Preventing Duplicate Bug Reports by Continuously Querying Bug Reports
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
AVG Android App Performance and Trend Report H1 2016
AndroidTM App Performance & Trend Report H1 2016 By AVG® Technologies Table of Contents Executive Summary .....................................................................................2-3 A Insights and Analysis ..................................................................................4-8 B Key Findings .....................................................................................................9 Top 50 Installed Apps .................................................................................... 9-10 World’s Greediest Mobile Apps .......................................................................11-12 Top Ten Battery Drainers ...............................................................................13-14 Top Ten Storage Hogs ..................................................................................15-16 Click Top Ten Data Trafc Hogs ..............................................................................17-18 here Mobile Gaming - What Gamers Should Know ........................................................ 19 C Addressing the Issues ...................................................................................20 Contact Information ...............................................................................21 D Appendices: App Resource Consumption Analysis ...................................22 United States ....................................................................................23-25 United Kingdom .................................................................................26-28 -

Andrew Phay Whatcom CD [email protected]
New Technology for Use in Your District Andrew Phay Whatcom CD [email protected] Smart Phones • Takes the place of GPS, Camera, Data Logger, Notes • GPS o iPhone/iPad – MoronX GPS, SpyGlass o Android – MyTracks, GPSLogger • Document Editing– Docs To Go, Google Docs, Office Suite Pro • Notes & To-Dos’– Evernote, Awesome Note • File Access – DropBox, Box.net • LogMeIn • Soilweb • Calendar sharing and reminders • Email • Weather iPad/Tablets • Mapping/GPS – MyTracks, GPSLogger, GISPro, Google Earth, ArcGIS • Word/Excel/PowerPoint – Docs to Go • Notes – Evernote • Photos/video – GPS tags • Conferencing – Skype, FaceTime • Remote Desktop – LogMeIn • File Access – DropBox, Box.net • Scan/Sign/Edit/Draw • Friend Finder – Device Locator • Security – can wipe from AppleID login • Email • Weather – USGS flooding app • Cases/Keyboards/Other accessories o Pen/GPS/Otter Box GPS Test Web LogMeIn iPad iPhone EverNote Web: Evernote iPad: Evernote Screen Shot Screen Shot iPhone: Evernote Screen Shot Other Hardware • Cameras - Waterproof/Dustproof/Fog-resistant • Portable Projectors File Syncing • DropBox – 2gb free o On smartphones, PC, Mac, Integrates with Docs2Go o Can share a link through email that others can download. • Box.net – 5gb free o Same kind of stuff Online Mapping • ArcGIS.com • Google Maps - My Places • Google Fusion Tables Website Management • Drupal • WordPress • SquareSpace • Google Sites News Aggregators Password Manager • Holds all my passwords • One Master password • On smartphones • Generates passwords • Browser Plugin • Security is great! Browser Plugins • News Aggregators • Lastpass • Screenshots - Fireshot • Download helpers – DownloadThemAll • Morning Coffee Teleconferencing/ Desktop Sharing • LogMeIn - free • Skype - free • Crossloop - free • Join.me – free • GoToMeeting • WebEx Social Networking • Facebook • LinkedIn • Twitter • Google+ • Google Groups Thanks! Andrew Phay [email protected] 360-354-2035 x129 . -

A Security Framework for Mobile Health Applications on Android Platform
A SECURITY FRAMEWORK FOR MOBILE HEALTH APPLICATIONS ON ANDROID PLATFORM MUZAMMIL HUSSAIN FACULTY OF COMPUTER SCIENCE AND INFORMATION TECHNOLOGY UNIVERSITY OF MALAYA UniversityKUALA LUMPUR of Malaya 2017 A SECURITY FRAMEWORK FOR MOBILE HEALTH APPLICATIONS ON ANDROID PLATFORM MUZAMMIL HUSSAIN THESIS SUBMITTED IN FULFILMENT OF THE REQUIREMENTS FOR THE DEGREE OF DOCTOR OF PHILOSOPHY FACULTY OF COMPUTER SCIENCE AND INFORMATION TECHNOLOGY UNIVERSITY OF MALAYA UniversityKUALA LUMPUR of Malaya 2017 UNIVERSITY OF MALAYA ORIGINAL LITERARY WORK DECLARATION Name of Candidate: Muzammil Hussain Matric No: WHA130038 Name of Degree: Doctor of Philosophy Title of Project Paper/Research Report/Dissertation/Thesis (“this Work”): A SECURITY FRAMEWORK FOR MOBILE HEALTH APPLICATIONS ON ANDROID PLATFORM Field of Study: Network Security (Computer Science) I do solemnly and sincerely declare that: (1) I am the sole author/writer of this Work; (2) This Work is original; (3) Any use of any work in which copyright exists was done by way of fair dealing and for permitted purposes and any excerpt or extract from, or reference to or reproduction of any copyright work has been disclosed expressly and sufficiently and the title of the Work and its authorship have been acknowledged in this Work; (4) I do not have any actual knowledge nor do I ought reasonably to know that the making of this work constitutes an infringement of any copyright work; (5) I hereby assign all and every rights in the copyright to this Work to the University of Malaya (“UM”), who henceforth shall be owner of the copyright in this Work and that any reproduction or use in any form or by any means whatsoever is prohibited without the written consent of UM having been first had and obtained; (6) I am fully aware that if in the course of making this Work I have infringed any copyright whether intentionally or otherwise, I may be subject to legal action or any other action as may be determined by UM. -

Understanding and Detecting Wake Lock Misuses for Android Applications
✓ Artifact evaluated by FSE Understanding and Detecting Wake Lock Misuses for Android Applications Yepang Liux Chang Xu‡ Shing-Chi Cheungx Valerio Terragnix xDept. of Comp. Science and Engineering, The Hong Kong Univ. of Science and Technology, Hong Kong, China ‡State Key Lab for Novel Software Tech. and Dept. of Comp. Sci. and Tech., Nanjing University, Nanjing, China x{andrewust, scc*, vterragni}@cse.ust.hk, ‡[email protected]* ABSTRACT over slow network connections, it may take a while for the transaction to complete. If the user's smartphone falls asleep Wake locks are widely used in Android apps to protect crit- while waiting for server messages and does not respond in ical computations from being disrupted by device sleeping. time, the transaction will fail, causing poor user experience. Inappropriate use of wake locks often seriously impacts user To address this problem, modern smartphone platforms al- experience. However, little is known on how wake locks are low apps to explicitly control when to keep certain hardware used in real-world Android apps and the impact of their mis- awake for continuous computation. On Android platforms, uses. To bridge the gap, we conducted a large-scale empiri- wake locks are designed for this purpose. Specifically, to keep cal study on 44,736 commercial and 31 open-source Android certain hardware awake for computation, an app needs to ac- apps. By automated program analysis and manual investi- quire a corresponding type of wake lock from the Android gation, we observed (1) common program points where wake OS (see Section 2.2). When the computation completes, the locks are acquired and released, (2) 13 types of critical com- app should release the acquired wake locks properly. -

Privatumo Apsaugos Metodas Nuo Buvimo Vietos Nustatymo Mobiliesiems Įrenginiams Baigiamasis Magistro Studijų Projektas
Kauno technologijos universitetas Informatikos fakultetas Privatumo apsaugos metodas nuo buvimo vietos nustatymo mobiliesiems įrenginiams Baigiamasis magistro studijų projektas Deimantė Zemeckytė Projekto autorė Prof. Jevgenijus Toldinas Vadovas Kaunas, 2021 Kauno technologijos universitetas Informatikos fakultetas Privatumo apsaugos metodas nuo buvimo vietos nustatymo mobiliesiems įrenginiams Magistro studijų projektas Informacijos ir informaciniu technologijų sauga (621E10003) Deimantė Zemeckytė Projekto autorė Prof. Jevgenijus Toldinas Vadovas Doc. Statys Maciulevičius Recenzentas Kaunas, 2021 2 Kauno technologijos universitetas Informatikos fakultetas Deimantė Zemeckytė Privatumo apsaugos metodas nuo buvimo vietos nustatymo mobiliesiems įrenginiams Akademinio sąžiningumo deklaracija Patvirtinu, kad mano, Deimantė Zemeckytė, baigiamasis projektas tema „Privatumo apsaugos metodas nuo buvimo vietos nustatymo mobiliesiems įrenginiams“ yra parašytas visiškai savarankiškai ir visi pateikti duomenys ar tyrimų rezultatai yra teisingi ir gauti sąžiningai. Šiame darbe nei viena dalis nėra plagijuota nuo jokių spausdintinių ar internetinių šaltinių, visos kitų šaltinių tiesioginės ir netiesioginės citatos nurodytos literatūros nuorodose. Įstatymų nenumatytų piniginių sumų už šį darbą niekam nesu mokėjęs. Aš suprantu, kad išaiškėjus nesąžiningumo faktui, man bus taikomos nuobaudos, remiantis Kauno technologijos universitete galiojančia tvarka. Deimantė Zemeckytė (vardą ir pavardę įrašyti ranka) (parašas) Deimantė Zemeckytė. Privatumo apsaugos -
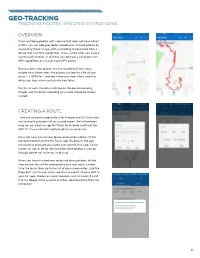
Geo-Tracking Tracking Routes, Syncing Coordinates
geo-tracking tracking routes, syncing coordinates overview: If you are taking photos with a device that does not have a built in GPS, you can add geographic coordinates to those photos by associating those images with a recording of your route from a device that has GPS capabilities. This is useful when you have a camera with no built-in GPS but you do have a cell phone with GPS capabilities or a stand-alone GPS device. Because both your photos and the recording of your route include time information, the photos can look to a file of your route — a GPX file — and see where you were, when, and thus where you were when each photo was taken. For this to work, the date and time on the device recording images and the device recording your route should be closely synced. creating a route: There are numerous applications for Android and iOS that allow you to record geographical routes and export that information. Here we are using the app My Tracks for Android (myTracks for iOS). It is free and works well enough for our purposes. Once you have synced your phone and camera clocks, hit the red record button on the My Tracks app. By default, the app will continue to record your route until you tell it to stop. Go for a walk, car trip, or jet ski ride and take some photos as you go (though please not while you’re driving). When you have finished your route and taking photos, hit the stop button. You will be prompted to give your route a name. -

An Android Application for Capturing Mobility Behavior
EasyTracker: An Android application for capturing mobility behavior Alexandros Doulamis Nikos Pelekis Yannis Theodoridis Dept. of Informatics Dept. of Statistics & Insurance Sci. Dept. of Informatics University of Piraeus University of Piraeus University of Piraeus Piraeus, Greece Piraeus, Greece Piraeus, Greece [email protected] [email protected] [email protected] Abstract — This paper presents EasyTracker, a mobile EasyTracker provides end users with personalized privacy application developed for the Android O/S that enable the functionality [8]. storage, analysis and map visualization of routes of mobile The second key functionality is that EasyTracker allows users. Furthermore, it enable users to manually annotate part a user to annotate parts of her track with labels and therefore of their routes with labels describing their activity and to describe her current activity (e.g. “stopped at café A”, behavior (e.g. “home having breakfast”, “travelling by car to “driving towards office”) [9]. Such feature can turn out to be work”, etc.). Of equal importance, the application encapsulates very useful for automatic fill-in of surveys performed in several state-of-the-art line simplification algorithms for transportation science or for researchers working on activity compressing the trajectories drawn from collected GPS recognition who are usually restricted to use manually records, as well as segmenting trajectories into homogeneous processed surveys. parts in order to facilitate automatic auditing of the user’s manual annotation. Third, EasyTracker encapsulates state-of-the-art algorithms that process in an online fashion the received Keywords - EasyTracker; GPS data; trajectory; path; track; stream of GPS recordings and transforms it into meaningful privacy; compression; segmentation; Android OS tracks, ready to be stored into a trajectory database [10] for further analysis. -

Edoctor: Automatically Diagnosing Abnormal Battery Drain Issues on Smartphones
eDoctor: Automatically Diagnosing Abnormal Battery Drain Issues on Smartphones Xiao Ma∗†, Peng Huang∗, Xinxin Jin∗, Pei Wang‡, Soyeon Park∗, Dongcai Shen∗ Yuanyuan Zhou∗, Lawrence K. Saul∗ and Geoffrey M. Voelker∗ ∗Univ. of California at San Diego, †Univ. of Illinois at Urbana-Champaign, ‡Peking Univ., China Abstract profiling [18, 36, 46, 52], energy efficient hardware [21, 30], operating systems [7, 10, 15, 29, 42, 49, 50, 51], lo- The past few years have witnessed an evolutionary cation services [14, 20, 26, 31], displays [5, 17] and net- change in the smartphone ecosystem. Smartphones have working [4, 6, 32, 41, 43]. Previous work has achieved gone from closed platforms containing only pre-installed notable improvements in smartphone battery life, yet the applications to open platforms hosting a variety of third- focus has primarily been on normal usage, i.e., where the party applications. Unfortunately, this change has also led energy used is needed for normal operation. to a rapidincrease in Abnormal Battery Drain (ABD) prob- In this work, we address an under-explored, yet emerg- lems that can be caused by software defects or miscon- ing type of battery problem on smartphones – Abnormal figuration. Such issues can drain a fully-charged battery Battery Drain (ABD). within a couple of hours, and can potentially affect a sig- nificant number of users. This paper presents eDoctor, a practical tool that helps 1.1 Abnormal Battery Drain Issues regular users troubleshoot abnormal battery drain issues on smartphones. eDoctor leverages the concept of exe- ABD refers to abnormally fast draining of a smartphone’s cution phases to capture an app’s time-varying behavior, battery that is not caused by normal resource usage. -

Appropriate Obfuscation of Location Information on an Application Level for Mobile Devices
Appropriate obfuscation of location information on an application level for mobile devices Empower user to regain control of their location privacy DIPLOMARBEIT zur Erlangung des akademischen Grades Diplom-Ingenieur im Rahmen des Studiums Software Engineering & Internet Computing eingereicht von Christoph Hochreiner Matrikelnummer 0726292 an der Fakultät für Informatik der Technischen Universität Wien Betreuung: Privatdoz. Dipl.-Ing. Mag.rer.soc.oec. Dr.techn. Edgar Weippl Mitwirkung: Univ. Lektor Dr.techn. Markus Huber, MSc Wien, TODOTT.MM.JJJJ (Unterschrift Verfasser) (Unterschrift Betreuung) Technische Universität Wien A-1040 Wien Karlsplatz 13 Tel. +43-1-58801-0 www.tuwien.ac.at Appropriate obfuscation of location information on an application level for mobile devices Empower user to regain control of their location privacy MASTER’S THESIS submitted in partial fulfillment of the requirements for the degree of Diplom-Ingenieur in Software Engineering & Internet Computing by Christoph Hochreiner Registration Number 0726292 to the Faculty of Informatics at the Vienna University of Technology Advisor: Privatdoz. Dipl.-Ing. Mag.rer.soc.oec. Dr.techn. Edgar Weippl Assistance: Univ. Lektor Dr.techn. Markus Huber, MSc Vienna, TODOTT.MM.JJJJ (Signature of Author) (Signature of Advisor) Technische Universität Wien A-1040 Wien Karlsplatz 13 Tel. +43-1-58801-0 www.tuwien.ac.at Erklärung zur Verfassung der Arbeit Christoph Hochreiner Jungerstraße 16, 4950 Altheim Hiermit erkläre ich, dass ich diese Arbeit selbständig verfasst habe, dass ich die verwende- ten Quellen und Hilfsmittel vollständig angegeben habe und dass ich die Stellen der Arbeit - einschließlich Tabellen, Karten und Abbildungen -, die anderen Werken oder dem Internet im Wortlaut oder dem Sinn nach entnommen sind, auf jeden Fall unter Angabe der Quelle als Ent- lehnung kenntlich gemacht habe. -

Enregister Ses Randonnees
ENREGISTER SES RANDONNEES Objectif : cataloguer les tracés des sorties dans le but de les exploiter, de les effectuer de nouveau ou de les partager avec d’autres Pour enregistrer une trace GPS avec son smartphone : télécharger l’application Mes Parcours de Google (simple et gratuite) : https://play.google.com/store/apps/details?id=com.google.android.maps.mytracks Utiliser MesParcours Activer le GPS sur son Lancer l’application Cliquer sur le bouton rouge Le Smartphone commence à Smartphone MesParcours REC pour démarrer enregistrer le parcours l’enregistrement Arrêter l’enregistrement en fin de parcours en cliquant sur le bouton STOP Traces de la randonnée Trois onglets donnent accès … au Graphique, … …et aux Statistiques Saisir les informations à la Carte, … demandées … et éventuellement …en complétant son adresse …. ou le visionner sur partager le fichier de la email…. Google Earth … randonnée par email …. Exploiter ses traces sur son ordinateur Pour télécharger Google Earth (gratuit) : http://www.google.fr/intl/fr/earth/index.html Afficher ses traces GPS avec Google Earth : Enregistrer le tracé sur son ordinateur Lancer le logiciel Google Earth Sélectionner le menu Fichier>Ouvrir En bas de la boîte de dialogue, Rechercher le fichier gpx, kmz ou kml sur Google Earth affiche la trace sélectionner Fichier de type : Gps (*.gpx, l’ordinateur, le sélectionner ou saisir son GPS sur un fond d’image *.loc, *.mps), ou Google Earth nom puis cliquer sur Ouvrir satellite (*.kml*.kmz…) Masquer la Cliquer barre latérale Mesurer avec la règle pour regarder autour de soiCliquer pour se déplacer Envoyer ou imprimer Faire glisser Ajouter un repère, un polygone, un trajet, une couche d’information, enregistrer une le curseur Enregistrer l’image ou cliquer visite sur les Aller dans Google maps boutons Utiliser la barre d’outils pour zoomer Utiliser les curseurs et boutons Avant d’effectuer un survol du ……Configurer la visite 3D Lancer la visite en 3D tracé…. -

Em-Arch: a System Architecture for Reproducible and Extensible Collection of Human Mobility Data
em-arch: A system architecture for reproducible and extensible collection of human mobility data Kalyanaraman Shankari Pavan Yedavalli Ipsita Banerjee Taha Rashidi Randy H. Katz Paul Waddell David E. Culler Electrical Engineering and Computer Sciences University of California at Berkeley Technical Report No. UCB/EECS-2019-88 http://www2.eecs.berkeley.edu/Pubs/TechRpts/2019/EECS-2019-88.html May 20, 2019 Copyright © 2019, by the author(s). All rights reserved. Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission. Acknowledgement In addition to NSF CISE Expeditions Award CCF-1730628, this research is supported in part by gifts from Alibaba, Amazon Web Services, Ant Financial, Arm, CapitalOne, Ericsson, Facebook, Google, Huawei, Intel, Microsoft, Scotiabank, Splunk and VMware. This work was also supported in part by the CONIX Research Center, one of six centers in JUMP, a Semiconductor Research Corporation (SRC) program sponsored by DARPA. em-arch: A system architecture for reproducible and extensible collection of human mobility data January 22, 2019 1 Abstract did you take?", or \How long did it take you?". The 37 origins and destinations of travelers, the time it takes 38 2 Smartphones have revolutionized transportation for to travel, the cost and purpose, and other trip char- 39 3 travelers by providing mapping services that tell users acteristics have historically been collected through 40 4 how to get to a specific destination as well as ride- travel surveys, which form the practice standard for 41 5 hailing services that help them get there. -

Smartphone Applications
Every Æ Aware Project no. 265432 EveryAware Enhance Environmental Awareness through Social Information Technologies http://www.everyaware.eu Seventh Framework Programme (FP7) Future and Emerging Technologies of the Information Communication Technologies (ICT FET Open) D1.2: Final report on: sensor selection, calibration and testing; EveryAware platform; smartphone applications Period covered: from 01/09/2012 to 28/02/2014 Date of preparation: 28/02/2014 Start date of project: March 1st, 2011 Duration: 36 months Due date of deliverable: Apr 30th, 2014 Actual submission date: Apr 30th, 2014 Distribution: Public Status: Final Project coordinator: Vittorio Loreto Project coordinator organisation name: Fondazione ISI, Turin, Italy (ISI) Lead contractor for this deliverable: Fondazione ISI, Turin, Italy (ISI) 2014 c Copyright lies with the respective authors and their institutions Page 2 of 41 EveryAware: Enhance Environmental Awareness through Social Information Technologies Every Æ Contents Aware 1 The sensor box for air quality monitoring 7 1.1 The AirProbe mobile application . .7 1.1.1 Live Track mode . .8 1.1.2 Synchronization mode . .8 1.1.3 Browsing mode . .9 2 The smartphone for noise pollution monitoring 10 3 Calibration of the sensor box 11 3.1 Introduction . 11 3.2 EveryAware sensorbox calibration approach . 11 3.3 Calibration Stages . 14 3.3.1 Stationary Calibration in Turin . 14 3.3.2 Parameterization of the calibration model . 14 3.3.3 Testing of the calibration model . 16 3.4 Mobile and Indoor Calibration for Turin . 18 3.5 Calibration for the international test case . 19 3.5.1 Collection of representative data . 19 3.5.2 Model training and testing .