Live Upgrading Thousands of Servers from an Ancient Red Hat Distribution to 10 Year Newer Debian Based One Marc Merlin, Google, Inc
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Chrooting All Services in Linux
LinuxFocus article number 225 http://linuxfocus.org Chrooting All Services in Linux by Mark Nielsen (homepage) About the author: Abstract: Mark works as an independent consultant Chrooted system services improve security by limiting damage that donating time to causes like someone who broke into the system can possibly do. GNUJobs.com, writing _________________ _________________ _________________ articles, writing free software, and working as a volunteer at eastmont.net. Introduction What is chroot? Chroot basically redefines the universe for a program. More accurately, it redefines the "ROOT" directory or "/" for a program or login session. Basically, everything outside of the directory you use chroot on doesn't exist as far a program or shell is concerned. Why is this useful? If someone breaks into your computer, they won't be able to see all the files on your system. Not being able to see your files limits the commands they can do and also doesn't give them the ability to exploit other files that are insecure. The only drawback is, I believe it doesn't stop them from looking at network connections and other stuff. Thus, you want to do a few more things which we won't get into in this article too much: Secure your networking ports. Have all services run as a service under a non-root account. In addition, have all services chrooted. Forward syslogs to another computer. Analyze logs files Analyze people trying to detect random ports on your computer Limit cpu and memory resources for a service. Activate account quotas. The reason why I consider chroot (with a non-root service) to be a line of defense is, if someone breaks in under a non-root account, and there are no files which they can use to break into root, then they can only limit damage to the area they break in. -

The Linux Kernel Module Programming Guide
The Linux Kernel Module Programming Guide Peter Jay Salzman Michael Burian Ori Pomerantz Copyright © 2001 Peter Jay Salzman 2007−05−18 ver 2.6.4 The Linux Kernel Module Programming Guide is a free book; you may reproduce and/or modify it under the terms of the Open Software License, version 1.1. You can obtain a copy of this license at http://opensource.org/licenses/osl.php. This book is distributed in the hope it will be useful, but without any warranty, without even the implied warranty of merchantability or fitness for a particular purpose. The author encourages wide distribution of this book for personal or commercial use, provided the above copyright notice remains intact and the method adheres to the provisions of the Open Software License. In summary, you may copy and distribute this book free of charge or for a profit. No explicit permission is required from the author for reproduction of this book in any medium, physical or electronic. Derivative works and translations of this document must be placed under the Open Software License, and the original copyright notice must remain intact. If you have contributed new material to this book, you must make the material and source code available for your revisions. Please make revisions and updates available directly to the document maintainer, Peter Jay Salzman <[email protected]>. This will allow for the merging of updates and provide consistent revisions to the Linux community. If you publish or distribute this book commercially, donations, royalties, and/or printed copies are greatly appreciated by the author and the Linux Documentation Project (LDP). -

LM1881 Video Sync Separator Datasheet
Product Sample & Technical Tools & Support & Folder Buy Documents Software Community LM1881 SNLS384G –FEBRUARY 1995–REVISED JUNE 2015 LM1881 Video Sync Separator 1 Features 3 Description The LM1881 Video sync separator extracts timing 1• AC Coupled Composite Input Signal information including composite and vertical sync, • >10-kΩ Input Resistance burst or back porch timing, and odd and even field • <10-mA Power Supply Drain Current information from standard negative going sync NTSC, • Composite Sync and Vertical Outputs PAL (1) and SECAM video signals with amplitude from • Odd and Even Field Output 0.5-V to 2-V p-p. The integrated circuit is also capable of providing sync separation for non- • Burst Gate or Back Porch Output standard, faster horizontal rate video signals. The • Horizontal Scan Rates to 150 kHz vertical output is produced on the rising edge of the • Edge Triggered Vertical Output first serration in the vertical sync period. A default vertical output is produced after a time delay if the • Default Triggered Vertical Output for Non- rising edge mentioned above does not occur within Standard Video Signal (Video Games-Home the externally set delay period, such as might be the Computers) case for a non-standard video signal. 2 Applications Device Information(1) • Video Cameras and Recorders PART NUMBER PACKAGE BODY SIZE (NOM) SOIC (8) 4.90 mm × 3.91 mm • Broadcasting Systems LM1881 • Set-Top Boxes PDIP (8) 9.81 mm × 6.35 mm • Home Entertainment (1) For all available packages, see the orderable addendum at the end of the data sheet. • Computing and Gaming Applications (1) PAL in this datasheet refers to European broadcast TV standard “Phase Alternating Line”, and not to Programmable Array Logic. -

26 Disk Space Management
26 Disk Space Management 26.1 INTRODUCTION It has been said that the only thing all UNIX systems have in common is the login message asking users to clean up their files and use less disk space. No matter how much space you have, it isn’t enough; as soon as a disk is added, files magically appear to fill it up. Both users and the system itself are potential sources of disk bloat. Chapter 12, Syslog and Log Files, discusses various sources of logging information and the techniques used to manage them. This chapter focuses on space problems caused by users and the technical and psy- chological weapons you can deploy against them. If you do decide to Even if you have the option of adding more disk storage to your system, add a disk, refer to it’s a good idea to follow this chapter’s suggestions. Disks are cheap, but Chapter 9 for help. administrative effort is not. Disks have to be dumped, maintained, cross-mounted, and monitored; the fewer you need, the better. 26.2 DEALING WITH DISK HOGS In the absence of external pressure, there is essentially no reason for a user to ever delete anything. It takes time and effort to clean up unwanted files, and there’s always the risk that something thrown away might be wanted again in the future. Even when users have good intentions, it often takes a nudge from the system administrator to goad them into action. 618 Chapter 26 Disk Space Management 619 On a PC, disk space eventually runs out and the machine’s primary user must clean up to get the system working again. -

How UNIX Organizes and Accesses Files on Disk Why File Systems
UNIX File Systems How UNIX Organizes and Accesses Files on Disk Why File Systems • File system is a service which supports an abstract representation of the secondary storage to the OS • A file system organizes data logically for random access by the OS. • A virtual file system provides the interface between the data representation by the kernel to the user process and the data presentation to the kernel in memory. The file and directory system cache. • Because of the performance disparity between disk and CPU/memory, file system performance is the paramount issue for any OS Main memory vs. Secondary storage • Small (MB/GB) Large (GB/TB) • Expensive Cheap -2 -3 • Fast (10-6/10-7 sec) Slow (10 /10 sec) • Volatile Persistent Cannot be directly accessed • Directly accessible by CPU by CPU – Interface: (virtual) memory – Data should be first address brought into the main memory Secondary storage (disk) • A number of disks directly attached to the computer • Network attached disks accessible through a fast network - Storage Area Network (SAN) • Simple disks (IDE, SATA) have a described disk geometry. Sector size is the minimum read/write unit of data (usually 512Bytes) – Access: (#surface, #track, #sector) • Smart disks (SCSI, SAN, NAS) hide the internal disk layout using a controller type function – Access: (#sector) • Moving arm assembly (Seek) is expensive – Sequential access is x100 times faster than the random access Internal disk structure • Disk structure User Process Accessing Data • Given the file name. Get to the file’s FCB using the file system catalog (Open, Close, Set_Attribute) • The catalog maps a file name to the FCB – Checks permissions • file_handle=open(file_name): – search the catalog and bring FCB into the memory – UNIX: in-memory FCB: in-core i-node • Use the FCB to get to the desired offset within the file data: (CREATE, DELETE, SEEK, TRUNCATE) • close(file_handle): release FCB from memory Catalog Organization (Directories) • In UNIX, special files (not special device files) called directories contain information about other files. -

Linux Kernel and Driver Development Training Slides
Linux Kernel and Driver Development Training Linux Kernel and Driver Development Training © Copyright 2004-2021, Bootlin. Creative Commons BY-SA 3.0 license. Latest update: October 9, 2021. Document updates and sources: https://bootlin.com/doc/training/linux-kernel Corrections, suggestions, contributions and translations are welcome! embedded Linux and kernel engineering Send them to [email protected] - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 1/470 Rights to copy © Copyright 2004-2021, Bootlin License: Creative Commons Attribution - Share Alike 3.0 https://creativecommons.org/licenses/by-sa/3.0/legalcode You are free: I to copy, distribute, display, and perform the work I to make derivative works I to make commercial use of the work Under the following conditions: I Attribution. You must give the original author credit. I Share Alike. If you alter, transform, or build upon this work, you may distribute the resulting work only under a license identical to this one. I For any reuse or distribution, you must make clear to others the license terms of this work. I Any of these conditions can be waived if you get permission from the copyright holder. Your fair use and other rights are in no way affected by the above. Document sources: https://github.com/bootlin/training-materials/ - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 2/470 Hyperlinks in the document There are many hyperlinks in the document I Regular hyperlinks: https://kernel.org/ I Kernel documentation links: dev-tools/kasan I Links to kernel source files and directories: drivers/input/ include/linux/fb.h I Links to the declarations, definitions and instances of kernel symbols (functions, types, data, structures): platform_get_irq() GFP_KERNEL struct file_operations - Kernel, drivers and embedded Linux - Development, consulting, training and support - https://bootlin.com 3/470 Company at a glance I Engineering company created in 2004, named ”Free Electrons” until Feb. -
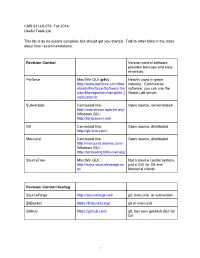
Useful Tools for Game Making
CMS.611J/6.073 Fall 2014 Useful Tools List This list is by no means complete, but should get you started. Talk to other folks in the class about their recommendations. Revision Control Version control software, provides backups and easy reversion. Perforce Mac/Win GUI (p4v): Heavily used in game http://www.perforce.com/dow industry. Commercial nloads/Perforce-Software-Ver software; you can use the sion-Management/complete_l Game Lab server. ist/Customer Subversion Command line: Open source, server-based http://subversion.apache.org/ Windows GUI: http://tortoisesvn.net/ Git Command line: Open source, distributed http://git-scm.com/ Mercurial Command line: Open source, distributed http://mercurial.selenic.com/ Windows GUI: http://tortoisehg.bitbucket.org/ SourceTree Mac/Win GUI: Not a source control system, http://www.sourcetreeapp.co just a GUI for Git and m/ Mercurial clients Revision Control Hosting SourceForge http://sourceforge.net/ git, mercurial, or subversion BitBucket https://bitbucket.org/ git or mercurial GitHub https://github.com/ git, has own (painful) GUI for Git 1 Image Editing MSPaint Windows, pre-installed Surprisingly useful quick pixel art editor (esp for prototypes) Paint.NET Windows, About as easy as MSPaint, but http://www.getpaint.net/download much more powerful .html Photoshop Mac, Windows New Media Center, 26-139 GIMP Many platforms, Easier than photoshop, at http://www.gimp.org/downloads/ least. Sound GarageBand Mac New Media Center, 26-139 Audacity Many platforms, Free, open source. http://audacity.sourceforge.ne -

Jenkins Job Builder Documentation Release 3.10.0
Jenkins Job Builder Documentation Release 3.10.0 Jenkins Job Builder Maintainers Aug 23, 2021 Contents 1 README 1 1.1 Developers................................................1 1.2 Writing a patch..............................................2 1.3 Unit Tests.................................................2 1.4 Installing without setup.py........................................2 2 Contents 5 2.1 Quick Start Guide............................................5 2.1.1 Use Case 1: Test a job definition................................5 2.1.2 Use Case 2: Updating Jenkins Jobs...............................5 2.1.3 Use Case 3: Working with JSON job definitions........................6 2.1.4 Use Case 4: Deleting a job...................................6 2.1.5 Use Case 5: Providing plugins info...............................6 2.2 Installation................................................6 2.2.1 Documentation.........................................7 2.2.2 Unit Tests............................................7 2.2.3 Test Coverage..........................................7 2.3 Configuration File............................................7 2.3.1 job_builder section.......................................8 2.3.2 jenkins section.........................................9 2.3.3 hipchat section.........................................9 2.3.4 stash section...........................................9 2.3.5 __future__ section.......................................9 2.4 Running.................................................9 2.4.1 Test Mode........................................... -

DVCS Or a New Way to Use Version Control Systems for Freebsd
Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions DVCS or a new way to use Version Control Systems for FreeBSD Ollivier ROBERT <[email protected]> BSDCan 2006 Ottawa, Canada May, 12-13th, 2006 Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions Agenda 1 Brief history of VCS 2 FreeBSD context & gures 3 Is Arch/baz suited for FreeBSD? 4 Mercurial to the rescue 5 New processes & policies needed 6 Conclusions Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions The ancestors: SCCS, RCS File-oriented Use a subdirectory to store deltas and metadata Use lock-based architecture Support shared developments through NFS (fragile) SCCS is proprietary (System V), RCS is Open Source a SCCS clone exists: CSSC You can have a central repository with symlinks (RCS) Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions CVS, the de facto VCS for the free world Initially written as shell wrappers over RCS then rewritten in C Centralised server Easy UI Use sandboxes to avoid locking Simple 3-way merges Can be replicated through CVSup or even rsync Extensive documentation (papers, websites, books) Free software and used everywhere (SourceForge for example) Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions CVS annoyances and aws BUT.. -

Installing the Data Broker on a Linux Host : Cloud Sync
Installing the data broker on a Linux host Cloud Sync Ben Cammett April 11, 2021 This PDF was generated from https://docs.netapp.com/us-en/cloudsync/task_installing_linux.html on September 23, 2021. Always check docs.netapp.com for the latest. Table of Contents Installing the data broker on a Linux host. 1 Linux host requirements. 1 Networking requirements . 1 Enabling access to AWS . 1 Enabling access to Google Cloud . 2 Enabling access to Microsoft Azure . 2 Installing the data broker . 2 Installing the data broker on a Linux host When you create a new data broker, choose the On-Prem Data Broker option to install the data broker software on an on-premises Linux host, or on an existing Linux host in the cloud. Cloud Sync guides you through the installation process, but the requirements and steps are repeated on this page to help you prepare for installation. Linux host requirements • Operating system: ◦ CentOS 7.0, 7.7, and 8.0 ◦ Red Hat Enterprise Linux 7.7 and 8.0 ◦ Ubuntu Server 20.04 LTS ◦ SUSE Linux Enterprise Server 15 SP1 The command yum update all must be run on the host before you install the data broker. A Red Hat Enterprise Linux system must be registered with Red Hat Subscription Management. If it is not registered, the system cannot access repositories to update required 3rd party software during installation. • RAM: 16 GB • CPU: 4 cores • Free disk space: 10 GB • SELinux: We recommend that you disable SELinux on the host. SELinux enforces a policy that blocks data broker software updates and can block the data broker from contacting endpoints required for normal operation. -

Helix Authentication Service Administrator Guide 2021.1 May 2021 Copyright © 2020-2021 Perforce Software, Inc
Helix Authentication Service Administrator Guide 2021.1 May 2021 Copyright © 2020-2021 Perforce Software, Inc.. All rights reserved. All software and documentation of Perforce Software, Inc. is available from www.perforce.com. You can download and use Perforce programs, but you can not sell or redistribute them. You can download, print, copy, edit, and redistribute the documentation, but you can not sell it, or sell any documentation derived from it. You can not modify or attempt to reverse engineer the programs. This product is subject to U.S. export control laws and regulations including, but not limited to, the U.S. Export Administration Regulations, the International Traffic in Arms Regulation requirements, and all applicable end-use, end-user and destination restrictions. Licensee shall not permit, directly or indirectly, use of any Perforce technology in or by any U.S. embargoed country or otherwise in violation of any U.S. export control laws and regulations. Perforce programs and documents are available from our Web site as is. No warranty or support is provided. Warranties and support, along with higher capacity servers, are sold by Perforce. Perforce assumes no responsibility or liability for any errors or inaccuracies that might appear in this book. By downloading and using our programs and documents you agree to these terms. Perforce and Inter-File Branching are trademarks of Perforce. All other brands or product names are trademarks or registered trademarks of their respective companies or organizations. Contents How to use -

Staying out of the Swamp
Staying out of the server swamp Richard Baum Perforce Software October, 2001 Contents Introduction How do I tell if I'm in the swamp? Is your system CPU bound? Is your system memory bound? Is your system I/O bound? How can Perforce cause server swamp? Network Attached Storage Confusing and complex client mappings Background processes The Perforce error log Gigantic operations Conclusion Introduction Perforce runs extremely well when it is given the right resources. A Perforce server does not generally require much CPU. Memory and disk requirements correspond to the amount of data you wish to store. Conditions can sometimes conspire to change a well-performing server into a poorly-performing one. This talk will cover some of the things to watch out for to keep your Perforce server happy and healthy. The object of this talk is to familiarize you with what to look for so you can determine where the problem lies, and what to do so you can remedy the problem. In general, performance that a user will see is limited by the I/O bandwidth of the server and the speed of its connection with a client machine. A server that appears to not be responding in its typically speedy fashion may, in fact, be swamped with data and requests for data. How do I tell if I'm in the swamp? If you suspect that your Perforce server is swamped, the first things to do are to check whether it is, in fact, running, and to examine the machine that hosts the server for any obvious signs of a problem.