TRANSFORMING LIBRARY SERVICES for COMPUTATIONAL RESEARCH with TEXT DATA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

PATHWAYS to OPEN ACCESS University of California Libraries
University of Nebraska - Lincoln DigitalCommons@University of Nebraska - Lincoln Copyright, Fair Use, Scholarly Communication, etc. Libraries at University of Nebraska-Lincoln 2-27-2018 PATHWAYS TO OPEN ACCESS University of California Libraries Follow this and additional works at: https://digitalcommons.unl.edu/scholcom Part of the Intellectual Property Law Commons, Scholarly Communication Commons, and the Scholarly Publishing Commons University of California Libraries, "PATHWAYS TO OPEN ACCESS" (2018). Copyright, Fair Use, Scholarly Communication, etc.. 74. https://digitalcommons.unl.edu/scholcom/74 This Article is brought to you for free and open access by the Libraries at University of Nebraska-Lincoln at DigitalCommons@University of Nebraska - Lincoln. It has been accepted for inclusion in Copyright, Fair Use, Scholarly Communication, etc. by an authorized administrator of DigitalCommons@University of Nebraska - Lincoln. PATHWAYS TO OPEN ACCESS Approved 27 February 2018 Prepared by the University of California Libraries PATHWAYS TO OPEN ACCESS Table of Contents Introduction 1 Definitions 1 Approaches & Strategies 2 Green OA 2 Gold OA, APC-based 12 Gold OA, Non-APC Funded 23 Universal Strategies 28 Possible Next Steps 35 Green OA 35 Gold OA, APC-based 36 Gold OA, Non-APC-based 37 Universal Strategies 38 Selected Bibliography 40 INTRODUCTION Pursuant to the University of California (UC) Council of University Librarian’s (CoUL)1 3 August 2017 charge, this Pathways to OA Working Group2 has identified the current universe of Open Access (OA) approaches, and has analyzed the suite of strategies available for effectuating those approaches. Each approach described within this Pathways document offers unique and, in some cases, overlapping challenges, opportunities, and room for experimentation. -

Službeni List Grada Subotice
POŠTARINA PLA ĆENA TISKOVINA KOD POŠTE 24000 SUBOTICA SLUŽBENI LIST GRADA SUBOTICE BROJ: 22 GODINA: XLVII DANA:25. maj 2011. CENA: 87,00 DIN. Na osnovu člana 22. i člana 26. Odluke o mesnim zajednicama (pre čiš ćeni tekst) («Službeni list Grada Subotica», broj 17/2009- pre čiš ćeni tekst i 26/2009) i člana 24. Uputstva za sprovo đenje izbora za članove skupština mesnih zajednica («Službeni list Grada Subotica», broj 12/2011), Izborna komisija grada Subotice, na sednici održanoj dana 25. maja 2011. godine, donela je ZBIRNU IZBORNU LISTU KANDIDATA ZA IZBOR ČLANOVA SKUPŠTINE MESNE ZAJEDNICE ALEKSANDROVO I Zbirna izborna lista kandidata za izbor članova Skupštine Mesne zajednice Aleksandrovo koji se održava 05. juna 2011. godine sastoji se od slede ćih izbornih lista sa slede ćim kandidatima: 1.) Naziv izborne liste: DEMOKRATSKA STRANKA – BOŽIDAR KRSTI Ć Podnosilac izborne liste: Demokratska stranka Kandidati: 1. Božidar Krsti ć, 1953., elektroinženjer, Subotica, Vladimira Rolovi ća 22 2. Danijel Horvat, 1984., dipl. ekonomista, Subotica, Jovana Pa čua 43 3. Jadranka Vukovi ć, 1957., maturant gimnazije, Subotica, Aksentija Marodi ća 62 4. Slobodan Bukvi ć, 1974., matemat. program. sarad., Subotica, Josipa Lihta 13 5. Vlado Nim čevi ć, 1964., poljoprivredni tehni čar, Subotica, Kameni čka 16 6. Ljiljana Majlat, 1962., ekonomski tehni čar, Subotica, Josipa Lihta 64 7. Dragoljub Vesi ć, 1942., penzioner, Subotica, Trg Paje Jovanovi ća 3 8. Savo Mar četi ć, 1961., knjigovo đa, Subotica, Vojislava Ili ća 67 9. Judit Radakov, 1969., medicinski tehni čar-sestra, Subotica, Josipa Lihta 54 10. Vjekoslav Šar čevi ć, 1984., student, Subotica, Jelene Čovi ć 69 11. -
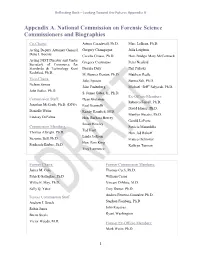
Appendix A. Natioan Commission on Forensic Science Commissioners
Reflecting Back—Looking Toward the Future: Appendix A Appendix A. National Commission on Forensic Science Commissioners and Biographies Co-Chairs: Arturo Casadevall, Ph.D. Marc LeBeau, Ph.D. Acting Deputy Attorney General Gregory Champagne Julia Leighton Dana J. Boente Cecelia Crouse, Ph.D. Hon. Bridget Mary McCormack Acting NIST Director and Under Gregory Czarnopys Peter Neufeld Secretary of Commerce for Standards & Technology Kent Deirdre Daly Phil Pulaski Rochford, Ph.D. M. Bonner Denton, Ph.D. Matthew Redle Vice-Chairs: Jules Epstein Sunita Sah, Ph.D. Nelson Santos John Fudenberg Michael “Jeff” Salyards, Ph.D. John Butler, Ph.D. S. James Gates, Jr., Ph.D. Ex-Officio Members: Commission Staff: Dean Gialamas Rebecca Ferrell, Ph.D. Jonathan McGrath, Ph.D. (DFO) Paul Giannelli David Honey, Ph.D. Danielle Weiss Randy Hanzlick, M.D. Marilyn Huestis, Ph.D. Lindsay DePalma Hon. Barbara Hervey Gerald LaPorte Susan Howley Commission Members: Patricia Manzolillo Ted Hunt Thomas Albright, Ph.D. Hon. Jed Rakoff Linda Jackson Suzanne Bell, Ph.D. Frances Schrotter Hon. Pam King Frederick Bieber, Ph.D. Kathryn Turman Troy Lawrence Former Chairs: Former Commission Members: James M. Cole Thomas Cech, Ph.D. Patrick Gallagher, Ph.D. William Crane Willie E. May, Ph.D. Vincent DiMaio, M.D. Sally Q. Yates Troy Duster, Ph.D. Andrea Ferreira-Gonzalez, Ph.D. Former Commission Staff: Andrew J. Bruck Stephen Fienberg, Ph.D. Robin Jones John Kacavas Brette Steele Ryant Washington Victor Weedn, M.D. Former Ex-Officio Members: Mark Weiss, Ph.D. 1 Reflecting Back—Looking Toward the Future: Appendix A NCFS Co-Chairs Dana J. -

Policy Governing Access to and Use of Copyrighted Works
Academic Affairs – Academic Policies 5.4012.1 Policy Governing Access to and Use of Copyrighted Works In an era increasingly defined by exponential advances in technology by which intellectual property may be disseminated with increasing ease, the County College of Morris (“CCM” or “the College”) expects its students, faculty and staff to restrict use of copyrighted works to uses and applications permissible in an academic setting. The College maximizes the utility of web-based technologies to advance instruction and study both in the classroom and through remote learning opportunities. However, students and faculty must remain mindful that improper use or dissemination of copyrighted work can lead to substantial liability. Accordingly, the College requires that all faculty, administrators, students, employees and members of the CCM family maintain a good faith observance of the principles of copyright law and adhere to the requirements of the Copyright Act of 1976, 17 U.S.C. §§ 101- 810 (the “Act”). BlackBoard Compliance Declaration: By accessing Blackboard, I certify that I am a CCM student, instructor, faculty member, employee or other user authorized by CCM to access Blackboard. I acknowledge and agree that my access to Blackboard, including any posting or downloading of content is governed by federal copyright law and the terms of this Declaration. Any copyrighted material(s) that I upload to, download from, or otherwise access or make available on Blackboard, whether visual, audio-visual, or audial in nature, shall be for use solely by CCM students, faculty or other authorized users. My use shall be for purposes directly related to a regularly scheduled CCM course of study and may not be used or disseminated for any other purpose. -

Nancy Wolff, Et Al., Best Practices in Rights Clearance
BEST PRACTICES IN RIGHTS CLEARANCE SELECTION OF RESOURCES AND BEST PRACTICES FOR VISUAL ARTISTS I. INTRODUCTION This document summarizes tips and resources for rights clearance and licensing of copyrighted works suggested by participants in the Best Practices in Rights Clearance – Visual Arts Symposium held at Scalia Law School, George Mason University on January 18, 2018. It is not intended as a comprehensive guide, but rather a more user-friendly tool for finding key information shared by participants than the transcripts of the sessions themselves. A. What is Copyrightable? Copyright law is meant to encourage creativity and the development of new works such as songs, photographs, poems, etc. Facts and ideas are not copyrightable, only the creative expression of the author. Types of works that can be protected are listed in the Copyright Act.1 ➢ The rights to create derivative works, or works that adapt, modify or transform the original, are also the property of the copyright owner. For example, if an author writes a book, that author is the only person who has the right to permit the book to be adapted into a movie. There are also limits on the scope of copyright. Therefore not every use needs to be cleared. For instance: ➢ The “scenes-a-faire” doctrine limits copyrights in commonly used themes or subjects in works. Such elements of works are not copyrightable, because they are the language or building blocks of creative works. ➢ The “merger” doctrine is the concept that if a copyrightable part of a work and a non-copyrightable part of a work are closely linked together and can’t be separated, they merge and become non-copyrightable. -

Old Spanish Masters Engraved by Timothy Cole
in o00 eg >^ ^V.^/ y LIBRARY OF THE University of California. Class OLD SPANISH MASTERS • • • • • , •,? • • TIIK COXCEPTION OF THE VIRGIN. I!V MURILLO. PRADO Mi;SEUAI, MADKIU. cu Copyright, 1901, 1902, 1903, 1904, 1905, 1906, and 1907, by THE CENTURY CO. Published October, k^j THE DE VINNE PRESS CONTENTS rjuw A Note on Spanish Painting 3 CHAPTER I Early Native Art and Foreign Influence the period of ferdinand and isabella (1492-15 16) ... 23 I School of Castile 24 II School of Andalusia 28 III School of Valencia 29 CHAPTER II Beginnings of Italian Influence the PERIOD OF CHARLES I (1516-1556) 33 I School of Castile 37 II School of Andalusia 39 III School of Valencia 41 CHAPTER III The Development of Italian Influence I Period of Philip II (l 556-1 598) 45 II Luis Morales 47 III Other Painters of the School of Castile 53 IV Painters of the School of Andalusia 57 V School of Valencia 59 CHAPTER IV Conclusion of Italian Influence I of III 1 Period Philip (1598-162 ) 63 II El Greco (Domenico Theotocopuli) 66 225832 VI CONTENTS CHAPTER V PACE Culmination of Native Art in the Seventeenth Century period of philip iv (162 1-1665) 77 I Lesser Painters of the School of Castile 79 II Velasquez 81 CHAPTER VI The Seventeenth-Century School of Valencia I Introduction 107 II Ribera (Lo Spagnoletto) log CHAPTER VII The Seventeenth-Century School of Andalusia I Introduction 117 II Francisco de Zurbaran 120 HI Alonso Cano x. 125 CHAPTER VIII The Great Period of the Seventeenth-Century School of Andalusia (continued) 133 CHAPTER IX Decline of Native Painting ii 1 charles ( 665-1 700) 155 CHAPTER X The Bourbon Dynasty FRANCISCO GOYA l6l INDEX OF ILLUSTRATIONS MuRiLLO, The Conception of the Virgin . -

Download Full White Paper
Open Access White Paper University of Oregon SENATE SUB-COMMITTEE ON OPEN ACCESS I. Executive Summary II. Introduction a. Definition and History of the Open Access Movement b. History of Open Access at the University of Oregon c. The Senate Subcommittee on Open Access at the University of Oregon III. Overview of Current Open Access Trends and Practices a. Open Access Formats b. Advantages and Challenges of the Open Access Approach IV. OA in the Process of Research & Dissemination of Scholarly Works at UO a. A Summary of Current Circumstances b. Moving Towards Transformative Agreements c. Open Access Publishing at UO V. Advancing Open Access at the University of Oregon and Beyond a. Barriers to Moving Forward with OA b. Suggestions for Local Action at UO 1 Executive Summary The state of global scholarly communications has evolved rapidly over the last two decades, as libraries, funders and some publishers have sought to hasten the spread of more open practices for the dissemination of results in scholarly research worldwide. These practices have become collectively known as Open Access (OA), defined as "the free, immediate, online availability of research articles combined with the rights to use these articles fully in the digital environment." The aim of this report — the Open Access White Paper by the Senate Subcommittee on Open Access at the University of Oregon — is to review the factors that have precipitated these recent changes and to explain their relevance for members of the University of Oregon community. Open Access History and Trends Recently, the OA movement has gained momentum as academic institutions around the globe have begun negotiating and signing creative, new agreements with for-profit commercial publishers, and as innovations to the business models for disseminating scholarly research have become more widely adopted. -

Best Practices for Open Sourcing Government Code Housekeeping
Best Practices for Open Sourcing Government Code Housekeeping ● Compliance Engineer and In-house Counsel ● Former technology manager and IT architect at University of Connecticut ● Practicing Free Software Law for 5 years Drupal GovCon | Open Sourcing Government Code | Marc Jones | @marcturnerjones | @CIVICACTIONS Housekeeping 1. I am an attorney, but I am not your attorney 2. This is not legal advice Drupal GovCon | Open Sourcing Government Code | Marc Jones | @marcturnerjones | @CIVICACTIONS Housekeeping 1. Jargon ○ Free Software vs. Open Source Software ○ FOSS, FLOSS, & OSS Drupal GovCon | Open Sourcing Government Code | Marc Jones | @marcturnerjones | @CIVICACTIONS Overview 1. What Is Open Source 2. Government Policy 3. Publishing Code 4. Encouraging a Community 5. Contributing 6. Evaluating FOSS Projects 7. Vendor Management Drupal GovCon | Open Sourcing Government Code | Marc Jones | @marcturnerjones | @CIVICACTIONS What is Open Source? What Is Open Source? Practical definition of a FOSS License ● A license that allows anyone to use, modify, and redistribute software with few restrictions. Drupal GovCon | Open Sourcing Government Code | Marc Jones | @marcturnerjones | @CIVICACTIONS What Is Open Source? Licenses Restrictions ● “These are the limits of the rights I give you permission to use ....” ● “You can’t use the software unless you …” Drupal GovCon | Open Sourcing Government Code | Marc Jones | @marcturnerjones | @CIVICACTIONS What Is Open Source? When do FOSS restrictions apply? ● Doesn’t restrict use ● Doesn’t restrict copying -

Free Software As Commons
FREE SOFTWARE AS COMMONS BETWEEN INFORMATIONAL CAPITALISM AND A NEW MODE OF PRODUCTION By Emrah Irzık Submitted to Central European University Department of Sociology and Social Anthropology In partial fulfillment of the requirements for the degree of Doctor of Philosophy Supervisor: Professor Jakob Rigi CEU eTD Collection Budapest, Hungary 2015 Statement I hereby state that the thesis contains no material accepted for any other degrees in any other institutions. The thesis contains no materials previously written and/or published by another person, except where appropriate acknowledgment is made in the form of bibliographical reference. Emrah Irzık Budapest, November 2015 CEU eTD Collection Abstract Free Software is a particular way of organizing the production and distribution of software that offers a solid alternative to the intellectual property regime by constituting an open commons: non-proprietary, created and held in common by all. Considering that in contemporary capitalism a significant amount of wealth is created through the application of intellectual effort to existing knowledge to produce new, higher compositions of knowledge that can be privately monetized as intellectual property, the challenge that Free Software might present to capitalism is bound to have important transformational potential. This potential needs to be studied both on an empirical level, in its partial and concrete manifestations in actual projects, and investigated more theoretically, to see if Free Software can be characterized as a nascent, new mode of production. This dissertation aims to contribute to the theorization of the relation between Free Software as a commons and the tenets of informational capitalism by means of an analytical study that is supported by an ethnography of a particular instance of Free Software as a project and a community. -

The Copyleft Movement: Creative Commons Licensing
Centre for the Study of Communication and Culture Volume 26 (2007) No. 3 IN THIS ISSUE The Copyleft Movement: Creative Commons Licensing Sharee L. Broussard, MS APR Spring Hill College AQUARTERLY REVIEW OF COMMUNICATION RESEARCH ISSN: 0144-4646 Communication Research Trends Table of Contents Volume 26 (2007) Number 3 http://cscc.scu.edu The Copyleft Movement:Creative Commons Licensing Published four times a year by the Centre for the Study of Communication and Culture (CSCC), sponsored by the 1. Introduction . 3 California Province of the Society of Jesus. 2. Copyright . 3 Copyright 2007. ISSN 0144-4646 3. Protection Activity . 6 4. DRM . 7 Editor: William E. Biernatzki, S.J. 5. Copyleft . 7 Managing Editor: Paul A. Soukup, S.J. 6. Creative Commons . 8 Editorial assistant: Yocupitzia Oseguera 7. Internet Practices Encouraging Creative Commons . 11 Subscription: 8. Pros and Cons . 12 Annual subscription (Vol. 26) US$50 9. Discussion and Conclusion . 13 Payment by check, MasterCard, Visa or US$ preferred. Editor’s Afterword . 14 For payments by MasterCard or Visa, send full account number, expiration date, name on account, and signature. References . 15 Checks and/or International Money Orders (drawn on Book Reviews . 17 USA banks; for non-USA banks, add $10 for handling) should be made payable to Communication Research Journal Report . 37 Trends and sent to the managing editor Paul A. Soukup, S.J. Communication Department In Memoriam Santa Clara University Michael Traber . 41 500 El Camino Real James Halloran . 43 Santa Clara, CA 95053 USA Transfer by wire: Contact the managing editor. Add $10 for handling. Address all correspondence to the managing editor at the address shown above. -

(B): Motion Pictures and Literary Works – Text and Data Mining
Submission on behalf of Joint Creators and Copyright Owners Class 7(a) & (b): Motion Pictures and Literary Works – Text and Data Mining [ ] Check here if multimedia evidence is being provided in connection with this comment ITEM A. COMMENTER INFORMATION The Motion Picture Association, Inc. (“MPA”) is a trade association representing some of the world’s largest producers and distributors of motion pictures and other audiovisual entertainment for viewing in theaters, on prerecorded media, over broadcast TV, cable and satellite services, and on the internet. The MPA’s members are: Netflix Studios, LLC, Paramount Pictures Corporation, Sony Pictures Entertainment Inc., Universal City Studios LLC, Walt Disney Studios Motion Pictures, and Warner Bros. Entertainment Inc. Alliance for Recorded Music (“ARM”) is a nonprofit coalition comprising the many artists and record labels who together perform, create, and/or distribute nearly all of the sound recordings commercially released in the United States. Members include the American Association of Independent Music (“A2IM”), the Music Artists Coalition (“MAC”), the Recording Industry Association of America, Inc. (“RIAA”), hundreds of recording artists, the major record companies, and more than 600 independently owned U.S. music labels. The Entertainment Software Association (“ESA”) is the United States trade association serving companies that publish computer and video games for video game consoles, handheld video game devices, personal computers, and the internet. It represents nearly all of the major video game publishers and major video game platform providers in the United States. Represented By: J. Matthew Williams ([email protected]) Sofia Castillo ([email protected]) MITCHELL SILBERBERG & KNUPP LLP 1818 N Street, NW, 7th Floor Washington, D.C. -

Ocm08458220-1834.Pdf (12.15Mb)
317.3M31 A 4^CHTVES ^K REGISTER, ^ AND 18S4. ALSO CITY OFFICEKS IN BOSTON, AND OTHKR USEFUL INFORMATION. BOSTON: JAMES LORING, 132 WASHINGTON STREET. — — ECLIPSES IN 1834. There will be five Eclipses this year, three of ike Svtf, and two of tht Moon, as follows, viz;— I. The first will be of the Sun, January, 9th day, 6h. 26m. eve. invisible. II. The second will likewise be of the Sun, June, 7th day, 5h. 12m. morning invisible. III. The third will be of the Moorr, June, 21st day, visible and total. Beginning Ih 52m. ^ Beginning of total darkness 2 55 / Middle 3 38 V, Appar. time End of total darkness (Moon sets). ..4 18 C morn. End of the Eclipse 5 21 j IV. The fourth will be a remarkable eclipse of the Sun, Sunday, the 30th day of November, visible, as follows, viz : Beginning Ih. 21m. J Greatest obscurity 2 40 fAppar. time End 3 51 ( even. Duration 2 30 * Digits eclipsed 10 deg. 21m. on the Sun's south limb. *** The Sun will be totally eclipsed in Mississippi, Alabama Georgia, South Carolina. At Charleston, the Sun will be totally eclipsed nearly a minute and a half. V. The fifth will be of the Moon, December 15th and I6th days, visible as follows viz : Beginning 15th d. lOli. Q2m. ) Appar. time Middle 16 5 > even. End 1 30 ) Appar. morn. Digits eclipsed 8 deg. 10m. (JU* The Compiler of the Register has endeavoured to be accurate in all the statements and names which it contains ; but when the difficulties in such a compilation are considered, and the constant changes which are occur- ring, by new elections, deaths, &c.