Design Challenges of an Ontology-Based Modelling And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The Representation and Exchange of Material and Other Engineering Properties
Data Science Journal, Volume 8, 24 September 2009 THE REPRESENTATION AND EXCHANGE OF MATERIAL AND OTHER ENGINEERING PROPERTIES Norman Swindells Ferroday Limited, 14 Mere Farm Road, UK-Birkenhead, CH43 9TT Email: [email protected] ABSTRACT The representation of information and its exchange in a communication requires the use of a common information model to define the semantics and syntax of the representation and a common dictionary to define the meaning of the data items. These fundamental concepts are the basis of the new standard ISO 10303-235: 'Engineering properties for product design and verification' for the computer representation and exchange of material and any other engineering properties of a product and to provide an audit trail for the derivation of the property value. A related dictionary conforming to ISO 13584 can define testing methods and their properties and enable the information model to be used for any property of any product. Keywords: Materials properties, Data representation, Data exchange, Materials informatics, International standards 1 INTRODUCTION Engineering properties are essential information for design and manufacturing processes and play an increasing role in the management of products throughout their life-cycle, including the end-of-life phase. For these reasons it is necessary to be able to communicate the information about the meaning of these properties and their values efficiently and without ambiguity among many different software programs and to retain this information for the lifetime of the product, independently from any proprietary software. The fundamental requirement for the communication of information in a natural language is the combination of a common information model and a common dictionary. -

Industrial Automation
ISO Focus The Magazine of the International Organization for Standardization Volume 4, No. 12, December 2007, ISSN 1729-8709 Industrial automation • Volvo’s use of ISO standards • A new generation of watches Contents 1 Comment Alain Digeon, Chair of ISO/TC 184, Industrial automation systems and integration, starting January 2008 2 World Scene Highlights of events from around the world 3 ISO Scene Highlights of news and developments from ISO members 4 Guest View ISO Focus is published 11 times Katarina Lindström, Senior Vice-President, a year (single issue : July-August). It is available in English. Head of Manufacturing in Volvo Powertrain and Chairman of the Manufacturing, Key Technology Committee Annual subscription 158 Swiss Francs Individual copies 16 Swiss Francs 8 Main Focus Publisher • Product data – ISO Central Secretariat Managing (International Organization for information through Standardization) the lifecycle 1, ch. de la Voie-Creuse CH-1211 Genève 20 • Practical business Switzerland solutions for ontology Telephone + 41 22 749 01 11 data exchange Fax + 41 22 733 34 30 • Modelling the E-mail [email protected] manufacturing enterprise Web www.iso.org • Improving productivity Manager : Roger Frost with interoperability Editor : Elizabeth Gasiorowski-Denis • Towards integrated Assistant Editor : Maria Lazarte manufacturing solutions Artwork : Pascal Krieger and • A new model for machine data transfer Pierre Granier • The revolution in engineering drawings – Product definition ISO Update : Dominique Chevaux data sets Subscription enquiries : Sonia Rosas Friot • A new era for cutting tools ISO Central Secretariat • Robots – In industry and beyond Telephone + 41 22 749 03 36 Fax + 41 22 749 09 47 37 Developments and Initiatives E-mail [email protected] • A new generation of watches to meet consumer expectations © ISO, 2007. -

V T T T I E D O T T E I T A
ISSN 1235–0605 (nid.) ISSN 1455–0865 (URL: http://www.inf.vtt.fi/pdf/) (URL: 1455–0865 (nid.) ISSN 1235–0605 ISSN VALTION TEKNILLINEN TUTKIMUSKESKUS ESPOO 2000 ESPOO TUTKIMUSKESKUS TEKNILLINEN VALTION ISBN 951–38–5669–0 (nid.) ISBN 951–38–5670–4 (URL: http://www.inf.vtt.fi/pdf/) (URL: 951–38–5670–4 (nid.) ISBN 951–38–5669–0 ISBN Faksi (09) 456 4374 4374 4374 456 456 456 9 (09) (09) 358 + Faksi Fax Fax Puh. (09) 456 4404 Tel. (09) 456 4404 Phone internat. + 358 9 456 4404 456 9 358 + 4404 4404 456 internat. 456 (09) (09) Phone Puh. Tel. 02044 VTT 02044 VTT Finland VTT, 02044 FIN–02044 PL 2000 PL 2000 PB 2000 P.O.Box VTT TIETOPALVELU VTT INFORMATIONSTJÄNST VTT INFORMATION SERVICE INFORMATION VTT INFORMATIONSTJÄNST VTT TIETOPALVELU VTT Tätä julkaisua myy Denna publikation säljs av This publication is available from available is av publication säljs This myy publikation julkaisua Denna Tätä V T T T I E D O T T E I T A T T EI T T IEDO T T V MINEN ˜ KEHITT MINEN ˜ KEHITT EKLS N ST HENKIL TIETOTEKNIIKAN MAHDOLLISUUDET KONSEPTI TEKNOLOGIAN KOKONAIS- TOIMINTAPROSESSIT VAATIMUKSET vaatimuksiin Sovellusalueen analyysista käyttäjän analyysista Sovellusalueen Ydinvoimaloiden uudet tietojärjestelmät. Sovellusalueen analyysista käyttäjän vaatimuksiin tietojärjestelmät tionaalisen prosessiteollisuuden edustajat voinevat löytää siitä hyödyllistä tietoa. hyödyllistä siitä löytää voinevat edustajat prosessiteollisuuden tionaalisen tarkoitettu palvelemaan ydinvoimateollisuuden tarpeita, mutta myös konven- myös mutta tarpeita, ydinvoimateollisuuden palvelemaan tarkoitettu Ydinvoimaloiden uudet Ydinvoimaloiden nallista rakennetta sekä esittelee mahdollisia toteutusteknologioita. Raportti on Raportti toteutusteknologioita. mahdollisia esittelee sekä rakennetta nallista su käsittelee ydinvoimalan tietojärjestelmille asetettavia vaatimuksia ja toimin- ja vaatimuksia asetettavia tietojärjestelmille ydinvoimalan käsittelee su suja, joten toimivan kokonaiskonseptin löytäminen ei ole helppoa. -

IST-1999-10303 D601 Virtual Reality Information Front-End (Multi-Media Enhanced Bcxml Communication)
Classification: Restricted IST-1999-10303 D601 Virtual Reality Information Front-end (multi-media enhanced bcXML communication) Authors: Frits TOLMAN TU-Delft Joost FLEUREN TU-Delft Reza BEHESHTI TU-Delft Reinout van REES TU-Delft Jeff STEPHENS Taylor Woodrow Distribution Draft1 Draft 2 Issued4 Date 23-03-01 23-04-01 11-09-01 BETANET á á CSTB á á EPM á á NEM á á Deliverable Reference STABU á á TNO á á WP Task No. TUD á á á WP6 T6100 D601 TW á á Status Draft/Issued/Revised Rev. Issued 4 WWW á á á Date Release to CEC 11-09-2001 Sep 01 CEC á IST-1999-10303 eConstruct D601 – Virtual Reality Information Front-end i Document Control Sheet Revision Status Page Nos. Amendment Date By 1 Draft For comment 23-03-2001 TU-Delft 2 Draft Full document 24-04-2001 TU-Delft 3 Draft Conclusions updated 20-08-2001 TU-Delft 4 Issued Final update 11-09-2001 TU-Delft Issued to the Commission Rev. 4 ii D601 – Virtual Reality Information Front-end IST-1999-10303 eConstruct Table of Contents 1 SUMMARY.......................................................................................................................1 1.1 INTRODUCTION ............................................................................................................2 1.1.1 The technology is there.......................................................................................2 1.1.2 The needs are real ..............................................................................................2 2 OBJECTIVES...................................................................................................................3 -

Final Report Standards for Smart Grids
Final report of the CEN/CENELEC/ETSI Joint Working Group on Standards for Smart Grids Final report of the CEN/CENELEC/ETSI Joint Working Group on Standards for Smart Grids Status: approved by the CEN/CENELEC/ETSI Joint Presidents Group (JPG) on 4 May 2011, subject to the formal approval by 2011-06-05 by the individual ESOs Final report of the CEN/CENELEC/ETSI Joint Working Group on Standards for Smart Grids Foreword < to be added> Final report of the CEN/CENELEC/ETSI Joint Working Group on Standards for Smart Grids Contents 1. Executive summary .................................................................................................................................. 6 2. Introduction ............................................................................................................................................... 8 2.1 Basic idea of smart grids ..................................................................................................................... 9 2.2 Current political background in Europe ............................................................................................. 11 2.3 Aim of a European standardization report ........................................................................................ 11 2.4 Standardization activities around the world ...................................................................................... 13 3. Description of the overall concept ....................................................................................................... 17 3.1 -

ISO TC 184/SC4 Reference Manual
ISO TO 184/SC4 Reference Manual Joan Wellington Bradford Smith U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Manufacturing Engineering Laboratory Manufacturing Systems Integration Division Gaithersburg, MD 20899 NOTE: Identification of commercial equipment and materials in this report does not imply recommendation or endorsement by NIST, nor does it imply that the materials and equipment are necessarily the best for the purpose. 3C 100 J56 NIST ^0.5665 1995 NISTIR 5665 ISO TC 184/SC4 Reference Manual Joan Wellington Bradford Smith U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Manufacturing Engineering Laboratory Manufacturing Systems Integration Division Gaithersburg, MD 20899 June 1995 NOTE: Identification of commercial equipment and materials in this report does not imply recommendation or endorsement by NIST, nor does it imply that the materials and equipment are necessarily the best for the purpose. U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary TECHNOLOGY ADMINISTRATION Mary L. Good, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Arati Prabhakar, Director June 25, 1995 To: All SC4 Participants and Observers From: Bradford Smith, SC4 Chairman Subject: June 1995 Reference Manual Attached is a newly updated copy of our subcommittee’s Reference Manual. This document has been published twice a year for the last several years in an effort to introduce new experts to the work of our committee and to serve as a single reference source for those actively involved with SC4 standards development. It contains: - descriptions of our organizational structure and approval procedures, - listings of our technical personnel and projects under development, - details of our many forms of electronic archives and communications mechanisms. -
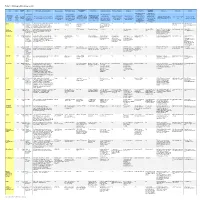
Table 1. Ontology Editor Survey Results
Table 1. Ontology editor survey results Release Import/Export Information Tool: Version: Source: Modeling Features/Limitations: Base Language: Web Support {Use}: Graph View: Consistency Checks: Multi-user Support: Merging: Lexical Support: Comments: More Info: Contact: Date: Formats: Extraction: Capabilities for lexical Capabilities for The company Support for Web- The degree to which referencing of ontology-directed The product or The Languages in which The extent to which the or The native or compliant ontologies the syntactic, Features that allow and Support for easily ontology elements capture of target other software latest The date ontology data can be built ontology can be Pertinent information about organization The representational and logical qualities primary language (e.g., URI's). {Use of referential and/or facilitate concurrent comparing and (e.g., synonyms) and information from Product or project Web E-mail contact for offering for software it became read in, and/or the built created, debugged, methodology, availability and producing or that can be expressed in the built ontology used to encode the the software over the logical correctness of development of the merging independent processing lexical content and possibly site additional information building release available ontology can be written edited and/or compared support, additional features, etc. supplying the ontology Web (e.g., browser the ontology can be built ontology built ontologies content (e.g., subsequent ontologies identifier out directly in graphic form software tool client).} verified automatically searching/filtering elaboration of the ontology terms) ontology Apollo 1.1(.1) 29-Sep- Knowledge Classes with slots plus facets for restrictions OKBC model No. -

Concepts and an Implementation for Product Data Management
Concepts and an Implementation for Product Data Management Doctorate Thesis Hannu Peltonen Helsinki University of Technology Department of Computer Science and Engineering P.O. Box 9555 FIN-02015 HUT, Finland [email protected] 2 Peltonen, H., Concepts and an Implementation for Product Data Manage- ment. Acta Polytechnica Scandinavica, Mathematics and Computing Series No. 105, Espoo 2000, 188 pp. Published by the The Finnish Academies of Technology. ISBN 951-666-538-1. ISSN 1456-9418. Keywords: Product data management, document management, configurable prod- ucts Abstract Shorter product life-cycles, growing product complexity and the need for a large number of product variants have made Product Data Management (PDM) increas- ingly important for many manufacturing companies. This thesis provides a survey of the most important concepts of PDM technology and illustrates the concepts by describing the design and implementation of an advanced document management system. The survey in the first part of the thesis illustrates the relations between different concepts and can be used as a framework for evaluating PDM systems. This part includes summaries of the STEP standards for product models and the IEC 6130 and ISO 13584 standards for component management. The STEP standards are partic- ularly difficult to read, and these sections of the thesis provide accessible introduc- tions to these very complex standards. The document management system described in the second part of the thesis has been developed in close co-operation with a large manufacturing company, which now stores all engineering documents in the system and accesses the system through a global intranet. The main strengths of the system are its versatile document model and the flexible customisation properties of the system, including dynamic schema manipulation operations and a programmable authorisation mechanism. -

Background Study: Requisite Elements, Rationale, and Technology
i \ Requisite Elements, Rationale, AND Technology Overview for THE Systems Integration for Manufacturing Applications (SIMA) Program i Edward J. Barkmeyer Theodore H. Hopp Michael J. Pratt Gaylen R. Rinaudot STATES I UNITED DEPARTMENT OF COMMERCE NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY NISTIR 5662 U.S. DraAKTMENT OF COMMERCE TECHNOLOGY ADMINISTRATION National Institute of Standards and Technology NISTIR 5662 Background Study Requisite Elements, Rationale, and Technology Overview for the Systems Integration for Manufacturing Applications (SIMA) Program Editors: Edward J. Barkmeyer Theodore H. Hopp Michael J. Pratt Gaylen R. Rinaudot Contributors: Neil Christopher Shaw Feng Simon Frechette Al Jones Mark Luce Kevin Lyons Chuck McLean Stephen A. Osella Steven Ray Bradford Smith Evan Wallace Peter Wilson U.S. DEPARTMENT OF COMMERCE Technology Administration National Institute of Standards and Technology Gaithersburg, MD 20899 September 1995 U.S. DEPARTMENT OF COMMERCE Ronald H. Brown, Secretary TECHNOLOGY ADMINISTRATION Mary L. Good, Under Secretary for Technology NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY Arati Prabhakar, Director No approval or endorsement of any commercial product by the National Institute ofStandards and Technology is intended or implied. The work described wasfunded by the United States Government and is not subject to copyright. Table of Contents Executive Summary vii Preface xi Parti: Project Overview 1 Chapter 1: Introduction to the MSE Project 3 1.1 The National Challenge of Advanced Manufacturing 3 1.2 -

Building an Integrated Digital Environment for Nuclear Science and Engineering
Transactions , SMiRT-23 Manchester, United Kingdom - August 10-14, 2015 Division III , Paper 570 Building an integrated digital environment for nuclear science and engineering Norman Swindells 1 1 Managing Director, Ferroday Ltd, UK ABSTRACT This paper proposes that an integrated digital environment for nuclear science and engineering should be built from the established technology specified in the International Standards for product data representation and exchange developed by ISO TC184/SC4. These standards provide comprehensive, scalable and extendable representations of engineering data by using computer-processable information models to support interoperability between different software systems and through-life data management. Examples of the application of one of these Standards, ISO 10303-235, to the representation of steel plate and to data from three types of ultrasonic NDT inspections illustrate some of the capabilities of this technology. INTRODUCTION Throughout the supply chain and the life cycle of an engineered product there is the need for the transfer of digital information about the product between different software systems, each with its own internal method of representing the data. Figure 1 is an attempt to illustrate this life cycle. Digital interoperability between different systems therefore requires a method to ensure that the data in the message from one system can be understood and used by the receiving system. For the long life times of products and plant, such as in the nuclear sector, the digital data also needs to be conserved and yet be still understandable and usable when the originating software is obsolete or no longer available. Figure 1. Illustration of the flow of digital information throughout the life of a product The solution for interoperability and information conservation of product data adopted by the aerospace, automotive, defence, construction, machine tools, process plant, offshore oil & gas and other sectors is to represent the product data in non-proprietary, computer-understandable information models. -

Development Architecture for Industrial Data Management
Development architecture for industrial data management Yujiang Li Licentiate Thesis Royal Institute of Technology School of Industrial Engineering and Management Department of Production Engineering Stockholm, Sweden 2013 Abstract Standardized information modeling is important for interoperability of CAx systems. Existing information standards such as ISO 10303 STEP have been proposed and developed for decades for this purpose. Comprehensive data structure and various implementation methodologies make such standards strong in support of different industry domains, information types, and technical requirements. However, this fact also leads to increased implementation complexity and workloads for CAx system developers. This licentiate proposes the development architecture, STEP Toolbox, to help users implement standards with a simplified development process and minimal knowledge requirements on standards. Implementation difficulties for individuals are identified with analysis on implementation of the information standards in three aspects: tasks, users, and technology. Then the toolbox is introduced with an illustration of design of behavior and structure. Case studies are performed to validate the toolbox with prototypes. Internal and external observation has shown the around two-month learning process skipped and a great amount of workload reduction in implementation with the utilization of this architecture. Keywords: Information modeling, ISO 10303 STEP, CAx, API I Contents Abstract ........................................................................................................................ -

White Paper Automationml and Ecl@Ss Integration
® classification and product description White paper AutomationML and eCl@ss integration State: November 2015 AutomationML and eCl@ss integration Common Working Group of AutomationML e.V and eCl@ss e.V. Contributer: Olaf Gräser PHOENIX CONTACT GmbH & Co. KG Lorenz Hundt inpro Innovationsgesellschaft für fortgeschrittene Produktionssysteme in der Fahrzeugindustrie mbH Michael John Siemens AG Gerald Lobermeier Weidmüller Interface GmbH & Co. KG Arndt Lüder Otto-von-Guericke-Universität Magdeburg Stefan Mülhens AmpereSoft GmbH Nicolaus Ondracek Paradine GmbH Mario Thron Institut für Automation und Kommunikation e.V. Josef Schmelter PHOENIX CONTACT GmbH & Co. KG Version 1.0, October 2015 Contact: www.automationml.org www.eclass.de 2 AutomationML and eCl@ss integration Table of content Table of content .................................................................................................................................... 3 List of figures ........................................................................................................................................ 5 List of tables ......................................................................................................................................... 7 1 Introduction and Scope ............................................................................................................. 8 2 Terms, definitions and abbreviations .................................................................................... 10 2.1 Terms and definitions ............................................................................................................