ever-popular work. -

Race in Hollywood: Quantifying the Effect of Race on Movie Performance
Race in Hollywood: Quantifying the Effect of Race on Movie Performance Kaden Lee Brown University 20 December 2014 Abstract I. Introduction This study investigates the effect of a movie’s racial The underrepresentation of minorities in Hollywood composition on three aspects of its performance: ticket films has long been an issue of social discussion and sales, critical reception, and audience satisfaction. Movies discontent. According to the Census Bureau, minorities featuring minority actors are classified as either composed 37.4% of the U.S. population in 2013, up ‘nonwhite films’ or ‘black films,’ with black films defined from 32.6% in 2004.3 Despite this, a study from USC’s as movies featuring predominantly black actors with Media, Diversity, & Social Change Initiative found that white actors playing peripheral roles. After controlling among 600 popular films, only 25.9% of speaking for various production, distribution, and industry factors, characters were from minority groups (Smith, Choueiti the study finds no statistically significant differences & Pieper 2013). Minorities are even more between films starring white and nonwhite leading actors underrepresented in top roles. Only 15.5% of 1,070 in all three aspects of movie performance. In contrast, movies released from 2004-2013 featured a minority black films outperform in estimated ticket sales by actor in the leading role. almost 40% and earn 5-6 more points on Metacritic’s Directors and production studios have often been 100-point Metascore, a composite score of various movie criticized for ‘whitewashing’ major films. In December critics’ reviews. 1 However, the black film factor reduces 2014, director Ridley Scott faced scrutiny for his movie the film’s Internet Movie Database (IMDb) user rating 2 by 0.6 points out of a scale of 10. -
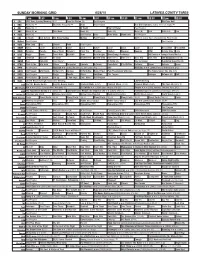
Sunday Morning Grid 6/28/15 Latimes.Com/Tv Times
SUNDAY MORNING GRID 6/28/15 LATIMES.COM/TV TIMES 7 am 7:30 8 am 8:30 9 am 9:30 10 am 10:30 11 am 11:30 12 pm 12:30 2 CBS CBS News Sunday Morning (N) Å Face the Nation (N) Paid Program PGA Tour Golf 4 NBC News (N) Å Meet the Press (N) Å News Paid Program Red Bull Signature Series From Las Vegas. Å 5 CW News (N) Å In Touch Hour Of Power Paid Program 7 ABC News (N) Å This Week News (N) News (N) News (N) Paid Vista L.A. Paid 9 KCAL News (N) Joel Osteen Hour Mike Webb Woodlands Paid Program 11 FOX In Touch Joel Osteen Fox News Sunday Midday Paid Program Golf U.S. Senior Open Championship, Final Round. 13 MyNet Paid Program Paid Program 18 KSCI Man Land Paid Church Faith Paid Program 22 KWHY Cosas Local Jesucristo Local Local Gebel Local Local Local Local RescueBot RescueBot 24 KVCR Painting Dowdle Joy of Paint Wyland’s Paint This Painting Kitchen Mexican Cooking BBQ Simply Ming Lidia 28 KCET Raggs Space Travel-Kids Biz Kid$ News Asia Insight BrainChange-Perlmutter 30 Days to a Younger Heart-Masley 30 ION Jeremiah Youssef In Touch Bucket-Dino Bucket-Dino Doki (TVY7) Doki (TVY7) Dive, Olly Dive, Olly The Bodyguard ›› (R) 34 KMEX Paid Conexión Paid Program Al Punto (N) Tras la Verdad República Deportiva (N) 40 KTBN Walk in the Win Walk Prince Carpenter Liberate In Touch PowerPoint It Is Written Pathway Super Kelinda Jesse 46 KFTR Paid Program Madison ›› (2001) Jim Caviezel, Jake Lloyd. -

NETFLIX – CATALOGO USA 20 Dicembre 2015 1. 009-1: the End Of
NETFLIX – CATALOGO USA 20 dicembre 2015 1. 009-1: The End of the Beginning (2013) , 85 imdb 2. 1,000 Times Good Night (2013) , 117 imdb 3. 1000 to 1: The Cory Weissman Story (2014) , 98 imdbAvailable in HD on your TV 4. 1001 Grams (2014) , 90 imdb 5. 100 Bloody Acres (2012) , 1hr 30m imdbAvailable in HD on your TV 6. 10.0 Earthquake (2014) , 87 imdb 7. 100 Ghost Street: Richard Speck (2012) , 1hr 23m imdbAvailable in HD on your TV 8. 100, The - Season 1 (2014) 4.3, 1 Season imdbClosed Captions: [ Available in HD on your TV 9. 100, The - Season 2 (2014) , 41 imdbAvailable in HD on your TV 10. 101 Dalmatians (1996) 3.6, 1hr 42m imdbClosed Captions: [ 11. 10 Questions for the Dalai Lama (2006) 3.9, 1hr 27m imdbClosed Captions: [ 12. 10 Rules for Sleeping Around (2013) , 1hr 34m imdbAvailable in HD on your TV 13. 11 Blocks (2015) , 78 imdb 14. 12/12/12 (2012) 2.4, 1hr 25m imdbClosed Captions: [ Available in HD on your TV 15. 12 Dates of Christmas (2011) 3.8, 1hr 26m imdbClosed Captions: [ Available in HD on your TV 16. 12 Horas 2 Minutos (2012) , 70 imdb 17. 12 Segundos (2013) , 85 imdb 18. 13 Assassins (2010) , 2hr 5m imdbAvailable in HD on your TV 19. 13 Going on 30 (2004) 3.5, 1hr 37m imdbClosed Captions: [ Available in HD on your TV 20. 13 Sins (2014) 3.6, 1hr 32m imdbClosed Captions: [ Available in HD on your TV 21. 14 Blades (2010) , 113 imdbAvailable in HD on your TV 22.