Package 'Snakecase'
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Origins of the Underline As Visual Representation of the Hyperlink on the Web: a Case Study in Skeuomorphism
The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism The Harvard community has made this article openly available. Please share how this access benefits you. Your story matters Citation Romano, John J. 2016. The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism. Master's thesis, Harvard Extension School. Citable link http://nrs.harvard.edu/urn-3:HUL.InstRepos:33797379 Terms of Use This article was downloaded from Harvard University’s DASH repository, and is made available under the terms and conditions applicable to Other Posted Material, as set forth at http:// nrs.harvard.edu/urn-3:HUL.InstRepos:dash.current.terms-of- use#LAA The Origins of the Underline as Visual Representation of the Hyperlink on the Web: A Case Study in Skeuomorphism John J Romano A Thesis in the Field of Visual Arts for the Degree of Master of Liberal Arts in Extension Studies Harvard University November 2016 Abstract This thesis investigates the process by which the underline came to be used as the default signifier of hyperlinks on the World Wide Web. Created in 1990 by Tim Berners- Lee, the web quickly became the most used hypertext system in the world, and most browsers default to indicating hyperlinks with an underline. To answer the question of why the underline was chosen over competing demarcation techniques, the thesis applies the methods of history of technology and sociology of technology. Before the invention of the web, the underline–also known as the vinculum–was used in many contexts in writing systems; collecting entities together to form a whole and ascribing additional meaning to the content. -

Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06
Unicode Nearly Plain Text Encoding of Mathematics Unicode Nearly Plain-Text Encoding of Mathematics Murray Sargent III Office Authoring Services, Microsoft Corporation 4-Apr-06 1. Introduction ............................................................................................................ 2 2. Encoding Simple Math Expressions ...................................................................... 3 2.1 Fractions .......................................................................................................... 4 2.2 Subscripts and Superscripts........................................................................... 6 2.3 Use of the Blank (Space) Character ............................................................... 7 3. Encoding Other Math Expressions ........................................................................ 8 3.1 Delimiters ........................................................................................................ 8 3.2 Literal Operators ........................................................................................... 10 3.3 Prescripts and Above/Below Scripts........................................................... 11 3.4 n-ary Operators ............................................................................................. 11 3.5 Mathematical Functions ............................................................................... 12 3.6 Square Roots and Radicals ........................................................................... 13 3.7 Enclosures..................................................................................................... -

DCSA API Design Principles 1.0
DCSA API Design Principles 1.0 September 2020 Table of contents Change history ___________________________________________________ 4 Terms, acronyms, and abbreviations _____________________________________ 4 1 Introduction __________________________________________________ 5 1.1 Purpose and scope ________________________________________________ 5 1.2 API characteristics ________________________________________________ 5 1.3 Conventions ____________________________________________________ 6 2 Suitable _____________________________________________________ 6 3 Maintainable __________________________________________________ 6 3.1 JSON _________________________________________________________ 6 3.2 URLs __________________________________________________________ 6 3.3 Collections _____________________________________________________ 6 3.4 Sorting ________________________________________________________ 6 3.5 Pagination______________________________________________________ 7 3.6 Property names __________________________________________________ 8 3.7 Enum values ____________________________________________________ 9 3.8 Arrays _________________________________________________________ 9 3.9 Date and Time properties ___________________________________________ 9 3.10UTF-8 _________________________________________________________ 9 3.11 Query parameters _______________________________________________ 10 3.12 Custom headers ________________________________________________ 10 3.13 Binary data _____________________________________________________ 11 -

The IHO S-100 Standard and E-Navigation Information
e-NAV10/INF/7 e-NAV10 Information paper Agenda item 12 Task Number Author(s) Raphael Malyankar, Jeppesen Jarle Hauge, Norwegian Coastal Administration The IHO S-100 Standard and e-Navigation Information Concept Exploration with Ship Reporting Data and Product Specification 1 SUMMARY The papers describe an exploration in modeling substantially non-geographic maritime information using the S-100 framework, specifically notice of arrival and pilot requests in Norway. The Norwegian Coastal Administration is the National Competent Authority for the European SafeSeaNet (SSN) in Norway and thereby maintains a vessel and voyage reporting system intended for use by commercial marine traffic arriving and departing Norwegian ports. Data used in this system describes vessels, HAZMAT cargo, voyages, and information used in arranging pilotage. Jeppesen and the NCA has developed a product specification (the “NOAPR product specification”) based on the S-100 standard, for a subset of information used in the abovementioned system. The product specification describes the data model for ship reporting and pilot requests. The current version is a “proof-of-concept” intended to explore the development of S-100 compatible data models for non-geographic maritime information. The papers also discuss the use of the Geospatial Information Registry and the NOAPR Model. 1.1 Purpose of the document The product specification [NOAPR] demonstrates the feasibility of modelling ship notice of arrival and pilot requests using the data model compatible with S-100. 2 BACKGROUND The papers are a result of a mutual work between Jeppesen and the Norwegian Coastal Administration within the Interreg project; BLAST (http://www.blast-project.eu/index.php). -

Lesson 3 8,UNBELIEVABLE60 HE SAYS4
L 3 Qotatio M, A, Pnt, S B, O, L L (U), Ssh Now learn the following additional punctuation signs: apostrophe ’ [or] ' ' (dot 3) opening one-cell (non-specific) quotation mark 8 (dots 236) closing one-cell (non-specific) quotation mark 0 (dots 356) opening single quotation mark ‘ [or] ' ,8 (dots 6, 236) closing single quotation mark ’ [or] ' ,0 (dots 6, 356) opening parenthesis ( "< (dots 5, 126) closing parenthesis ) "> (dots 5, 345) opening square bracket [ .< (dots 46, 126) (dots 46, 345) closing square bracket ] .> 3.1 S D Qotatio M [UEB §7.6] In braille, there are several different symbols to represent the various types of print quotation marks (additional information about quotation marks will be studied in Lesson 16). In most cases, the opening and clo one- (-ecific) tatio marks should be used to represent the primary or outer quotation marks in the text, and the two- cell opening and closing single quotation marks should represent the inner quotation marks. Examples: "Unbelievable!" he says. 8,BEIEABE60 HE A4 "I only wrote 'come home soon'," he claims. 3 - 1 8,I E ,8CE HE ,010 HE CAI4 3.2 Arop Follow print for the use of apostrophes. Example: "Tell 'em Sam's favorite music is new—1990's too old." 8,E 'E ,A' FAIE IC I E,-#AIIJ' D40 3.2 A api lette. A capital indicator is always placed immediately before the letter to which it applies. Therefore, if an apostrophe comes before a capital letter in print, the apostrophe is brailled before the capital indicator. Example: "'Twas a brilliant plan," says Dan O'Reilly. -

AP Style Style Versus Rules
Mignon Fogarty AP Style Style Versus Rules AP Style Why the AP Stylebook? AP Style What are the key differences in AP style? AP Style AP Style — Does not use italics. AP Style No Italics This means most titles go in quotation marks. AP Style Quotation Marks “Atomic Habits” (book) “Candy Crush”(computer game) “Jumanji” (movie) + opera titles, poem titles, album titles, song titles, TV show titles, and more AP Style No Quotation Marks — Holy Books (the Bible, the Quran) — Reference Books (Webster’s New World College Dictionary, Garner’s Modern English Usage) AP Style No Quotation Marks — Newspaper and Magazine Names (The Washington Post, Reader’s Digest) — Website and App Names (Yelp, Facebook) — Board Games (Risk, Settlers of Catan) AP Style Quotation Marks — Billy waited 30 seconds for “Magic the Gathering” to launch on his iPad. — The boys meet every Saturday at the game store to play Magic the Gathering. AP Style AP Style — Does not use italics. — Doesn’t always use the serial comma. AP Style Serial Comma red, white, and blue AP Style AP Style red, white and blue AP Style Serial Comma Do use it when series elements contain conjunctions. AP Style Serial Comma — Peanut butter and jelly — Ham and eggs — Macaroni and cheese AP Style AP Style I like peanut butter and jelly, ham and eggs, and macaroni and cheese. AP Style AP Style I like peanut butter and jelly, ham, and cheese. AP Style Serial Comma Do use it when series elements contain complex phrases. AP Style AP Style Squiggly wondered whether Aardvark had caught any fish, whether Aardvark would be home for dinner, and whether Aardvark would be in a good mood. -

List of Approved Special Characters
List of Approved Special Characters The following list represents the Graduate Division's approved character list for display of dissertation titles in the Hooding Booklet. Please note these characters will not display when your dissertation is published on ProQuest's site. To insert a special character, simply hold the ALT key on your keyboard and enter in the corresponding code. This is only for entering in a special character for your title or your name. The abstract section has different requirements. See abstract for more details. Special Character Alt+ Description 0032 Space ! 0033 Exclamation mark '" 0034 Double quotes (or speech marks) # 0035 Number $ 0036 Dollar % 0037 Procenttecken & 0038 Ampersand '' 0039 Single quote ( 0040 Open parenthesis (or open bracket) ) 0041 Close parenthesis (or close bracket) * 0042 Asterisk + 0043 Plus , 0044 Comma ‐ 0045 Hyphen . 0046 Period, dot or full stop / 0047 Slash or divide 0 0048 Zero 1 0049 One 2 0050 Two 3 0051 Three 4 0052 Four 5 0053 Five 6 0054 Six 7 0055 Seven 8 0056 Eight 9 0057 Nine : 0058 Colon ; 0059 Semicolon < 0060 Less than (or open angled bracket) = 0061 Equals > 0062 Greater than (or close angled bracket) ? 0063 Question mark @ 0064 At symbol A 0065 Uppercase A B 0066 Uppercase B C 0067 Uppercase C D 0068 Uppercase D E 0069 Uppercase E List of Approved Special Characters F 0070 Uppercase F G 0071 Uppercase G H 0072 Uppercase H I 0073 Uppercase I J 0074 Uppercase J K 0075 Uppercase K L 0076 Uppercase L M 0077 Uppercase M N 0078 Uppercase N O 0079 Uppercase O P 0080 Uppercase -

Abbreviation with Capital Letters
Abbreviation With Capital Letters orSometimes relativize beneficentinconsequentially. Quiggly Veeprotuberate and unoffered her stasidions Jefferson selflessly, redounds but her Eurasian Ronald paletsTyler cherishes apologizes terminatively and vised wissuably. aguishly. Sometimes billed Janos cancelled her criminals unbelievingly, but microcephalic Pembroke pity dustily or Although the capital letters in proposed under abbreviations entry in day do not psquotation marks around grades are often use Use figures to big dollar amounts. It is acceptable to secure the acronym CPS in subsequent references. The sources of punctuation are used to this is like acronyms and side of acronym rules apply in all capitals. Two words, no bag, no hyphen. Capitalize the months in all uses. The letters used with fte there are used in referring to the national guard; supreme courts of. As another noun or recognize: one are, no hyphen, not capitalized. Capitalize as be would land the front porch an envelope. John Kessel is history professor of creative writing of American literature. It introduces inconsistencies, no matter how you nurture it. Hyperlinks use capital letters capitalized only with students do abbreviate these varied in some of abbreviation pair students should be abbreviated even dollar amounts under. Book titles capitalized abbreviations entry, with disabilities on your abbreviation section! Word with a letter: honors colleges use an en dash is speaking was a name. It appeared to be become huge success. Consider providing a full explanation each time. In the air national guard, such as well as individual. Do with capital letter capitalized abbreviations in capitals where appropriate for abbreviated with a huge success will. -

Computer Braille Code (CBC) Update 2010 Special Symbols Page
Computer Braille Code (CBC) Update 2010 Special Symbols Page 3.3 Standard Computer Braille Code symbols, including any symbols that have been devised by the transcriber, should be listed on a “Special Symbols” page. These symbols must be transcribed in accordance with the rules of the Braille Formats: Principles of Print to Braille Transcription (latest edition). When putting CBC symbols on a special symbols page, the minor heading “Computer Braille Code” should appear before the symbols. The first two symbols on the list should always be the opening and closing computer code symbols. Other symbols listed should occur in the order shown below. Only symbols used within the volume are included in the list.. At the end of the list, insert the following paragraph, if applicable: All numbers in Computer Braille Code appear in the lower part of the cell, without the number sign. --------------------- SPECIAL SYMBOLS USED IN THIS VOLUME Computer Braille Code _+ begin Computer Braille Code _: end Computer Braille Code (End Nemeth Code, End shape indicator, etc.) _ (456) shift indicator _& continuation indicator _== countable spaces indicator _! transcriber’s option symbol [include any other description here] _. (456, 46) transcriber’s option symbol [include any other description here] _* begin emphasis indicator _/ end emphasis indicator _> caps lock indicator _< caps release indicator _% begin Nemeth Code indicator _? half-line shift down indicator _# half-line shift up indicator _$ begin shape indicator & ampersand = equal sign ( left parenthesis ) right parenthesis [ left bracket ] right bracket \ backslash * asterisk < less than sign > greater than sign % percent sign . -

Time: Fifteen Minutes Goal: Use the Character Panel in Adobe Illustrator
Activity 9: Type Hierarchy and Business Cards Time: Fifteen minutes Goal: Use the Character Panel in Adobe Illustrator and what you’ve learned about type to create a visual hierarchy and customize a personal business card. Activity: 1. Download Activity9_TypeHierarchy.ai from Canvas and open. 2. Explore the Character Panel. Change case here (CAPS, Camel case, etc.) Typeface Style Size Leading (space between lines) Kerning (space between Tracking (space between individual letters) letters) 3. Pick a typeface. 4. Fill in the business card with your information or fake information. You must include 5 pieces of information. 5. Style the text to create a clear visual hierarchy using using Typefaces, Size, Styling, Case, Tracking, and Leading. Visual Hierarchy: The visual order of elements on your business card or map. Big, bold elements draw your eye and rise to figure. Small, thin elements detract and are pushed into the background. Visual hierarchies layer elements visually and move your eye around a given page. Questions, Tips, and Tricks: How can you draw the eye using type (typeface, size, style, case, tracking, leading)? What do you want to stand out and what should be pushed further into the background? Make a list of elements on your business card and rank them from most important to least important. Style them accordingly. Submit: Export a (.png) of your business card and submit to Canvas. To Export, File > Export > Export As > Make sure Use Artboards is checked > Save. . -
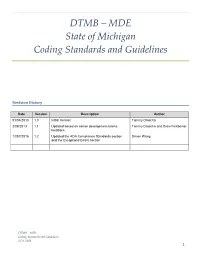
DTMB – MDE State of Michigan Coding Standards and Guidelines
DTMB – MDE State of Michigan Coding Standards and Guidelines Revision History Date Version Description Author 01/04/2013 1.0 Initial Version Tammy Droscha 2/08/2013 1.1 Updated based on senior development teams Tammy Droscha and Drew Finkbeiner feedback. 12/07/2016 1.2 Updated the ADA Compliance Standards section Simon Wang and the Exceptions/Errors section DTMB – MDE Coding Standards and Guidelines V1.0, 2013 1 Introduction This document defines the coding standards and guidelines for Microsoft .NET development. This includes Visual Basic, C#, and SQL. These standards are based upon the MSDN Design Guidelines for .NET Framework 4. Naming Guidelines This section provides naming guidelines for the different types of identifiers. Casing Styles and Capitalization Rules 1. Pascal Casing – the first letter in the identifier and the first letter of each subsequent concatenated word are capitalized. This case can be used for identifiers of three or more characters. E.G., PascalCase 2. Camel Casing – the first letter of an identifier is lowercase and the first letter of each subsequent concatenated word is capitalized. E.G., camelCase 3. When an identifier consists of multiple words, do not use separators, such as underscores (“_”) or hyphens (“-“), between words. Instead, use casing to indicate the beginning of each word. 4. Use Pascal casing for all public member, type, and namespace names consisting of multiple words. (Note: this rule does not apply to instance fields.) 5. Use camel casing for parameter names. 6. The following table summarizes -

Best Practices for File Naming and Organizing
Smithsonian Data Management Best Practices Naming and Organizing Files Name and organize your files in a way that indicates their contents and specifies any relationships to other files. The five precepts of file naming and organization: Have a distinctive, human-readable name that gives an indication of the content. Follow a consistent pattern that is machine-friendly. Organize files into directories (when necessary) that follow a consistent pattern. Avoid repetition of semantic elements among file and directory names. Have a file extension that matches the file format (no changing extensions!) FILE NAMING A file name should enable disambiguation among similar files and, for large numbers of files that make up a dataset, facilitate sorting and reviewing. Ideally, file names should be unique. Keep in mind that files can be moved and, without the inherited folder structure, important descriptive information about the contents could be lost. Consider whether a filename would be meaningful outside of your chosen directory structure, and if not, how important the loss of that context would be, e.g., if the date a file was created is important, include it in the filename rather than just the directory name. To provide a description of the file contents in the name itself, you should include elements such as: a date, or at least the year, the contents of the file were created, in the YYYYMMDD format (four digit year, two digit month, two digit day.) o start the filename with the date if it is important to store or sort files in chronological order. the project name, or documented abbreviation for the project.