Integrating Multiple Data Views for Improved Malware Analysis Blake Anderson
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A the Hacker
A The Hacker Madame Curie once said “En science, nous devons nous int´eresser aux choses, non aux personnes [In science, we should be interested in things, not in people].” Things, however, have since changed, and today we have to be interested not just in the facts of computer security and crime, but in the people who perpetrate these acts. Hence this discussion of hackers. Over the centuries, the term “hacker” has referred to various activities. We are familiar with usages such as “a carpenter hacking wood with an ax” and “a butcher hacking meat with a cleaver,” but it seems that the modern, computer-related form of this term originated in the many pranks and practi- cal jokes perpetrated by students at MIT in the 1960s. As an example of the many meanings assigned to this term, see [Schneier 04] which, among much other information, explains why Galileo was a hacker but Aristotle wasn’t. A hack is a person lacking talent or ability, as in a “hack writer.” Hack as a verb is used in contexts such as “hack the media,” “hack your brain,” and “hack your reputation.” Recently, it has also come to mean either a kludge, or the opposite of a kludge, as in a clever or elegant solution to a difficult problem. A hack also means a simple but often inelegant solution or technique. The following tentative definitions are quoted from the jargon file ([jargon 04], edited by Eric S. Raymond): 1. A person who enjoys exploring the details of programmable systems and how to stretch their capabilities, as opposed to most users, who prefer to learn only the minimum necessary. -

Synthesizing Near-Optimal Malware Specifications from Suspicious
Synthesizing Near-Optimal Malware Specifications from Suspicious Behaviors Somesh Jha∗, Matthew Fredrikson∗, Mihai Christodoresu†, Reiner Sailer‡, Xifeng Yan§ ∗University of Wisconsin–Madison, †Qualcomm Research Silicon Valley, ‡IBM T.J Watson Research Center, §University of California–Santa Barbara Abstract—Behavior-based detection techniques are a promis- and errors. ing solution to the problem of malware proliferation. However, We make the observation that behavioral specifications they require precise specifications of malicious behavior that do not result in an excessive number of false alarms, while still are best viewed as a form of discriminative specification.A remaining general enough to detect new variants before tradi- discriminative specification describes the unique properties tional signatures can be created and distributed. In this paper, of a given class, in contrast to the properties exhibited by we present an automatic technique for extracting optimally discriminative specifications a second mutually-exclusive class. This paper presents an , which uniquely identify a class automated technique that combines program analysis, graph of programs. Such a discriminative specification can be used by a behavior-based malware detector. Our technique, based mining, and stochastic optimization to synthesize malware on graph mining and stochastic optimization, scales to large behavior specifications. We represent program behaviors as classes of programs. When this work was originally published, graphs that are mined for discriminative patterns. As there the technique yielded favorable results on malware targeted are many ways in which malware can accomplish the same towards workstations (~86% detection rates on new malware). goal, we use these patterns as building blocks for construct- We believe that it can be brought to bear on emerging malware- based threats for new platforms, and discuss several promising ing discriminative specifications that are general across vari- avenues for future work in this direction. -

Cyber Warfare a “Nuclear Option”?
CYBER WARFARE A “NUCLEAR OPTION”? ANDREW F. KREPINEVICH CYBER WARFARE: A “NUCLEAR OPTION”? BY ANDREW KREPINEVICH 2012 © 2012 Center for Strategic and Budgetary Assessments. All rights reserved. About the Center for Strategic and Budgetary Assessments The Center for Strategic and Budgetary Assessments (CSBA) is an independent, nonpartisan policy research institute established to promote innovative thinking and debate about national security strategy and investment options. CSBA’s goal is to enable policymakers to make informed decisions on matters of strategy, secu- rity policy and resource allocation. CSBA provides timely, impartial, and insight- ful analyses to senior decision makers in the executive and legislative branches, as well as to the media and the broader national security community. CSBA encour- ages thoughtful participation in the development of national security strategy and policy, and in the allocation of scarce human and capital resources. CSBA’s analysis and outreach focus on key questions related to existing and emerging threats to US national security. Meeting these challenges will require transforming the national security establishment, and we are devoted to helping achieve this end. About the Author Dr. Andrew F. Krepinevich, Jr. is the President of the Center for Strategic and Budgetary Assessments, which he joined following a 21-year career in the U.S. Army. He has served in the Department of Defense’s Office of Net Assessment, on the personal staff of three secretaries of defense, the National Defense Panel, the Defense Science Board Task Force on Joint Experimentation, and the Defense Policy Board. He is the author of 7 Deadly Scenarios: A Military Futurist Explores War in the 21st Century and The Army and Vietnam. -

The Botnet Chronicles a Journey to Infamy
The Botnet Chronicles A Journey to Infamy Trend Micro, Incorporated Rik Ferguson Senior Security Advisor A Trend Micro White Paper I November 2010 The Botnet Chronicles A Journey to Infamy CONTENTS A Prelude to Evolution ....................................................................................................................4 The Botnet Saga Begins .................................................................................................................5 The Birth of Organized Crime .........................................................................................................7 The Security War Rages On ........................................................................................................... 8 Lost in the White Noise................................................................................................................. 10 Where Do We Go from Here? .......................................................................................................... 11 References ...................................................................................................................................... 12 2 WHITE PAPER I THE BOTNET CHRONICLES: A JOURNEY TO INFAMY The Botnet Chronicles A Journey to Infamy The botnet time line below shows a rundown of the botnets discussed in this white paper. Clicking each botnet’s name in blue will bring you to the page where it is described in more detail. To go back to the time line below from each page, click the ~ at the end of the section. 3 WHITE -

MODELING the PROPAGATION of WORMS in NETWORKS: a SURVEY 943 in Section 2, Which Set the Stage for Later Sections
942 IEEE COMMUNICATIONS SURVEYS & TUTORIALS, VOL. 16, NO. 2, SECOND QUARTER 2014 Modeling the Propagation of Worms in Networks: ASurvey Yini Wang, Sheng Wen, Yang Xiang, Senior Member, IEEE, and Wanlei Zhou, Senior Member, IEEE, Abstract—There are the two common means for propagating attacks account for 1/4 of the total threats in 2009 and nearly worms: scanning vulnerable computers in the network and 1/5 of the total threats in 2010. In order to prevent worms from spreading through topological neighbors. Modeling the propa- spreading into a large scale, researchers focus on modeling gation of worms can help us understand how worms spread and devise effective defense strategies. However, most previous their propagation and then, on the basis of it, investigate the researches either focus on their proposed work or pay attention optimized countermeasures. Similar to the research of some to exploring detection and defense system. Few of them gives a nature disasters, like earthquake and tsunami, the modeling comprehensive analysis in modeling the propagation of worms can help us understand and characterize the key properties of which is helpful for developing defense mechanism against their spreading. In this field, it is mandatory to guarantee the worms’ spreading. This paper presents a survey and comparison of worms’ propagation models according to two different spread- accuracy of the modeling before the derived countermeasures ing methods of worms. We first identify worms characteristics can be considered credible. In recent years, although a variety through their spreading behavior, and then classify various of models and algorithms have been proposed for modeling target discover techniques employed by them. -
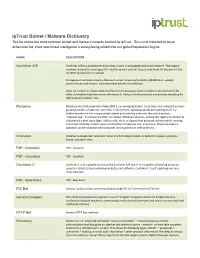
Iptrust Botnet / Malware Dictionary This List Shows the Most Common Botnet and Malware Variants Tracked by Iptrust
ipTrust Botnet / Malware Dictionary This list shows the most common botnet and malware variants tracked by ipTrust. This is not intended to be an exhaustive list, since new threat intelligence is always being added into our global Reputation Engine. NAME DESCRIPTION Conficker A/B Conficker A/B is a downloader worm that is used to propagate additional malware. The original malware it was after was rogue AV - but the army's current focus is undefined. At this point it has no other purpose but to spread. Propagation methods include a Microsoft server service vulnerability (MS08-067) - weakly protected network shares - and removable devices like USB keys. Once on a machine, it will attach itself to current processes such as explorer.exe and search for other vulnerable machines across the network. Using a list of passwords and actively searching for legitimate usernames - the ... Mariposa Mariposa was first observed in May 2009 as an emerging botnet. Since then it has infected an ever- growing number of systems; currently, in the millions. Mariposa works by installing itself in a hidden location on the compromised system and injecting code into the critical process ͞ĞdžƉůŽƌĞƌ͘ĞdžĞ͘͟/ƚŝƐknown to affect all modern Windows versions, editing the registry to allow it to automatically start upon login. Additionally, there is a guard that prevents deletion while running, and it automatically restarts upon crash/restart of explorer.exe. In essence, Mariposa opens a backdoor on the compromised computer, which grants full shell access to ... Unknown A botnet is designated 'unknown' when it is first being tracked, or before it is given a publicly- known common name. -

Computer Security Fundamentals Third Edition
Computer Security Fundamentals Third Edition Chuck Easttom 800 East 96th Street, Indianapolis, Indiana 46240 USA Computer Security Fundamentals, Third Edition Executive Editor Brett Bartow Copyright © 2016 by Pearson Education, Inc. All rights reserved. No part of this book shall be reproduced, stored in a retrieval system, or Acquisitions Editor transmitted by any means, electronic, mechanical, photocopying, recording, or otherwise, Betsy Brown without written permission from the publisher. No patent liability is assumed with respect Development Editor to the use of the information contained herein. Although every precaution has been taken in Christopher Cleveland the preparation of this book, the publisher and author assume no responsibility for errors or omissions. Nor is any liability assumed for damages resulting from the use of the information Managing Editor contained herein. Sandra Schroeder ISBN-13: 978-0-7897-5746-3 ISBN-10: 0-7897-5746-X Senior Project Editor Tonya Simpson Library of Congress control number: 2016940227 Copy Editor Printed in the United States of America Gill Editorial Services First Printing: May 2016 Indexer Brad Herriman Trademarks All terms mentioned in this book that are known to be trademarks or service marks have Proofreader been appropriately capitalized. Pearson IT Certification cannot attest to the accuracy of this Paula Lowell information. Use of a term in this book should not be regarded as affecting the validity of any trademark or service mark. Technical Editor Dr. Louay Karadsheh Warning and Disclaimer Publishing Coordinator Every effort has been made to make this book as complete and as accurate as possible, but Vanessa Evans no warranty or fitness is implied. -

Security Chapter
Barbarians at the Gateway (and just about everywhere else): A Brief Managerial Introduction to Information Security Issues1 a gallaugher.com case provided free to faculty & students for non-commercial use © Copyright 1997-2009, John M. Gallaugher, Ph.D. – for more info see: http://www.gallaugher.com/chapters.html Draft version last modified: Dec. 7 , 2009 – comments welcome [email protected] Note: this is an earlier version of the chapter. All chapters updated Dec. 2009 are now hosted (and still free) at http://www.flatworldknowledge.com. For details see the ‘Courseware’ section of http://gallaugher.com INTRODUCTION LEARNING OBJECTIVES: After studying this section you should be able to: 1. Recognize that information security breaches are on the rise. 2. Understand the potentially damaging impact of security breaches. 3. Recognize that information security must be made a top organizational priority. Sitting in the parking lot of a Minneapolis Marshalls, a hacker armed with a laptop and a telescope‐shaped antenna infiltrated the store’s network via an insecure Wi‐Fi base station. The attack launched what would become a billion‐dollar plus nightmare scenario for TJX, the parent of retail chains that include Marshalls, Home Goods, and T.J. Maxx. Over a period of several months, the hacker and his gang stole at least 45.7 million credit and debit card numbers, and pilfered driver’s license and other private information from an additional 450,000 customers2. TJX, at the time a $17.5 billion, Fortune 500 firm, was left reeling from the incident. The attack deeply damaged the firm’s reputation. -

Emerging Threats and Attack Trends
Emerging Threats and Attack Trends Paul Oxman Cisco Security Research and Operations PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 1 Agenda What? Where? Why? Trends 2008/2009 - Year in Review Case Studies Threats on the Horizon Threat Containment PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 2 What? Where? Why? PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 3 What? Where? Why? What is a Threat? A warning sign of possible trouble Where are Threats? Everywhere you can, and more importantly cannot, think of Why are there Threats? The almighty dollar (or euro, etc.), the underground cyber crime industry is growing with each year PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 4 Examples of Threats Targeted Hacking Vulnerability Exploitation Malware Outbreaks Economic Espionage Intellectual Property Theft or Loss Network Access Abuse Theft of IT Resources PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 5 Areas of Opportunity Users Applications Network Services Operating Systems PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 6 Why? Fame Not so much anymore (more on this with Trends) Money The root of all evil… (more on this with the Year in Review) War A battlefront just as real as the air, land, and sea PSIRT_2009 © 2009 Cisco Systems, Inc. All rights reserved. Cisco Public 7 Operational Evolution of Threats Emerging Threat Nuisance Threat Threat Evolution Unresolved Threat Policy and Process Reactive Process Socialized Process Formalized Process Definition Reaction Mitigation Technology Manual Process Human “In the Automated Loop” Response Evolution Burden Operational End-User “Help-Desk” Aware—Know End-User No End-User Increasingly Self- Awareness Knowledge Enough to Call Burden Reliant Support PSIRT_2009 © 2009 Cisco Systems, Inc. -

Download Slides
Scott Wu Point in time cleaning vs. RTP MSRT vs. Microsoft Security Essentials Threat events & impacts More on MSRT / Security Essentials MSRT Microsoft Windows Malicious Software Removal Tool Deployed to Windows Update, etc. monthly since 2005 On-demand scan on prevalent malware Microsoft Security Essentials Full AV RTP Inception in Oct 2009 RTP is the solution One-off cleaner has its role Quiikck response Workaround Baseline ecosystem cleaning Industrypy response & collaboration Threat Events Worms (some are bots) have longer lifespans Rogues move on quicker MarMar 2010 2010 Apr Apr 2010 2010 May May 2010 2010 Jun Jun 2010 2010 Jul Jul 2010 2010 Aug Aug 2010 2010 1,237,15 FrethogFrethog 979,427 979,427 Frethog Frethog 880,246880,246 Frethog Frethog465,351 TaterfTaterf 5 1,237,155Taterf Taterf 797,935797,935 TaterfTaterf 451,561451,561 TaterfTaterf 497,582 497,582 Taterf Taterf 393,729393,729 Taterf Taterf447,849 FrethogFrethog 535,627535,627 AlureonAlureon 493,150 493,150 AlureonAlureon 436,566 436,566 RimecudRimecud 371,646 371,646 Alureon Alureon 308,673308,673 Alureon Alureon 441,722 RimecudRimecud 341,778341,778 FrethogFrethog 473,996473,996 BubnixBubnix 348,120 348,120 HamweqHamweq 289,603 289,603 Rimecud Rimecud289,629 289,629 Rimecud Rimecud318,041 AlureonAlureon 292,810 292,810 BubnixBubnix 471,243 471,243 RimecudRimecud 287,942287,942 ConfickerConficker 286,091286, 091 Hamwe Hamweqq 250,286250, 286 Conficker Conficker220,475220, 475 ConfickerConficker 237237,348, 348 RimecudRimecud 280280,440, 440 VobfusVobfus 251251,335, 335 -

An Analysis of the Nature of Groups Engaged in Cyber Crime
International Journal of Cyber Criminology Vol 8 Issue 1 January - June 2014 Copyright © 2014 International Journal of Cyber Criminology (IJCC) ISSN: 0974 – 2891 January – June 2014, Vol 8 (1): 1–20. This is an Open Access paper distributed under the terms of the Creative Commons Attribution-Non- Commercial-Share Alike License, which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited. This license does not permit commercial exploitation or the creation of derivative works without specific permission. Organizations and Cyber crime: An Analysis of the Nature of Groups engaged in Cyber Crime Roderic Broadhurst,1 Peter Grabosky,2 Mamoun Alazab3 & Steve Chon4 ANU Cybercrime Observatory, Australian National University, Australia Abstract This paper explores the nature of groups engaged in cyber crime. It briefly outlines the definition and scope of cyber crime, theoretical and empirical challenges in addressing what is known about cyber offenders, and the likely role of organized crime groups. The paper gives examples of known cases that illustrate individual and group behaviour, and motivations of typical offenders, including state actors. Different types of cyber crime and different forms of criminal organization are described drawing on the typology suggested by McGuire (2012). It is apparent that a wide variety of organizational structures are involved in cyber crime. Enterprise or profit-oriented activities, and especially cyber crime committed by state actors, appear to require leadership, structure, and specialisation. By contrast, protest activity tends to be less organized, with weak (if any) chain of command. Keywords: Cybercrime, Organized Crime, Crime Groups; Internet Crime; Cyber Offenders; Online Offenders, State Crime. -

Information Assurance Situation in Switzerland and Internationally
Federal Strategy Unit for IT FSUIT Federal Intelligence Service FIS Reporting and Analysis Centre for Information Assurance MELANI www.melani.admin.ch Information Assurance Situation in Switzerland and Internationally Semi-annual report 2009/II (July – December) MELANI – Semi-annual report 2009/II Information Assurance – Situation in Switzerland and Internationally Contents 1 Focus Areas of Issue 2009/II .........................................................................................3 2 Introduction.....................................................................................................................4 3 Current National ICT Infrastructure Situation ..............................................................5 33.1.1 FDFA targeted by malware.................................................................................5 33.2.2 Website defacements after adoption of minaret ban initiative ............................5 33.3.3 DDoS attacks against Swisscom and Swisscom clients ....................................6 33.4.4 Fraud with fake domain registrations..................................................................7 33.5.5 Purported free offers against viruses, scareware, rogueware and ransomware 8 33.6.6 New top level domains (TLD) and high security zones in the Internet .............10 33.7.7 Revision of provisions implementing the Telecommunications Act ..................10 33.8.8 Skype wiretap published as source code .........................................................11 4 Current International ICT