Footprints of Antigen Processing Boost MHC Class II Natural Ligand
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Antigen Presentation by Dendritic Cells and Their Significance in Antineoplastic Immunotherapy
in vivo 18: 81-100 (2004) Antigen Presentation by Dendritic Cells and their Significance in Antineoplastic Immunotherapy BELA BODEY1,2, STUART E. SIEGEL1,2 and HANS E. KAISER3 1Department of Pathology, Keck School of Medicine, University of Southern California, Los Angeles, CA; 2Childrens’ Center for Cancer and Blood Diseases, Childrens’ Hospital Los Angeles, Los Angeles, CA; 3Department of Pathology, School of Medicine, University of Maryland, Baltimore, MD, U.S.A. and Department of General and Experimental Pathology, University of Vienna, Vienna, Austria Abstract. Dendritic cells (DCs) are present in essentially every derived peptides on the surface of major histocompatibility mammalian tissue, where they operate at the interface of innate complex (MHC) molecules and acquire the cellular specialization and acquired immunity by recognizing pathogens and presenting to select and activate naive antigen-specific T lymphocytes. pathogen-derived peptides to T lymphocytes. According to the Immunotherapeutic ideas are based on the ability of the research group of Shortman (1-9), experimental results suggest a mammalian immune system to recognize neoplastically "dual" DC differentiation model, demonstrating the existence of transformed cells. Immunotherapy of human neoplasms has both myeloid-derived (with characteristic IF: CD11b+, CD11c+, always represented a very attractive fourth-modality therapeutic CD8alpha- and DEC205+) and lymphoid-derived DCs (showing approach, especially in light of the many shortcomings of CD11b-, CD11c-, CD8alpha+ and DEC205+ IF). DCs, including conventional surgical, radiation and chemotherapies in the interdigitating cells (IDCs) and Langerhans cells (LCs), are management of neoplastically transformed cells. The cancer characterized by dendritic morphology, high migratory mobility and vaccine approach to therapy is based on the notion that the are the most effective, "professional" cells for antigen presentation immune system could possibly mount a rejection strength response in primary immune responses. -

Antigen Processing (Major Hbitocompatlbility Complex/Class I Moecules/Lymphokines) YOUNG YANG, JAMES B
Proc. Nati. Acad. Sci. USA Vol. 89, pp. 4928-4932, June 1992 Immunology Proteasomes are regulated by interferon y: Implications for antigen processing (major hbitocompatlbility complex/class I moecules/lymphokines) YOUNG YANG, JAMES B. WATERS, KLAUS FROH, AND PER A. PETERSON Department of Immunology, The Scripps Research Institute, La Jolla, CA 92037 Communicated by Frank J. Dixon, February 27, 1992 ABSTRACT Class I major histocompatibility complex strengthened by the findings, presented in this communica- (MHC) molecules present antigenic peptides of cytoplasmic tion, that several proteasomal subunits, including MHC- origin to T cells. As the lengths ofthese peptides seem stried encoded subunits, are regulated by interferon y (IFN--y) and to eight or nine amino acids, an unusual proteolytic system that the incorporation of several more subunits into protea- must play a role in antigen processing. Proteasomes, a major somes appears to depend on the expression of the MHC- extralysosomal proteolytic system, are responsible for the encoded proteasomal subunits. Moreover, the pattern of degradation of cytoplasmic proteins. We demonstrate that expression of IFN-y-regulated subunits suggests complexi- several proteasomal subunits, including MHC-encoded sub- ties in the regulation of proteasomes with respect to its units, are regulated by interferon y. These data and the finding subunit composition, subcellular localization, and its incor- that MHC-encoded and other interferon -regulated protea- poration into larger ubiquitin-related proteolytic complexes. somal subunits are uniquely associated with proteasomes Possible functions for the MHC-encoded and IFN-y- strongly suggest that the immune system has recruited protea- regulated proteasomal subunits in antigen processing are somes for antigen processing. -

Cytoplasmic Proteolysis Antigens on MHC Class II Is Dependent On
Efficient Presentation of Both Cytosolic and Endogenous Transmembrane Protein Antigens on MHC Class II Is Dependent on Cytoplasmic Proteolysis This information is current as of September 28, 2021. Paushali Mukherjee, Aadish Dani, Sumeena Bhatia, Nagendra Singh, Alexander Y. Rudensky, Anna George, Vineeta Bal, Satyajit Mayor and Satyajit Rath J Immunol 2001; 167:2632-2641; ; doi: 10.4049/jimmunol.167.5.2632 Downloaded from http://www.jimmunol.org/content/167/5/2632 References This article cites 51 articles, 20 of which you can access for free at: http://www.jimmunol.org/content/167/5/2632.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists by guest on September 28, 2021 • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2001 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. Efficient Presentation of Both Cytosolic and Endogenous Transmembrane Protein Antigens on MHC Class II Is Dependent on Cytoplasmic Proteolysis1 Paushali Mukherjee,* Aadish Dani,† Sumeena Bhatia,* Nagendra Singh,* Alexander Y. -

1 ICAM3-Fc Outperforms Receptor-Specific Antibodies
Preprints (www.preprints.org) | NOT PEER-REVIEWED | Posted: 10 April 2019 doi:10.20944/preprints201904.0118.v1 Peer-reviewed version available at Molecules 2019, 24, 1825; doi:10.3390/molecules24091825 ICAM3-Fc outperforms receptor-specific antibodies targeted nanoparticles to dendritic cells for cross-presentation Luis J. Cruz,1* Paul J. Tacken,2 Johan S. van der Schoot,2 Felix Rueda,3 Ruurd Torensma,2 Carl G. Figdor2* 1Translational Nanobiomaterials and Imaging, Department of Radiology, Leiden University Medical Center, Albinusdreef 2, 2333 ZA Leiden, The Netherlands. 2Department of Tumor Immunology, Radboud Insititute for Molecular Life Sciences, Radboud University Medical Center, Postbox 9101, 6500 HB Nijmegen, The Netherlands. 3Department of Biochemistry and Molecular Biology, University of Barcelona, Diagonal 643, 08028 Barcelona, Spain. Running title: ICAM3-Fc- versus antibody-targeted NP vaccines to human DCs Keywords: Delivery system; nanoparticle; targeting. AUTHOR INFORMATION Corresponding Author *Dr. Luis J. Cruz Translational Nanobiomaterials and Imaging, Department of Radiology, Bldg.1, C5-60. Leiden University Medical Center, Albinusdreef 2 2333 ZA Leiden, The Netherlands Tel: +31 71 5263025 Email: [email protected] *Prof. Dr. Carl G. Figdor Department of Tumor Immunology, Nijmegen Centre for Molecular Life Sciences, Radboud University Nijmegen Medical Centre, Postbox 9101, 6500 HB Nijmegen, The Netherlands. Fax: +31-24-3540339; Tel.: +31-24-3617600; E-mail: [email protected] 1 © 2019 by the author(s). Distributed -
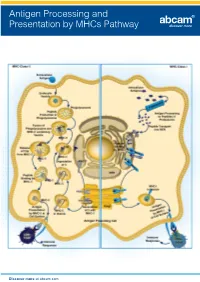
Antigen Processing and Presentation by Mhcs Pathway
Antigen Processing and Presentation by MHCs Pathway Discover more at abcam.com Antigen Processing and Presentation by MHCs Pathway Related antibodies Product This image shows MHC Class II highlights Product Clonality Applications Host Species Reactivity Product code expressing cells in formalin fixed and paraffin embedded human lymph MHC class I antibody [EP1395Y] M Flow Cyt, ICC/IF, IHC-P, IP, WB Rb Hu, Ms, Rat 52922 node, using ab55152. MHC class I antibody [AF6-88.5.5.3] (Biotin) M Flow Cyt Ms Ms 93528 MHC Class II antibody MHC class I antibody [34-1-2S] (FITC) M Flow Cyt Ms Ms 95572 (ab55152) MHC class I antibody [34-1-2S] (Phycoerythrin) M Flow Cyt Ms Ms 95571 MHC Class I alpha antibody [F21-2] M AP, Flow Cyt, IP, WB Ms Chk 23483 Clonality Applications MHC Class 1 H2 Db antibody [27-11-13] - BSA and Azide free M Flow Cyt, FuncS, IHC-Fr Ms Ms 25244 M IHC-P, WB MHC Class 1 H2 Db antibody [28-14-8] (FITC) M Flow Cyt Ms Ms 25056 Host Species cross reactivity MHC Class 1 H2 Db antibody [KH95] M Flow Cyt, FuncS, WB Ms Ms 64373 Ms Hu, RecFrag MHC Class I H2 Dd antibody [34-2-12] M Flow Cyt, FuncS, IHC-Fr, IP Ms Ms 64368 MHC Class I H2 Dk antibody [15-5-5.3] M Flow Cyt Ms Ms 25216 MHC Class II antigens are a valuable tool for studying T helper cell interactions with class II MHC Class I H2 Kb antibody P ELISA, WB Rb Ms 93364 positive antigen presenting cells, as well as the MHC Class I H2 Kd + Dd + q + u + v antibody [1.B.552] (FITC) M Flow Cyt, IP Ms Ms 62228 development of T helper cells since the antigen is present on stromal cells in the thymus. -

Class II MHC Cytoplasmic Domain-Mediated Signaling in B Cells a Tail of Two Signals
Human Immunology 80 (2019) 32–36 Contents lists available at ScienceDirect Human Immunology journal homepage: www.elsevier.com/locate/humimm Class II MHC cytoplasmic domain-mediated signaling in B cells: A tail of two T signals Jonathan A. Harton Department of Immunology & Microbial Disease, Albany Medical College, 47 New Scotland Avenue, MC-151, Albany, NY 12208, USA ARTICLE INFO ABSTRACT Keywords: In addition to their role in antigen presentation, class II MHC molecules also transmit signals to B lymphocytes. MHC class II Class II MHC-mediated signals initiate a range of events in B cells, including induction of cell surface proteins, HLA-D initiation of cell-cycle progression/proliferation, activation of or protection from apoptosis, and antigen-de- Signaling pendent plasma cell differentiation. Although various transmembrane signaling proteins associate with classII B cells MHC molecules, the class II MHC cytoplasmic domains are essential for signals leading to increased intracellular cAMP and activation of protein kinase C (PKC). Although truncation and mutagenesis studies have provided considerable information about the cytoplasmic domain sequences required, how class II MHC molecules elicit cAMP and PKC activation is not known. Further, appropriate T-dependent B cell responses require intact cAMP and PKC signaling, but the extent to which class II MHC signals are involved is also unknown. This review details our current knowledge of class II MHC cytoplasmic domain signaling in B cells with an emphasis on the likely importance of class II MHC signals for T-dependent antibody responses. 1. Introduction complex, is only found on CD4+ T cells which are dependent upon thymic MHC class II for their development. -

Cell Biology from an Immune Perspective in This Lecture We Will
Harvard-MIT Division of Health Sciences and Technology HST.176: Cellular and Molecular Immunology Course Director: Dr. Shiv Pillai Cell Biology from an Immune Perspective In this lecture we will very briefly review some aspects of cell biology which are required as background knowledge in order to understand how the immune system works. These will include: 1. A brief overview of protein trafficking 2. Signal transduction 3. The cell cycle Some of these issues will be treated in greater depth in later lectures. Protein Trafficking/The Secretory Pathway: From an immune perspective the secretory compartment and structures enclosed by vesicles are “seen” in different ways from proteins that reside in the cytosol or the nucleus. We will briefly review the secretory and endocytic pathways and discuss the biogenesis of membrane proteins. Some of the issues that will be discussed are summarized in Figures 1-3. Early endosomes Late endosomes Lysosomes Golgi Vesiculo-Tubular Compartment ER Figure 1. An overview of the secretory pathway Early endosomes Late endosomes Multivesicular and multilamellar bodies Golgi ER Proteasomes Figure 2. Protein degradation occurs mainly in lysosomes and proteasomes Proteins that enter the cell from the environment are primarily degraded in lysosomes. Most cytosolic and nuclear proteins are degraded in organelles called proteasomes. Intriguingly these two sites of degradation are each functionally linked to distinct antigen presentation pathways, different kinds of MHC molecules and the activation of different categories of T cells. Integral membrane proteins maybe inserted into the membrane in a number of ways, the two most common of these ways being considered in Figure 3. -

Mechanisms of HIV Protein Degradation Into Epitopes: Implications for Vaccine Design
Viruses 2014, 6, 3271-3292; doi:10.3390/v6083271 OPEN ACCESS viruses ISSN 1999-4915 www.mdpi.com/journal/viruses Review Mechanisms of HIV Protein Degradation into Epitopes: Implications for Vaccine Design Marijana Rucevic †, Julie Boucau †, Jens Dinter †, Georgio Kourjian † and Sylvie Le Gall * Ragon Institute of MGH, MIT and Harvard, Massachusetts General Hospital and Harvard Medical School, Cambridge, MA 02139, USA; E-Mails: [email protected] (M.R.); [email protected] (J.B.); [email protected] (J.D.); [email protected] (G.K.) † These authors contributed equally to this work. * Author to whom correspondence should be addressed; E-Mail: [email protected]; Tel.: +1-857-268-7010. Received: 11 June 2014; in revised form: 6 August 2014 / Accepted: 11 August 2014 / Published: 21 August 2014 Abstract: The degradation of HIV-derived proteins into epitopes displayed by MHC-I or MHC-II are the first events leading to the priming of HIV-specific immune responses and to the recognition of infected cells. Despite a wealth of information about peptidases involved in protein degradation, our knowledge of epitope presentation during HIV infection remains limited. Here we review current data on HIV protein degradation linking epitope production and immunodominance, viral evolution and impaired epitope presentation. We propose that an in-depth understanding of HIV antigen processing and presentation in relevant primary cells could be exploited to identify signatures leading to efficient or inefficient epitope presentation in HIV proteomes, and to improve the design of immunogens eliciting immune responses efficiently recognizing all infected cells. Keywords: HIV; antigen processing; protein degradation; proteasome; aminopeptidase; peptidase; immunogen; vaccine vector; dendritic cells; T cells; viral evolution Viruses 2014, 6 3272 1. -

MHC Class II Stabilization at the Surface of Human Dendritic Cells Is the Result of Maturation-Dependent MARCH I Down-Regulation
MHC class II stabilization at the surface of human dendritic cells is the result of maturation-dependent MARCH I down-regulation Aude De Gassart*†‡, Voahirana Camosseto*†‡, Jacques Thibodeau§¶, Maurizio Ceppi*†‡, Nadia Catalan*†‡, Philippe Pierre*†‡ʈ, and Evelina Gatti*†‡ʈ *Centre d’Immunologie de Marseille–Luminy, Universite´ delaMe´ diterrane´e, Case 906, 13288 Marseille Cedex 9, France; †Institut National de la Sante´etde la Recherche Me´dicale, Unite´631, 13288 Marseille, France; ‡Centre National de la Recherche Scientifique, Unite´Mixte de Recherche 6102, 13288 Marseille, France; §De´partement de Microbiologie et Immunologie, Universite´de Montre´al, Montreal, QC, Canada H3T 1J4; and ¶Institut National de la Sante´et de la Recherche Me´dicale, Unite´743, Montreal, QC, Canada H3T 1J4 Edited by Ralph M. Steinman, The Rockefeller University, New York, NY, and approved January 9, 2008 (received for review September 19, 2007) In response to Toll-like receptor ligands, dendritic cells (DCs) dramatically when cells are exposed to LPS (12, 13). As determined dramatically enhance their antigen presentation capacity by sta- by confocal microscopy, iDCs accumulate HLA-DR molecules in bilizing at the cell-surface MHC II molecules. We demonstrate here LAMP1ϩ late endosomes and lysosomes. On activation by LPS, that, in human monocyte-derived DCs, the RING-CH ubiquitin E3 rapid relocalization of MHC II to the cell surface is observed (4–8 ligase, membrane-associated RING-CH I (MARCH I), promotes the h) [supporting information (SI) Fig. 7A]. Recently, this process has ubiquitination of the HLA-DR -chain. Thus, in nonactivated DCs, been shown to be associated with a loss of ubiquitination on the MARCH I induces the surface internalization of mature HLA-DR class II -chain in mouse bone marrow-derived DCs (bmDCs) (4, complexes, therefore reducing their stability and levels. -

Interaction Between CD8 and Major Histocompatibility Complex (MHC) Class I Mediated by Multiple Contact Surfaces That Include Th
Interaction Between CD8 and Major Histocompatibility Complex (MHC) Class I Mediated by Multiple Contact Surfaces that Include the oL2 and oL3 Domains of MHC Class I By Jiaren Sun,* DanielJ. Leahy,~ and Paula B. Kavathas*w From the *Department of Laboratory Medicine and Section of lmmunobiology, Yale University School of Medicine, New Haven, Connecticut 06520-8035; "Ji.Departmentof Biophysics and Biophysical Chemistry,Johns Hopkins University School of Medicine, Baltimore, Maryland 21205-2185; wDepartment of Genetics, Yale University School of Medicine, New Haven, Connecticut 06520-8035 Summary Downloaded from http://rupress.org/jem/article-pdf/182/5/1275/1107333/1275.pdf by guest on 03 October 2021 The cell surface glycoprotein CD8 functions as a coreceptor with the TCR on cytotoxic T lymphocytes. Mutational analysis of the binding site of CD8 for MHC class I predicted that distinct surfaces of CD8 would interact with both the a2 and a3 domains of class I. Using a cell-cell adhesion assay, we identified three residues Q115, D122, and E128 in the or2 domain of class I critical for interaction with CD8. The side chains of these residues point towards a cavity formed by the 0tl/e~2 platform, the or3 domain and [32-microglobulin ([32m) of class I. These residues were predicted to contact CD8 based on a bivalent model of interaction be- tween one CD8o~/oL homodimer and two MHC class I molecules. These results therefore pro- vide support for the model. HC class I molecules are highly polymorphic pro- critical residues in the 0~2 domain, two located underneath M teins that bind antigenic peptides and present them the peptide-binding floor and one on a nearby loop, all to T cells. -
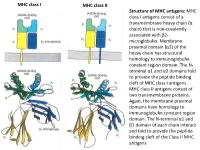
MHC Class I Antigens Consist of a Transmembrane Heavy Chain (Α Chain) That Is Non-Covalently Associated with Β2- Microglobulin
MHC class I MHC class II Structure of MHC antigens: MHC class I antigens consist of a transmembrane heavy chain (α chain) that is non-covalently associated with β2- microglobulin. Membrane proximal domain (α3) of the heavy chain has structural homology to immunoglobulin constant region domain. The N- terminal α1 and α2 domains fold to provide the peptide binding cleft of MHC class I antigens. MHC class II antigens consist of two transmembrane proteins. Again, the membrane proximal domains have homology to immunoglobulin constant region domain. The N-terminal α1 and β1 domain of each chain interact and fold to provide the peptide binding cleft of the Class II MHC antigens MHC class I MHC class II A top-down view of the peptide binding cleft of MHC antigens. The peptide binding cleft for MHC class I antigens is relatively narrower at the ends and accommodate 8- 10 amino acid residues long peptides. In contrast, due to non-covalent association between the N-terminal domains of the two chains of the class II antigens, the peptide binding cleft is open at the ends. This permits binding of larger peptides, typically 13-20 aa long. T cell receptor Interaction between T cell receptor and MHC-peptide complex: The T cell receptors binds to the peptide-MHC complex in a diagonal fashion. The CDR1 and CDR2 regions of the α and β chains of the T cell receptor bind to the α-helical walls of the peptide binding cleft. The CDR3 regions on the other hand bind to the peptide present in the cleft. -

Antigen Processing and Presentation Pamela Wearsch and Peter Cresswell
Antigen processing and presentation Pamela Wearsch and Peter Cresswell In antigen-presenting cells (APCs), such as dendritic cells (DCs) and B cells, heterogeneous intracellular phagocytosed by APCs, this simple division is not strictly enforced. Indeed, exogenous proteins pathways and mechanisms are responsible for generating complexes of MHC class I and class II internalized by DCs can generate peptide–MHC class I complexes that are recognized by CD8+ T cells, molecules with peptide antigens, and complexes of CD1 molecules with lipid antigens, for presentation a phenomenon referred to as cross-presentation. Similarly, endogenous and viral proteins can generate to T cells. This process — referred to as antigen processing and presentation — allows T cells to peptide–MHC class II complexes that are recognized by CD4+ T cells in a process involving autophagy. continuously assess the intracellular and extracellular milieu for signs of infection or abnormal cell Understanding the processes and mechanisms by which antigens are captured, processed and loaded growth. Although MHC class I molecules typically bind peptides derived from endogenous proteins onto MHC molecules for presentation to T cells provides us with crucial insights that are necessary for and MHC class II molecules typically bind peptides derived from proteins that are endocytosed or the design of vaccines and therapeutic strategies to bolster T-cell responses. The MHC class II pathway The MHC class I pathway MHC class II αβ-chain dimers are assembled in the endoplasmic reticulum (ER) All nucleated cells express MHC class I molecules and present endogenous peptide as a nonameric complex with the invariant chain (Ii), which protects against antigens to CD8+ T cells, but some DC subsets can also present exogenous premature peptide or protein interactions in pre-lysosomal peptides to CD8+ T cells through cross-presentation.