Whole Genome Comparison of 1,803 Bacteria: an Analysis of Genetic Relatedness
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
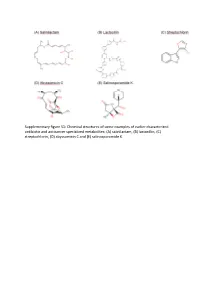
Chemical Structures of Some Examples of Earlier Characterized Antibiotic and Anticancer Specialized
Supplementary figure S1: Chemical structures of some examples of earlier characterized antibiotic and anticancer specialized metabolites: (A) salinilactam, (B) lactocillin, (C) streptochlorin, (D) abyssomicin C and (E) salinosporamide K. Figure S2. Heat map representing hierarchical classification of the SMGCs detected in all the metagenomes in the dataset. Table S1: The sampling locations of each of the sites in the dataset. Sample Sample Bio-project Site depth accession accession Samples Latitude Longitude Site description (m) number in SRA number in SRA AT0050m01B1-4C1 SRS598124 PRJNA193416 Atlantis II water column 50, 200, Water column AT0200m01C1-4D1 SRS598125 21°36'19.0" 38°12'09.0 700 and above the brine N "E (ATII 50, ATII 200, 1500 pool water layers AT0700m01C1-3D1 SRS598128 ATII 700, ATII 1500) AT1500m01B1-3C1 SRS598129 ATBRUCL SRS1029632 PRJNA193416 Atlantis II brine 21°36'19.0" 38°12'09.0 1996– Brine pool water ATBRLCL1-3 SRS1029579 (ATII UCL, ATII INF, N "E 2025 layers ATII LCL) ATBRINP SRS481323 PRJNA219363 ATIID-1a SRS1120041 PRJNA299097 ATIID-1b SRS1120130 ATIID-2 SRS1120133 2168 + Sea sediments Atlantis II - sediments 21°36'19.0" 38°12'09.0 ~3.5 core underlying ATII ATIID-3 SRS1120134 (ATII SDM) N "E length brine pool ATIID-4 SRS1120135 ATIID-5 SRS1120142 ATIID-6 SRS1120143 Discovery Deep brine DDBRINP SRS481325 PRJNA219363 21°17'11.0" 38°17'14.0 2026– Brine pool water N "E 2042 layers (DD INF, DD BR) DDBRINE DD-1 SRS1120158 PRJNA299097 DD-2 SRS1120203 DD-3 SRS1120205 Discovery Deep 2180 + Sea sediments sediments 21°17'11.0" -

The Role of Earthworm Gut-Associated Microorganisms in the Fate of Prions in Soil
THE ROLE OF EARTHWORM GUT-ASSOCIATED MICROORGANISMS IN THE FATE OF PRIONS IN SOIL Von der Fakultät für Lebenswissenschaften der Technischen Universität Carolo-Wilhelmina zu Braunschweig zur Erlangung des Grades eines Doktors der Naturwissenschaften (Dr. rer. nat.) genehmigte D i s s e r t a t i o n von Taras Jur’evič Nechitaylo aus Krasnodar, Russland 2 Acknowledgement I would like to thank Prof. Dr. Kenneth N. Timmis for his guidance in the work and help. I thank Peter N. Golyshin for patience and strong support on this way. Many thanks to my other colleagues, which also taught me and made the life in the lab and studies easy: Manuel Ferrer, Alex Neef, Angelika Arnscheidt, Olga Golyshina, Tanja Chernikova, Christoph Gertler, Agnes Waliczek, Britta Scheithauer, Julia Sabirova, Oleg Kotsurbenko, and other wonderful labmates. I am also grateful to Michail Yakimov and Vitor Martins dos Santos for useful discussions and suggestions. I am very obliged to my family: my parents and my brother, my parents on low and of course to my wife, which made all of their best to support me. 3 Summary.....................................................………………………………………………... 5 1. Introduction...........................................................................................................……... 7 Prion diseases: early hypotheses...………...………………..........…......…......……….. 7 The basics of the prion concept………………………………………………….……... 8 Putative prion dissemination pathways………………………………………….……... 10 Earthworms: a putative factor of the dissemination of TSE infectivity in soil?.………. 11 Objectives of the study…………………………………………………………………. 16 2. Materials and Methods.............................…......................................................……….. 17 2.1 Sampling and general experimental design..................................................………. 17 2.2 Fluorescence in situ Hybridization (FISH)………..……………………….………. 18 2.2.1 FISH with soil, intestine, and casts samples…………………………….……... 18 Isolation of cells from environmental samples…………………………….………. -

Indoor Microbiome, Environmental Characteristics and Asthma Among Junior High
Indoor microbiome, environmental characteristics and asthma among junior high school students in Johor Bahru, Malaysia Xi Fu1, Dan Norbäck2, Qianqian Yuan3,4, Yanling Li3,4, Xunhua Zhu3,4,Yiqun Deng3,4, Jamal Hisham Hashim5,6, Zailina Hashim7, Yi-Wu Zheng8, Xu-Xin Lai8, Michael Dho Spangfort8, Yu Sun3,4 * 1Department of Occupational and Environmental Health, School of Public Health, Sun Yat-sen University, Guangzhou, PR China. 2Occupational and Environmental Medicine, Dept. of Medical Science, University Hospital, Uppsala University, 75237 Uppsala, Sweden. 3Guangdong Provincial Key Laboratory of Protein Function and Regulation in Agricultural Organisms, College of Life Sciences, South China Agricultural University, Guangzhou, Guangdong, 510642, PR China. 4Key Laboratory of Zoonosis of Ministry of Agriculture and Rural Affairs, South China Agricultural University, Guangzhou, Guangdong, 510642, PR China. 5United Nations University-International Institute for Global Health, Kuala Lumpur, Malaysia, 6Department of Community Health, National University of Malaysia, Kuala Lumpur, Malaysia 7Department of Environmental and Occupational Health, Faculty of Medicine and Health Sciences, Universiti Putra Malaysia, UPM, Serdang, Selangor, Malaysia 8Asia Pacific Research, ALK-Abello A/S, Guanzhou, China *To whom corresponds should be addressed: Yu Sun [email protected], Key words: bacteria, fungi, microbial community, absolute quantity, wheezing, breathlessness, adolescence, dampness/visible mold Abstract Indoor microbial diversity and composition are suggested to affect the prevalence and severity of asthma, but no microbial association study has been conducted in tropical countries. In this study, we collected floor dust and environmental characteristics from 21 classrooms, and health data related to asthma symptoms from 309 students, in junior high schools in Johor Bahru, Malaysia. -

Diversity of Understudied Archaeal and Bacterial Populations of Yellowstone National Park: from Genes to Genomes Daniel Colman
University of New Mexico UNM Digital Repository Biology ETDs Electronic Theses and Dissertations 7-1-2015 Diversity of understudied archaeal and bacterial populations of Yellowstone National Park: from genes to genomes Daniel Colman Follow this and additional works at: https://digitalrepository.unm.edu/biol_etds Recommended Citation Colman, Daniel. "Diversity of understudied archaeal and bacterial populations of Yellowstone National Park: from genes to genomes." (2015). https://digitalrepository.unm.edu/biol_etds/18 This Dissertation is brought to you for free and open access by the Electronic Theses and Dissertations at UNM Digital Repository. It has been accepted for inclusion in Biology ETDs by an authorized administrator of UNM Digital Repository. For more information, please contact [email protected]. Daniel Robert Colman Candidate Biology Department This dissertation is approved, and it is acceptable in quality and form for publication: Approved by the Dissertation Committee: Cristina Takacs-Vesbach , Chairperson Robert Sinsabaugh Laura Crossey Diana Northup i Diversity of understudied archaeal and bacterial populations from Yellowstone National Park: from genes to genomes by Daniel Robert Colman B.S. Biology, University of New Mexico, 2009 DISSERTATION Submitted in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Biology The University of New Mexico Albuquerque, New Mexico July 2015 ii DEDICATION I would like to dedicate this dissertation to my late grandfather, Kenneth Leo Colman, associate professor of Animal Science in the Wool laboratory at Montana State University, who even very near the end of his earthly tenure, thought it pertinent to quiz my knowledge of oxidized nitrogen compounds. He was a man of great curiosity about the natural world, and to whom I owe an acknowledgement for his legacy of intellectual (and actual) wanderlust. -

Investigating Prevalence and Geographical Distribution of Mycoplasma Sp. in the Gut of Atlantic Salmon (Salmo Salar L.)
Master’s Thesis 2020 60 ECTS Faculty of Chemistry, Biotechnology and Food Science Investigating prevalence and geographical distribution of Mycoplasma sp. in the gut of Atlantic Salmon (Salmo salar L.) Mari Raudstein MSc Biotechnology ACKNOWLEDGEMENTS This master project was performed at the Faculty of Chemistry, Biotechnology and Food Science, at the Norwegian University of Life Sciences (NMBU), with Professor Knut Rudi as primary supervisor and associate professor Lars-Gustav Snipen as secondary supervisor. To begin with, I want to express my gratitude to my supervisor Knut Rudi for giving me the opportunity to include fish, one of my main interests, in my thesis. Professor Rudi has helped me execute this project to my best ability by giving me new ideas and solutions to problems that would occur, as well as answering any questions I would have. Further, my secondary supervisor associate professor Snipen has helped me in acquiring and interpreting shotgun data for this thesis. A big thank you to both of you. I would also like to thank laboratory engineer Inga Leena Angell for all the guidance in the laboratory, and for her patience when answering questions. Also, thank you to Ida Ormaasen, Morten Nilsen, and the rest of the Microbial Diversity group at NMBU for always being positive, friendly, and helpful – it has been a pleasure working at the MiDiv lab the past year! I am very grateful to the salmon farmers providing me with the material necessary to study salmon gut microbiota. Without the generosity of Lerøy Sjøtroll in Bømlo, Lerøy Aurora in Skjervøy and Mowi in Chile, I would not be able to do this work. -

Species Determination – What's in My Sample?
Species determination – what’s in my sample? What is my sample? • When might you not know what your sample is? • One species • You have a malaria sample but don’t know which species • Misidentification or no identification from culture/MALDI-TOF • Metagenomic samples • Contamination Taxonomic Classifiers • Compare sequence reads against a database and determine the species • BLAST works for a single sequence, too slow for a whole run • Classifiers use database indexing and k-mer searching • Similar accuracy to BLAST but much much faster Wood and Salzberg Genome Biology 2014, 15:R46 Page 3 of 12 http://genomebiology.com/2014/15/3/R46 Kraken taxonomic classifier Figure 1 The Kraken sequence classification algorithm. To classify a sequence, each k-mer in the sequence is mapped to the lowest common ancestor (LCA) of the genomes that contain that k-mer in a database. The taxa associated with the sequence’s k-mers, as well as the taxa’s ancestors, form a pruned subtree of the general taxonomy tree, which is used for classification. In the classification tree, each node has a 15 weight equal to the number of k-mersWood in the and sequence Salzberg associatedGenome with the Biology node’s taxon. 2014 Each root-to-leaf:R46 (RTL) path in the classification tree is scored by adding all weights in the path, and the maximal RTL path in the classification tree is the classification path (nodes highlighted in yellow). The leaf of this classification path (the orange, leftmost leaf in the classification tree) is the classification used for the query sequence. -

Global Metagenomic Survey Reveals a New Bacterial Candidate Phylum in Geothermal Springs
ARTICLE Received 13 Aug 2015 | Accepted 7 Dec 2015 | Published 27 Jan 2016 DOI: 10.1038/ncomms10476 OPEN Global metagenomic survey reveals a new bacterial candidate phylum in geothermal springs Emiley A. Eloe-Fadrosh1, David Paez-Espino1, Jessica Jarett1, Peter F. Dunfield2, Brian P. Hedlund3, Anne E. Dekas4, Stephen E. Grasby5, Allyson L. Brady6, Hailiang Dong7, Brandon R. Briggs8, Wen-Jun Li9, Danielle Goudeau1, Rex Malmstrom1, Amrita Pati1, Jennifer Pett-Ridge4, Edward M. Rubin1,10, Tanja Woyke1, Nikos C. Kyrpides1 & Natalia N. Ivanova1 Analysis of the increasing wealth of metagenomic data collected from diverse environments can lead to the discovery of novel branches on the tree of life. Here we analyse 5.2 Tb of metagenomic data collected globally to discover a novel bacterial phylum (‘Candidatus Kryptonia’) found exclusively in high-temperature pH-neutral geothermal springs. This lineage had remained hidden as a taxonomic ‘blind spot’ because of mismatches in the primers commonly used for ribosomal gene surveys. Genome reconstruction from metagenomic data combined with single-cell genomics results in several high-quality genomes representing four genera from the new phylum. Metabolic reconstruction indicates a heterotrophic lifestyle with conspicuous nutritional deficiencies, suggesting the need for metabolic complementarity with other microbes. Co-occurrence patterns identifies a number of putative partners, including an uncultured Armatimonadetes lineage. The discovery of Kryptonia within previously studied geothermal springs underscores the importance of globally sampled metagenomic data in detection of microbial novelty, and highlights the extraordinary diversity of microbial life still awaiting discovery. 1 Department of Energy Joint Genome Institute, Walnut Creek, California 94598, USA. 2 Department of Biological Sciences, University of Calgary, Calgary, Alberta T2N 1N4, Canada. -

Novel Bacterial Diversity in an Anchialine Blue Hole On
NOVEL BACTERIAL DIVERSITY IN AN ANCHIALINE BLUE HOLE ON ABACO ISLAND, BAHAMAS A Thesis by BRETT CHRISTOPHER GONZALEZ Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE December 2010 Major Subject: Wildlife and Fisheries Sciences NOVEL BACTERIAL DIVERSITY IN AN ANCHIALINE BLUE HOLE ON ABACO ISLAND, BAHAMAS A Thesis by BRETT CHRISTOPHER GONZALEZ Submitted to the Office of Graduate Studies of Texas A&M University in partial fulfillment of the requirements for the degree of MASTER OF SCIENCE Approved by: Chair of Committee, Thomas Iliffe Committee Members, Robin Brinkmeyer Daniel Thornton Head of Department, Thomas Lacher, Jr. December 2010 Major Subject: Wildlife and Fisheries Sciences iii ABSTRACT Novel Bacterial Diversity in an Anchialine Blue Hole on Abaco Island, Bahamas. (December 2010) Brett Christopher Gonzalez, B.S., Texas A&M University at Galveston Chair of Advisory Committee: Dr. Thomas Iliffe Anchialine blue holes found in the interior of the Bahama Islands have distinct fresh and salt water layers, with vertical mixing, and dysoxic to anoxic conditions below the halocline. Scientific cave diving exploration and microbiological investigations of Cherokee Road Extension Blue Hole on Abaco Island have provided detailed information about the water chemistry of the vertically stratified water column. Hydrologic parameters measured suggest that circulation of seawater is occurring deep within the platform. Dense microbial assemblages which occurred as mats on the cave walls below the halocline were investigated through construction of 16S rRNA clone libraries, finding representatives across several bacterial lineages including Chlorobium and OP8. -

A Tertiary-Branched Tetra-Amine, N4-Aminopropylspermidine Is A
Journal of Japanese Society for Extremophiles (2010) Vol.9 (2) Journal of Japanese Society for Extremophiles (2010) Vol. 9 (2), 75-77 ORIGINAL PAPER a a b Hamana K , Hayashi H and Niitsu M NOTE 4 A tertiary-branched tetra-amine, N -aminopropylspermidine is a major cellular polyamine in an anaerobic thermophile, Caldisericum exile belonging to a new bacterial phylum, Caldiserica a Faculty of Engineering, Maebashi Institute of Technology, Maebashi, Gunma 371-0816, Japan. b Faculty of Pharmaceutical Sciences, Josai University, Sakado, Saitama 350-0290, Japan. Corresponding author: Koei Hamana, [email protected] Phone: +81-27-234-4611, Fax: +81-27-234-4611 Received: November 17, 2010 / Revised: December 8, 2010 /Accepted: December 8, 2010 Abstract Acid-extractable cellular polyamines of Anaerobic, moderately thermophilic, filamentous, thermophilic Caldisericum exile belonging to a new thiosulfate-reducing Caldisericum exile was isolated bacterial phylum, Caldiserica were analyzed by HPLC from a terrestrial hot spring in Japan for the first and GC. The coexistence of an unusual tertiary cultivated representative of the candidate phylum OP5 4 brancehed tetra-amine, N -aminopropylspermidine with and located in the newly validated bacterial phylum 19,20) spermine, a linear tetra-amine, as the major polyamines Caldiserica (order Caldisericales) . The in addition to putrescine and spermidine, is first reported temperature range for growth is 55-70°C, with the 20) in the moderate thermophile isolated from a terrestrial optimum growth at 65°C . The optimum growth 20) hot spring in Japan. Linear and branched penta-amines occurs at pH 6.5 and with the absence of NaCl . T were not detected. -

Bordetella Petrii Clinical Isolate Isolates of This Species Have Been Previously Reported from 4
routine laboratory protocols. Initial susceptibility testing Bordetella petrii using disk diffusion indicated apparent susceptibility of the isolate to erythromycin, gentamicin, ceftriaxone, and Clinical Isolate piperacillin/tazobactam. The isolate was resistant to amox- icillin, co-amoxiclav, tetracycline, clindamycin, ciproflo- Norman K. Fry,* John Duncan,* Henry Malnick,* xacin, and metronidazole. After initial sensitivity results, a Marina Warner,* Andrew J. Smith,† 6-week course of oral clarithromycin (500 mg, 8 hourly) Margaret S. Jackson,† and Ashraf Ayoub† was begun. We describe the first clinical isolate of Bordetella petrii At follow-up appointments 3 months and 6 months from a patient with mandibular osteomyelitis. The only pre- after antimicrobial drug therapy ceased, clinical and radi- viously documented isolation of B. petrii occurred after the ographic findings were not unusual, and the infected area initial culture of a single strain from an environmental healed successfully. Despite the successful clinical out- source. come, the isolate was subsequently shown to be resistant to clarithromycin in vitro (Table). Improvement of the 67-year-old man visited an emergency dental clinic, osteomyelitis may also have been facilitated by the biopsy Awhere he complained of toothache in the lower right procedure, during which a sequestrum of bone was mandibular quadrant. Examination showed a root-filled removed. lower right canine tooth that was mobile and tender to per- The gram-negative bacillus (designated strain cussion. The tooth was extracted uneventfully under local GDH030510) was submitted to the Health Protection anesthesia. The patient returned after several days with Agency, Centre for Infections, London, for identification. pain at the extraction site. A localized alveolar osteitis was Preliminary tests results were consistent with those diagnosed, and local debridement measures were institut- described for members of the genus Bordetella. -

Prokaryotic Community Structure and Activity of Sulfate Reducers in Production Water from High-Temperature Oil Reservoirs with and Without Nitrate Treatment
Prokaryotic community structure and activity of sulfate reducers in production water from high-temperature oil reservoirs with and without nitrate treatment Dr. Antje Gittel Dept. of Biological Sciences, Aarhus University ISMOS 2 Aarhus 2009 Introduction Hypothesis Results Conclusions Offshore oil production systems Separation Oil Gas Water Production Injection ~80 degC 50-60 degC Reservoir ISMOS 2, June 2009 Antje Gittel Introduction Hypothesis Results Conclusions Characteristics of the study sites Norway Halfdan • Injection of sulfate-rich seawater Denmark • High loads of organic carbon compounds in the reservoir Dan Enrichment of sulfate -reducing prokaryotes Danish Underground Consortium, Maersk Oil (SRP ) that produce H 2S Souring, plugging, biocorrosion, toxicity, ..... • Strategy to control SRP activity at Halfdan: Addition of nitrate to the injection water ISMOS 2, June 2009 Antje Gittel Introduction Hypothesis Results Conclusions Principles of SRP inhibition by nitrate addition (i) Stimulation of heterothrophic nitrate- reducing bacteria (hNRB ) that hNRB outcompete SRP for electron donors (ii) Activity of nitrate -reducing, sulfide - oxidizing bacteria (NR-SOB ) resulting in SRP NR-SOB a decreasing net production of H2S (iii) Increase in redox potential by the production of nitrite and nitrous oxides and thereby and inhibition of SRP ISMOS 2, June 2009 Antje Gittel Introduction Hypothesis Results Conclusions Compared to an untreated oil field (Dan), nitrate addition to the injection water at Halfdan stimulates the growth of hNRB and/or NR-SOB , resulting in: 1) A general change in the prokaryotic community composition, i.e. • Presence of competitive hNRB and NR-SOB and/or • Presence of SRP that are able to reduce nitrate instead of sulfate 2) A decrease in SRP abundance and activity and 3) A reduced net sulfide production. -

The Mysterious Orphans of Mycoplasmataceae
The mysterious orphans of Mycoplasmataceae Tatiana V. Tatarinova1,2*, Inna Lysnyansky3, Yuri V. Nikolsky4,5,6, and Alexander Bolshoy7* 1 Children’s Hospital Los Angeles, Keck School of Medicine, University of Southern California, Los Angeles, 90027, California, USA 2 Spatial Science Institute, University of Southern California, Los Angeles, 90089, California, USA 3 Mycoplasma Unit, Division of Avian and Aquatic Diseases, Kimron Veterinary Institute, POB 12, Beit Dagan, 50250, Israel 4 School of Systems Biology, George Mason University, 10900 University Blvd, MSN 5B3, Manassas, VA 20110, USA 5 Biomedical Cluster, Skolkovo Foundation, 4 Lugovaya str., Skolkovo Innovation Centre, Mozhajskij region, Moscow, 143026, Russian Federation 6 Vavilov Institute of General Genetics, Moscow, Russian Federation 7 Department of Evolutionary and Environmental Biology and Institute of Evolution, University of Haifa, Israel 1,2 [email protected] 3 [email protected] 4-6 [email protected] 7 [email protected] 1 Abstract Background: The length of a protein sequence is largely determined by its function, i.e. each functional group is associated with an optimal size. However, comparative genomics revealed that proteins’ length may be affected by additional factors. In 2002 it was shown that in bacterium Escherichia coli and the archaeon Archaeoglobus fulgidus, protein sequences with no homologs are, on average, shorter than those with homologs [1]. Most experts now agree that the length distributions are distinctly different between protein sequences with and without homologs in bacterial and archaeal genomes. In this study, we examine this postulate by a comprehensive analysis of all annotated prokaryotic genomes and focusing on certain exceptions.