Conceptual Foundations: Bayesian Inference
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Statistical Methods for Data Science, Lecture 5 Interval Estimates; Comparing Systems
Statistical methods for Data Science, Lecture 5 Interval estimates; comparing systems Richard Johansson November 18, 2018 statistical inference: overview I estimate the value of some parameter (last lecture): I what is the error rate of my drug test? I determine some interval that is very likely to contain the true value of the parameter (today): I interval estimate for the error rate I test some hypothesis about the parameter (today): I is the error rate significantly different from 0.03? I are users significantly more satisfied with web page A than with web page B? -20pt “recipes” I in this lecture, we’ll look at a few “recipes” that you’ll use in the assignment I interval estimate for a proportion (“heads probability”) I comparing a proportion to a specified value I comparing two proportions I additionally, we’ll see the standard method to compute an interval estimate for the mean of a normal I I will also post some pointers to additional tests I remember to check that the preconditions are satisfied: what kind of experiment? what assumptions about the data? -20pt overview interval estimates significance testing for the accuracy comparing two classifiers p-value fishing -20pt interval estimates I if we get some estimate by ML, can we say something about how reliable that estimate is? I informally, an interval estimate for the parameter p is an interval I = [plow ; phigh] so that the true value of the parameter is “likely” to be contained in I I for instance: with 95% probability, the error rate of the spam filter is in the interval [0:05; 0:08] -20pt frequentists and Bayesians again. -

DSA 5403 Bayesian Statistics: an Advancing Introduction 16 Units – Each Unit a Week’S Work
DSA 5403 Bayesian Statistics: An Advancing Introduction 16 units – each unit a week’s work. The following are the contents of the course divided into chapters of the book Doing Bayesian Data Analysis . by John Kruschke. The course is structured around the above book but will be embellished with more theoretical content as needed. The book can be obtained from the library : http://www.sciencedirect.com/science/book/9780124058880 Topics: This is divided into three parts From the book: “Part I The basics: models, probability, Bayes' rule and r: Introduction: credibility, models, and parameters; The R programming language; What is this stuff called probability?; Bayes' rule Part II All the fundamentals applied to inferring a binomial probability: Inferring a binomial probability via exact mathematical analysis; Markov chain Monte C arlo; J AG S ; Hierarchical models; Model comparison and hierarchical modeling; Null hypothesis significance testing; Bayesian approaches to testing a point ("Null") hypothesis; G oals, power, and sample size; S tan Part III The generalized linear model: Overview of the generalized linear model; Metric-predicted variable on one or two groups; Metric predicted variable with one metric predictor; Metric predicted variable with multiple metric predictors; Metric predicted variable with one nominal predictor; Metric predicted variable with multiple nominal predictors; Dichotomous predicted variable; Nominal predicted variable; Ordinal predicted variable; C ount predicted variable; Tools in the trunk” Part 1: The Basics: Models, Probability, Bayes’ Rule and R Unit 1 Chapter 1, 2 Credibility, Models, and Parameters, • Derivation of Bayes’ rule • Re-allocation of probability • The steps of Bayesian data analysis • Classical use of Bayes’ rule o Testing – false positives etc o Definitions of prior, likelihood, evidence and posterior Unit 2 Chapter 3 The R language • Get the software • Variables types • Loading data • Functions • Plots Unit 3 Chapter 4 Probability distributions. -

Statistical Inferences Hypothesis Tests
STATISTICAL INFERENCES HYPOTHESIS TESTS Maªgorzata Murat BASIC IDEAS Suppose we have collected a representative sample that gives some information concerning a mean or other statistical quantity. There are two main questions for which statistical inference may provide answers. 1. Are the sample quantity and a corresponding population quantity close enough together so that it is reasonable to say that the sample might have come from the population? Or are they far enough apart so that they likely represent dierent populations? 2. For what interval of values can we have a specic level of condence that the interval contains the true value of the parameter of interest? STATISTICAL INFERENCES FOR THE MEAN We can divide statistical inferences for the mean into two main categories. In one category, we already know the variance or standard deviation of the population, usually from previous measurements, and the normal distribution can be used for calculations. In the other category, we nd an estimate of the variance or standard deviation of the population from the sample itself. The normal distribution is assumed to apply to the underlying population, but another distribution related to it will usually be required for calculations. TEST OF HYPOTHESIS We are testing the hypothesis that a sample is similar enough to a particular population so that it might have come from that population. Hence we make the null hypothesis that the sample came from a population having the stated value of the population characteristic (the mean or the variation). Then we do calculations to see how reasonable such a hypothesis is. We have to keep in mind the alternative if the null hypothesis is not true, as the alternative will aect the calculations. -

Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam
Practical Statistics for Particle Physics Lecture 1 AEPS2018, Quy Nhon, Vietnam Roger Barlow The University of Huddersfield August 2018 Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 1 / 34 Lecture 1: The Basics 1 Probability What is it? Frequentist Probability Conditional Probability and Bayes' Theorem Bayesian Probability 2 Probability distributions and their properties Expectation Values Binomial, Poisson and Gaussian 3 Hypothesis testing Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 2 / 34 Question: What is Probability? Typical exam question Q1 Explain what is meant by the Probability PA of an event A [1] Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 3 / 34 Four possible answers PA is number obeying certain mathematical rules. PA is a property of A that determines how often A happens For N trials in which A occurs NA times, PA is the limit of NA=N for large N PA is my belief that A will happen, measurable by seeing what odds I will accept in a bet. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 4 / 34 Mathematical Kolmogorov Axioms: For all A ⊂ S PA ≥ 0 PS = 1 P(A[B) = PA + PB if A \ B = ϕ and A; B ⊂ S From these simple axioms a complete and complicated structure can be − ≤ erected. E.g. show PA = 1 PA, and show PA 1.... But!!! This says nothing about what PA actually means. Kolmogorov had frequentist probability in mind, but these axioms apply to any definition. Roger Barlow ( Huddersfield) Statistics for Particle Physics August 2018 5 / 34 Classical or Real probability Evolved during the 18th-19th century Developed (Pascal, Laplace and others) to serve the gambling industry. -
3.3 Bayes' Formula
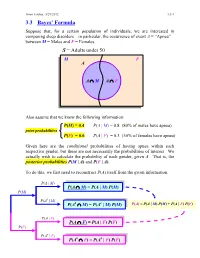
Ismor Fischer, 5/29/2012 3.3-1 3.3 Bayes’ Formula Suppose that, for a certain population of individuals, we are interested in comparing sleep disorders – in particular, the occurrence of event A = “Apnea” – between M = Males and F = Females. S = Adults under 50 M F A A ∩ M A ∩ F Also assume that we know the following information: P(M) = 0.4 P(A | M) = 0.8 (80% of males have apnea) prior probabilities P(F) = 0.6 P(A | F) = 0.3 (30% of females have apnea) Given here are the conditional probabilities of having apnea within each respective gender, but these are not necessarily the probabilities of interest. We actually wish to calculate the probability of each gender, given A. That is, the posterior probabilities P(M | A) and P(F | A). To do this, we first need to reconstruct P(A) itself from the given information. P(A | M) P(A ∩ M) = P(A | M) P(M) P(M) P(Ac | M) c c P(A ∩ M) = P(A | M) P(M) P(A) = P(A | M) P(M) + P(A | F) P(F) P(A | F) P(A ∩ F) = P(A | F) P(F) P(F) P(Ac | F) c c P(A ∩ F) = P(A | F) P(F) Ismor Fischer, 5/29/2012 3.3-2 So, given A… P(M ∩ A) P(A | M) P(M) P(M | A) = P(A) = P(A | M) P(M) + P(A | F) P(F) (0.8)(0.4) 0.32 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.64 and posterior P(F ∩ A) P(A | F) P(F) P(F | A) = = probabilities P(A) P(A | M) P(M) + P(A | F) P(F) (0.3)(0.6) 0.18 = (0.8)(0.4) + (0.3)(0.6) = 0.50 = 0.36 S Thus, the additional information that a M F randomly selected individual has apnea (an A event with probability 50% – why?) increases the likelihood of being male from a prior probability of 40% to a posterior probability 0.32 0.18 of 64%, and likewise, decreases the likelihood of being female from a prior probability of 60% to a posterior probability of 36%. -

The Focused Information Criterion in Logistic Regression to Predict Repair of Dental Restorations
THE FOCUSED INFORMATION CRITERION IN LOGISTIC REGRESSION TO PREDICT REPAIR OF DENTAL RESTORATIONS Cecilia CANDOLO1 ABSTRACT: Statistical data analysis typically has several stages: exploration of the data set; deciding on a class or classes of models to be considered; selecting the best of them according to some criterion and making inferences based on the selected model. The cycle is usually iterative and will involve subject-matter considerations as well as statistical insights. The conclusion reached after such a process depends on the model(s) selected, but the consequent uncertainty is not usually incorporated into the inference. This may lead to underestimation of the uncertainty about quantities of interest and overoptimistic and biased inferences. This framework has been the aim of research under the terminology of model uncertainty and model averanging in both, frequentist and Bayesian approaches. The former usually uses the Akaike´s information criterion (AIC), the Bayesian information criterion (BIC) and the bootstrap method. The last weigths the models using the posterior model probabilities. This work consider model selection uncertainty in logistic regression under frequentist and Bayesian approaches, incorporating the use of the focused information criterion (FIC) (CLAESKENS and HJORT, 2003) to predict repair of dental restorations. The FIC takes the view that a best model should depend on the parameter under focus, such as the mean, or the variance, or the particular covariate values. In this study, the repair or not of dental restorations in a period of eighteen months depends on several covariates measured in teenagers. The data were kindly provided by Juliana Feltrin de Souza, a doctorate student at the Faculty of Dentistry of Araraquara - UNESP. -

The Composite Marginal Likelihood (CML) Inference Approach with Applications to Discrete and Mixed Dependent Variable Models
Technical Report 101 The Composite Marginal Likelihood (CML) Inference Approach with Applications to Discrete and Mixed Dependent Variable Models Chandra R. Bhat Center for Transportation Research September 2014 Data-Supported Transportation Operations & Planning Center (D-STOP) A Tier 1 USDOT University Transportation Center at The University of Texas at Austin D-STOP is a collaborative initiative by researchers at the Center for Transportation Research and the Wireless Networking and Communications Group at The University of Texas at Austin. DISCLAIMER The contents of this report reflect the views of the authors, who are responsible for the facts and the accuracy of the information presented herein. This document is disseminated under the sponsorship of the U.S. Department of Transportation’s University Transportation Centers Program, in the interest of information exchange. The U.S. Government assumes no liability for the contents or use thereof. Technical Report Documentation Page 1. Report No. 2. Government Accession No. 3. Recipient's Catalog No. D-STOP/2016/101 4. Title and Subtitle 5. Report Date The Composite Marginal Likelihood (CML) Inference Approach September 2014 with Applications to Discrete and Mixed Dependent Variable 6. Performing Organization Code Models 7. Author(s) 8. Performing Organization Report No. Chandra R. Bhat Report 101 9. Performing Organization Name and Address 10. Work Unit No. (TRAIS) Data-Supported Transportation Operations & Planning Center (D- STOP) 11. Contract or Grant No. The University of Texas at Austin DTRT13-G-UTC58 1616 Guadalupe Street, Suite 4.202 Austin, Texas 78701 12. Sponsoring Agency Name and Address 13. Type of Report and Period Covered Data-Supported Transportation Operations & Planning Center (D- STOP) The University of Texas at Austin 14. -

Numerical Physics with Probabilities: the Monte Carlo Method and Bayesian Statistics Part I for Assignment 2
Numerical Physics with Probabilities: The Monte Carlo Method and Bayesian Statistics Part I for Assignment 2 Department of Physics, University of Surrey module: Energy, Entropy and Numerical Physics (PHY2063) 1 Numerical Physics part of Energy, Entropy and Numerical Physics This numerical physics course is part of the second-year Energy, Entropy and Numerical Physics mod- ule. It is online at the EENP module on SurreyLearn. See there for assignments, deadlines etc. The course is about numerically solving ODEs (ordinary differential equations) and PDEs (partial differential equations), and introducing the (large) part of numerical physics where probabilities are used. This assignment is on numerical physics of probabilities, and looks at the Monte Carlo (MC) method, and at the Bayesian statistics approach to data analysis. It covers MC and Bayesian statistics, in that order. MC is a widely used numerical technique, it is used, amongst other things, for modelling many random processes. MC is used in fields from statistical physics, to nuclear and particle physics. Bayesian statistics is a powerful data analysis method, and is used everywhere from particle physics to spam-email filters. Data analysis is fundamental to science. For example, analysis of the data from the Large Hadron Collider was required to extract a most probable value for the mass of the Higgs boson, together with an estimate of the region of masses where the scientists think the mass is. This region is typically expressed as a range of mass values where the they think the true mass lies with high (e.g., 95%) probability. Many of you will be analysing data (physics data, commercial data, etc) for your PTY or RY, or future careers1 . -

The Bayesian Approach to Statistics
THE BAYESIAN APPROACH TO STATISTICS ANTHONY O’HAGAN INTRODUCTION the true nature of scientific reasoning. The fi- nal section addresses various features of modern By far the most widely taught and used statisti- Bayesian methods that provide some explanation for the rapid increase in their adoption since the cal methods in practice are those of the frequen- 1980s. tist school. The ideas of frequentist inference, as set out in Chapter 5 of this book, rest on the frequency definition of probability (Chapter 2), BAYESIAN INFERENCE and were developed in the first half of the 20th century. This chapter concerns a radically differ- We first present the basic procedures of Bayesian ent approach to statistics, the Bayesian approach, inference. which depends instead on the subjective defini- tion of probability (Chapter 3). In some respects, Bayesian methods are older than frequentist ones, Bayes’s Theorem and the Nature of Learning having been the basis of very early statistical rea- Bayesian inference is a process of learning soning as far back as the 18th century. Bayesian from data. To give substance to this statement, statistics as it is now understood, however, dates we need to identify who is doing the learning and back to the 1950s, with subsequent development what they are learning about. in the second half of the 20th century. Over that time, the Bayesian approach has steadily gained Terms and Notation ground, and is now recognized as a legitimate al- ternative to the frequentist approach. The person doing the learning is an individual This chapter is organized into three sections. -

Posterior Propriety and Admissibility of Hyperpriors in Normal
The Annals of Statistics 2005, Vol. 33, No. 2, 606–646 DOI: 10.1214/009053605000000075 c Institute of Mathematical Statistics, 2005 POSTERIOR PROPRIETY AND ADMISSIBILITY OF HYPERPRIORS IN NORMAL HIERARCHICAL MODELS1 By James O. Berger, William Strawderman and Dejun Tang Duke University and SAMSI, Rutgers University and Novartis Pharmaceuticals Hierarchical modeling is wonderful and here to stay, but hyper- parameter priors are often chosen in a casual fashion. Unfortunately, as the number of hyperparameters grows, the effects of casual choices can multiply, leading to considerably inferior performance. As an ex- treme, but not uncommon, example use of the wrong hyperparameter priors can even lead to impropriety of the posterior. For exchangeable hierarchical multivariate normal models, we first determine when a standard class of hierarchical priors results in proper or improper posteriors. We next determine which elements of this class lead to admissible estimators of the mean under quadratic loss; such considerations provide one useful guideline for choice among hierarchical priors. Finally, computational issues with the resulting posterior distributions are addressed. 1. Introduction. 1.1. The model and the problems. Consider the block multivariate nor- mal situation (sometimes called the “matrix of means problem”) specified by the following hierarchical Bayesian model: (1) X ∼ Np(θ, I), θ ∼ Np(B, Σπ), where X1 θ1 X2 θ2 Xp×1 = . , θp×1 = . , arXiv:math/0505605v1 [math.ST] 27 May 2005 . X θ m m Received February 2004; revised July 2004. 1Supported by NSF Grants DMS-98-02261 and DMS-01-03265. AMS 2000 subject classifications. Primary 62C15; secondary 62F15. Key words and phrases. Covariance matrix, quadratic loss, frequentist risk, posterior impropriety, objective priors, Markov chain Monte Carlo. -

Scalable and Robust Bayesian Inference Via the Median Posterior
Scalable and Robust Bayesian Inference via the Median Posterior CS 584: Big Data Analytics Material adapted from David Dunson’s talk (http://bayesian.org/sites/default/files/Dunson.pdf) & Lizhen Lin’s ICML talk (http://techtalks.tv/talks/scalable-and-robust-bayesian-inference-via-the-median-posterior/61140/) Big Data Analytics • Large (big N) and complex (big P with interactions) data are collected routinely • Both speed & generality of data analysis methods are important • Bayesian approaches offer an attractive general approach for modeling the complexity of big data • Computational intractability of posterior sampling is a major impediment to application of flexible Bayesian methods CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Positives • Optimization-based approaches, such as ADMM or glmnet, are currently most popular for analyzing big data • General and computationally efficient • Used orders of magnitude more than Bayes methods • Can exploit distributed & cloud computing platforms • Can borrow some advantages of Bayes methods through penalties and regularization CS 584 [Spring 2016] - Ho Existing Frequentist Approaches: The Drawbacks • Such optimization-based methods do not provide measure of uncertainty • Uncertainty quantification is crucial for most applications • Scalable penalization methods focus primarily on convex optimization — greatly limits scope and puts ceiling on performance • For non-convex problems and data with complex structure, existing optimization algorithms can fail badly CS 584 [Spring 2016] - -

The Deviance Information Criterion: 12 Years On
J. R. Statist. Soc. B (2014) The deviance information criterion: 12 years on David J. Spiegelhalter, University of Cambridge, UK Nicola G. Best, Imperial College School of Public Health, London, UK Bradley P. Carlin University of Minnesota, Minneapolis, USA and Angelika van der Linde Bremen, Germany [Presented to The Royal Statistical Society at its annual conference in a session organized by the Research Section on Tuesday, September 3rd, 2013, Professor G. A.Young in the Chair ] Summary.The essentials of our paper of 2002 are briefly summarized and compared with other criteria for model comparison. After some comments on the paper’s reception and influence, we consider criticisms and proposals for improvement made by us and others. Keywords: Bayesian; Model comparison; Prediction 1. Some background to model comparison Suppose that we have a given set of candidate models, and we would like a criterion to assess which is ‘better’ in a defined sense. Assume that a model for observed data y postulates a density p.y|θ/ (which may include covariates etc.), and call D.θ/ =−2log{p.y|θ/} the deviance, here considered as a function of θ. Classical model choice uses hypothesis testing for comparing nested models, e.g. the deviance (likelihood ratio) test in generalized linear models. For non- nested models, alternatives include the Akaike information criterion AIC =−2log{p.y|θˆ/} + 2k where θˆ is the maximum likelihood estimate and k is the number of parameters in the model (dimension of Θ). AIC is built with the aim of favouring models that are likely to make good predictions.