Town Plans to Press for Sewer Ruling
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

General Versus Specific Sentences: Uta Omatic Identification and Application to Analysis of News Summaries
University of Pennsylvania ScholarlyCommons Technical Reports (CIS) Department of Computer & Information Science 1-1-2011 General Versus Specific Sentences: utA omatic Identification and Application to Analysis of News Summaries Annie Louis University of Pennsylvania Ani Nenkova Univesity of Pennsylvania, [email protected] Follow this and additional works at: https://repository.upenn.edu/cis_reports Recommended Citation Annie Louis and Ani Nenkova, "General Versus Specific Sentences: utA omatic Identification and Application to Analysis of News Summaries", . January 2011. University of Pennsylvania Department of Computer and Information Science Technical Report No. MS-CIS-11-07. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/cis_reports/951 For more information, please contact [email protected]. General Versus Specific Sentences: utA omatic Identification and Application ot Analysis of News Summaries Abstract In this paper, we introduce the task of identifying general and specific sentences in news articles. Instead of embarking on a new annotation effort to obtain data for the task, we explore the possibility of leveraging existing large corpora annotated with discourse information to train a classifier. We introduce several classes of features that capture lexical and syntactic information, as well as word specificity and polarity. We then use the classifier ot analyze the distribution of general and specific sentences in human and machine summaries of news articles. We discover that while all types of summaries tend to be more specific than the original documents, human abstracts contain a more balanced mix of general and specific sentences but automatic summaries are overwhelmingly specific. Our findings give strong evidence for the need for a new task in (abstractive) summarization: identification and generation of general sentences. -

Abbess-Elect Envisions Great U. S. Benedictine Convent Mullen High to Take Day Pupils Denvircatholic Work Halted on Ten Projects
Abbess-Elect Envisions Great U. S. Benedictine Convent Mother Augustina Returns to Germany Next Month But Her Heart Will Remain in Colorado A grgantic Benedioine convent, a St. Walburga’s of ser of Eichstaett. That day is the Feast of the Holy Name In 1949 when Mother Augustina visited the German as Abbess will be as custodian and distributor of the famed the West, is the W jo c h o p e envisioned by Mother M. of Mary, a name that Mother Augustina bears as'' a nun. mother-house and conferred with the late Lady Abbess Ben- St. Walburga oil. This oil exudes from the bones of the Augustina Weihermuellcrp^perior of St. Walbutga’s con The ceremony will be held in St. Walburga’s parish church edicta, whom she has succeeejed, among the subjects con saint, who founded the Benedictine community and lived vent in South Boulder, as she prepares to return to Ger and the cloistered nuns of the community will witness it sidered wJs the possibility of transferring the heart of the 710-780. Many remarkable cures have been attributed many to assume her position as, Lady Abbess at the mother- ffom their private choir. order to America if Russia should:overrun Europe! to its use while seeking the intercession o f St. Walburga. house of her community in Eidistaett, Bavaria. That day, just two months hence, will mark the first At the great St. Walburga’s mother-house in Eich 'Those who have heard Mother Augustina in one of her Mother Augustina’s departure for Europe is scheduled time that an American citizen ,has returned to Europe to staett, she will be superior of 130 sisters. -

2010 New York Marathon Statistical Information Men New York Marathon All Time List
2010 New York Marathon Statistical Information Men New York Marathon All Time list Performances Time Performers Name Nat Place Date 1 2:07:43 1 Tesfaye Jifar ETH 1 4 Nov 2001 2 2:08:01 2 Juma Ikangaa TAN 1 5 Nov 1989 3 2:08:07 3 Rodger Rop KEN 1 3 Nov 2002 4 2:08:12 4 John Kagwe KEN 1 2 Nov 1997 5 2:08:17 5 Christopher Cheboiboch KEN 2 3 Nov 2002 6 2:08:20 6 Steve Jones GBR 1 6 Nov 1988 7 2:08:39 7 Laban Kipkemboi KEN 3 3 Nov 2002 8 2:08:43 8 Marilson Gomes dos Santos BRA 1 2 Nov 2008 9 2:08:45 John Kagwe 1 1 Nov 1998 10 2:08:48 9 Joseph Chebet KEN 2 1 Nov 1998 11 2:08:51 10 Zebedayo Bayo TAN 3 1 Nov 1998 12 2:08:53 11 Mohamed Ouaadi FRA 4 3 Nov 2002 13 2:08:59 12 Rod Dixon NZL 1 23 Oct 1983 14 2:09:04 13 Martin Lel KEN 1 5 Nov 2007 15 2:09:07 14 Abderrahim Goumri MAR 2 2 Nov 2008 16 2:09:08 15 Geoff Smith GBR 2 23 Oct 1983 17 2:09:12 16 Stefano Baldini ITA 5 3 Nov 2002 18 2:09:14 Joseph Chebet 1 7 Nov 1999 19 2:09:15 17 Meb Keflezighi USA 1 1 Nov 2009 20 2:09:16 Abderrahim Goumri 2 4 Nov 2007 21 2:09:19 18 Japhet Kosgei KEN 2 4 Nov 2001 22 2:09:20 19 Domingos Castro POR 2 7 Nov 1999 23 2:09:27 Joseph Chebet 2 2 Nov 1997 24 2:09:28 20 Salvador Garcia MEX 1 3 Nov 1991 25 2:09:28 21 Hendrick Ramaala RSA 1 7 Nov 2004 26 2:09:29 22 Alberto Salazar USA 1 24 Oct 1982 27 2:09:29 23 Willie Mtolo RSA 1 1 Nov 1992 28 2:09:30 24 Paul Tergat KEN 1 6 Nov 2005 29 2:09:31 Stefano Baldini 3 2 Nov 1997 30 2:09:31 Hendrick Ramaala 2 6 Nov 2005 31 2:09:32 25 Shem Kororia KEN 3 7 Nov 1999 32 2:09:33 26 Rodolfo Gomez MEX 2 24 Oct 1982 33 2:09:36 27 Giacomo -

As Writers of Film and Television and Members of the Writers Guild Of
July 20, 2021 As writers of film and television and members of the Writers Guild of America, East and Writers Guild of America West, we understand the critical importance of a union contract. We are proud to stand in support of the editorial staff at MSNBC who have chosen to organize with the Writers Guild of America, East. We welcome you to the Guild and the labor movement. We encourage everyone to vote YES in the upcoming election so you can get to the bargaining table to have a say in your future. We work in scripted television and film, including many projects produced by NBC Universal. Through our union membership we have been able to negotiate fair compensation, excellent benefits, and basic fairness at work—all of which are enshrined in our union contract. We are ready to support you in your effort to do the same. We’re all in this together. Vote Union YES! In solidarity and support, Megan Abbott (THE DEUCE) John Aboud (HOME ECONOMICS) Daniel Abraham (THE EXPANSE) David Abramowitz (CAGNEY AND LACEY; HIGHLANDER; DAUGHTER OF THE STREETS) Jay Abramowitz (FULL HOUSE; MR. BELVEDERE; THE PARKERS) Gayle Abrams (FASIER; GILMORE GIRLS; 8 SIMPLE RULES) Kristen Acimovic (THE OPPOSITION WITH JORDAN KLEEPER) Peter Ackerman (THINGS YOU SHOULDN'T SAY PAST MIDNIGHT; ICE AGE; THE AMERICANS) Joan Ackermann (ARLISS) 1 Ilunga Adell (SANFORD & SON; WATCH YOUR MOUTH; MY BROTHER & ME) Dayo Adesokan (SUPERSTORE; YOUNG & HUNGRY; DOWNWARD DOG) Jonathan Adler (THE TONIGHT SHOW STARRING JIMMY FALLON) Erik Agard (THE CHASE) Zaike Airey (SWEET TOOTH) Rory Albanese (THE DAILY SHOW WITH JON STEWART; THE NIGHTLY SHOW WITH LARRY WILMORE) Chris Albers (LATE NIGHT WITH CONAN O'BRIEN; BORGIA) Lisa Albert (MAD MEN; HALT AND CATCH FIRE; UNREAL) Jerome Albrecht (THE LOVE BOAT) Georgianna Aldaco (MIRACLE WORKERS) Robert Alden (STREETWALKIN') Richard Alfieri (SIX DANCE LESSONS IN SIX WEEKS) Stephanie Allain (DEAR WHITE PEOPLE) A.C. -

Henry Jenkins Convergence Culture Where Old and New Media
Henry Jenkins Convergence Culture Where Old and New Media Collide n New York University Press • NewYork and London Skenovano pro studijni ucely NEW YORK UNIVERSITY PRESS New York and London www.nyupress. org © 2006 by New York University All rights reserved Library of Congress Cataloging-in-Publication Data Jenkins, Henry, 1958- Convergence culture : where old and new media collide / Henry Jenkins, p. cm. Includes bibliographical references and index. ISBN-13: 978-0-8147-4281-5 (cloth : alk. paper) ISBN-10: 0-8147-4281-5 (cloth : alk. paper) 1. Mass media and culture—United States. 2. Popular culture—United States. I. Title. P94.65.U6J46 2006 302.230973—dc22 2006007358 New York University Press books are printed on acid-free paper, and their binding materials are chosen for strength and durability. Manufactured in the United States of America c 15 14 13 12 11 p 10 987654321 Skenovano pro studijni ucely Contents Acknowledgments vii Introduction: "Worship at the Altar of Convergence": A New Paradigm for Understanding Media Change 1 1 Spoiling Survivor: The Anatomy of a Knowledge Community 25 2 Buying into American Idol: How We are Being Sold on Reality TV 59 3 Searching for the Origami Unicorn: The Matrix and Transmedia Storytelling 93 4 Quentin Tarantino's Star Wars? Grassroots Creativity Meets the Media Industry 131 5 Why Heather Can Write: Media Literacy and the Harry Potter Wars 169 6 Photoshop for Democracy: The New Relationship between Politics and Popular Culture 206 Conclusion: Democratizing Television? The Politics of Participation 240 Notes 261 Glossary 279 Index 295 About the Author 308 V Skenovano pro studijni ucely Acknowledgments Writing this book has been an epic journey, helped along by many hands. -

MARATHON (WO)MAN… Made in Athènes… Since 1896 !
NEWSLETTER N°13 JUILLET 2021 CÔTE DE JADE ATHLETIC CLUB Convivialité | Entraide | Performance L’édito d’été d’un triathlète impliqué, Samuel Brégeot "Depuis quelques semaines, on se réjouit de voir que le sport en compétition redémarre. Tout le monde connaît le triathlon avec le traditionnel enchaînement Natation / Vélo de route / Course à pied (CAP). Mais la section est tout d'abord définie comme un sport de disciplines enchaînées. On pratique de multiples épreuves combinées : - le Cross triathlon (on remplace le vélo de route par un VTT et la CAP se déroule toujours en mode trail, pour ceux qui préfèrent la nature au bitume)... - l'Aquathlon (natation / CAP) pour ceux qui n'aiment pas le vélo... - le Duathlon (CAP / vélo / CAP) pour ceux qui ne savent pas nager ... - le Vétathlon est la version nature de ce dernier avec du VTT à la place du vélo de route... - le Run&Bike par équipe de 2 pour ceux qui adorent sauter sur leur vélo et piquer des sprints... - le SwimRun en binôme où tu nages avec tes chaussures et tu cours avec ta combi, - des épreuves en équipe (triathlon, duathlon) ou en relais (chacun fait son sport de prédilection)... - le Swim&Bike, euh non ce sport n'existe pas (pas encore ) !!! Bien-sûr toutes ces épreuves sont proposées avec toute une palette de distances. Du triathlon XS (300m de nat' + 10km de vélo + 2,5km de Cap) jusqu'au XL, plus connu sous le nom d'Ironman (3,8km de nat' + 180km de vélo + 42km de CAP). Les pratiques sont très variées et c'est ce qui fait le charme de ce sport. -

The Narrative Functions of Television Dreams by Cynthia A. Burkhead A
Dancing Dwarfs and Talking Fish: The Narrative Functions of Television Dreams By Cynthia A. Burkhead A Dissertation Submitted in Partial Fulfillment of the Requirements for the Ph.D. Department of English Middle Tennessee State University December, 2010 UMI Number: 3459290 All rights reserved INFORMATION TO ALL USERS The quality of this reproduction is dependent upon the quality of the copy submitted. In the unlikely event that the author did not send a complete manuscript and there are missing pages, these will be noted. Also, if material had to be removed, a note will indicate the deletion. UMT Dissertation Publishing UMI 3459290 Copyright 2011 by ProQuest LLC. All rights reserved. This edition of the work is protected against unauthorized copying under Title 17, United States Code. ProQuest LLC 789 East Eisenhower Parkway P.O. Box 1346 Ann Arbor, Ml 48106-1346 DANCING DWARFS AND TALKING FISH: THE NARRATIVE FUNCTIONS OF TELEVISION DREAMS CYNTHIA BURKHEAD Approved: jr^QL^^lAo Qjrg/XA ^ Dr. David Lavery, Committee Chair c^&^^Ce~y Dr. Linda Badley, Reader A>& l-Lr 7i Dr./ Jill Hague, Rea J <7VM Dr. Tom Strawman, Chair, English Department Dr. Michael D. Allen, Dean, College of Graduate Studies DEDICATION First and foremost, I dedicate this work to my husband, John Burkhead, who lovingly carved for me the space and time that made this dissertation possible and then protected that space and time as fiercely as if it were his own. I dedicate this project also to my children, Joshua Scanlan, Daniel Scanlan, Stephen Burkhead, and Juliette Van Hoff, my son-in-law and daughter-in-law, and my grandchildren, Johnathan Burkhead and Olivia Van Hoff, who have all been so impressively patient during this process. -

6 World-Marathon-Majors1.Pdf
Table of contents World Marathon Majors World Marathon Majors: how it works ...............................................................................................................208 Scoring system .................................................................................................................................................................210 Series champions ............................................................................................................................................................211 Series schedule ................................................................................................................................................................213 2012-2013 Series results ..........................................................................................................................................214 2012-2013 Men’s leaderboard ...............................................................................................................................217 2012-2013 Women’s leaderboard ........................................................................................................................220 2013-2014 Men’s leaderboard ...............................................................................................................................223 2013-2014 Women’s leaderboard ........................................................................................................................225 Event histories ..................................................................................................................................................................227 -
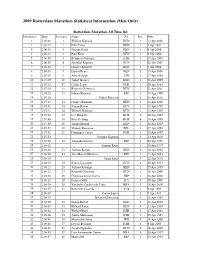
2009 Rotterdam Marathon Statistical Information (Men Only)
2009 Rotterdam Marathon Statistical Information (Men Only) Rotterdam Marathon All Time list Performances Time Performers Name Nat Place Date 1 2:05:49 1 William Kipsang KEN 1 13 Apr 2008 2 2:06:14 2 Felix Limo KEN 1 4 Apr 2004 3 2:06:38 3 Sammy Korir KEN 1 9 Apr 2006 4 2:06:44 4 Paul Kirui KEN 2 9 Apr 2006 5 2:06:50 5 Belayneh Dinsamo ETH 1 17 Apr 1988 6 2:06:50 6 Josephat Kiprono KEN 1 22 Apr 2001 7 2:06:52 7 Charles Kibiwott KEN 3 9 Apr 2006 8 2:06:58 8 Daniel Rono KEN 2 13 Apr 2008 9 2:07:07 9 Ahmed Salah DJI 2 17 Apr 1988 10 2:07:09 10 Japhet Kosgei KEN 1 18 Apr 1999 11 2:07:12 11 Carlos Lopes POR 1 20 Apr 1985 12 2:07:18 12 Kenneth Cheruiyot KEN 2 22 Apr 2001 13 2:07:23 13 Fabian Roncero ESP 2 18 Apr 1999 14 2:07:26 Fabian Roncero 1 19 Apr 1998 15 2:07:33 14 Charles Kamathi KEN 3 13 Apr 2008 16 2:07:41 15 Simon Biwott KEN 3 18 Apr 1999 17 2:07:42 16 William Kiplagat KEN 1 13 Apr 2003 18 2:07:44 17 Lee Bong-Ju KOR 2 19 Apr 1998 19 2:07:49 18 Kim Yi-Yong KOR 4 18 Apr 1999 20 2:07:50 19 Jimmy Muindi KEN 1 10 Apr 2005 21 2:07:51 20 Vincent Rousseau BEL 1 17 Apr 1994 22 2:07:51 21 Domingos Castro POR 1 20 Apr 1997 23 2:07:53 Josephat Kiprono 2 13 Apr 2003 24 2:07:54 22 Alejandro Gomez ESP 2 20 Apr 1997 25 2:08:02 Sammy Korir 3 20 Apr 1997 26 2:08:02 23 Jackson Koech KEN 2 10 Apr 2005 27 2:08:09 24 Jose Manuel Martinez ESP 3 13 Apr 2003 28 2:08:14 Samy Korir 3 22 Apr 2001 29 2:08:19 25 Simon Loywapet KEN 4 20 Apr 1997 30 2:08:21 26 Joshua Chelanga KEN 1 15 Apr 2007 31 2:08:22 27 Kenneth Cheruiyot KEN 1 16 Apr 2000 32 2:08:30 28 Francisco -

Updated 2019 Completemedia
April 15, 2019 Dear Members of the Media, On behalf of the Boston Athletic Association, principal sponsor John Hancock, and all of our sponsors and supporters, we welcome you to the City of Boston and the 123rd running of the Boston Marathon. As the oldest annually contested marathon in the world, the Boston Marathon represents more than a 26.2-mile footrace. The roads from Hopkinton to Boston have served as a beacon for well over a century, bringing those from all backgrounds together to celebrate the pursuit of athletic excellence. From our early beginnings in 1897 through this year’s 123rd running, the Boston Marathon has been an annual tradition that is on full display every April near and far. We hope that all will be able to savor the spirit of the Boston Marathon, regardless whether you are an athlete or volunteer, spectator or member of the media. Race week will surely not disappoint. The race towards Boylston Street will continue to showcase some of the world’s best athletes. Fronting the charge on Marathon Monday will be a quartet of defending champions who persevered through some of the harshest weather conditions in race history twelve months ago. Desiree Linden, the determined and resilient American who snapped a 33-year USA winless streak in the women’s open division, returns with hopes of keeping her crown. Linden has said that last year’s race was the culmination of more than a decade of trying to tame the beast of Boston – a race course that rewards those who are both patient and daring. -

Chicago Year-By-Year
YEAR-BY-YEAR CHICAGO MEDCHIIAC INFOAGO & YEFASTAR-BY-Y FACTSEAR TABLE OF CONTENTS YEAR-BY-YEAR HISTORY 2011 Champion and Runner-Up Split Times .................................... 126 2011 Top 25 Overall Finishers ....................................................... 127 2011 Top 10 Masters Finishers ..................................................... 128 2011 Top 5 Wheelchair Finishers ................................................... 129 Chicago Champions (1977-2011) ................................................... 130 Chicago Champions by Country ...................................................... 132 Masters Champions (1977-2011) .................................................. 134 Wheelchair Champions (1984-2011) .............................................. 136 Top 10 Overall Finishers (1977-2011) ............................................. 138 Historic Event Statistics ................................................................. 161 Historic Weather Conditions ........................................................... 162 Year-by-Year Race Summary............................................................ 164 125 2011 CHAMPION/RUNNER-UP SPLIT TIMES 2011 TOP 25 OVERALL FINISHERS 2011 CHAMPION AND RUNNER-UP SPLIT TIMES 2011 TOP 25 OVERALL FINISHERS MEN MEN Moses Mosop (KEN) Wesley Korir (KEN) # Name Age Country Time Distance Time (5K split) Min/Mile/5K Time Sec. Back 1. Moses Mosop ..................26 .........KEN .................................... 2:05:37 5K .................00:14:54 .....................04:47 -

2013 World Championships Statistics - Men’S Marathon by K Ken Nakamura
2013 World Championships Statistics - Men’s Marathon by K Ken Nakamura The records to look for in Moskva: 1) No nation ever swept the medal in the Worlds. Can ETH or KEN change that? 2) 2007 was the last time African born runner did NOT sweep the medal? Will Africans continue to dominate? All time Performance List at the World Championships Performance Performer Time Name Nat Pos Venue Year 1 1 2:06:54 Abel Kirui KEN 1 Berlin 2009 2 2:07:38 Abel Kirui 1 Daegu 2011 3 2 2:07:48 Emmanuel Mutai KEN 2 Berlin 2009 4 3 2:08:31 Jaouad Gharib MAR 1 Paris 2003 5 4 2:08:35 Tsegaye Kebede ETH 3 Berlin 2009 6 5 2:08:38 Julio Rey ESP 2 Paris 2003 7 6 2:08:42 Adhane Yemane Tsegay ETH 4 Berlin 2009 8 7 2:09:14 Stefano Baldini ITA 3 Paris 2003 9 8 2:09:25 Alberto Chaiça POR 4 Paris 2003 10 9 2:09:26 Shigeru Aburaya JPN 5 Paris 2003 11 10 2:09:29 Daniele Caimmi ITA 6 Paris 2003 12 11 2:10:03 Rob de Castella AUS 1 Helsinki 1983 13 12 2:10:06 Vincent Kipruto KEN 2 Daegu 2011 14 2:10:10 Jaouad Gharib 1 Helsinki 2005 15 13 2:10:17 Ian Syster RSA 7 Paris 2003 15 14 2:10:21 Christopher Isegwe TAN 2 Helsinki 2005 16 15 2:10:27 Kebede Balcha ETH 2 Helsinki 1983 18 16 2:10:32 Feyisa Lilesa ETH 3 Daegu 2011 19 17 2:10:35 Michael Kosgei Rotich KEN 8 Paris 2003 20 18 2:10:37 Waldemar Cierpinski GDR 3 Helsinki 1983 21 19 2:10:37 Hendrick Ramaala RSA 9 Paris 2003 22 20 2:10:38 Kjell-Erik Ståhl SWE 4 Helsinki 1983 22 21 2:10:38 Atsushi Sato JPN 10 Paris 2003 22 22 2:10:38 Lee Bong-Ju KOR 11 Paris 2003 25 23 2:10:39 Tsuyoshi Ogata JPN 12 Paris 2003 26 24 2:10:42 Agapius