Identi Cation of Potential Biomarkers in PBMC of Systemic Lupus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

LRG1 Promotes Diabetic Kidney Disease Progression by Enhancing TGF-B–Induced Angiogenesis
BASIC RESEARCH www.jasn.org LRG1 Promotes Diabetic Kidney Disease Progression by Enhancing TGF-b–Induced Angiogenesis Quan Hong,1,2 Lu Zhang,3,1 Jia Fu,1 Divya A. Verghese,1 Kinsuk Chauhan,1 Girish N. Nadkarni,1 Zhengzhe Li,1 Wenjun Ju,4 Matthias Kretzler ,4 Guang-Yan Cai,2 Xiang-Mei Chen,2 Vivette D. D’Agati,5 Steven G. Coca ,1 Detlef Schlondorff,1 John C. He,1,6 and Kyung Lee1 Due to the number of contributing authors, the affiliations are listed at the end of this article. ABSTRACT Background Glomerular endothelial dysfunction and neoangiogenesis have long been implicated in the pathogenesis of diabetic kidney disease (DKD). However, the specific molecular pathways contributing to these processes in the early stages of DKD are not well understood. Our recent transcriptomic profiling of glomerular endothelial cells identified a number of proangiogenic genes that were upregulated in diabetic mice, including leucine-rich a-2-glycoprotein 1 (LRG1). LRG1 was previously shown to promote neovascularization in mouse models of ocular disease by potentiating endothelial TGF-b/activin receptor- like kinase 1 (ALK1) signaling. However, LRG1’s role in the kidney, particularly in the setting of DKD, has been unclear. Methods We analyzed expression of LRG1 mRNA in glomeruli of diabetic kidneys and assessed its localization by RNA in situ hybridization. We examined the effects of genetic ablation of Lrg1 on DKD progression in unilaterally nephrectomized, streptozotocin-induced diabetic mice at 12 and 20 weeks after diabetes induction. We also assessed whether plasma LRG1 was associated with renal outcome in patients with type 2 diabetes. -

Network Medicine Approach for Analysis of Alzheimer's Disease Gene Expression Data
International Journal of Molecular Sciences Article Network Medicine Approach for Analysis of Alzheimer’s Disease Gene Expression Data David Cohen y, Alexander Pilozzi y and Xudong Huang * Neurochemistry Laboratory, Department of Psychiatry, Massachusetts General Hospital and Harvard Medical School, Charlestown, MA 02129, USA; [email protected] (D.C.); [email protected] (A.P.) * Correspondence: [email protected]; Tel./Fax: +1-617-724-9778 These authors contributed equally to this work. y Received: 15 November 2019; Accepted: 30 December 2019; Published: 3 January 2020 Abstract: Alzheimer’s disease (AD) is the most widespread diagnosed cause of dementia in the elderly. It is a progressive neurodegenerative disease that causes memory loss as well as other detrimental symptoms that are ultimately fatal. Due to the urgent nature of this disease, and the current lack of success in treatment and prevention, it is vital that different methods and approaches are applied to its study in order to better understand its underlying mechanisms. To this end, we have conducted network-based gene co-expression analysis on data from the Alzheimer’s Disease Neuroimaging Initiative (ADNI) database. By processing and filtering gene expression data taken from the blood samples of subjects with varying disease states and constructing networks based on that data to evaluate gene relationships, we have been able to learn about gene expression correlated with the disease, and we have identified several areas of potential research interest. Keywords: Alzheimer’s disease; network medicine; gene expression; neurodegeneration; neuroinflammation 1. Introduction Alzheimer’s disease (AD) is the most widespread diagnosed cause of dementia in the elderly [1]. -

Downloaded the Normalized Gene Expression Profile from the GEO (Package Geoquery (5))
1 SUPPLEMENTARY MATERIALS 2 Supplementary Methods 3 Study design 4 The workflow to identify and validate the TME risk score and TME subtypes in gastric cancer is 5 depicted in Fig. S1. We first estimated the absolute abundance levels of the major stromal and 6 immune cell types in the TME using bulk gene expression data, and assessed the prognostic 7 effect of these cells in a discovery cohort. Next, we constructed a TME risk score and validated it 8 in two independent gene expression validation cohorts and three immunohistochemistry 9 validation cohorts. Finally, we stratified patients into four TME subtypes and examined their 10 genomic and molecular features and relation to established molecular subtypes. 11 Gene expression data 12 To explore the prognostic landscape of the TME, we used four gene expression profile (GEP) 13 datasets of resected gastric cancer patients with publicly available clinical information, namely, 14 ACRG (GSE62254) (1), GSE15459 (2), GSE84437 (3), and TCGA stomach adenocarcinoma 15 (STAD). Specifically, the raw microarray data in the ACRG cohort and GSE15459 were retrieved 16 from the Gene Expression Omnibus (GEO), and normalized by the RMA algorithm (package affy) 17 using custom chip definition files (Brainarray version 23 (4)) that convert Affymetrix probesets to 18 Entrez gene IDs. For GSE84437 dataset, which was measured by the Illumina platform, we 19 downloaded the normalized gene expression profile from the GEO (package GEOquery (5)). The 20 Illumina probes were also mapped to Entrez genes. For multiple probes mapping to the same 21 Entrez gene, we selected the one with the maximum mean expression level as the surrogate for 22 the Entrez gene using the function of collapseRows (6) (package WGCNA). -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Systems and Chemical Biology Approaches to Study Cell Function and Response to Toxins
Dissertation submitted to the Combined Faculties for the Natural Sciences and for Mathematics of the Ruperto-Carola University of Heidelberg, Germany for the degree of Doctor of Natural Sciences Presented by MSc. Yingying Jiang born in Shandong, China Oral-examination: Systems and chemical biology approaches to study cell function and response to toxins Referees: Prof. Dr. Rob Russell Prof. Dr. Stefan Wölfl CONTRIBUTIONS The chapter III of this thesis was submitted for publishing under the title “Drug mechanism predominates over toxicity mechanisms in drug induced gene expression” by Yingying Jiang, Tobias C. Fuchs, Kristina Erdeljan, Bojana Lazerevic, Philip Hewitt, Gordana Apic & Robert B. Russell. For chapter III, text phrases, selected tables, figures are based on this submitted manuscript that has been originally written by myself. i ABSTRACT Toxicity is one of the main causes of failure during drug discovery, and of withdrawal once drugs reached the market. Prediction of potential toxicities in the early stage of drug development has thus become of great interest to reduce such costly failures. Since toxicity results from chemical perturbation of biological systems, we combined biological and chemical strategies to help understand and ultimately predict drug toxicities. First, we proposed a systematic strategy to predict and understand the mechanistic interpretation of drug toxicities based on chemical fragments. Fragments frequently found in chemicals with certain toxicities were defined as structural alerts for use in prediction. Some of the predictions were supported with mechanistic interpretation by integrating fragment- chemical, chemical-protein, protein-protein interactions and gene expression data. Next, we systematically deciphered the mechanisms of drug actions and toxicities by analyzing the associations of drugs’ chemical features, biological features and their gene expression profiles from the TG-GATEs database. -

Dietary Supplementation with L-Arginine, Single Nucleotide
The Journal of Nutrition Commentary Dietary Supplementation with L-Arginine, Single Nucleotide Polymorphisms of Arginase Downloaded from https://academic.oup.com/jn/advance-article/doi/10.1093/jn/nxaa431/6131937 by University of Memphis - Library user on 10 February 2021 1 and 2, and Plasma L-Arginine Keith R Martin Center for Nutraceutical and Dietary Supplement Research, College of Health Sciences, University of Memphis, Memphis, TN, USA There are ∼3 million single nucleotide polymorphisms (SNPs) Arginine-dependent NO impacts the immune, neuronal, and between 2 unrelated individuals, with each SNP representing cardiovascular systems and is a potent vasodilator critical for a single modification in the genomic code and cumulatively vascular tone, blood pressure modulation, vascular permeabil- representing 0.1% human genetic diversity. Although many of ity, and angiogenesis (7–9). SNPs in the ARG1 gene are clinically these differences are silent, relatively recent data suggest that associated with cardiovascular diseases such as hypertension, around half of the various responses to dietary agents could cardiomyopathy, myocardial infarction, and carotid intima be related to genetic variation, a field coined as nutrigenetics. media thickness, and upregulation of arginase is implicated in These variations are of considerable interest in improving the vascular dysfunction (10, 11). Thus, dietary supplementation health of individuals and collectively mitigating the risk of with l-arginine could be warranted. chronic disease. In this issue of the Journal, Hannemann et The study by Hannemann et al. is the first to describe al. (1) describe a possible functional relation between arginase an association between genotypes of ARG1 and ARG2 with isoforms, important in the urea cycle and nitric oxide (NO) consequent circulating plasma concentrations of l-arginine. -

Low Basal Expression and Slow Induction of IFITM3 Puts Immune
bioRxiv preprint doi: https://doi.org/10.1101/2019.12.20.885590; this version posted December 23, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 TITLE: Low basal expression and slow induction of IFITM3 puts immune 2 cells at risk of influenza A infection 3 4 Running head (40 characters): 5 Cells at risk of Influenza A infection 6 7 Authors: 8 Dannielle Wellington1,2,*, , Zixi Yin1,2, Liwei Zhang1, Jessica Forbester1,3, Kerry 9 Kite1, Henry Laurenson-Schafer1, Shokouh Makvandi-Nejad1 , Boquan Jin4, 10 Emma Bowes5, Krishnageetha Manoharan5, David Maldonado-Perez5, Clare 11 Verill5, Ian Humphreys3 & Tao Dong1,2,* 12 1. MRC Human Immunology Unit, MRC Weatherall Institute of Molecular Medicine, Radcliffe 13 Department of Medicine, Oxford University, Oxford OX3 9DS, UK 14 2. Chinese Academy of Medical Sciences (CAMS) Oxford Institute, Nuffield Department of 15 Medicine, Oxford University, OX3 7BN, UK 16 3. Division of Infection and Immunity/Systems Immunity University Research Institute, Cardiff 17 University, Cardiff, CF14 4XN, UK 18 4. Fourth Military Medical University, Xian, China 19 5. Oxford Radcliffe BioBank, Nuffield Department of Surgical Sciences, Oxford University, 20 Oxford OX3 9DU, UK 21 *Corresponding to Dannielle Wellington [email protected] or Tao Dong, 22 [email protected] 23 24 Acknowledgements: 25 The authors would like to thank the following facilities and individuals within 26 the MRC Weatherall Institute (Oxford) for their invaluaBle help in the following 27 experiments: Mass Cytometry Facility and Alain Townsend for kindly providing 28 virus stocks. -

Mesenchymal Stem Cells Prevent the Progression of Diabetic
Lee et al. Experimental & Molecular Medicine (2019) 51:77 https://doi.org/10.1038/s12276-019-0268-5 Experimental & Molecular Medicine ARTICLE Open Access Mesenchymal stem cells prevent the progression of diabetic nephropathy by improving mitochondrial function in tubular epithelial cells Seung Eun Lee1,2,7,JungEunJang1,2,8,HyunSikKim2,MinKyoJung2,MyoungSeokKo2,Mi-OkKim2, Hye Sun Park2, Wonil Oh3, Soo Jin Choi3,HyeJinJin3, Sang-Yeob Kim4,YunJaeKim2,SeongWhoKim5, Min Kyung Kim5, Chang Ohk Sung6, Chan-Gi Pack 2,Ki-UpLee1,2 and Eun Hee Koh1,2 Abstract The administration of mesenchymal stem cells (MSCs) was shown to attenuate overt as well as early diabetic nephropathy in rodents, but the underlying mechanism of this beneficial effect is largely unknown. Inflammation and mitochondrial dysfunction are major pathogenic factors in diabetic nephropathy. In this study, we found that the repeated administration of MSCs prevents albuminuria and injury to tubular epithelial cells (TECs), an important element in the progression of diabetic nephropathy, by improving mitochondrial function. The expression of M1 macrophage markers was significantly increased in diabetic kidneys compared with that in control kidneys. Interestingly, the expression of arginase-1 (Arg1), an important M2 macrophage marker, was reduced in diabetic kidneys and increased by MSC treatment. In cultured TECs, conditioned media from lipopolysaccharide-activated 1234567890():,; 1234567890():,; 1234567890():,; 1234567890():,; macrophages reduced peroxisomal proliferator-activated receptor gamma coactivator 1α (Pgc1a) expression and impaired mitochondrial function. The coculture of macrophages with MSCs increased and decreased the expression of Arg1 and M1 markers, respectively. Treatment with conditioned media from cocultured macrophages prevented activated macrophage-induced mitochondrial dysfunction in TECs. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

A Molecular and Genetic Analysis of Otosclerosis
A molecular and genetic analysis of otosclerosis Joanna Lauren Ziff Submitted for the degree of PhD University College London January 2014 1 Declaration I, Joanna Ziff, confirm that the work presented in this thesis is my own. Where information has been derived from other sources, I confirm that this has been indicated in the thesis. Where work has been conducted by other members of our laboratory, this has been indicated by an appropriate reference. 2 Abstract Otosclerosis is a common form of conductive hearing loss. It is characterised by abnormal bone remodelling within the otic capsule, leading to formation of sclerotic lesions of the temporal bone. Encroachment of these lesions on to the footplate of the stapes in the middle ear leads to stapes fixation and subsequent conductive hearing loss. The hereditary nature of otosclerosis has long been recognised due to its recurrence within families, but its genetic aetiology is yet to be characterised. Although many familial linkage studies and candidate gene association studies to investigate the genetic nature of otosclerosis have been performed in recent years, progress in identifying disease causing genes has been slow. This is largely due to the highly heterogeneous nature of this condition. The research presented in this thesis examines the molecular and genetic basis of otosclerosis using two next generation sequencing technologies; RNA-sequencing and Whole Exome Sequencing. RNA–sequencing has provided human stapes transcriptomes for healthy and diseased stapes, and in combination with pathway analysis has helped identify genes and molecular processes dysregulated in otosclerotic tissue. Whole Exome Sequencing has been employed to investigate rare variants that segregate with otosclerosis in affected families, and has been followed by a variant filtering strategy, which has prioritised genes found to be dysregulated during RNA-sequencing. -
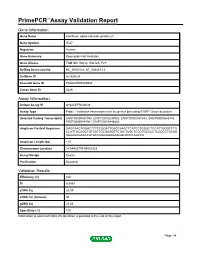
Primepcr™Assay Validation Report
PrimePCR™Assay Validation Report Gene Information Gene Name interferon, alpha-inducible protein 27 Gene Symbol IFI27 Organism Human Gene Summary Description Not Available Gene Aliases FAM14D, ISG12, ISG12A, P27 RefSeq Accession No. NC_000014.8, NT_026437.12 UniGene ID Hs.532634 Ensembl Gene ID ENSG00000165949 Entrez Gene ID 3429 Assay Information Unique Assay ID qHsaCEP0024638 Assay Type Probe - Validation information is for the primer pair using SYBR® Green detection Detected Coding Transcript(s) ENST00000557098, ENST00000298902, ENST00000557634, ENST00000555744, ENST00000444961, ENST00000448882 Amplicon Context Sequence GAGCAACTGGACTCTCCGGATTGACCAAGTTCATCCTGGGCTCCATTGGGTCTG CCATTGCGGCTGTCATTGCGAGGTTCTACTAGCTCCCTGCCCCTCGCCCTGCAG AGAAGAGAACCATGCCAGGGGAGAAGGCACCCAGCCA Amplicon Length (bp) 115 Chromosome Location 14:94582779-94582923 Assay Design Exonic Purification Desalted Validation Results Efficiency (%) 100 R2 0.9997 cDNA Cq 23.09 cDNA Tm (Celsius) 86 gDNA Cq 23.06 Specificity (%) 100 Information to assist with data interpretation is provided at the end of this report. Page 1/4 PrimePCR™Assay Validation Report IFI27, Human Amplification Plot Amplification of cDNA generated from 25 ng of universal reference RNA Melt Peak Melt curve analysis of above amplification Standard Curve Standard curve generated using 20 million copies of template diluted 10-fold to 20 copies Page 2/4 PrimePCR™Assay Validation Report Products used to generate validation data Real-Time PCR Instrument CFX384 Real-Time PCR Detection System Reverse Transcription Reagent iScript™ Advanced cDNA Synthesis Kit for RT-qPCR Real-Time PCR Supermix SsoAdvanced™ SYBR® Green Supermix Experimental Sample qPCR Human Reference Total RNA Data Interpretation Unique Assay ID This is a unique identifier that can be used to identify the assay in the literature and online. Detected Coding Transcript(s) This is a list of the Ensembl transcript ID(s) that this assay will detect. -

Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights Into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle
animals Article Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle Masoumeh Naserkheil 1 , Abolfazl Bahrami 1 , Deukhwan Lee 2,* and Hossein Mehrban 3 1 Department of Animal Science, University College of Agriculture and Natural Resources, University of Tehran, Karaj 77871-31587, Iran; [email protected] (M.N.); [email protected] (A.B.) 2 Department of Animal Life and Environment Sciences, Hankyong National University, Jungang-ro 327, Anseong-si, Gyeonggi-do 17579, Korea 3 Department of Animal Science, Shahrekord University, Shahrekord 88186-34141, Iran; [email protected] * Correspondence: [email protected]; Tel.: +82-31-670-5091 Received: 25 August 2020; Accepted: 6 October 2020; Published: 9 October 2020 Simple Summary: Hanwoo is an indigenous cattle breed in Korea and popular for meat production owing to its rapid growth and high-quality meat. Its yearling weight and carcass traits (backfat thickness, carcass weight, eye muscle area, and marbling score) are economically important for the selection of young and proven bulls. In recent decades, the advent of high throughput genotyping technologies has made it possible to perform genome-wide association studies (GWAS) for the detection of genomic regions associated with traits of economic interest in different species. In this study, we conducted a weighted single-step genome-wide association study which combines all genotypes, phenotypes and pedigree data in one step (ssGBLUP). It allows for the use of all SNPs simultaneously along with all phenotypes from genotyped and ungenotyped animals. Our results revealed 33 relevant genomic regions related to the traits of interest.