Polycube Documentation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Informal Data Transformation Considered Harmful
Informal Data Transformation Considered Harmful Eric Daimler, Ryan Wisnesky Conexus AI out the enterprise, so that data and programs that depend on that data need not constantly be re-validated for ev- ery particular use. Computer scientists have been develop- ing techniques for preserving data integrity during trans- formation since the 1970s (Doan, Halevy, and Ives 2012); however, we agree with the authors of (Breiner, Subrah- manian, and Jones 2018) and others that these techniques are insufficient for the practice of AI and modern IT sys- tems integration and we describe a modern mathematical approach based on category theory (Barr and Wells 1990; Awodey 2010), and the categorical query language CQL2, that is sufficient for today’s needs and also subsumes and unifies previous approaches. 1.1 Outline To help motivate our approach, we next briefly summarize an application of CQL to a data science project undertaken jointly with the Chemical Engineering department of Stan- ford University (Brown, Spivak, and Wisnesky 2019). Then, in Section 2 we review data integrity and in Section 3 we re- view category theory. Finally, we describe the mathematics of our approach in Section 4, and conclude in Section 5. We present no new results, instead citing a line of work summa- rized in (Schultz, Spivak, and Wisnesky 2017). Image used under a creative commons license; original 1.2 Motivating Case Study available at http://xkcd.com/1838/. In scientific practice, computer simulation is now a third pri- mary tool, alongside theory and experiment. Within -

Automating the Capture of Data Transformations from Statistical Scripts in Data Documentation Jie Song George Alter H
C2Metadata: Automating the Capture of Data Transformations from Statistical Scripts in Data Documentation Jie Song George Alter H. V. Jagadish University of Michigan University of Michigan University of Michigan Ann Arbor, Michigan Ann Arbor, Michigan Ann Arbor, Michigan [email protected] [email protected] [email protected] ABSTRACT CCS CONCEPTS Datasets are often derived by manipulating raw data with • Information systems → Data provenance; Extraction, statistical software packages. The derivation of a dataset transformation and loading. must be recorded in terms of both the raw input and the ma- nipulations applied to it. Statistics packages typically provide KEYWORDS limited help in documenting provenance for the resulting de- data transformation, data documentation, data provenance rived data. At best, the operations performed by the statistical ACM Reference Format: package are described in a script. Disparate representations Jie Song, George Alter, and H. V. Jagadish. 2019. C2Metadata: Au- make these scripts hard to understand for users. To address tomating the Capture of Data Transformations from Statistical these challenges, we created Continuous Capture of Meta- Scripts in Data Documentation. In 2019 International Conference data (C2Metadata), a system to capture data transformations on Management of Data (SIGMOD ’19), June 30-July 5, 2019, Am- in scripts for statistical packages and represent it as metadata sterdam, Netherlands. ACM, New York, NY, USA, 4 pages. https: in a standard format that is easy to understand. We do so by //doi.org/10.1145/3299869.3320241 devising a Structured Data Transformation Algebra (SDTA), which uses a small set of algebraic operators to express a 1 INTRODUCTION large fraction of data manipulation performed in practice. -

What Is a Data Warehouse?
What is a Data Warehouse? By Susan L. Miertschin “A data warehouse is a subject oriented, integrated, time variant, nonvolatile, collection of data in support of management's decision making process.” https: //www. bus iness.auc. dk/oe kostyr /file /What_ is_a_ Data_ Ware house.pdf 2 What is a Data Warehouse? “A copy of transaction data specifically structured for query and analysis” 3 “Data Warehousing is the coordination, architected, and periodic copying of data from various sources, both inside and outside the enterprise, into an environment optimized for analytical and informational processing” ‐ Alan Simon Data Warehousing for Dummies 4 Business Intelligence (BI) • “…implies thinking abstractly about the organization, reasoning about the business, organizing large quantities of information about the business environment.” p. 6 in Giovinazzo textbook • Purpose of BI is to define and execute a strategy 5 Strategic Thinking • Business strategist – Always looking forward to see how the company can meet the objectives reflected in the mission statement • Successful companies – Do more than just react to the day‐to‐day environment – Understand the past – Are able to predict and adapt to the future 6 Business Intelligence Loop Business Intelligence Figure 1‐1 p. 2 Giovinazzo • Encompasses entire loop shown Business Strategist • Data Storage + ETC = OLAP Data Mining Reports Data Warehouse Data Storage • Data WhWarehouse + Tools (yellow) = Extraction,Transformation, Cleaning DiiDecision Support CRM Accounting Finance HR System 7 The Data Warehouse Decision Support Systems Central Repository Metadata Dependent Data DtData Mar t EtExtrac tion DtData Log Administration Cleansing/Tranformation External Extraction Source Extraction Store Independent Data Mart Operational Environment Figure 1-2 p. -

POLITECNICO DI TORINO Repository ISTITUZIONALE
POLITECNICO DI TORINO Repository ISTITUZIONALE Rethinking Software Network Data Planes in the Era of Microservices Original Rethinking Software Network Data Planes in the Era of Microservices / Miano, Sebastiano. - (2020 Jul 13), pp. 1-175. Availability: This version is available at: 11583/2841176 since: 2020-07-22T19:49:25Z Publisher: Politecnico di Torino Published DOI: Terms of use: Altro tipo di accesso This article is made available under terms and conditions as specified in the corresponding bibliographic description in the repository Publisher copyright (Article begins on next page) 08 October 2021 Doctoral Dissertation Doctoral Program in Computer and Control Enginering (32nd cycle) Rethinking Software Network Data Planes in the Era of Microservices Sebastiano Miano ****** Supervisor Prof. Fulvio Risso Doctoral examination committee Prof. Antonio Barbalace, Referee, University of Edinburgh (UK) Prof. Costin Raiciu, Referee, Universitatea Politehnica Bucuresti (RO) Prof. Giuseppe Bianchi, University of Rome “Tor Vergata” (IT) Prof. Marco Chiesa, KTH Royal Institute of Technology (SE) Prof. Riccardo Sisto, Polytechnic University of Turin (IT) Politecnico di Torino 2020 This thesis is licensed under a Creative Commons License, Attribution - Noncommercial- NoDerivative Works 4.0 International: see www.creativecommons.org. The text may be reproduced for non-commercial purposes, provided that credit is given to the original author. I hereby declare that, the contents and organisation of this dissertation constitute my own original work and does not compromise in any way the rights of third parties, including those relating to the security of personal data. ........................................ Sebastiano Miano Turin, 2020 Summary With the advent of Software Defined Networks (SDN) and Network Functions Virtualization (NFV), software started playing a crucial role in the computer net- work architectures, with the end-hosts representing natural enforcement points for core network functionalities that go beyond simple switching and routing. -

Data Warehousing on AWS
Data Warehousing on AWS March 2016 Amazon Web Services – Data Warehousing on AWS March 2016 © 2016, Amazon Web Services, Inc. or its affiliates. All rights reserved. Notices This document is provided for informational purposes only. It represents AWS’s current product offerings and practices as of the date of issue of this document, which are subject to change without notice. Customers are responsible for making their own independent assessment of the information in this document and any use of AWS’s products or services, each of which is provided “as is” without warranty of any kind, whether express or implied. This document does not create any warranties, representations, contractual commitments, conditions or assurances from AWS, its affiliates, suppliers or licensors. The responsibilities and liabilities of AWS to its customers are controlled by AWS agreements, and this document is not part of, nor does it modify, any agreement between AWS and its customers. Page 2 of 26 Amazon Web Services – Data Warehousing on AWS March 2016 Contents Abstract 4 Introduction 4 Modern Analytics and Data Warehousing Architecture 6 Analytics Architecture 6 Data Warehouse Technology Options 12 Row-Oriented Databases 12 Column-Oriented Databases 13 Massively Parallel Processing Architectures 15 Amazon Redshift Deep Dive 15 Performance 15 Durability and Availability 16 Scalability and Elasticity 16 Interfaces 17 Security 17 Cost Model 18 Ideal Usage Patterns 18 Anti-Patterns 19 Migrating to Amazon Redshift 20 One-Step Migration 20 Two-Step Migration 20 Tools for Database Migration 21 Designing Data Warehousing Workflows 21 Conclusion 24 Further Reading 25 Page 3 of 26 Amazon Web Services – Data Warehousing on AWS March 2016 Abstract Data engineers, data analysts, and developers in enterprises across the globe are looking to migrate data warehousing to the cloud to increase performance and lower costs. -
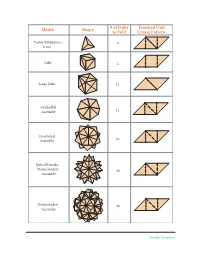
Sonobe Assembly Guide for a Few Polyhedra
Model Shape # of Units Finished Unit to Fold Crease Pattern Toshie Takahama’s 3 Jewel Cube 6 Large Cube 12 Octahedral Assembly 12 Icosahedral Assembly 30 Spiked Pentakis Dodecahedral 60 Assembly Dodecahedral 90 Assembly 2 Sonobe Variations Sonobe Assembly Basics Sonobe assemblies are essentially “pyramidized” constructing a polyhedron, the key thing to re- polyhedra, each pyramid consisting of three So- member is that the diagonal ab of each Sonobe nobe units. The figure below shows a generic So- unit will lie along an edge of the polyhedron. nobe unit and how to form one pyramid. When a Pocket Tab Forming one Tab pyramid Pocket b A generic Sonobe unit representation Sonobe Assembly Guide for a Few Polyhedra 1. Toshie’s Jewel: Crease three finished units as tabs and pockets. This assembly is also sometimes explained in the table on page 2. Form a pyramid known as a Crane Egg. as above. Then turn the assembly upside down 2. Cube Assembly: Crease six finished units as and make another pyramid with the three loose explained in the table on page 2. Each face will be made up of 3 the center square of one unit and the tabs of two other units. 4 Do Steps 1 and 2 to form one face. Do Steps 3 and 4 to form one corner or vertex. Continue 1 2 interlocking in this manner to arrive at the finished cube. Sonobe Variations 3 3. Large Cube Assembly: Crease 12 finished units as explained on page 2. 5 6 3 The 12-unit large cube is the only assembly that does not involve pyramidizing. -

Master Data Simplified
MASTER THE BEST IN MASTER DATA GOVERNANCE DATA SIMPLIFICATION & MANAGEMENT SIMPLIFIED CHARLIE MASSOGLIA & ANBARASAN MURUGAN ‘A MUST READ FOR DATA ENTHUISIASTS’ - AUSTIN DAVIS About the Authors Charlie Massoglia VP & CIO, Chain-Sys Corporation Former CIO for Dawn Food Products For 13+ years. 25+ years experience with a variety of ERP systems. Extensive experience in system migrations & conversions. Participated in 9 acquisitions ranging from a single US location to 14 sites in 11 countries. Author of numerous technical books, articles, presentations, and seminars globally. Anbarasan Murugan Product Lead, Master Data Management Master Data Simplification & Governance expert. Industry experience of more than 11 years. Chief Technical Architect for more than 10 products TM within the Chain Sys Platform . Has designed complex analytical & transactional Master data processes for Fortune 500 companies. Master Data Simplified An Introduction to Master Data Simplification, Governance, and Management By Charles L. Massoglia VP & CIO Chain●Sys Corporation [email protected] and Anbarasan Murugan Product Manager Chain●Sys Corporation [email protected] No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copyright Act, without written permission of the publisher. For information regarding permission, write to Chain-Sys Corporation, Attention: Permissions Department, 325 S. Clinton Street, Suite 205, Grand Ledge, MI 48837 Trademarks: Chain●Sys Platform is a trademark of Chain-Sys Corporation in the United States and other countries and may not be used without permission. -

A Survey of Folding and Unfolding in Computational Geometry
Combinatorial and Computational Geometry MSRI Publications Volume 52, 2005 A Survey of Folding and Unfolding in Computational Geometry ERIK D. DEMAINE AND JOSEPH O’ROURKE Abstract. We survey results in a recent branch of computational geome- try: folding and unfolding of linkages, paper, and polyhedra. Contents 1. Introduction 168 2. Linkages 168 2.1. Definitions and fundamental questions 168 2.2. Fundamental questions in 2D 171 2.3. Fundamental questions in 3D 175 2.4. Fundamental questions in 4D and higher dimensions 181 2.5. Protein folding 181 3. Paper 183 3.1. Categorization 184 3.2. Origami design 185 3.3. Origami foldability 189 3.4. Flattening polyhedra 191 4. Polyhedra 193 4.1. Unfolding polyhedra 193 4.2. Folding polygons into convex polyhedra 196 4.3. Folding nets into nonconvex polyhedra 199 4.4. Continuously folding polyhedra 200 5. Conclusion and Higher Dimensions 201 Acknowledgements 202 References 202 Demaine was supported by NSF CAREER award CCF-0347776. O’Rourke was supported by NSF Distinguished Teaching Scholars award DUE-0123154. 167 168 ERIKD.DEMAINEANDJOSEPHO’ROURKE 1. Introduction Folding and unfolding problems have been implicit since Albrecht D¨urer [1525], but have not been studied extensively in the mathematical literature until re- cently. Over the past few years, there has been a surge of interest in these problems in discrete and computational geometry. This paper gives a brief sur- vey of most of the work in this area. Related, shorter surveys are [Connelly and Demaine 2004; Demaine 2001; Demaine and Demaine 2002; O’Rourke 2000]. We are currently preparing a monograph on the topic [Demaine and O’Rourke ≥ 2005]. -
![Arxiv:2105.14305V1 [Cs.CG] 29 May 2021](https://docslib.b-cdn.net/cover/2277/arxiv-2105-14305v1-cs-cg-29-may-2021-1052277.webp)
Arxiv:2105.14305V1 [Cs.CG] 29 May 2021
Efficient Folding Algorithms for Regular Polyhedra ∗ Tonan Kamata1 Akira Kadoguchi2 Takashi Horiyama3 Ryuhei Uehara1 1 School of Information Science, Japan Advanced Institute of Science and Technology (JAIST), Ishikawa, Japan fkamata,[email protected] 2 Intelligent Vision & Image Systems (IVIS), Tokyo, Japan [email protected] 3 Faculty of Information Science and Technology, Hokkaido University, Hokkaido, Japan [email protected] Abstract We investigate the folding problem that asks if a polygon P can be folded to a polyhedron Q for given P and Q. Recently, an efficient algorithm for this problem has been developed when Q is a box. We extend this idea to regular polyhedra, also known as Platonic solids. The basic idea of our algorithms is common, which is called stamping. However, the computational complexities of them are different depending on their geometric properties. We developed four algorithms for the problem as follows. (1) An algorithm for a regular tetrahedron, which can be extended to a tetramonohedron. (2) An algorithm for a regular hexahedron (or a cube), which is much efficient than the previously known one. (3) An algorithm for a general deltahedron, which contains the cases that Q is a regular octahedron or a regular icosahedron. (4) An algorithm for a regular dodecahedron. Combining these algorithms, we can conclude that the folding problem can be solved pseudo-polynomial time when Q is a regular polyhedron and other related solid. Keywords: Computational origami folding problem pseudo-polynomial time algorithm regular poly- hedron (Platonic solids) stamping 1 Introduction In 1525, the German painter Albrecht D¨urerpublished his masterwork on geometry [5], whose title translates as \On Teaching Measurement with a Compass and Straightedge for lines, planes, and whole bodies." In the book, he presented each polyhedron by drawing a net, which is an unfolding of the surface of the polyhedron to a planar layout without overlapping by cutting along its edges. -

Universal Folding Pathways of Polyhedron Nets
Universal folding pathways of polyhedron nets Paul M. Dodda, Pablo F. Damascenob, and Sharon C. Glotzera,b,c,d,1 aChemical Engineering Department, University of Michigan, Ann Arbor, MI 48109; bApplied Physics Program, University of Michigan, Ann Arbor, MI 48109; cDepartment of Materials Science and Engineering, University of Michigan, Ann Arbor, MI 48109; and dBiointerfaces Institute, University of Michigan, Ann Arbor, MI 48109 Contributed by Sharon C. Glotzer, June 6, 2018 (sent for review January 17, 2018; reviewed by Nuno Araujo and Andrew L. Ferguson) Low-dimensional objects such as molecular strands, ladders, and navigate, thermodynamically, from a denatured (unfolded) state sheets have intrinsic features that affect their propensity to fold to a natured (folded) one. Even after many decades of study, into 3D objects. Understanding this relationship remains a chal- however, a universal relationship between molecular sequence lenge for de novo design of functional structures. Using molecular and folded state—which could provide crucial insight into the dynamics simulations, we investigate the refolding of the 24 causes and potential treatments of many diseases—remains out possible 2D unfoldings (“nets”) of the three simplest Platonic of reach (11–13). shapes and demonstrate that attributes of a net’s topology— In this work, we study the thermodynamic foldability of 2D net compactness and leaves on the cutting graph—correlate nets for all five Platonic solids. Despite being the simplest and with thermodynamic folding propensity. To -

Lineage Tracing for General Data Warehouse Transformations
Lineage Tracing for General Data Warehouse Transformations∗ Yingwei Cui and Jennifer Widom Computer Science Department, Stanford University fcyw, [email protected] Abstract. Data warehousing systems integrate information and managing such transformations as part of the extract- from operational data sources into a central repository to enable transform-load (ETL) process, e.g., [Inf, Mic, PPD, Sag]. analysis and mining of the integrated information. During the The transformations may vary from simple algebraic op- integration process, source data typically undergoes a series of erations or aggregations to complex procedural code. transformations, which may vary from simple algebraic opera- In this paper we consider the problem of lineage trac- tions or aggregations to complex “data cleansing” procedures. ing for data warehouses created by general transforma- In a warehousing environment, the data lineage problem is that tions. Since we no longer have the luxury of a fixed set of of tracing warehouse data items back to the original source items operators or the algebraic properties offered by relational from which they were derived. We formally define the lineage views, the problem is considerably more difficult and tracing problem in the presence of general data warehouse trans- open-ended than previous work on lineage tracing. Fur- formations, and we present algorithms for lineage tracing in this thermore, since transformation graphs in real ETL pro- environment. Our tracing procedures take advantage of known cesses can often be quite complex—containing as many structure or properties of transformations when present, but also as 60 or more transformations—the storage requirements work in the absence of such information. -

Doppiodb 2.0: Hardware Techniques for Improved Integration of Machine Learning Into Databases
Research Collection Conference Paper doppioDB 2.0: Hardware Techniques for Improved Integration of Machine Learning into Databases Author(s): Kara, Kaan; Wang, Zeke; Zhang, Ce; Alonso, Gustavo Publication Date: 2019-08 Permanent Link: https://doi.org/10.3929/ethz-b-000394510 Originally published in: Proceedings of the VLDB Endowment 12(12), http://doi.org/10.14778/3352063.3352074 Rights / License: Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International This page was generated automatically upon download from the ETH Zurich Research Collection. For more information please consult the Terms of use. ETH Library doppioDB 2.0: Hardware Techniques for Improved Integration of Machine Learning into Databases Kaan Kara Zeke Wang Ce Zhang Gustavo Alonso Systems Group, Department of Computer Science ETH Zurich, Switzerland fi[email protected] ABSTRACT t1 compressed/ Database engines are starting to incorporate machine learning (ML) doppioDB 2.0 encrypted functionality as part of their repertoire. Machine learning algo- Table t1 Iterative Decryption rithms, however, have very different characteristics than those of Execution Decompression relational operators. In this demonstration, we explore the chal- SCD lenges that arise when integrating generalized linear models into a t1 bitweaving t1_model database engine and how to incorporate hardware accelerators into Iterative Quantized Execution SGD the execution, a tool now widely used for ML workloads. t1_model The demo explores two complementary alternatives: (1) how to - Training: INSERT INTO t1_model train models directly on compressed/encrypted column-stores us- SELECT weights FROM TRAIN('t1', step_size, …); ing a specialized coordinate descent engine, and (2) how to use a - Validation: SELECT loss FROM VALIDATE('t1_model', 't1'); bitwise weaving index for stochastic gradient descent on low pre- SELECT prediction FROM INFER('t1_model', 't1_new'); cision input data.