Decision Tree Learning– Solution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
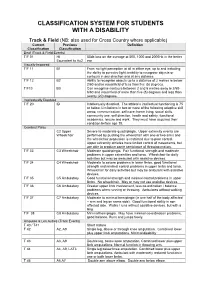
Disability Classification System
CLASSIFICATION SYSTEM FOR STUDENTS WITH A DISABILITY Track & Field (NB: also used for Cross Country where applicable) Current Previous Definition Classification Classification Deaf (Track & Field Events) T/F 01 HI 55db loss on the average at 500, 1000 and 2000Hz in the better Equivalent to Au2 ear Visually Impaired T/F 11 B1 From no light perception at all in either eye, up to and including the ability to perceive light; inability to recognise objects or contours in any direction and at any distance. T/F 12 B2 Ability to recognise objects up to a distance of 2 metres ie below 2/60 and/or visual field of less than five (5) degrees. T/F13 B3 Can recognise contours between 2 and 6 metres away ie 2/60- 6/60 and visual field of more than five (5) degrees and less than twenty (20) degrees. Intellectually Disabled T/F 20 ID Intellectually disabled. The athlete’s intellectual functioning is 75 or below. Limitations in two or more of the following adaptive skill areas; communication, self-care; home living, social skills, community use, self direction, health and safety, functional academics, leisure and work. They must have acquired their condition before age 18. Cerebral Palsy C2 Upper Severe to moderate quadriplegia. Upper extremity events are Wheelchair performed by pushing the wheelchair with one or two arms and the wheelchair propulsion is restricted due to poor control. Upper extremity athletes have limited control of movements, but are able to produce some semblance of throwing motion. T/F 33 C3 Wheelchair Moderate quadriplegia. Fair functional strength and moderate problems in upper extremities and torso. -

What Are We Doing with (Or To) the F-Scale?
5.6 What Are We Doing with (or to) the F-Scale? Daniel McCarthy, Joseph Schaefer and Roger Edwards NOAA/NWS Storm Prediction Center Norman, OK 1. Introduction Dr. T. Theodore Fujita developed the F- Scale, or Fujita Scale, in 1971 to provide a way to compare mesoscale windstorms by estimating the wind speed in hurricanes or tornadoes through an evaluation of the observed damage (Fujita 1971). Fujita grouped wind damage into six categories of increasing devastation (F0 through F5). Then for each damage class, he estimated the wind speed range capable of causing the damage. When deriving the scale, Fujita cunningly bridged the speeds between the Beaufort Scale (Huler 2005) used to estimate wind speeds through hurricane intensity and the Mach scale for near sonic speed winds. Fujita developed the following equation to estimate the wind speed associated with the damage produced by a tornado: Figure 1: Fujita's plot of how the F-Scale V = 14.1(F+2)3/2 connects with the Beaufort Scale and Mach number. From Fujita’s SMRP No. 91, 1971. where V is the speed in miles per hour, and F is the F-category of the damage. This Amazingly, the University of Oklahoma equation led to the graph devised by Fujita Doppler-On-Wheels measured up to 318 in Figure 1. mph flow some tens of meters above the ground in this tornado (Burgess et. al, 2002). Fujita and his staff used this scale to map out and analyze 148 tornadoes in the Super 2. Early Applications Tornado Outbreak of 3-4 April 1974. -

Reframing Sport Contexts: Labeling, Identities, and Social Justice
Reframing Sport Contexts: Labeling, Identities, and Social Justice Dr. Ted Fay and Eli Wolff Sport in Society Disability in Sport Initiative Northeastern University Critical Context • Marginalization (Current Status Quo) vs. • Legitimatization (New Inclusive Paradigm) Critical Context Naturalism vs. Trans-Humanism (Wolbring, G. (2009) How Do We Handle Our Differences related to Labeling Language and Cultural Identities? • Stereotyping? • Prejudice? • Discrimination? (Carr-Ruffino, 2003, p. 1) Ten Major Cultural Differences 1) Source of Control 2) Collectivism or Individualism 3) Homogeneous or Heterogeneous 4) Feminine or Masculine 5) Rank Status 6) Risk orientation 7) Time use 8) Space use 9) Communication Style 10) Economic System (Carr – Ruffino, 2003, p.27) Rationale for Inclusion • Divisioning by classification relative to “fair play” and equity principles • Sport model rather than “ism” segregated model (e.g., by race, gender, disability, socio-economic class, sexual orientation, look (body image), sect (religion), age) • Legitimacy • Human rights and equality Social Dynamics of Inequality Reinforce and reproduce Social Institutions Ideology Political (Patriarchy) Economic Educational Perpetuates Religious Prejudice & Are institutionalized by Discrimination Cultural Practices (ISM) Sport Music Art (Sage, 1998) Five Interlinking Conceptual Frameworks • Critical Change Factors Model (CCFM) • Organizational Continuum in Sport Governance (OCSG) • Criteria for Inclusion in Sport Organizations (CISO) • Individual Multiple Identity Sport Classifications Index (IMISCI) • Sport Opportunity Spectrum (SOS) Critical Change Factors Model (CCFM) F1) Change/occurrence of major societal event (s) affecting public opinion toward ID group. F2) Change in laws, government and court action in changing public policies toward ID group. F3) Change in level of influence of high profile ID group role models on public opinion. -

Connexion Client Cataloging Quick Reference
OCLC Connexion Client Cataloging Quick Reference Introduction Keystroke shortcuts The Connexion client is a Windows-based interface to OCLC • Use default keystroke shortcuts or assign your own to activate Connexion® used to access WorldCat for cataloging. commands, insert characters, run macros, and insert text strings. This quick reference provides brief instructions for editing, saving, • View key assignments in View > Assigned Keys.To print or copy exporting, and printing labels for bibliographic records; using local files; the list, click Print or Copy to Clipboard. creating and adding records to WorldCat; replacing WorldCat records; Tip: Before printing, click a column heading to sort the list by data batch processing; and cataloging with non-Latin scripts. in the column. • Assign your own keystrokes in Tools > Keymaps. Multiscript support: The client supports the following non-Latin scripts: • Print a function key template to put at the top of your keyboard: Arabic, Armenian, Bengali, Chinese, Cyrillic, Devanagari, Ethiopic, Greek, Hebrew, Japanese, Korean, Syriac, Tamil, and Thai. www.oclc.org/support/documentation/connexion/client/ gettingstarted/keyboardtemplate.pdf. This quick reference does not cover instructions for authorities work or instructions already available in: Toolbar • Getting Started with Connexion Client • The client installs with three toolbars displayed by default: • Connexion Client Setup Worksheet o Main client toolbar (with command-equivalent buttons) • Connexion: Searching WorldCat Quick Reference o WorldCat quick search tool Quick tools for text strings and user tools Connexion client documentation assumes knowledge of MARC o cataloging. • Customize the main client toolbar: In Tools > Toolbar Editor, drag and drop buttons to add or remove, or reset to the default. -

The ICD-10 Classification of Mental and Behavioural Disorders Diagnostic Criteria for Research
The ICD-10 Classification of Mental and Behavioural Disorders Diagnostic criteria for research World Health Organization Geneva The World Health Organization is a specialized agency of the United Nations with primary responsibility for international health matters and public health. Through this organization, which was created in 1948, the health professions of some 180 countries exchange their knowledge and experience with the aim of making possible the attainment by all citizens of the world by the year 2000 of a level of health that will permit them to lead a socially and economically productive life. By means of direct technical cooperation with its Member States, and by stimulating such cooperation among them, WHO promotes the development of comprehensive health services, the prevention and control of diseases, the improvement of environmental conditions, the development of human resources for health, the coordination and development of biomedical and health services research, and the planning and implementation of health programmes. These broad fields of endeavour encompass a wide variety of activities, such as developing systems of primary health care that reach the whole population of Member countries; promoting the health of mothers and children; combating malnutrition; controlling malaria and other communicable diseases including tuberculosis and leprosy; coordinating the global strategy for the prevention and control of AIDS; having achieved the eradication of smallpox, promoting mass immunization against a number of other -

Spinal Fractures Classification System an Aospine Knowledge Forum Initiative
Spinal Fractures Classification System an AOSpine Knowledge Forum initiative Subaxial Spine Fractures Thoracolumbar Spine Fractures Sacral Spine Fractures AOSpine–the leading global academic community for innovative education and research in spine care, inspiring lifelong learning and improving patients’ lives. Spinal Fractures Classification System 2 Spinal Fractures Classification System an AOSpine Knowledge Forum initiative CONTENT AOSpine Classification and Injury Severity System ................ 04 for Traumatic Fractures of the Subaxial Spine AOSpine Classification and Injury Severity System ................. 37 for Traumatic Fractures of the Thoracolumbar Spine AOSpine Classification and Injury Severity System .................55 for Traumatic Fractures of the Sacral Spine Spinal Fractures Classification System 3 AOSpine Knowledge Forum AOSpine Classification and Injury Severity System for Traumatic Fractures of the Subaxial Spine This is the present form of the classification the AOSpine Knowledge Forum (KF) SCI & Trauma is working on. It is the aim of the KF to develop a system, which can in the future be used as a tool for scientific research and a guide for treatment. This system is being subjected to a rigorous scientific assessment. Project members Aarabi B, Bellabarba C, Chapman J, Dvorak M, Fehlings M, Kandziora F, Kepler C, (in alphabetic order) Oner C, Rajasekaran S, Reinhold M, Schnake K, Vialle L and Vaccaro A. Disclaimer 1. Vaccaro, A. R., J. D. Koerner, K. E. Radcliff, F. C. Oner, M. Reinhold, K. J. Schnake, F. Kandziora, M. G. Fehlings, M. F. Dvorak, B. Aarabi, S. Rajasekaran, G. D. Schroeder, C. K. Kepler and L. R. Vialle (2015). “AOSpine subaxial cervical spine injury classification system.” Eur Spine J. 2. International validation process to be completed in 2015. -

The International Snowboard / Freestyle Ski / Freeski Competition Rules (Icr)
THE INTERNATIONAL SNOWBOARD / FREESTYLE SKI / FREESKI COMPETITION RULES (ICR) BOOK VI JOINT REGULATIONS FOR SNOWBOARD / FREESTYLE SKI / FREESKI SNOWBOARD SLALOM / GIANT SLALOM SNOWBOARD PARALLEL EVENTS SNOWBOARD CROSS SNOWBOARD HALFPIPE SNOWBOARD BIG AIR SNOWBOARD SLOPESTYLE AERIALS MOGULS DUAL MOGULS SKI CROSS FREESKI HALFPIPE FREESKI BIG AIR FREESKI SLOPESTYLE APPROVED BY THE FIS COUNCIL ONLINE MEETING – OCTOBER 2020 INCL. PRECISIONS FALL 2018 EDITION November 2020 INTERNATIONAL SKI FEDERATION FEDERATION INTERNATIONALE DE SKI INTERNATIONALER SKI VERBAND Blochstrasse 2, CH-3653 Oberhofen / Thunersee, Switzerland Telephone: +41 33 244 61 61 Fax: +41 33 244 61 71 Website: www.fis.ski.com Email: [email protected] ________________________________________________________________________ © Copyright: International Ski Federation FIS, Oberhofen, Switzerland, 2020. No part of this book may be reproduced in any form or by any means without the written permis- sion of the International Ski Federation. Printed in Switzerland Oberhofen, 30th November 2020 2 Table of Contents 1st Section 200 Joint Regulations for all Competitions .............................................. 11 201 Classification and Types of Competitions ......................................... 11 202 FIS Calendar .................................................................................... 13 203 Licence to participate in FIS Races (FIS Licence) ............................ 14 204 Qualification of Competitors ............................................................ -

Implicit Equilibrium Dynamics∗
Implicit Equilibrium Dynamics∗ Alfredo Medio∗∗ and Brian Raines∗∗∗ ∗∗ Department of Statistics, University of Udine, Via Treppo 18, 33100, Udine, Italy ∗∗∗ Department of Mathematics, Baylor University, Waco, Texas, USA ∗ The authors would like to thank the Associate Editor of MD and two anonymous referees for many comments and criticisms which helped us correct several errors and significantly improve the quality of the paper. We are also grateful to Artur Avila and Duncan Sands for some very stimulating e.mail conversations that clarified a number of difficult questions concerning the dynamics of unimodal maps. The authors are of course solely responsible for any remaining errors or misunderstandings. 2 Running head: Implicit Dynamics Corresponding author: Alfredo Medio, Department of Statistics, University of Udine, Via Treppo 18, 33100, Udine, Italy, Telephone: +39 0432 249584, Fax: +39 0432 249595, e.mail: [email protected] 3 Abstract We discuss the problem known in economics as \backward dynamics (BD)" occurring in models of perfect foresight, intertemporal equilibrium described mathematically by implicit difference equations. In a previously published paper (Medio and Raines, 2007) we showed that by means of certain mathematical methods and results known as \inverse limits theory (ILT)" it is possible to establish a correspondence between backward dynamics of a non-invertible map and forward dynamics of a related, in- vertible map acting on an appropriately defined space of sequences, each of whose elements corresponds to an intertemporal equilibrium. We also proved the existence of different types of topological attractors for one{dimensional models of overlapping generations. In this paper, we provide an extension of those results, constructing a Lebesgue{like probability measure on spaces of infinite sequences that allows us to distinguish typical from exceptional dynamical behaviors in a measure{theoretical sense, thus proving that all the topological attractors considered in MR07 are also metric attractors. -

Screening Experiments with Maximally Balanced Projections Tim Kramer and Shankar Vaidyaraman October 2019 Overview
Screening Experiments with Maximally Balanced Projections Tim Kramer and Shankar Vaidyaraman October 2019 Overview • Design focus – screening and robustness studies • Orthogonality, near-orthogonality and balanced projections • Some examples • Outline of design optimization strategies • Benefits and drawbacks • Summary Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 2 Screening Designs • Many potential factors • Few factors will likely have large impact • Experimental setup may impose balance constraints (e.g. plates with fixed wells per plate) • Some factors will necessarily have more than two levels (solvents, HPLC column types, equipment types,…) • Prediction confidence increases if design projects into full-factorial experiment for active factors Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 3 Robustness Designs • Goal is not to identify impact of any specific factor • Identify whether quality attribute is acceptable when an individual factor or combination of factors are at their extreme values – Want worst case combination of 1, 2, 3,… factors Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 4 Special Case Designs • Calibration Designs: one key factor (e.g. concentration) in the presence of many noise factors • Split Plot and Blocked Designs: Multiple factors applied to a set of plots or blocks Box Centenary, October 2019 Company Confidential (c) 2019 Eli Lilly and Company 5 2-Dimensional Projections of Standard 2^3 Half- Fraction Design -

Research Article KINEMATIC ANALYSIS of JAVELIN THROW
©Journal of Sports Science and Medicine (2003) 2, 36-46 http://www.jssm.org Research article KINEMATIC ANALYSIS OF JAVELIN THROW PERFORMED BY WHEELCHAIR ATHLETES OF DIFFERENT FUNCTIONAL CLASSES John W. Chow 1 *, Ann F. Kuenster 2 and Young-tae Lim 3 1Department of Exercise and Sport Sciences, University of Florida, Gainesville, USA 2Department of Kinesiology, University of Illinois at Urbana-Champaign, USA 3Division of Sport Science, Konkuk University, Chungju, Korea Received: 10 December 2002 / Accepted: 07 February 2003 / Published (online): 01 June 2003 ABSTRACT The purpose of this study was to identify those kinematic characteristics that are most closely related to the functional classification of a wheelchair athlete and measured distance of a javelin throw. Two S- VHS camcorders (60 field· s-1) were used to record the performance of 15 males of different classes. Each subject performed 6 - 10 throws and the best two legal throws from each subject were selected for analysis. Three-dimensional kinematics of the javelin and upper body segments at the instant of release and during the throw (delivery) were determined. The selection of kinematic parameters that were analyzed in this study was based on a javelin throw model showing the factors that determine the measured distance of a throw. The average of two throws for each subject was used to compute Spearman rank correlation coefficients between selected parameters and measured distance, and between selected parameters and the functional classification. The speeds and angles of the javelin at release, ranged from 9.1 to 14.7 m· s-1 and 29.6 to 35.8º, respectively, were smaller than those exhibited by elite male able-bodied throwers. -

Letters to Assessors 2006-010
STATE OF CALIFORNIA BETTY T. YEE STATE BOARD OF EQUALIZATION Acting Member PROPERTY AND SPECIAL TAXES DEPARTMENT First District, San Francisco 450 N STREET, SACRAMENTO, CALIFORNIA PO BOX 942879, SACRAMENTO, CALIFORNIA 94279-0064 BILL LEONARD Second District, Sacramento/Ontario 916 445-4982 FAX 916 323-8765 www.boe.ca.gov CLAUDE PARRISH Third District, Long Beach February 6, 2006 JOHN CHIANG Fourth District, Los Angeles STEVE WESTLY State Controller, Sacramento RAMON J. HIRSIG Executive Director No. 2006/010 CORRECTION TO COUNTY ASSESSORS: REVENUE AND TAXATION CODE SECTION 69.5: PROPOSITIONS 60, 90, AND 110 Section 69.5 was added to the Revenue and Taxation Code1 in 1987 to implement Proposition 60, which amended section 2 of article XIII A of the California Constitution to authorize the Legislature to provide for the transfer of a base year value from a principal residence2 to a replacement dwelling within the same county by a homeowner age 55 and over. Subsequently, section 69.5 was amended to implement Proposition 90, which authorized county boards of supervisors to adopt ordinances allowing base year value transfers between different counties, and Proposition 110, which extended these provisions to severely and permanently disabled persons of any age. After summarizing the key elements of section 69.5, this letter provides answers to frequently asked questions about its application. This letter supersedes Letters To Assessors No. 87/71 (dated September 11, 1987) and No. 88/10 (dated February 11, 1988). SUMMARY OF SECTION 69.5 Section 69.5 allows a homeowner to transfer the existing base year value to a replacement dwelling provided that: • If the replacement property is located in a different county than the original property, then the county in which the replacement dwelling is located must have a current ordinance allowing base year value transfers from other counties. -

A Guide to F-Scale Damage Assessment
A Guide to F-Scale Damage Assessment U.S. DEPARTMENT OF COMMERCE National Oceanic and Atmospheric Administration National Weather Service Silver Spring, Maryland Cover Photo: Damage from the violent tornado that struck the Oklahoma City, Oklahoma metropolitan area on 3 May 1999 (Federal Emergency Management Agency [FEMA] photograph by C. Doswell) NOTE: All images identified in this work as being copyrighted (with the copyright symbol “©”) are not to be reproduced in any form whatsoever without the expressed consent of the copyright holders. Federal Law provides copyright protection of these images. A Guide to F-Scale Damage Assessment April 2003 U.S. DEPARTMENT OF COMMERCE Donald L. Evans, Secretary National Oceanic and Atmospheric Administration Vice Admiral Conrad C. Lautenbacher, Jr., Administrator National Weather Service John J. Kelly, Jr., Assistant Administrator Preface Recent tornado events have highlighted the need for a definitive F-scale assessment guide to assist our field personnel in conducting reliable post-storm damage assessments and determine the magnitude of extreme wind events. This guide has been prepared as a contribution to our ongoing effort to improve our personnel’s training in post-storm damage assessment techniques. My gratitude is expressed to Dr. Charles A. Doswell III (President, Doswell Scientific Consulting) who served as the main author in preparing this document. Special thanks are also awarded to Dr. Greg Forbes (Severe Weather Expert, The Weather Channel), Tim Marshall (Engineer/ Meteorologist, Haag Engineering Co.), Bill Bunting (Meteorologist-In-Charge, NWS Dallas/Fort Worth, TX), Brian Smith (Warning Coordination Meteorologist, NWS Omaha, NE), Don Burgess (Meteorologist, National Severe Storms Laboratory), and Stephan C.