Using Multiple Subwords to Improve English-Esperanto Automated Literary Translation Quality
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Alexander's Empire
4 Alexander’s Empire MAIN IDEA WHY IT MATTERS NOW TERMS & NAMES EMPIRE BUILDING Alexander the Alexander’s empire extended • Philip II •Alexander Great conquered Persia and Egypt across an area that today consists •Macedonia the Great and extended his empire to the of many nations and diverse • Darius III Indus River in northwest India. cultures. SETTING THE STAGE The Peloponnesian War severely weakened several Greek city-states. This caused a rapid decline in their military and economic power. In the nearby kingdom of Macedonia, King Philip II took note. Philip dreamed of taking control of Greece and then moving against Persia to seize its vast wealth. Philip also hoped to avenge the Persian invasion of Greece in 480 B.C. TAKING NOTES Philip Builds Macedonian Power Outlining Use an outline to organize main ideas The kingdom of Macedonia, located just north of Greece, about the growth of had rough terrain and a cold climate. The Macedonians were Alexander's empire. a hardy people who lived in mountain villages rather than city-states. Most Macedonian nobles thought of themselves Alexander's Empire as Greeks. The Greeks, however, looked down on the I. Philip Builds Macedonian Power Macedonians as uncivilized foreigners who had no great A. philosophers, sculptors, or writers. The Macedonians did have one very B. important resource—their shrewd and fearless kings. II. Alexander Conquers Persia Philip’s Army In 359 B.C., Philip II became king of Macedonia. Though only 23 years old, he quickly proved to be a brilliant general and a ruthless politician. Philip transformed the rugged peasants under his command into a well-trained professional army. -

The Resurrection of Alexander Push Kin John Oliver Killens
New Directions Volume 5 | Issue 2 Article 9 1-1-1978 The Resurrection Of Alexander Push kin John Oliver Killens Follow this and additional works at: http://dh.howard.edu/newdirections Recommended Citation Killens, John Oliver (1978) "The Resurrection Of Alexander Push kin," New Directions: Vol. 5: Iss. 2, Article 9. Available at: http://dh.howard.edu/newdirections/vol5/iss2/9 This Article is brought to you for free and open access by Digital Howard @ Howard University. It has been accepted for inclusion in New Directions by an authorized administrator of Digital Howard @ Howard University. For more information, please contact [email protected]. TH[ ARTS Essay every one of the courts of Europe, then 28 The Resurrection of of the 19th century? Here is how it came to pass. Peter felt that he had to have at least Alexander Pushkin one for his imperial court. Therefore, In the early part of the 18th century, in By [ohn Oliver Killens he sent the word out to all of his that sprawling subcontinent that took Ambassadors in Europe: To the majority of literate Americans, up one-sixth of the earth's surface, the giants of Russian literature are extending from the edge of Europe "Find me a Negro!" Tolstoy, Gogol, Dostoevsky and thousands of miles eastward across Meanwhile, Turkey and Ethiopia had Turgenev. Nevertheless, 97 years ago, grassy steppes (plains), mountain ranges been at war, and in one of the skirmishes at a Pushkin Memorial in Moscow, and vast frozen stretches of forest, lakes a young African prince had been cap- Dostoevsky said: "No Russian writer and unexplored terrain, was a land tured and brought back to Turkey and was so intimately at one with the known as the Holy Russian Empire, fore- placed in a harem. -

CURRICULUM VITAE L. Name & Institutional Affiliation: Alexander
CURRICULUM VITAE l. Name & Institutional Affiliation: Alexander Levitsky Professor of Slavic Languages & Literatures Department of Slavic Studies, Box E, Brown University, Providence, R.I. 029l2 e-mail: [email protected] Telephone: (401) 863 2689 or 863 2835 FAX:(401) 863 7330 2. Home Address: 23 Ray Street, Providence, Rhode Island 02906, USA Telephone: (40l) 272-3098 3. Education (most recent first): 1977 Ph.D. University of Michigan: Dissertation Topic: The Sacred Ode (Oda Duxovnaja) in Eighteenth-Century Russian Literary Culture, Ann Arbor, l977 (Copyright, October l977) 1972 M.A., University of Michigan, Ann Arbor, Michigan 1970 B.A., University of Minnesota (magna cum laude) 1964 Gymnasium in Prague, Czechoslovakia (summa cum laude [straight A average]) 4. Professional appointments (most recent first): Present (from 1975) Professor (Assistant, Associate, Full), Slavic Department, Brown University 2007-2017 (and 1976-91) Director of Graduate Studies, Slavic Dept, Brown University 2007 (Spring Sem.) Visiting Professor, Harvard University 2004 (Spring Sem.) Visiting Senior Professor, Charles University, Prague, Czech Republic 2004 (Spring Sem.) Visit. Senior Scholar, Collegium Hieronimus Pragensis, Prague, Czech Republic 1997-2003 Chair, Dept. of Slavic Languages, Brown University 2000 (Fall Semester) Visiting Senior Professor, Charles University, Prague, Czech Republic 1999-present Academic Advisory Board, Collegium Hieronimus Pragensis, Czech Rep. 1993-1994 Acting Chair, Dept. of Slavic Languages, Brown University 1993-present Full Professor, Brown University l983-1993 Associate Professor, Brown University l982 (Summer Sem.) Visiting Professor, Middlebury College l977-82 Assistant Professor, Brown University l975-l976 Instructor, Brown University l975 (Summer Sem.) Lecturer, Middlebury College l974-75 Teaching Assistant, University of Michigan 5. Completed Research, Scholarship and Creative Work (291 items in chronologically set groups a-i): A. -

Marginality and Variability in Esperanto
DOCUMENT RESUME ED 105 708 FL 005 381 AUTHOR Brent, Edmund TITLE Marginality and Variability in Esperanto. PUB DATE 28 Dec 73 NOTE 30p.; Paper presented at annual meeting of the Modern Language Association (88th, Chicago, Illinois, December 28, 1973); Best Copy Available EDRS PRICE EF-$0.76 HC-$1.95 PLUS POSTAGE DESCRIPTORS *Artificial Languages; Consonants; Diachronic Linguistics; Language Patterns; *Language Variation; Lexicolcgy; *Morphophonemics; Orthographic Symbols; Phonemics; Phonology; Sociolinguistics; Spelling; *Structural Analysis; *Synchronic Linguistics; Uncommonly Taught Languages; Vowels IDENTIFIERS *Esperanto ABSTRACT This paper discusses Esperanto as a planned language and refutes three myths connected to it, namely, that Esperanto is achronical, atopical, and apragmatic. The focus here is on a synchronic analysis. Synchronic variability is studied with reference to the structuralist determination of "marginality" and the dynamic linguistic description of "linguistic variables." Marginality is studied on the morphophonemic and on the lexical level. Linguistic variability is studied through a sociolinguistic survey. The sociolinguistic evidence is seen to converge with the structuralist evidence, and the synchronic analysis with earlier diachronic studies. It is hoped that this analysis will contribute toa redirection of scholarly work on Esperanto. (AM) ft'I,fF, zs- tom. ft ' t-' ."; rfl r4 ; fi S4* 3 4)4 r, J a. X PCY 114 MARGINALITY AND VARIABILITY IN ESPERANTO Paper prepared for Seminar 64, Esperanto Language and Literature 88th Annual Meeting of the Modern Language Association Chicago, Illinois December 28, 1973 by Edmund Brent Ontario Institute for Studies in Education and University of Toronto December 1973 PERMiSSON TO REPRODUCE THIS COPY. RIGHTED MA TERIAL HAS DEW GRANTED 131 U S DEPAR:Mr NT or HEALTH, EDUCATTOTt A WC. -
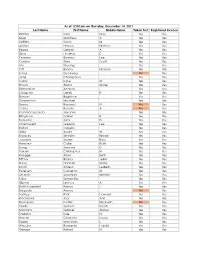
Last Name First Name Middle Name Taken Test Registered License
As of 12:00 am on Thursday, December 14, 2017 Last Name First Name Middle Name Taken Test Registered License Richter Sara May Yes Yes Silver Matthew A Yes Yes Griffiths Stacy M Yes Yes Archer Haylee Nichole Yes Yes Begay Delores A Yes Yes Gray Heather E Yes Yes Pearson Brianna Lee Yes Yes Conlon Tyler Scott Yes Yes Ma Shuang Yes Yes Ott Briana Nichole Yes Yes Liang Guopeng No Yes Jung Chang Gyo Yes Yes Carns Katie M Yes Yes Brooks Alana Marie Yes Yes Richardson Andrew Yes Yes Livingston Derek B Yes Yes Benson Brightstar Yes Yes Gowanlock Michael Yes Yes Denny Racheal N No Yes Crane Beverly A No Yes Paramo Saucedo Jovanny Yes Yes Bringham Darren R Yes Yes Torresdal Jack D Yes Yes Chenoweth Gregory Lee Yes Yes Bolton Isabella Yes Yes Miller Austin W Yes Yes Enriquez Jennifer Benise Yes Yes Jeplawy Joann Rose Yes Yes Harward Callie Ruth Yes Yes Saing Jasmine D Yes Yes Valasin Christopher N Yes Yes Roegge Alissa Beth Yes Yes Tiffany Briana Jekel Yes Yes Davis Hannah Marie Yes Yes Smith Amelia LesBeth Yes Yes Petersen Cameron M Yes Yes Chaplin Jeremiah Whittier Yes Yes Sabo Samantha Yes Yes Gipson Lindsey A Yes Yes Bath-Rosenfeld Robyn J Yes Yes Delgado Alonso No Yes Lackey Rick Howard Yes Yes Brockbank Taci Ann Yes Yes Thompson Kaitlyn Elizabeth No Yes Clarke Joshua Isaiah Yes Yes Montano Gabriel Alonzo Yes Yes England Kyle N Yes Yes Wiman Charlotte Louise Yes Yes Segay Marcinda L Yes Yes Wheeler Benjamin Harold Yes Yes George Robert N Yes Yes Wong Ann Jade Yes Yes Soder Adrienne B Yes Yes Bailey Lydia Noel Yes Yes Linner Tyler Dane Yes Yes -

In the Kingdom of Alexander the Great Ancient Macedonia
Advance press kit Exhibition From October 13, 2011 to January 16, 2012 Napoleon Hall In the Kingdom of Alexander the Great Ancient Macedonia Contents Press release page 3 Map of main sites page 9 Exhibition walk-through page 10 Images available for the press page 12 Press release In the Kingdom of Alexander the Great Exhibition Ancient Macedonia October 13, 2011–January 16, 2012 Napoleon Hall This exhibition curated by a Greek and French team of specialists brings together five hundred works tracing the history of ancient Macedonia from the fifteenth century B.C. up to the Roman Empire. Visitors are invited to explore the rich artistic heritage of northern Greece, many of whose treasures are still little known to the general public, due to the relatively recent nature of archaeological discoveries in this area. It was not until 1977, when several royal sepulchral monuments were unearthed at Vergina, among them the unopened tomb of Philip II, Alexander the Great’s father, that the full archaeological potential of this region was realized. Further excavations at this prestigious site, now identified with Aegae, the first capital of ancient Macedonia, resulted in a number of other important discoveries, including a puzzling burial site revealed in 2008, which will in all likelihood entail revisions in our knowledge of ancient history. With shrewd political skill, ancient Macedonia’s rulers, of whom Alexander the Great remains the best known, orchestrated the rise of Macedon from a small kingdom into one which came to dominate the entire Hellenic world, before defeating the Persian Empire and conquering lands as far away as India. -

Renegotiating Afrikaans-Based Identity Since 1994
Die Taal is Gans die Volk? Building a Common Afrikaans-Language Identity and Community in Post-Apartheid South Africa Susan DeMartino Advisor: Dr. Neville Alexander, PRAESA, UCT School for International Training Cape Town, South Africa: Multiculturalism and Social Change Spring 2009 Table of Contents Acknowledgements……………………………………………………………………3 Abstract………………………………………………………………………………..4 Introduction……………………………………………………………………………5 Literature Review……………………………………………………………………...7 Methodology…………………………………………………………………………13 Limitations of the Study……………………………………………………………...15 Body of Paper………………………………………………………………………… Fragile Identities from Historic Ideologies…………………………………..17 Legislation to Combat Linguistic Ideologies………………………………...19 Depoliticizing Afrikaans……………………………………………………..21 Shifting Towards English…………………………………………………….23 Racial Exclusivity and Linguistic Inclusivity………………………………..24 The Afrikaans Movements…………………………………………………...26 Building a “New, Inclusive, Afrikaans Community”………………………...28 Afrikaans as a Model for the South African Indigenous Languages………...31 Afrikaans in a Multilingual South Africa…………………………………….33 Conclusions………………………………………………………………………......35 Recommendations for Further Study………………………………………………...36 Bibliography………………………………………………………………………….37 Appendices……………………………………………………………………………. I: Excerpt from 1996 Constitution: Founding Provision 6 Languages………39 II: 2004 Western Cape Language Policy……………………………………..40 III: Interview Questions………………………………………………………44 2 Acknowledgements I would like to extend great thanks to -

Key Officers List (UNCLASSIFIED)
United States Department of State Telephone Directory This customized report includes the following section(s): Key Officers List (UNCLASSIFIED) 9/13/2021 Provided by Global Information Services, A/GIS Cover UNCLASSIFIED Key Officers of Foreign Service Posts Afghanistan FMO Inna Rotenberg ICASS Chair CDR David Millner IMO Cem Asci KABUL (E) Great Massoud Road, (VoIP, US-based) 301-490-1042, Fax No working Fax, INMARSAT Tel 011-873-761-837-725, ISO Aaron Smith Workweek: Saturday - Thursday 0800-1630, Website: https://af.usembassy.gov/ Algeria Officer Name DCM OMS Melisa Woolfolk ALGIERS (E) 5, Chemin Cheikh Bachir Ibrahimi, +213 (770) 08- ALT DIR Tina Dooley-Jones 2000, Fax +213 (23) 47-1781, Workweek: Sun - Thurs 08:00-17:00, CM OMS Bonnie Anglov Website: https://dz.usembassy.gov/ Co-CLO Lilliana Gonzalez Officer Name FM Michael Itinger DCM OMS Allie Hutton HRO Geoff Nyhart FCS Michele Smith INL Patrick Tanimura FM David Treleaven LEGAT James Bolden HRO TDY Ellen Langston MGT Ben Dille MGT Kristin Rockwood POL/ECON Richard Reiter MLO/ODC Andrew Bergman SDO/DATT COL Erik Bauer POL/ECON Roselyn Ramos TREAS Julie Malec SDO/DATT Christopher D'Amico AMB Chargé Ross L Wilson AMB Chargé Gautam Rana CG Ben Ousley Naseman CON Jeffrey Gringer DCM Ian McCary DCM Acting DCM Eric Barbee PAO Daniel Mattern PAO Eric Barbee GSO GSO William Hunt GSO TDY Neil Richter RSO Fernando Matus RSO Gregg Geerdes CLO Christine Peterson AGR Justina Torry DEA Edward (Joe) Kipp CLO Ikram McRiffey FMO Maureen Danzot FMO Aamer Khan IMO Jaime Scarpatti ICASS Chair Jeffrey Gringer IMO Daniel Sweet Albania Angola TIRANA (E) Rruga Stavro Vinjau 14, +355-4-224-7285, Fax +355-4- 223-2222, Workweek: Monday-Friday, 8:00am-4:30 pm. -

“Doing an Alexander:”
Faculty & Research “Doing an Alexander”: Lessons on Leadership by a Master Conqueror by M. Kets de Vries 2003/16/ENT Working Paper Series “Doing an Alexander”: Lessons on Leadership by a Master * Conqueror ** Manfred F. R. Kets de Vries * Exerpt from the book Are Leaders Born or Are They Made? The Case of Alexander the Great ** Raoul de Vitry d’Avaucourt Clinical Professor in Leadership Development, INSEAD, France & Singapore 1 Abstract The objective of this article is to explore what make for effective leadership and what contributes to leadership derailment. For the purpose of elucidation, one of the most famous leaders of all times has been selected: Alexander the Great of Macedonia, who more than any other person changed the history of civilization. His life-story illustrates the psychological forces that generally come into play in the making of a leader and reveals leadership lessons that can be learned from his actions. Included among the leadership lessons taught by Alexander are a compelling vision, the role of strategic innovation, the creation of an executive role constellation, the management of meaning, “praise- singing,” training and development, succession planning, and the importance of well-structured system of organizational governance. KEY WORDS: charisma; leadership; hubris; cyclothymia; narcissism; megalomania; paranoia; vision; innovation; executive role constellation; management of meaning; praise-singing; succession planning; organizational governance. 2 My son, ask for thyself another kingdom, For that which I leave is too small for thee. —King Philip, to his 16-year-old son, Alexander (the Great) Alexander the Great is often considered the most successful world leader in history. -

THE ALEXANDER ROMANCE in the ARABIC TRADITION Z. David
CHAPTER FOUR THE ALEXANDER ROMANCE IN THE ARABIC TRADITION Z. David Zuwiyya Introduction Alexander’s story permeated many genres of medieval Arabic litera- ture including history, geography, wisdom literature, Quranic exe- gesis, and stories of the prophets. For some he was considered nabī [prophet], while for others he was walī Allah [friend of God]. They called him Dhulqarnayn—the Two-Horned—and al-Iskandar. Some authors joined the two figures while others treated them separately. Al-Τ̣abarī, a ninth-century author, reflects the dichotomy surround- ing the Macedonian conqueror by narrating Dhulqarnayn’s life and deeds in his Tafsīr, an exegetical study of the Quran, and Alexander’s story in his Taʾrīkh [annales], an historical work. News of Alexander may have reached Arabia from the Syriac as early as 514 A.D.1 and circulated orally in Mecca and Medina before the revelation of the Quran since it is included in sura 18:83–98. Fahd says that a second version of the Alexander romance was translated directly from Pehlevi into Arabic and used by the early historians (30). Given the nature of the Quranic account, it was probably not Quintus Curtius, Arrian, or Plutarch who contributed to the original Arabian conception of Alexander, but rather the legendary material that spawned from the Alexander romance. With the expansion of the Islamic empire, Ara- bic authors gathered legends concerning Alexander from Persia in the east to al-Andalus in the west and blended them with material from the Pseudo-Callisthenes (PC). As part of the adoption process, 1 A.R. Nykl (ed.), Rrekontamiento del rrey Alisandre, in Revue Hispanique 77 (1929), pp. -

" class="text-overflow-clamp2"> The Politics of Language Planning in Post-Apartheid South Africa"SUBJECT "LPLP, Volume 28:2"KEYWORDS ""SIZE HEIGHT "240"WIDTH "160"VOFFSET "2">
<TARGET "ale" DOCINFO AUTHOR "Neville Alexander"TITLE "The politics of language planning in post-apartheid South Africa"SUBJECT "LPLP, Volume 28:2"KEYWORDS ""SIZE HEIGHT "240"WIDTH "160"VOFFSET "2"> The politics of language planning in post-apartheid South Africa Neville Alexander University of Cape Town There is no politically neutral theory of language planning, in spite of the fact that the power elites tend only to examine language policy under condi- tions of crisis. In South Africa, language planning was associated with the discredited racist social engineering of the apartheid era, especially because of the deleterious effects of Bantu education and because of the stigma of collaboration that came to be attached to the Bantu language boards. The same conditions, however, gave rise to an enduring ethos of democratic language planning (by NGOs and by some community-based organisations). This tradition, together with the peculiarities of the negotiated settlement, has had a lasting influence on the character and modalities of language planning agencies in post-apartheid South Africa. The article explores the implications of consociational and orthodox liberal democratic approaches for language planning in South Africa and underlines the persuasive effects of integrating a costing component into every language planning proposal, given the tendency of middle-class elites to exaggerate the economic cost of any policy change. Two points of theory A few futile attempts have been made from time to time to put forward ideologically and politically “neutral” theories of language planning.1 In the real world, all language planning, even that which denies that it is language plan- ning, serves specific ideological and political ends. -

National Myths in Interdependence
National Myths in Interdependence: The Narratives of the Ancient Past among Macedonians and Albanians in the Republic of Macedonia after 1991 By Matvey Lomonosov Submitted to Central European University Nationalism Studies Program In partial fulfillment of the requirements for the degree of Master of Arts CEU eTD Collection Advisor: Professor Maria Kovács Budapest, Hungary 2012 Abstract The scholarship on national mythology primarily focuses on the construction of historical narratives within separate “nations,” and oftentimes presents the particular national ist elites as single authors and undisputable controllers of mythological versions of the past. However, the authorship and authority of the dominant national ist elites in designing particular narratives of the communal history is limited. The national past, at least in non- totalitarian societies, is widely negotiated, and its interpretation is always heteroglot . The particular narratives that come out of the dominant elites’ “think-tanks” get into a polyphonic discursive milieu discussing the past. Thus they become addressed to alternative narratives, agree with them, deny them or reinterpret them. The existence of those “other” narratives as well as the others’ authorship constitutes a specific factor in shaping mythopoeic activities of dominant political and intellectual national elites. Then, achieving personal or “national” goals by nationalists usually means doing so at the expense or in relations to the others. If in this confrontation the rivals use historical myths, the evolution of the later will depend on mutual responses. Thus national historical myths are constructed in dialogue, contain voices of the others, and have “other” “authors” from within and from without the nation in addition to “own” dominant national ist elite.