Staying out of the Swamp
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
Useful Tools for Game Making
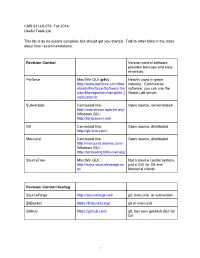
CMS.611J/6.073 Fall 2014 Useful Tools List This list is by no means complete, but should get you started. Talk to other folks in the class about their recommendations. Revision Control Version control software, provides backups and easy reversion. Perforce Mac/Win GUI (p4v): Heavily used in game http://www.perforce.com/dow industry. Commercial nloads/Perforce-Software-Ver software; you can use the sion-Management/complete_l Game Lab server. ist/Customer Subversion Command line: Open source, server-based http://subversion.apache.org/ Windows GUI: http://tortoisesvn.net/ Git Command line: Open source, distributed http://git-scm.com/ Mercurial Command line: Open source, distributed http://mercurial.selenic.com/ Windows GUI: http://tortoisehg.bitbucket.org/ SourceTree Mac/Win GUI: Not a source control system, http://www.sourcetreeapp.co just a GUI for Git and m/ Mercurial clients Revision Control Hosting SourceForge http://sourceforge.net/ git, mercurial, or subversion BitBucket https://bitbucket.org/ git or mercurial GitHub https://github.com/ git, has own (painful) GUI for Git 1 Image Editing MSPaint Windows, pre-installed Surprisingly useful quick pixel art editor (esp for prototypes) Paint.NET Windows, About as easy as MSPaint, but http://www.getpaint.net/download much more powerful .html Photoshop Mac, Windows New Media Center, 26-139 GIMP Many platforms, Easier than photoshop, at http://www.gimp.org/downloads/ least. Sound GarageBand Mac New Media Center, 26-139 Audacity Many platforms, Free, open source. http://audacity.sourceforge.ne -

Jenkins Job Builder Documentation Release 3.10.0
Jenkins Job Builder Documentation Release 3.10.0 Jenkins Job Builder Maintainers Aug 23, 2021 Contents 1 README 1 1.1 Developers................................................1 1.2 Writing a patch..............................................2 1.3 Unit Tests.................................................2 1.4 Installing without setup.py........................................2 2 Contents 5 2.1 Quick Start Guide............................................5 2.1.1 Use Case 1: Test a job definition................................5 2.1.2 Use Case 2: Updating Jenkins Jobs...............................5 2.1.3 Use Case 3: Working with JSON job definitions........................6 2.1.4 Use Case 4: Deleting a job...................................6 2.1.5 Use Case 5: Providing plugins info...............................6 2.2 Installation................................................6 2.2.1 Documentation.........................................7 2.2.2 Unit Tests............................................7 2.2.3 Test Coverage..........................................7 2.3 Configuration File............................................7 2.3.1 job_builder section.......................................8 2.3.2 jenkins section.........................................9 2.3.3 hipchat section.........................................9 2.3.4 stash section...........................................9 2.3.5 __future__ section.......................................9 2.4 Running.................................................9 2.4.1 Test Mode........................................... -

DVCS Or a New Way to Use Version Control Systems for Freebsd
Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions DVCS or a new way to use Version Control Systems for FreeBSD Ollivier ROBERT <[email protected]> BSDCan 2006 Ottawa, Canada May, 12-13th, 2006 Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions Agenda 1 Brief history of VCS 2 FreeBSD context & gures 3 Is Arch/baz suited for FreeBSD? 4 Mercurial to the rescue 5 New processes & policies needed 6 Conclusions Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions The ancestors: SCCS, RCS File-oriented Use a subdirectory to store deltas and metadata Use lock-based architecture Support shared developments through NFS (fragile) SCCS is proprietary (System V), RCS is Open Source a SCCS clone exists: CSSC You can have a central repository with symlinks (RCS) Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions CVS, the de facto VCS for the free world Initially written as shell wrappers over RCS then rewritten in C Centralised server Easy UI Use sandboxes to avoid locking Simple 3-way merges Can be replicated through CVSup or even rsync Extensive documentation (papers, websites, books) Free software and used everywhere (SourceForge for example) Ollivier ROBERT <[email protected]> DVCS or a new way to use Version Control Systems for FreeBSD Brief history of VCS FreeBSD context & gures Is Arch/baz suited for FreeBSD? Mercurial to the rescue New processes & policies needed Conclusions CVS annoyances and aws BUT.. -

Helix Authentication Service Administrator Guide 2021.1 May 2021 Copyright © 2020-2021 Perforce Software, Inc
Helix Authentication Service Administrator Guide 2021.1 May 2021 Copyright © 2020-2021 Perforce Software, Inc.. All rights reserved. All software and documentation of Perforce Software, Inc. is available from www.perforce.com. You can download and use Perforce programs, but you can not sell or redistribute them. You can download, print, copy, edit, and redistribute the documentation, but you can not sell it, or sell any documentation derived from it. You can not modify or attempt to reverse engineer the programs. This product is subject to U.S. export control laws and regulations including, but not limited to, the U.S. Export Administration Regulations, the International Traffic in Arms Regulation requirements, and all applicable end-use, end-user and destination restrictions. Licensee shall not permit, directly or indirectly, use of any Perforce technology in or by any U.S. embargoed country or otherwise in violation of any U.S. export control laws and regulations. Perforce programs and documents are available from our Web site as is. No warranty or support is provided. Warranties and support, along with higher capacity servers, are sold by Perforce. Perforce assumes no responsibility or liability for any errors or inaccuracies that might appear in this book. By downloading and using our programs and documents you agree to these terms. Perforce and Inter-File Branching are trademarks of Perforce. All other brands or product names are trademarks or registered trademarks of their respective companies or organizations. Contents How to use -

Coverity Static Analysis
Coverity Static Analysis Quickly find and fix Overview critical security and Coverity® gives you the speed, ease of use, accuracy, industry standards compliance, and quality issues as you scalability that you need to develop high-quality, secure applications. Coverity identifies code critical software quality defects and security vulnerabilities in code as it’s written, early in the development process when it’s least costly and easiest to fix. Precise actionable remediation advice and context-specific eLearning help your developers understand how to fix their prioritized issues quickly, without having to become security experts. Coverity Benefits seamlessly integrates automated security testing into your CI/CD pipelines and supports your existing development tools and workflows. Choose where and how to do your • Get improved visibility into development: on-premises or in the cloud with the Polaris Software Integrity Platform™ security risk. Cross-product (SaaS), a highly scalable, cloud-based application security platform. Coverity supports 22 reporting provides a holistic, more languages and over 70 frameworks and templates. complete view of a project’s risk using best-in-class AppSec tools. Coverity includes Rapid Scan, a fast, lightweight static analysis engine optimized • Deployment flexibility. You for cloud-native applications and Infrastructure-as-Code (IaC). Rapid Scan runs decide which set of projects to do automatically, without additional configuration, with every Coverity scan and can also AppSec testing for: on-premises be run as part of full CI builds with conventional scan completion times. Rapid Scan can or in the cloud. also be deployed as a standalone scan engine in Code Sight™ or via the command line • Shift security testing left. -

Teamcity 7.1 Documentation.Pdf
1. TeamCity Documentation . 4 1.1 What's New in TeamCity 7.1 . 5 1.2 What's New in TeamCity 7.0 . 14 1.3 Getting Started . 26 1.4 Concepts . 30 1.4.1 Agent Home Directory . 31 1.4.2 Agent Requirements . 32 1.4.3 Agent Work Directory . 32 1.4.4 Authentication Scheme . 33 1.4.5 Build Agent . 33 1.4.6 Build Artifact . 34 1.4.7 Build Chain . 35 1.4.8 Build Checkout Directory . 36 1.4.9 Build Configuration . 37 1.4.10 Build Configuration Template . 38 1.4.11 Build Grid . 39 1.4.12 Build History . 40 1.4.13 Build Log . 40 1.4.14 Build Number . 40 1.4.15 Build Queue . 40 1.4.16 Build Runner . 41 1.4.17 Build State . 41 1.4.18 Build Tag . 42 1.4.19 Build Working Directory . 43 1.4.20 Change . 43 1.4.21 Change State . 43 1.4.22 Clean Checkout . 44 1.4.23 Clean-Up . 45 1.4.24 Code Coverage . 46 1.4.25 Code Duplicates . 47 1.4.26 Code Inspection . 47 1.4.27 Continuous Integration . 47 1.4.28 Dependent Build . 47 1.4.29 Difference Viewer . 49 1.4.30 Guest User . 50 1.4.31 History Build . 51 1.4.32 Notifier . 51 1.4.33 Personal Build . 52 1.4.34 Pinned Build . 52 1.4.35 Pre-Tested (Delayed) Commit . 52 1.4.36 Project . 53 1.4.37 Remote Run . .. -

Perforce Tunables
Perforce Tunables Michael Shields Performance Lab Manager Perforce Software March, 2010 Abstract Tunables have been available in Perforce since the 2008.2 release. With help from Perforce, tunables can be used to modify some performance characteristics and limited changes to functionality. Though not strictly supported, Perforce would like to understand the effects of some of the tunables in customer environments. This paper discusses the importance of working with Perforce when considering the use of tunables. Also discussed is the mechanics of using tunables with the Perforce Server and clients. A strategy for implementing tunables is suggested. The tunables currently available are surveyed, detailing which might have an effect under what circumstances, and which should rarely be used and why. 1 Introduction Since the first releases of Perforce, there have been significant changes to both hardware and operating systems. Hardware typical of the mid-1990s included 167MHz UltraSPARC I or 166MHz Pentium processors, with perhaps a gigabyte or two of physical memory. Solaris 2.5 and Windows NT Server 3.51 were popular operating systems, and the Linux 2.0 kernel was first released in 1996. The hardware of the mid-1990s seems slow and small compared to current hardware consisting of several multi-core 3GHz Xeons or Opterons with tens or hundreds of gigabytes of physical memory. The performance of the Linux 2.6 kernel makes it a popular operating system on which to run today’s largest Perforce Servers. Perforce products have certainly evolved and improved since their first releases. Every Perforce release usually includes new features, enhancements, and performance improvements. -

Intellij IDEA, the Most Intelligent Java
IntelliJ IDEA, the most intelligent Java IDE IntelliJ IDEA, JetBrains’ flagship Java IDE, Every aspect of IntelliJ IDEA is specifically How does IntelliJ IDEA provides high-class support and productivity designed to maximize developer productiv- match up against competing tools? boosts for enterprise, mobile and web devel- ity. Together, powerful static code analysis opment in Java, Scala and Groovy, with all and ergonomic design make development Products versions in comparison the latest technologies and frameworks sup- a productive and enjoyable experience. ported out of the box. Compatibility with Operating systems Marketing / Market / Community comparison Community Comparison Platform More Information To learn more about the product, please visit our website at jetbrains.com/idea After IntelliJ IDEA has indexed your source languages and frameworks are at hand — IntelliJ IDEA is available in two editions: code, it ofers a blazingly fast and intelligent no plugin hustle included. While IntelliJ coding experience by giving relevant sug- IDEA is an IDE for Java, it also understands • Community Edition (free) gestions in every context: instant and clever and provides intelligent coding assistance • Ultimate Edition (paid) code completion, on-the-fly code analysis for a large variety of other languages such and reliable refactoring tools. Mission-critical as SQL, JPQL, HTML, JavaScript, and more, tools such as integration with version con- even when the language expression is inject- trols systems and a wide variety of supported ed into a String -

Live Upgrading Thousands of Servers from an Ancient Red Hat Distribution to 10 Year Newer Debian Based One Marc Merlin, Google, Inc
Live Upgrading Thousands of Servers from an Ancient Red Hat Distribution to 10 Year Newer Debian Based One Marc Merlin, Google, Inc. https://www.usenix.org/conference/lisa13/technical-sessions/papers/merlin This paper is included in the Proceedings of the 27th Large Installation System Administration Conference (LISA ’13). November 3–8, 2013 • Washington, D.C., USA ISBN 978-1-931971-05-8 Open access to the Proceedings of the 27th Large Installation System Administration Conference (LISA ’13) is sponsored by USENIX. Live upgrading thousands of servers from an ancient Red Hat distribution to 10 year newer Debian based one. Marc MERLIN Google, Inc. Abstract Google maintains many servers and employs a file level sync method with applications running in a different parti- tion than the base Linux distribution that boots the machine and interacts with hardware. This experience report first gives insights on how the distribution is setup, and then tackles the problem of doing a difficult upgrade from a Red Hat 7.1 image snapshot with layers of patches to a Debian Testing based distribution built from source. We will look at how this can actually be achieved as a live upgrade and without ending up with a long “flag day” where many machines are running totally different distributions, which would have made testing and debugging of appli- cations disastrous during a long switchover period. Like a coworker of mine put it, “It was basically akin to upgrading Red Hat 7.1 to Fedora Core 16, a totally unsup- ported and guaranteed to break upgrade, but also switching from rpm to dpkg in the process, and on live machines.” The end of the paper summarizes how we designed our packaging system for the new distribution, as well as how we build each new full distribution image from scratch in a few minutes. -
Azure Devops Server (TFS) / Azure Devops Services Plugin
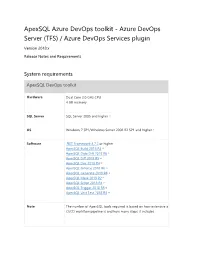
ApexSQL Azure DevOps toolkit - Azure DevOps Server (TFS) / Azure DevOps Services plugin Version 2018.x Release Notes and Requirements System requirements ApexSQL DevOps toolkit Hardware Dual Core 2.0 GHz CPU 4 GB memory SQL Server SQL Server 2005 and higher [1] OS Windows 7 SP1/Windows Server 2008 R2 SP1 and higher [1] Software .NET Framework 4.7.2 or higher ApexSQL Build 2018 R4 [3] ApexSQL Data Diff 2018 R6 [3] ApexSQL Diff 2018 R5 [3] ApexSQL Doc 2018 R4 [3] ApexSQL Enforce 2018 R6 [3] ApexSQL Generate 2018 R4 [3] ApexSQL Mask 2019 R2 [3] ApexSQL Script 2018 R4 [3] ApexSQL Trigger 2018 R3 [3] ApexSQL Unit Test 2018 R4 [3] Note The number of ApexSQL tools required is based on how extensive a CI/CD workflow pipeline is and how many steps it includes Source control integration available for Azure DevOps [4], Git [5], Mercurial [5], Subversion [5] and Perforce [5] Permissions and Windows user account with administrative privileges additional requirements See Minimum permissions required to install and use ApexSQL products See Minimum SQL Server permissions for ApexSQL Developer tools See Remote access for SQL Server instance See How to setup image based database provisioning Azure DevOps Server (TFS) / Azure DevOps Services plug-in Hardware 214 KB disk space Software TFS 2015 Update 2 or higher, Azure DevOps Services Bamboo plug-in Hardware 1.65 MB disk space Software Atlassian Bamboo 6.6.3 or higher Jenkins plugin Hardware 5.8 MB disk space Software Jenkins 2.138 or higher Octopus Deploy step templates Hardware 32 KB disk space Software -

Helix Core Vs. Microsoft TFS/TFVC
VS COMPARISON Helix Core vs. Microsoft TFS/TFVC In this document, we will compare Perforce Helix Core to Microsoft Team Foundation Server (TFS.) Specifically, we will look at the TFVC (Team Foundation Version Control) functionality. With TFVC, your code is kept on the TFS server, usually on-premises. Developers often work in the popular Microsoft Visual Studio application on their own Windows workstation. They connect to the TFVC server to collaborate with other developers. Changes in the Microsoft World When TFS version control originally shipped, it was What’s more important? Winning the hearts and exclusively an on-premises solution – Visual Studio minds of some 31 million+ GitHub users, and keep- 2005 Team System. Since then, of course, Microsoft ing them away from the very popular AWS cloud. has made regularly made significant updates. Because Microsoft’s new Azure and Git strategy is In 2016, Microsoft released a cloud-based service, so different from the way TFS and TFVC users work Visual Studio Team Services (VSTS). This marked a today, teams have a big decision looming. Should they different direction for TFS on-premises customers. move to the cloud and embrace Microsoft’s DevOps More recently, VSTS has been rebranded as Azure pipelines and other Azure-based technologies? Or DevOps, with a variety of developer tools available should they choose another VCS that will work on- on Microsoft’s Azure cloud platform. Although Azure premises and deliver on their DevOps priorities? DevOps continues to provide support for TFVC Microsoft will continue mainstream support of TFS repositories, the Microsoft vision has a new iteration. -

Solving the Source Control Issue David Shannon, Amadeus Software Limited
Solving the Source Control Issue David Shannon, Amadeus Software Limited ABSTRACT The administration of SAS code frequently depends on the file management and good practice of the individual developer. When many people share the same SAS programs it is likely a conflict or unintentional loss of code will occur. Source Control systems are designed to manage access, versions and the history of files. This paper presents a review of source control systems that are already available, or can be used, within the SAS environment. The discussion begins by understanding what is meant by the terms Source Control and Version Control. Methods of working with source control are discussed. Finally the existing capabilities of Data Integration Studio and Drug Development solutions are presented. This paper on “Solving the Source Control Issue” is appropriate for those who program SAS, maintain SAS code or are responsible for the long term security and availability of SAS programs. An understanding of the SAS programming language is not required. INTRODUCTION Source Control is a subject area quite familiar to software developers where the need to support many developers concurrently is a prerequisite. For the majority of SAS programmers this process is either separate from the programming environment or not performed at all. The need to maintain professional source control is increasingly recognised by organisations that fall under regulatory jurisdiction. Typical examples are the financial industry and the development and production of medicines and devices in the life sciences industries. Furthermore, organisations following ISO 9000 standards will require source control. Source control in SAS programming environments is usually managed through separate tools or functions from the SAS Display Manager or Enterprise Guide.