Leveraging Lotteries for School Value-Added: Testing and Estimation*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

We, the Undersigned Economists, Represent a Broad Variety of Areas of Expertise and Are United in Our Opposition to Donald Trump
We, the undersigned economists, represent a broad variety of areas of expertise and are united in our opposition to Donald Trump. We recommend that voters choose a different candidate on the following grounds: . He degrades trust in vital public institutions that collect and disseminate information about the economy, such as the Bureau of Labor Statistics, by spreading disinformation about the integrity of their work. He has misled voters in states like Ohio and Michigan by asserting that the renegotiation of NAFTA or the imposition of tariffs on China would substantially increase employment in manufacturing. In fact, manufacturing’s share of employment has been declining since the 1970s and is mostly related to automation, not trade. He claims to champion former manufacturing workers, but has no plan to assist their transition to well-compensated service sector positions. Instead, he has diverted the policy discussion to options that ignore both the reality of technological progress and the benefits of international trade. He has misled the public by asserting that U.S. manufacturing has declined. The location and product composition of manufacturing has changed, but the level of output has more than doubled in the U.S. since the 1980s. He has falsely suggested that trade is zero-sum and that the “toughness” of negotiators primarily drives trade deficits. He has misled the public with false statements about trade agreements eroding national income and wealth. Although the gains have not been equally distributed—and this is an important discussion in itself—both mean income and mean wealth have risen substantially in the U.S. -

Weak States: Causes and Consequences of the Sicilian Mafia
Weak States: Causes and Consequences of the Sicilian Mafia∗ Daron Acemoglu Giuseppe De Feo Giacomo De Luca MIT University of Leicester University of York LICOS, KU Leuven November 2018. Abstract We document that the spread of the Mafia in Sicily at the end of the 19th century was in part caused by the rise of socialist Peasant Fasci organizations. In an environment with weak state presence, this socialist threat triggered landowners, estate managers and local politicians to turn to the Mafia to resist and combat peasant demands. We show that the location of the Peasant Fasci is significantly affected by a severe drought in 1893, and using information on rainfall, we estimate the impact of the Peasant Fasci on the location of the Mafia in 1900. We provide extensive evidence that rainfall before and after this critical period has no effect on the spread of the Mafia or various economic and political outcomes. In the second part of the paper, we use the source of variation in the strength of the Mafia in 1900 to estimate its medium-term and long-term effects. We find significant and quantitatively large negative impacts of the Mafia on literacy and various public goods in the 1910s and 20s. We also show a sizable impact of the Mafia on political competition, which could be one of the channels via which it affected local economic outcomes. We document negative effects of the Mafia on longer-term outcomes (in the 1960s, 70s and 80s) as well, but these are in general weaker and often only marginally significant. -

Intangible Economies of Scope: Micro Evidence and Macro Implications∗
Intangible Economies of Scope: Micro Evidence and Macro Implications∗ Xiang Ding† Harvard University January 24, 2020 Click Here for the Latest Version Abstract Do economies of scope within firms transmit macro shocks across industries? I exploit exogenous variation in foreign demand faced by US multi-industry manufacturers to identify this mechanism. I find that a positive demand shock in one industry of a firm increases its sales in another only when both industries use the same intangible inputs. I develop a general equilibrium model of multi-industry firms and estimate that scope economies are driven by the scalability and non-rivalry of intangible inputs under joint production. Cross-industry spillovers due to scope economies account for 20 percent of the equilibrium response of productivity to market size. Applied to US trade, the model predicts large productivity spillovers from industry shocks, particularly across industries that use more intangible inputs. ∗I am indebted to Pol Antràs, Elhanan Helpman, Marc Melitz, Emmanuel Farhi, and Teresa Fort for their invaluable advice. I thank Isaiah Andrews, Robert Barro, Emily Blanchard, Kirill Borusyak, Lorenzo Caliendo, Davin Chor, Dave Donaldson, Fabian Eckert, Evgenii Fadeev, Ed Glaeser, Oliver Hart, Robin Lee, Myrto Kalouptsidi, Larry Katz, Ariel Pakes, Steve Redding, Pete Schott, Bob Staiger, Elie Tamer, Hanna Tian, Gabriel Unger, Jeffrey Wang, and seminar participants at Harvard, Dartmouth, FSRDC at Wisconsin-Madison, and METIT at WUSTL for very helpful comments, and Jim Davis for exceptional help with disclosure review. I wrote parts of this paper while visiting Dartmouth Tuck as an International Economics Ph.D. Fellow. I am grateful to the department for their hospitality and support. -

The Value of Medicaid: Interpreting Results from the Oregon Health Insurance Experiment
The Value of Medicaid: Interpreting Results from the Oregon Health Insurance Experiment Amy Finkelstein Massachusetts Institute of Technology Nathaniel Hendren Harvard University Erzo F. P. Luttmer Dartmouth College We develop frameworks for welfare analysis of Medicaid and apply them to the Oregon Health Insurance Experiment. Across different approaches, we estimate low-income uninsured adults’ willingness to pay for Medicaid between $0.5 and $1.2 per dollar of the resource cost of providing Medicaid; estimates of the expected transfer Medicaid pro- vides to recipients are relatively stable across approaches, but estimates of its additional value from risk protection are more variable. We also estimate that the resource cost of providing Medicaid to an additional recipient is only 40 percent of Medicaid’s total cost; 60 percent of Med- icaid spending is a transfer to providers of uncompensated care for the low-income uninsured. We are grateful to Lizi Chen for outstanding research assistance and to Isaiah Andrews, David Cutler, Liran Einav, Matthew Gentzkow, Jonathan Gruber, Conrad Miller, Jesse Sha- piro, Matthew Notowidigdo, Ivan Werning, three anonymous referees, Michael Green- stone (the editor), and seminar participants at Brown, Chicago Booth, Cornell, Harvard Medical School, Michigan State, Pompeu Fabra, Simon Fraser University, Stanford, the University of California Los Angeles, the University of California San Diego, the University of Houston, and the University of Minnesota for helpful comments. We gratefully acknowl- edge financial support from the National Institute of Aging under grants RC2AGO36631 and R01AG0345151 (Finkelstein) and the National Bureau of Economic Research Health Electronically published November 5, 2019 [ Journal of Political Economy, 2019, vol. -

A Complete Bibliography of the Journal of Business & Economic
A Complete Bibliography of the Journal of Business & Economic Statistics Nelson H. F. Beebe University of Utah Department of Mathematics, 110 LCB 155 S 1400 E RM 233 Salt Lake City, UT 84112-0090 USA Tel: +1 801 581 5254 FAX: +1 801 581 4148 E-mail: [email protected], [email protected], [email protected] (Internet) WWW URL: http://www.math.utah.edu/~beebe/ 20 May 2021 Version 1.01 Title word cross-reference (0; 1; 1)12 [Bel87]. 1=2 [GI11]. 4 [Fre85]. α [McC97]. F(d) [CdM19]. L [BC11]. M [TZ19]. N [AW07, CSZZ17, GK14]. = 1 [Bel87]. P [Han97, Ray90]. R [CW96]. R2 [MRW19]. T [AW07, GK14, RSW18, FSC03, IM10, JS10, MV91, NS96, TM19]. U [TZ19]. -Estimators [TZ19]. -Processes [TZ19]. -R [Fre85]. -Squared [CW96]. -Statistic [IM10, TM19]. -Statistics [BC11]. 100 [ACW97]. 11 [McK84, dBM90]. 225 [ACW97]. 2SLS [Lee18]. 500 [ACW97]. 1 2 a.m [HRV20]. Ability [CM09, Han05, Son12]. Abnormal [MlM87]. Absorbing [KK15]. Abuse [Die15a]. Accelerated [KLS15]. Access [AKO12]. Accessibility [FM97]. Accident [GFdH87]. Accommodating [KDM20]. Accountability [BDJ12]. Accounting [HPSW88, HW84, MPTK91]. Accounts [Che12]. Accumulated [DM01]. Accumulation [Cag03, DM01]. Accuracies [Fom86]. Accuracy [DM95a, DM02, Die15a, McN86a, NP90, PG93, Wec89]. Accurate [McK18]. Acidic [PR87]. Acknowledgment [Ano93a]. Acreages [HF87]. Across [PG93, PP11]. Act [Fre85]. Action [GW85]. Activities [AC03, But85]. Activity [FS93, JLR11, Li11, RS94b]. Actually [CO19]. Adaptive [CZ14, CHL18, CL17, HHK11, HF19, Tsa93b, ZS15]. Addiction [BG01]. Additional [LZ95]. Additive [Abe99, FZ18, FH94, Lia12, OHS14]. Addressing [Mel18]. Adequacy [HM89]. Adjust [Nev03]. Adjusted [AW84, LD19, MS03, NTP94, Rad83, Rub86, Son10]. Adjusting [vdHH86]. Adjustment [BH84a, BH02, BW84, CW86b, DM84, DL87, EG98, ES01a, FMB+98a, Ghy90, GGS96a, Ghy97, HR91, HKR97, Hil85, Jai89, Jor99, Lin86, LHM20, McE17, ML90, McK84, Pat86, Pfe91a, Pie83, Pie84, PGC84, Sim85, Tay02, dBM90]. -
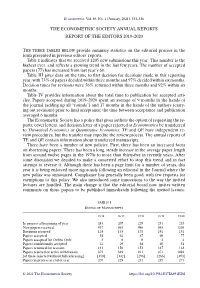
The Econometric Society Annual Reports. Report of the Editors 2019
Econometrica, Vol. 89, No. 1 (January, 2021), 533–536 THE ECONOMETRIC SOCIETY ANNUAL REPORTS REPORT OF THE EDITORS 2019–2020 THE THREE TABLES BELOW provide summary statistics on the editorial process in the form presented in previous editors’ reports. Ta b l e I indicates that we received 1205 new submissions this year. This number is the highest ever, and reflects a growing trend in the last few years. The number of accepted papers (77) has increased from last year’s 60. Ta b l e III gives data on the time to first decision for decisions made in this reporting year, with 73% of papers decided within three months and 97% decided within six months. Decision times for revisions were 56% returned within three months and 92% within six months. Ta b l e IV provides information about the total time to publication for accepted arti- cles. Papers accepted during 2019–2020 spent an average of 9 months in the hands of the journal (adding up all “rounds”) and 17 months in the hands of the authors (carry- ing out revisions) prior to final acceptance; the time between acceptance and publication averaged 6 months. The Econometric Society has a policy that gives authors the option of requesting the re- ports, cover letters, and decision letter of a paper rejected at Econometrica be transferred to Theoretical Economics or Quantitative Economics. TE and QE have independent re- view procedures, but the transfer may expedite the review process. The annual reports of TE and QE contain information about transferred manuscripts. There have been a number of new policies. -

AEM 7500: Resource Economics
Charles H. Dyson School of Applied Economics and Management Spring 2021 Cornell University AEM 7500: Resource Economics Syllabus Professor: Professor C.-Y. Cynthia Lin Lawell Office hours: TBA, via Zoom Course web site: Canvas (https://login.canvas.cornell.edu/) Class time and room: Wednesdays 7:30pm-10:30pm Eastern Time, via Zoom This Syllabus will be continually updated throughout the Semester. The Canvas course web site will always have the latest version of the Syllabus for this Semester. For the latest version of Syllabus, please see the Canvas course web site. 1 © 2021 C.-Y. Cynthia Lin Lawell COURSE DESCRIPTION AEM 7500 covers analytic methods for analyzing optimal control theory problems; analytic and numerical methods for solving dynamic programming problems; numerical methods for solving stochastic dynamic programming problems; structural econometric models of static games of incomplete information; structural econometric models of single-agent dynamic optimization problems; structural econometric models of multi-agent dynamic games; and advanced topics in dynamic structural econometric modeling including unobserved heterogeneity, identification, partial identification, and machine learning. The course also covers economic applications of these methods that are relevant to the environment, energy, natural resources, agriculture, development, management, finance, marketing, industrial organization, and business economics. These applications include firm investment, nonrenewable resource extraction, optimal economic growth, fisheries, -

Job Market Candidates 2019-2020 ______
HARVARD UNIVERSITY DEPARTMENT OF ECONOMICS LITTAUER CENTER, CAMBRIDGE, MASSACHUSETTS 02138-3001 Job Market Candidates 2019-2020 ________________________________________________________ LISA ABRAHAM JMP: “Words Matter: Experimental Evidence from Job Applications” Fields: Labor Economics, Public Economics Advisors: Claudia Goldin, Nathan Hendren, Larry Katz, Amanda Pallais EDOARDO ACABBI JMP: “The Financial Channels of Labor Rigidities: Evidence from Portugal” Fields: Macroeconomics, Financial Economics, Labor Economics Advisors: Gabriel Chodorow Reich, Jeremy Stein, Emmanuel Farhi, Sam Hanson OMAR BARBIERO JMP: “The Valuation Effects of Trade” Fields: Macroeconomics, International Finance, Trade Advisors: Gita Gopinath, Matteo Maggiori, Marc Melitz ALEX BELL JMP: “Job Amenities & Earnings Inequality” Fields: Labor Economics, Social Economics, Public Economics, Innovation Advisors: Nathan Hendren, Raj Chetty, Larry Katz, Elie Tamer SOPHIE CALDER-WANG JMP: “The Distributional Impact of the Sharing Economy on the Housing Market” Fields: Industrial Organization, Finance, Entrepreneurship, Real Estate Advisors: Ariel Pakes, Edward Glaeser, Robin Lee, Adi Sunderam, Paul Gompers MOYA CHIN JMP: “When do Politicians Appeal Broadly? The Economic Consequences of Electoral Rules in Brazil” Fields: Development Economics, Political Economy Advisors: Nathan Nunn, Melissa Dell, Gautam Rao, Vincent Pons CHRISTOPHER CLAYTON JMP: “Multinational Banks and Financial Stability” Fields: Macroeconomics, Financial Economics Advisors: Emmanuel Farhi, Matteo Maggiori, -
Download Program
Allied Social Science Associations Program BOSTON, MA January 3–5, 2015 Contract negotiations, management and meeting arrangements for ASSA meetings are conducted by the American Economic Association. Participants should be aware that the media has open access to all sessions and events at the meetings. i Thanks to the 2015 American Economic Association Program Committee Members Richard Thaler, Chair Severin Borenstein Colin Camerer David Card Sylvain Chassang Dora Costa Mark Duggan Robert Gibbons Michael Greenstone Guido Imbens Chad Jones Dean Karlan Dafny Leemore Ulrike Malmender Gregory Mankiw Ted O’Donoghue Nina Pavcnik Diane Schanzenbach Cover Art—“Melting Snow on Beacon Hill” by Kevin E. Cahill (Colored Pencil, 15 x 20 ); awarded first place in the mixed media category at the ″ ″ Salmon River Art Guild’s 2014 Regional Art Show. Kevin is a research economist with the Sloan Center on Aging & Work at Boston College and a managing director at ECONorthwest in Boise, ID. Kevin invites you to visit his personal website at www.kcahillstudios.com. ii Contents General Information............................... iv ASSA Hotels ................................... viii Listing of Advertisers and Exhibitors ...............xxvii ASSA Executive Officers......................... xxix Summary of Sessions by Organization ..............xxxii Daily Program of Events ............................1 Program of Sessions Friday, January 2 ...........................29 Saturday, January 3 .........................30 Sunday, January 4 .........................145 Monday, January 5.........................259 Subject Area Index...............................337 Index of Participants . 340 iii General Information PROGRAM SCHEDULES A listing of sessions where papers will be presented and another covering activities such as business meetings and receptions are provided in this program. Admittance is limited to those wearing badges. Each listing is arranged chronologically by date and time of the activity. -

Aggregating Distributional Treatment Effects
Aggregating Distributional Treatment Effects: A Bayesian Hierarchical Analysis of the Microcredit Literature JOB MARKET PAPER Most recent version: http://economics.mit.edu/files/12292 Rachael Meager∗† December 21, 2016 Abstract This paper develops methods to aggregate evidence on distributional treatment effects from multiple studies conducted in different settings, and applies them to the microcredit literature. Several randomized trials of expanding access to microcredit found substantial effects on the tails of household outcome distributions, but the extent to which these findings generalize to future settings was not known. Aggregating the evidence on sets of quantile effects poses additional challenges relative to average effects because distributional effects must imply monotonic quantiles and pass information across quantiles. Using a Bayesian hierarchical framework, I develop new models to aggregate distributional effects and assess their generalizability. For continuous outcome variables, the methodological challenges are addressed by applying transforms to the unknown parameters. For partially discrete variables such as business profits, I use contextual economic knowledge to build tailored parametric aggregation models. I find generalizable evidence that microcredit has negligible impact on the distribution of various household outcomes below the 75th percentile, but above this point there is no generalizable prediction. Thus, while microcredit typically does not lead to worse outcomes at the group level, there is no generalizable evidence on whether it improves group outcomes. Households with previous business experience account for the majority of the impact and see large increases in the right tail of the consumption distribution. ∗Massachusetts Institute of Technology. Contact: [email protected] †Funding for this research was generously provided by the Berkeley Initiative for Transparency in the Social Sciences (BITSS), a program of the Center for Effective Global Action (CEGA), with support from the Laura and John Arnold Foundation. -

The Payoffs of Higher Pay: Elasticitiesof Productivityand Labor Supply with Respectto Wages
THE PAYOFFS OF HIGHER PAY: ELASTICITIES OF PRODUCTIVITY AND LABOR SUPPLY WITH RESPECT TO WAGES Natalia Emanuel · Emma Harrington1 (Job Market Paper) . This version: October 30, 2020 Latest Version: Click here Abstract Firm wage-setting trades off the potential benefits of higher wages — including increased productivity, decreased turnover, and enhanced recruitment — against their direct costs. We estimate productivity and labor supply elasticities with respect to wages among ware- house and call-center workers in a Fortune 500 retailer. To identify these elasticities, we use rigidities in the firm’s pay setting policies that create heterogeneity relative to a chang- ing outside option, as well as discrete jumps when the firm recalibrates pay. We find evi- dence of labor market frictions that can give firms wage-setting power: we estimate moder- ately large, but finite, turnover elasticities (−3 to −4) and recruitment elasticities (3 to 4.5). In addition, we find productivity responses to higher pay in excess of $1. By comparing warehouse workers’ responses to higher wages both across workers and within the same worker, we find that over half of the turnover reductions and productivity increases arise from behavioral responses as opposed to compositional differences. Our results suggest historical pay increases are consistent with optimizing behavior. However, these aggregate patterns mask heterogeneity. For example, women’s productivity responds more to wages than men’s, while women’s turnover is less responsive than men’s, which can lead to occu- pational wage differences. 1Contact: Harvard University, 1805 Cambridge Street, Cambridge, MA 02138, [email protected] · ehar- [email protected]. -

Department of Economics, Report to the President 2016-2017
Department of Economics The MIT Economics Department is widely regarded as one of the world’s premier institutions for economics research and education. The faculty balance substantial commitments to training both undergraduates and doctoral students with active and influential research programs. With one of the youngest senior faculties among its peer institutions, the department plays a central role as an innovator in economics research and a source of exciting new directions in undergraduate and graduate economics education. Highlights The highlight of the past year was Bengt Holmström’s receipt of the 2016 Nobel Prize in Economics. The 2016 Sveriges Riksbank Prize in Economic Sciences in Memory of Alfred Nobel, was awarded jointly to Holmstrom and to Oliver Hart of Harvard University for their research on contract theory. Their pioneering work opened up a broad field of inquiry that studies incentives within organizations, the optimal design of contracts between employers and employees, and the role of asymmetric information in other settings. Many other members of the faculty received important honors and recognition. Alberto Abadie, Jonathan Gruber, and Parag Pathak were elected as fellows of the Econometric Society. Daron Acemoglu won the 2017 BBVA Foundation Frontiers of Knowledge Award for Economics, Finance, and Management, and was named a Carnegie fellow. Dave Donaldson, an MIT faculty member from 2009 until 2014, and who rejoined the faculty in July 2017, received the John Bates Clark Medal from the American Economic Association as the outstanding American economist under the age of 40. Isaiah Andrews and Alp Simsek were awarded National Science Foundation CAREER grants. Esther Duflo was elected to the National Academy of Sciences.