2Q13 Microdeletions
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Bayesian Hierarchical Modeling of High-Throughput Genomic Data with Applications to Cancer Bioinformatics and Stem Cell Differentiation
BAYESIAN HIERARCHICAL MODELING OF HIGH-THROUGHPUT GENOMIC DATA WITH APPLICATIONS TO CANCER BIOINFORMATICS AND STEM CELL DIFFERENTIATION by Keegan D. Korthauer A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy (Statistics) at the UNIVERSITY OF WISCONSIN–MADISON 2015 Date of final oral examination: 05/04/15 The dissertation is approved by the following members of the Final Oral Committee: Christina Kendziorski, Professor, Biostatistics and Medical Informatics Michael A. Newton, Professor, Statistics Sunduz Kele¸s,Professor, Biostatistics and Medical Informatics Sijian Wang, Associate Professor, Biostatistics and Medical Informatics Michael N. Gould, Professor, Oncology © Copyright by Keegan D. Korthauer 2015 All Rights Reserved i in memory of my grandparents Ma and Pa FL Grandma and John ii ACKNOWLEDGMENTS First and foremost, I am deeply grateful to my thesis advisor Christina Kendziorski for her invaluable advice, enthusiastic support, and unending patience throughout my time at UW-Madison. She has provided sound wisdom on everything from methodological principles to the intricacies of academic research. I especially appreciate that she has always encouraged me to eke out my own path and I attribute a great deal of credit to her for the successes I have achieved thus far. I also owe special thanks to my committee member Professor Michael Newton, who guided me through one of my first collaborative research experiences and has continued to provide key advice on my thesis research. I am also indebted to the other members of my thesis committee, Professor Sunduz Kele¸s,Professor Sijian Wang, and Professor Michael Gould, whose valuable comments, questions, and suggestions have greatly improved this dissertation. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

Figure S1. Representative Report Generated by the Ion Torrent System Server for Each of the KCC71 Panel Analysis and Pcafusion Analysis
Figure S1. Representative report generated by the Ion Torrent system server for each of the KCC71 panel analysis and PCaFusion analysis. (A) Details of the run summary report followed by the alignment summary report for the KCC71 panel analysis sequencing. (B) Details of the run summary report for the PCaFusion panel analysis. A Figure S1. Continued. Representative report generated by the Ion Torrent system server for each of the KCC71 panel analysis and PCaFusion analysis. (A) Details of the run summary report followed by the alignment summary report for the KCC71 panel analysis sequencing. (B) Details of the run summary report for the PCaFusion panel analysis. B Figure S2. Comparative analysis of the variant frequency found by the KCC71 panel and calculated from publicly available cBioPortal datasets. For each of the 71 genes in the KCC71 panel, the frequency of variants was calculated as the variant number found in the examined cases. Datasets marked with different colors and sample numbers of prostate cancer are presented in the upper right. *Significantly high in the present study. Figure S3. Seven subnetworks extracted from each of seven public prostate cancer gene networks in TCNG (Table SVI). Blue dots represent genes that include initial seed genes (parent nodes), and parent‑child and child‑grandchild genes in the network. Graphical representation of node‑to‑node associations and subnetwork structures that differed among and were unique to each of the seven subnetworks. TCNG, The Cancer Network Galaxy. Figure S4. REVIGO tree map showing the predicted biological processes of prostate cancer in the Japanese. Each rectangle represents a biological function in terms of a Gene Ontology (GO) term, with the size adjusted to represent the P‑value of the GO term in the underlying GO term database. -

Statistical and Bioinformatic Analysis of Hemimethylation Patterns in Non-Small Cell Lung Cancer
Statistical and Bioinformatic Analysis of Hemimethylation Patterns in Non-Small Cell Lung Cancer Shuying Sun ( [email protected] ) Texas State University San Marcos https://orcid.org/0000-0003-3974-6996 Austin Zane Texas A&M University College Station Carolyn Fulton Schreiner University Jasmine Philipoom Case Western Reserve University Research article Keywords: Methylation, Hemimethylation, Lung Cancer, Bioinformatics, Epigenetics Posted Date: October 12th, 2020 DOI: https://doi.org/10.21203/rs.3.rs-17794/v2 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Version of Record: A version of this preprint was published on March 12th, 2021. See the published version at https://doi.org/10.1186/s12885-021-07990-7. Page 1/29 Abstract Background: DNA methylation is an epigenetic event involving the addition of a methyl-group to a cytosine-guanine base pair (i.e., CpG site). It is associated with different cancers. Our research focuses on studying non- small cell lung cancer hemimethylation, which refers to methylation occurring on only one of the two DNA strands. Many studies often assume that methylation occurs on both DNA strands at a CpG site. However, recent publications show the existence of hemimethylation and its signicant impact. Therefore, it is important to identify cancer hemimethylation patterns. Methods: In this paper, we use the Wilcoxon signed rank test to identify hemimethylated CpG sites based on publicly available non-small cell lung cancer methylation sequencing data. We then identify two types of hemimethylated CpG clusters, regular and polarity clusters, and genes with large numbers of hemimethylated sites. -

Appendix 2. Significantly Differentially Regulated Genes in Term Compared with Second Trimester Amniotic Fluid Supernatant
Appendix 2. Significantly Differentially Regulated Genes in Term Compared With Second Trimester Amniotic Fluid Supernatant Fold Change in term vs second trimester Amniotic Affymetrix Duplicate Fluid Probe ID probes Symbol Entrez Gene Name 1019.9 217059_at D MUC7 mucin 7, secreted 424.5 211735_x_at D SFTPC surfactant protein C 416.2 206835_at STATH statherin 363.4 214387_x_at D SFTPC surfactant protein C 295.5 205982_x_at D SFTPC surfactant protein C 288.7 1553454_at RPTN repetin solute carrier family 34 (sodium 251.3 204124_at SLC34A2 phosphate), member 2 238.9 206786_at HTN3 histatin 3 161.5 220191_at GKN1 gastrokine 1 152.7 223678_s_at D SFTPA2 surfactant protein A2 130.9 207430_s_at D MSMB microseminoprotein, beta- 99.0 214199_at SFTPD surfactant protein D major histocompatibility complex, class II, 96.5 210982_s_at D HLA-DRA DR alpha 96.5 221133_s_at D CLDN18 claudin 18 94.4 238222_at GKN2 gastrokine 2 93.7 1557961_s_at D LOC100127983 uncharacterized LOC100127983 93.1 229584_at LRRK2 leucine-rich repeat kinase 2 HOXD cluster antisense RNA 1 (non- 88.6 242042_s_at D HOXD-AS1 protein coding) 86.0 205569_at LAMP3 lysosomal-associated membrane protein 3 85.4 232698_at BPIFB2 BPI fold containing family B, member 2 84.4 205979_at SCGB2A1 secretoglobin, family 2A, member 1 84.3 230469_at RTKN2 rhotekin 2 82.2 204130_at HSD11B2 hydroxysteroid (11-beta) dehydrogenase 2 81.9 222242_s_at KLK5 kallikrein-related peptidase 5 77.0 237281_at AKAP14 A kinase (PRKA) anchor protein 14 76.7 1553602_at MUCL1 mucin-like 1 76.3 216359_at D MUC7 mucin 7, -

Table S2.Up Or Down Regulated Genes in Tcof1 Knockdown Neuroblastoma N1E-115 Cells Involved in Differentbiological Process Anal
Table S2.Up or down regulated genes in Tcof1 knockdown neuroblastoma N1E-115 cells involved in differentbiological process analysed by DAVID database Pop Pop Fold Term PValue Genes Bonferroni Benjamini FDR Hits Total Enrichment GO:0044257~cellular protein catabolic 2.77E-10 MKRN1, PPP2R5C, VPRBP, MYLIP, CDC16, ERLEC1, MKRN2, CUL3, 537 13588 1.944851 8.64E-07 8.64E-07 5.02E-07 process ISG15, ATG7, PSENEN, LOC100046898, CDCA3, ANAPC1, ANAPC2, ANAPC5, SOCS3, ENC1, SOCS4, ASB8, DCUN1D1, PSMA6, SIAH1A, TRIM32, RNF138, GM12396, RNF20, USP17L5, FBXO11, RAD23B, NEDD8, UBE2V2, RFFL, CDC GO:0051603~proteolysis involved in 4.52E-10 MKRN1, PPP2R5C, VPRBP, MYLIP, CDC16, ERLEC1, MKRN2, CUL3, 534 13588 1.93519 1.41E-06 7.04E-07 8.18E-07 cellular protein catabolic process ISG15, ATG7, PSENEN, LOC100046898, CDCA3, ANAPC1, ANAPC2, ANAPC5, SOCS3, ENC1, SOCS4, ASB8, DCUN1D1, PSMA6, SIAH1A, TRIM32, RNF138, GM12396, RNF20, USP17L5, FBXO11, RAD23B, NEDD8, UBE2V2, RFFL, CDC GO:0044265~cellular macromolecule 6.09E-10 MKRN1, PPP2R5C, VPRBP, MYLIP, CDC16, ERLEC1, MKRN2, CUL3, 609 13588 1.859332 1.90E-06 6.32E-07 1.10E-06 catabolic process ISG15, RBM8A, ATG7, LOC100046898, PSENEN, CDCA3, ANAPC1, ANAPC2, ANAPC5, SOCS3, ENC1, SOCS4, ASB8, DCUN1D1, PSMA6, SIAH1A, TRIM32, RNF138, GM12396, RNF20, XRN2, USP17L5, FBXO11, RAD23B, UBE2V2, NED GO:0030163~protein catabolic process 1.81E-09 MKRN1, PPP2R5C, VPRBP, MYLIP, CDC16, ERLEC1, MKRN2, CUL3, 556 13588 1.87839 5.64E-06 1.41E-06 3.27E-06 ISG15, ATG7, PSENEN, LOC100046898, CDCA3, ANAPC1, ANAPC2, ANAPC5, SOCS3, ENC1, SOCS4, -

Abstracts from the 51St European Society of Human Genetics Conference: Electronic Posters
European Journal of Human Genetics (2019) 27:870–1041 https://doi.org/10.1038/s41431-019-0408-3 MEETING ABSTRACTS Abstracts from the 51st European Society of Human Genetics Conference: Electronic Posters © European Society of Human Genetics 2019 June 16–19, 2018, Fiera Milano Congressi, Milan Italy Sponsorship: Publication of this supplement was sponsored by the European Society of Human Genetics. All content was reviewed and approved by the ESHG Scientific Programme Committee, which held full responsibility for the abstract selections. Disclosure Information: In order to help readers form their own judgments of potential bias in published abstracts, authors are asked to declare any competing financial interests. Contributions of up to EUR 10 000.- (Ten thousand Euros, or equivalent value in kind) per year per company are considered "Modest". Contributions above EUR 10 000.- per year are considered "Significant". 1234567890();,: 1234567890();,: E-P01 Reproductive Genetics/Prenatal Genetics then compared this data to de novo cases where research based PO studies were completed (N=57) in NY. E-P01.01 Results: MFSIQ (66.4) for familial deletions was Parent of origin in familial 22q11.2 deletions impacts full statistically lower (p = .01) than for de novo deletions scale intelligence quotient scores (N=399, MFSIQ=76.2). MFSIQ for children with mater- nally inherited deletions (63.7) was statistically lower D. E. McGinn1,2, M. Unolt3,4, T. B. Crowley1, B. S. Emanuel1,5, (p = .03) than for paternally inherited deletions (72.0). As E. H. Zackai1,5, E. Moss1, B. Morrow6, B. Nowakowska7,J. compared with the NY cohort where the MFSIQ for Vermeesch8, A. -
![Downloaded from and Have Previously Been Described in Detail [51; 52]](https://docslib.b-cdn.net/cover/3628/downloaded-from-and-have-previously-been-described-in-detail-51-52-1253628.webp)
Downloaded from and Have Previously Been Described in Detail [51; 52]
CpG island structure and trithorax/ polycomb chromatin domains in human cells The MIT Faculty has made this article openly available. Please share how this access benefits you. Your story matters. Citation Orlando, David A., Matthew G. Guenther, Garrett M. Frampton, and Richard A. Young. “CpG Island Structure and Trithorax/ polycomb Chromatin Domains in Human Cells.” Genomics 100, no. 5 (November 2012): 320–326. As Published http://dx.doi.org/10.1016/j.ygeno.2012.07.006 Publisher Elsevier Version Final published version Citable link http://hdl.handle.net/1721.1/101286 Terms of Use Creative Commons Attribution-Noncommercial-NoDerivatives Detailed Terms http://creativecommons.org/licenses/by-nc-nd/4.0/ NIH Public Access Author Manuscript Genomics. Author manuscript; available in PMC 2013 November 01. NIH-PA Author ManuscriptPublished NIH-PA Author Manuscript in final edited NIH-PA Author Manuscript form as: Genomics. 2012 November ; 100(5): 320–326. doi:10.1016/j.ygeno.2012.07.006. CpG Island Structure and Trithorax/Polycomb Chromatin Domains in Human Cells David A. Orlando1,*, Matthew G. Guenther1,*, Garrett M. Frampton1,2,*, and Richard A. Young1,2,† 1Whitehead Institute for Biomedical Research, 9 Cambridge Center, Cambridge, Massachusetts 02142, USA 2Department of Biology, Massachusetts Institute of Technology, Cambridge, Massachusetts 02139, USA Abstract TrxG and PcG complexes play key roles in the epigenetic regulation of development through H3K4me3 and H3K27me3 modification at specific sites throughout the human genome, but how these sites are selected is poorly understood. We find that in pluripotent cells, clustered CpG- islands at genes predict occupancy of H3K4me3 and H3K27me3, and these “bivalent” chromatin domains precisely span the boundaries of CpG-island clusters. -

2Q13 Microduplications
2q13 microduplications rarechromo.org 2q13 microduplications A 2q13 microduplication is a rare genetic condition caused by a small piece of extra genetic material from one of the body’s chromosomes - chromosome 2. Duplications can vary in size but those that are too small to be visible under the microscope using standard techniques are called microduplications. For typical and healthy development, chromosomes should contain the expected amount of genetic material. Like most other chromosome disorders, having an extra piece of chromosome 2 may affect the development and intellectual abilities of a child. The outcome of having a 2q13 microduplication is very variable and depends on a number of factors including what and how much genetic material is duplicated. Background on chromosomes Our bodies are made up of different types of cells, almost all of which contain the same chromosomes. Each chromosome consists of DNA that carries the code for hundreds to thousands of genes. Genes can be thought of as individual instruction booklets (or recipes) that contain all the genetic information that tells the body how to develop, grow and function. Chromosomes (and hence genes) usually come in pairs with one member of each chromosome pair being inherited from each parent. Most cells of the human body have a total of 46 (23 pairs of) chromosomes. The egg and the sperm cells, however, have 23 unpaired chromosomes, so that when the egg and sperm join together at conception, the chromosomes pair up to make 46 in total. Of these 46 chromosomes, 44 are grouped in 22 pairs, numbered 1 to 22. -
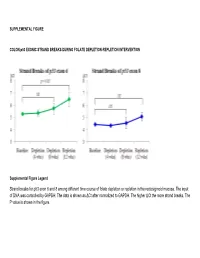
Strand Breaks for P53 Exon 6 and 8 Among Different Time Course of Folate Depletion Or Repletion in the Rectosigmoid Mucosa
SUPPLEMENTAL FIGURE COLON p53 EXONIC STRAND BREAKS DURING FOLATE DEPLETION-REPLETION INTERVENTION Supplemental Figure Legend Strand breaks for p53 exon 6 and 8 among different time course of folate depletion or repletion in the rectosigmoid mucosa. The input of DNA was controlled by GAPDH. The data is shown as ΔCt after normalized to GAPDH. The higher ΔCt the more strand breaks. The P value is shown in the figure. SUPPLEMENT S1 Genes that were significantly UPREGULATED after folate intervention (by unadjusted paired t-test), list is sorted by P value Gene Symbol Nucleotide P VALUE Description OLFM4 NM_006418 0.0000 Homo sapiens differentially expressed in hematopoietic lineages (GW112) mRNA. FMR1NB NM_152578 0.0000 Homo sapiens hypothetical protein FLJ25736 (FLJ25736) mRNA. IFI6 NM_002038 0.0001 Homo sapiens interferon alpha-inducible protein (clone IFI-6-16) (G1P3) transcript variant 1 mRNA. Homo sapiens UDP-N-acetyl-alpha-D-galactosamine:polypeptide N-acetylgalactosaminyltransferase 15 GALNTL5 NM_145292 0.0001 (GALNT15) mRNA. STIM2 NM_020860 0.0001 Homo sapiens stromal interaction molecule 2 (STIM2) mRNA. ZNF645 NM_152577 0.0002 Homo sapiens hypothetical protein FLJ25735 (FLJ25735) mRNA. ATP12A NM_001676 0.0002 Homo sapiens ATPase H+/K+ transporting nongastric alpha polypeptide (ATP12A) mRNA. U1SNRNPBP NM_007020 0.0003 Homo sapiens U1-snRNP binding protein homolog (U1SNRNPBP) transcript variant 1 mRNA. RNF125 NM_017831 0.0004 Homo sapiens ring finger protein 125 (RNF125) mRNA. FMNL1 NM_005892 0.0004 Homo sapiens formin-like (FMNL) mRNA. ISG15 NM_005101 0.0005 Homo sapiens interferon alpha-inducible protein (clone IFI-15K) (G1P2) mRNA. SLC6A14 NM_007231 0.0005 Homo sapiens solute carrier family 6 (neurotransmitter transporter) member 14 (SLC6A14) mRNA. -

A Multiethnic Genome-Wide Analysis of 44,039 Individuals Identifies 41 New Loci Associated with Central Corneal Thickness
ARTICLE https://doi.org/10.1038/s42003-020-1037-7 OPEN A multiethnic genome-wide analysis of 44,039 individuals identifies 41 new loci associated with central corneal thickness ✉ Hélène Choquet 1 , Ronald B. Melles2, Jie Yin1, Thomas J. Hoffmann 3,4, Khanh K. Thai1, Mark N. Kvale3, 1234567890():,; Yambazi Banda3, Alison J. Hardcastle 5,6, Stephen J. Tuft7, M. Maria Glymour4, Catherine Schaefer 1, ✉ Neil Risch1,3,4, K. Saidas Nair8, Pirro G. Hysi 9,10,11 & Eric Jorgenson 1 Central corneal thickness (CCT) is one of the most heritable human traits, with broad-sense heritability estimates ranging between 0.68 to 0.95. Despite the high heritability and numerous previous association studies, only 8.5% of CCT variance is currently explained. Here, we report the results of a multiethnic meta-analysis of available genome-wide asso- ciation studies in which we find association between CCT and 98 genomic loci, of which 41 are novel. Among these loci, 20 were significantly associated with keratoconus, and one (RAPSN rs3740685) was significantly associated with glaucoma after Bonferroni correction. Two-sample Mendelian randomization analysis suggests that thinner CCT does not causally increase the risk of primary open-angle glaucoma. This large CCT study explains up to 14.2% of CCT variance and increases substantially our understanding of the etiology of CCT var- iation. This may open new avenues of investigation into human ocular traits and their rela- tionship to the risk of vision disorders. 1 Kaiser Permanente Northern California (KPNC), Division of Research, Oakland, CA 94612, USA. 2 KPNC, Department of Ophthalmology, Redwood City, CA 94063, USA. -

Disruption of the Anaphase-Promoting Complex Confers Resistance to TTK Inhibitors in Triple-Negative Breast Cancer
Disruption of the anaphase-promoting complex confers resistance to TTK inhibitors in triple-negative breast cancer K. L. Thua,b, J. Silvestera,b, M. J. Elliotta,b, W. Ba-alawib,c, M. H. Duncana,b, A. C. Eliaa,b, A. S. Merb, P. Smirnovb,c, Z. Safikhanib, B. Haibe-Kainsb,c,d,e, T. W. Maka,b,c,1, and D. W. Cescona,b,f,1 aCampbell Family Institute for Breast Cancer Research, Princess Margaret Cancer Centre, University Health Network, Toronto, ON, Canada M5G 1L7; bPrincess Margaret Cancer Centre, University Health Network, Toronto, ON, Canada M5G 1L7; cDepartment of Medical Biophysics, University of Toronto, Toronto, ON, Canada M5G 1L7; dDepartment of Computer Science, University of Toronto, Toronto, ON, Canada M5G 1L7; eOntario Institute for Cancer Research, Toronto, ON, Canada M5G 0A3; and fDepartment of Medicine, University of Toronto, Toronto, ON, Canada M5G 1L7 Contributed by T. W. Mak, December 27, 2017 (sent for review November 9, 2017; reviewed by Mark E. Burkard and Sabine Elowe) TTK protein kinase (TTK), also known as Monopolar spindle 1 (MPS1), ator of the spindle assembly checkpoint (SAC), which delays is a key regulator of the spindle assembly checkpoint (SAC), which anaphase until all chromosomes are properly attached to the functions to maintain genomic integrity. TTK has emerged as a mitotic spindle, TTK has an integral role in maintaining genomic promising therapeutic target in human cancers, including triple- integrity (6). Because most cancer cells are aneuploid, they are negative breast cancer (TNBC). Several TTK inhibitors (TTKis) are heavily reliant on the SAC to adequately segregate their abnormal being evaluated in clinical trials, and an understanding of karyotypes during mitosis.