Alphago-Tutorial
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Artificial Intelligence in Health Care: the Hope, the Hype, the Promise, the Peril
Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril Michael Matheny, Sonoo Thadaney Israni, Mahnoor Ahmed, and Danielle Whicher, Editors WASHINGTON, DC NAM.EDU PREPUBLICATION COPY - Uncorrected Proofs NATIONAL ACADEMY OF MEDICINE • 500 Fifth Street, NW • WASHINGTON, DC 20001 NOTICE: This publication has undergone peer review according to procedures established by the National Academy of Medicine (NAM). Publication by the NAM worthy of public attention, but does not constitute endorsement of conclusions and recommendationssignifies that it is the by productthe NAM. of The a carefully views presented considered in processthis publication and is a contributionare those of individual contributors and do not represent formal consensus positions of the authors’ organizations; the NAM; or the National Academies of Sciences, Engineering, and Medicine. Library of Congress Cataloging-in-Publication Data to Come Copyright 2019 by the National Academy of Sciences. All rights reserved. Printed in the United States of America. Suggested citation: Matheny, M., S. Thadaney Israni, M. Ahmed, and D. Whicher, Editors. 2019. Artificial Intelligence in Health Care: The Hope, the Hype, the Promise, the Peril. NAM Special Publication. Washington, DC: National Academy of Medicine. PREPUBLICATION COPY - Uncorrected Proofs “Knowing is not enough; we must apply. Willing is not enough; we must do.” --GOETHE PREPUBLICATION COPY - Uncorrected Proofs ABOUT THE NATIONAL ACADEMY OF MEDICINE The National Academy of Medicine is one of three Academies constituting the Nation- al Academies of Sciences, Engineering, and Medicine (the National Academies). The Na- tional Academies provide independent, objective analysis and advice to the nation and conduct other activities to solve complex problems and inform public policy decisions. -

Lecture Note on Deep Learning and Quantum Many-Body Computation
Lecture Note on Deep Learning and Quantum Many-Body Computation Jin-Guo Liu, Shuo-Hui Li, and Lei Wang∗ Institute of Physics, Chinese Academy of Sciences Beijing 100190, China November 23, 2018 Abstract This note introduces deep learning from a computa- tional quantum physicist’s perspective. The focus is on deep learning’s impacts to quantum many-body compu- tation, and vice versa. The latest version of the note is at http://wangleiphy.github.io/. Please send comments, suggestions and corrections to the email address in below. ∗ [email protected] CONTENTS 1 introduction2 2 discriminative learning4 2.1 Data Representation 4 2.2 Model: Artificial Neural Networks 6 2.3 Cost Function 9 2.4 Optimization 11 2.4.1 Back Propagation 11 2.4.2 Gradient Descend 13 2.5 Understanding, Visualization and Applications Beyond Classification 15 3 generative modeling 17 3.1 Unsupervised Probabilistic Modeling 17 3.2 Generative Model Zoo 18 3.2.1 Boltzmann Machines 19 3.2.2 Autoregressive Models 22 3.2.3 Normalizing Flow 23 3.2.4 Variational Autoencoders 25 3.2.5 Tensor Networks 28 3.2.6 Generative Adversarial Networks 29 3.3 Summary 32 4 applications to quantum many-body physics and more 33 4.1 Material and Chemistry Discoveries 33 4.2 Density Functional Theory 34 4.3 “Phase” Recognition 34 4.4 Variational Ansatz 34 4.5 Renormalization Group 35 4.6 Monte Carlo Update Proposals 36 4.7 Tensor Networks 37 4.8 Quantum Machine Leanring 38 4.9 Miscellaneous 38 5 hands on session 39 5.1 Computation Graph and Back Propagation 39 5.2 Deep Learning Libraries 41 5.3 Generative Modeling using Normalizing Flows 42 5.4 Restricted Boltzmann Machine for Image Restoration 43 5.5 Neural Network as a Quantum Wave Function Ansatz 43 6 challenges ahead 45 7 resources 46 BIBLIOGRAPHY 47 1 1 INTRODUCTION Deep Learning (DL) ⊂ Machine Learning (ML) ⊂ Artificial Intelli- gence (AI). -

AI Computer Wraps up 4-1 Victory Against Human Champion Nature Reports from Alphago's Victory in Seoul
The Go Files: AI computer wraps up 4-1 victory against human champion Nature reports from AlphaGo's victory in Seoul. Tanguy Chouard 15 March 2016 SEOUL, SOUTH KOREA Google DeepMind Lee Sedol, who has lost 4-1 to AlphaGo. Tanguy Chouard, an editor with Nature, saw Google-DeepMind’s AI system AlphaGo defeat a human professional for the first time last year at the ancient board game Go. This week, he is watching top professional Lee Sedol take on AlphaGo, in Seoul, for a $1 million prize. It’s all over at the Four Seasons Hotel in Seoul, where this morning AlphaGo wrapped up a 4-1 victory over Lee Sedol — incidentally, earning itself and its creators an honorary '9-dan professional' degree from the Korean Baduk Association. After winning the first three games, Google-DeepMind's computer looked impregnable. But the last two games may have revealed some weaknesses in its makeup. Game four totally changed the Go world’s view on AlphaGo’s dominance because it made it clear that the computer can 'bug' — or at least play very poor moves when on the losing side. It was obvious that Lee felt under much less pressure than in game three. And he adopted a different style, one based on taking large amounts of territory early on rather than immediately going for ‘street fighting’ such as making threats to capture stones. This style – called ‘amashi’ – seems to have paid off, because on move 78, Lee produced a play that somehow slipped under AlphaGo’s radar. David Silver, a scientist at DeepMind who's been leading the development of AlphaGo, said the program estimated its probability as 1 in 10,000. -

Accelerators and Obstacles to Emerging ML-Enabled Research Fields
Life at the edge: accelerators and obstacles to emerging ML-enabled research fields Soukayna Mouatadid Steve Easterbrook Department of Computer Science Department of Computer Science University of Toronto University of Toronto [email protected] [email protected] Abstract Machine learning is transforming several scientific disciplines, and has resulted in the emergence of new interdisciplinary data-driven research fields. Surveys of such emerging fields often highlight how machine learning can accelerate scientific discovery. However, a less discussed question is how connections between the parent fields develop and how the emerging interdisciplinary research evolves. This study attempts to answer this question by exploring the interactions between ma- chine learning research and traditional scientific disciplines. We examine different examples of such emerging fields, to identify the obstacles and accelerators that influence interdisciplinary collaborations between the parent fields. 1 Introduction In recent decades, several scientific research fields have experienced a deluge of data, which is impacting the way science is conducted. Fields such as neuroscience, psychology or social sciences are being reshaped by the advances in machine learning (ML) and the data processing technologies it provides. In some cases, new research fields have emerged at the intersection of machine learning and more traditional research disciplines. This is the case for example, for bioinformatics, born from collaborations between biologists and computer scientists in the mid-80s [1], which is now considered a well-established field with an active community, specialized conferences, university departments and research groups. How do these transformations take place? Do they follow similar paths? If yes, how can the advances in such interdisciplinary fields be accelerated? Researchers in the philosophy of science have long been interested in these questions. -

The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design
The Deep Learning Revolution and Its Implications for Computer Architecture and Chip Design Jeffrey Dean Google Research [email protected] Abstract The past decade has seen a remarkable series of advances in machine learning, and in particular deep learning approaches based on artificial neural networks, to improve our abilities to build more accurate systems across a broad range of areas, including computer vision, speech recognition, language translation, and natural language understanding tasks. This paper is a companion paper to a keynote talk at the 2020 International Solid-State Circuits Conference (ISSCC) discussing some of the advances in machine learning, and their implications on the kinds of computational devices we need to build, especially in the post-Moore’s Law-era. It also discusses some of the ways that machine learning may also be able to help with some aspects of the circuit design process. Finally, it provides a sketch of at least one interesting direction towards much larger-scale multi-task models that are sparsely activated and employ much more dynamic, example- and task-based routing than the machine learning models of today. Introduction The past decade has seen a remarkable series of advances in machine learning (ML), and in particular deep learning approaches based on artificial neural networks, to improve our abilities to build more accurate systems across a broad range of areas [LeCun et al. 2015]. Major areas of significant advances include computer vision [Krizhevsky et al. 2012, Szegedy et al. 2015, He et al. 2016, Real et al. 2017, Tan and Le 2019], speech recognition [Hinton et al. -

The Power and Promise of Computers That Learn by Example
Machine learning: the power and promise of computers that learn by example MACHINE LEARNING: THE POWER AND PROMISE OF COMPUTERS THAT LEARN BY EXAMPLE 1 Machine learning: the power and promise of computers that learn by example Issued: April 2017 DES4702 ISBN: 978-1-78252-259-1 The text of this work is licensed under the terms of the Creative Commons Attribution License which permits unrestricted use, provided the original author and source are credited. The license is available at: creativecommons.org/licenses/by/4.0 Images are not covered by this license. This report can be viewed online at royalsociety.org/machine-learning Cover image © shulz. 2 MACHINE LEARNING: THE POWER AND PROMISE OF COMPUTERS THAT LEARN BY EXAMPLE Contents Executive summary 5 Recommendations 8 Chapter one – Machine learning 15 1.1 Systems that learn from data 16 1.2 The Royal Society’s machine learning project 18 1.3 What is machine learning? 19 1.4 Machine learning in daily life 21 1.5 Machine learning, statistics, data science, robotics, and AI 24 1.6 Origins and evolution of machine learning 25 1.7 Canonical problems in machine learning 29 Chapter two – Emerging applications of machine learning 33 2.1 Potential near-term applications in the public and private sectors 34 2.2 Machine learning in research 41 2.3 Increasing the UK’s absorptive capacity for machine learning 45 Chapter three – Extracting value from data 47 3.1 Machine learning helps extract value from ‘big data’ 48 3.2 Creating a data environment to support machine learning 49 3.3 Extending the lifecycle -

ARCHITECTS of INTELLIGENCE for Xiaoxiao, Elaine, Colin, and Tristan ARCHITECTS of INTELLIGENCE
MARTIN FORD ARCHITECTS OF INTELLIGENCE For Xiaoxiao, Elaine, Colin, and Tristan ARCHITECTS OF INTELLIGENCE THE TRUTH ABOUT AI FROM THE PEOPLE BUILDING IT MARTIN FORD ARCHITECTS OF INTELLIGENCE Copyright © 2018 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the author, nor Packt Publishing or its dealers and distributors, will be held liable for any damages caused or alleged to have been caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. Acquisition Editors: Ben Renow-Clarke Project Editor: Radhika Atitkar Content Development Editor: Alex Sorrentino Proofreader: Safis Editing Presentation Designer: Sandip Tadge Cover Designer: Clare Bowyer Production Editor: Amit Ramadas Marketing Manager: Rajveer Samra Editorial Director: Dominic Shakeshaft First published: November 2018 Production reference: 2201118 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK ISBN 978-1-78913-151-2 www.packt.com Contents Introduction ........................................................................ 1 A Brief Introduction to the Vocabulary of Artificial Intelligence .......10 How AI Systems Learn ........................................................11 Yoshua Bengio .....................................................................17 Stuart J. -

In-Datacenter Performance Analysis of a Tensor Processing Unit
In-Datacenter Performance Analysis of a Tensor Processing Unit Presented by Josh Fried Background: Machine Learning Neural Networks: ● Multi Layer Perceptrons ● Recurrent Neural Networks (mostly LSTMs) ● Convolutional Neural Networks Synapse - each edge, has a weight Neuron - each node, sums weights and uses non-linear activation function over sum Propagating inputs through a layer of the NN is a matrix multiplication followed by an activation Background: Machine Learning Two phases: ● Training (offline) ○ relaxed deadlines ○ large batches to amortize costs of loading weights from DRAM ○ well suited to GPUs ○ Usually uses floating points ● Inference (online) ○ strict deadlines: 7-10ms at Google for some workloads ■ limited possibility for batching because of deadlines ○ Facebook uses CPUs for inference (last class) ○ Can use lower precision integers (faster/smaller/more efficient) ML Workloads @ Google 90% of ML workload time at Google spent on MLPs and LSTMs, despite broader focus on CNNs RankBrain (search) Inception (image classification), Google Translate AlphaGo (and others) Background: Hardware Trends End of Moore’s Law & Dennard Scaling ● Moore - transistor density is doubling every two years ● Dennard - power stays proportional to chip area as transistors shrink Machine Learning causing a huge growth in demand for compute ● 2006: Excess CPU capacity in datacenters is enough ● 2013: Projected 3 minutes per-day per-user of speech recognition ○ will require doubling datacenter compute capacity! Google’s Answer: Custom ASIC Goal: Build a chip that improves cost-performance for NN inference What are the main costs? Capital Costs Operational Costs (power bill!) TPU (V1) Design Goals Short design-deployment cycle: ~15 months! Plugs in to PCIe slot on existing servers Accelerates matrix multiplication operations Uses 8-bit integer operations instead of floating point How does the TPU work? CISC instructions, issued by host. -
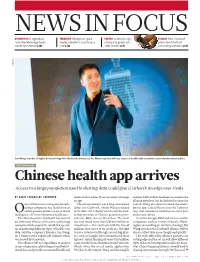
Chinese Health App Arrives Access to a Large Population Used to Sharing Data Could Give Icarbonx an Edge Over Rivals
NEWS IN FOCUS ASTROPHYSICS Legendary CHEMISTRY Deceptive spice POLITICS Scientists spy ECOLOGY New Zealand Arecibo telescope faces molecule offers cautionary chance to green UK plans to kill off all uncertain future p.143 tale p.144 after Brexit p.145 invasive predators p.148 ICARBONX Jun Wang, founder of digital biotechnology firm iCarbonX, showcases the Meum app that will use reams of health data to provide customized medical advice. BIOTECHNOLOGY Chinese health app arrives Access to a large population used to sharing data could give iCarbonX an edge over rivals. BY DAVID CYRANOSKI, SHENZHEN medical advice directly to consumers through another $400 million had been invested in the an app. alliance members, but he declined to name the ne of China’s most intriguing biotech- The announcement was a long-anticipated source. Wang also demonstrated the smart- nology companies has fleshed out an debut for iCarbonX, which Wang founded phone app, called Meum after the Latin for earlier quixotic promise to use artificial in October 2015 shortly after he left his lead- ‘my’, that customers would use to enter data Ointelligence (AI) to revolutionize health care. ership position at China’s genomics pow- and receive advice. The Shenzhen firm iCarbonX has formed erhouse, BGI, also in Shenzhen. The firm As well as Google, IBM and various smaller an ambitious alliance with seven technology has now raised more than US$600 million in companies, such as Arivale of Seattle, Wash- companies from around the world that special- investment — this contrasts with the tens of ington, are working on similar technology. But ize in gathering different types of health-care millions that most of its rivals are thought Wang says that the iCarbonX alliance will be data, said the company’s founder, Jun Wang, to have invested (although several big play- able to collect data more cheaply and quickly. -

Understanding & Generalizing Alphago Zero
Under review as a conference paper at ICLR 2019 UNDERSTANDING &GENERALIZING ALPHAGO ZERO Anonymous authors Paper under double-blind review ABSTRACT AlphaGo Zero (AGZ) (Silver et al., 2017b) introduced a new tabula rasa rein- forcement learning algorithm that has achieved superhuman performance in the games of Go, Chess, and Shogi with no prior knowledge other than the rules of the game. This success naturally begs the question whether it is possible to develop similar high-performance reinforcement learning algorithms for generic sequential decision-making problems (beyond two-player games), using only the constraints of the environment as the “rules.” To address this challenge, we start by taking steps towards developing a formal understanding of AGZ. AGZ includes two key innovations: (1) it learns a policy (represented as a neural network) using super- vised learning with cross-entropy loss from samples generated via Monte-Carlo Tree Search (MCTS); (2) it uses self-play to learn without training data. We argue that the self-play in AGZ corresponds to learning a Nash equilibrium for the two-player game; and the supervised learning with MCTS is attempting to learn the policy corresponding to the Nash equilibrium, by establishing a novel bound on the difference between the expected return achieved by two policies in terms of the expected KL divergence (cross-entropy) of their induced distributions. To extend AGZ to generic sequential decision-making problems, we introduce a robust MDP framework, in which the agent and nature effectively play a zero-sum game: the agent aims to take actions to maximize reward while nature seeks state transitions, subject to the constraints of that environment, that minimize the agent’s reward. -

Computer Go: from the Beginnings to Alphago Martin Müller, University of Alberta
Computer Go: from the Beginnings to AlphaGo Martin Müller, University of Alberta 2017 Outline of the Talk ✤ Game of Go ✤ Short history - Computer Go from the beginnings to AlphaGo ✤ The science behind AlphaGo ✤ The legacy of AlphaGo The Game of Go Go ✤ Classic two-player board game ✤ Invented in China thousands of years ago ✤ Simple rules, complex strategy ✤ Played by millions ✤ Hundreds of top experts - professional players ✤ Until 2016, computers weaker than humans Go Rules ✤ Start with empty board ✤ Place stone of your own color ✤ Goal: surround empty points or opponent - capture ✤ Win: control more than half the board Final score, 9x9 board ✤ Komi: first player advantage Measuring Go Strength ✤ People in Europe and America use the traditional Japanese ranking system ✤ Kyu (student) and Dan (master) levels ✤ Separate Dan ranks for professional players ✤ Kyu grades go down from 30 (absolute beginner) to 1 (best) ✤ Dan grades go up from 1 (weakest) to about 6 ✤ There is also a numerical (Elo) system, e.g. 2500 = 5 Dan Short History of Computer Go Computer Go History - Beginnings ✤ 1960’s: initial ideas, designs on paper ✤ 1970’s: first serious program - Reitman & Wilcox ✤ Interviews with strong human players ✤ Try to build a model of human decision-making ✤ Level: “advanced beginner”, 15-20 kyu ✤ One game costs thousands of dollars in computer time 1980-89 The Arrival of PC ✤ From 1980: PC (personal computers) arrive ✤ Many people get cheap access to computers ✤ Many start writing Go programs ✤ First competitions, Computer Olympiad, Ing Cup ✤ Level 10-15 kyu 1990-2005: Slow Progress ✤ Slow progress, commercial successes ✤ 1990 Ing Cup in Beijing ✤ 1993 Ing Cup in Chengdu ✤ Top programs Handtalk (Prof. -

AI for Broadcsaters, Future Has Already Begun…
AI for Broadcsaters, future has already begun… By Dr. Veysel Binbay, Specialist Engineer @ ABU Technology & Innovation Department 0 Dr. Veysel Binbay I have been working as Specialist Engineer at ABU Technology and Innovation Department for one year, before that I had worked at TRT (Turkish Radio and Television Corporation) for more than 20 years as a broadcast engineer, and also as an IT Director. I have wide experience on Radio and TV broadcasting technologies, including IT systems also. My experience includes to design, to setup, and to operate analogue/hybrid/digital radio and TV broadcast systems. I have also experienced on IT Networks. 1/25 What is Artificial Intelligence ? • Programs that behave externally like humans? • Programs that operate internally as humans do? • Computational systems that behave intelligently? 2 Some Definitions Trials for AI: The exciting new effort to make computers think … machines with minds, in the full literal sense. Haugeland, 1985 3 Some Definitions Trials for AI: The study of mental faculties through the use of computational models. Charniak and McDermott, 1985 A field of study that seeks to explain and emulate intelligent behavior in terms of computational processes. Schalkoff, 1990 4 Some Definitions Trials for AI: The study of how to make computers do things at which, at the moment, people are better. Rich & Knight, 1991 5 It’s obviously hard to define… (since we don’t have a commonly agreed definition of intelligence itself yet)… Lets try to focus to benefits, and solve definition problem later… 6 Brief history of AI 7 Brief history of AI . The history of AI begins with the following article: .