A Cross Generational Dialect Study in Western North Carolina
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Historical Study of the Influences of European Immigration on the Formation of American English
ISSN 1799-2591 Theory and Practice in Language Studies, Vol. 4, No. 11, pp. 2410-2414, November 2014 © 2014 ACADEMY PUBLISHER Manufactured in Finland. doi:10.4304/tpls.4.11.2410-2414 A Historical Study of the Influences of European Immigration on the Formation of American English Chunming Gao School of Foreign Languages, Changchun University of Science and Technology, Changchun, China Lili Sun School of Foreign Languages, Changchun University of Science and Technology, Changchun, China Abstract—The paper studies the formation of American English under the influence of European immigration from a historical perspective. A literature review is presented first with many important early researches on American English, the history of American English, and American immigration. Then a general survey of American English is put forward, including how American English is defined, what the typical features are, how American English is formed and developed. The focus of the paper is the influences of European immigration on the formation of American English, in which the influences of Spanish, French, Dutch and German immigration are illustrated respectively. Index Terms—American English, European immigration, historical perspective I. INTRODUCTION Language is an important carrier of a country’s national culture and is also inevitably affected by the culture. With the development of the world, the global pattern changes quickly and American culture is affecting the world in various forms. It gains great academic and practical significance to study the formation and development of American English under the influence of American immigration culture, which helps understand the history of American English, American culture and American values. -

4. R-Influence on Vowels
4. R-influence on vowels Before you study this chapter, check whether you are familiar with the following terms: allophone, centring diphthong, complementary distribution, diphthong, distribution, foreignism, fricative, full vowel, GA, hiatus, homophone, Intrusive-R, labial, lax, letter-to-sound rule, Linking-R, low-starting diphthong, minimal pair, monophthong, morpheme, nasal, non-productive suffix, non-rhotic accent, phoneme, productive suffix, rhotic accent, R-dropping, RP, tense, triphthong This chapter mainly focuses on the behaviour of full vowels before an /r/, the phonological and letter-to-sound rules related to this behaviour and some further phenomena concerning vowels. As it is demonstrated in Chapter 2 the two main accent types of English, rhotic and non-rhotic accents, are most easily distinguished by whether an /r/ is pronounced in all positions or not. In General American, a rhotic accent, all /r/'s are pronounced while in Received Pronunciation, a non-rhotic variant, only prevocalic ones are. Besides this, these – and other – dialects may also be distinguished by the behaviour of stressed vowels before an /r/, briefly mentioned in the previous chapter. To remind the reader of the most important vowel classes that will be referred to we repeat one of the tables from Chapter 3 for convenience. Tense Lax Monophthongs i, u, 3 , e, , , , , , , 1, 2 Diphthongs and , , , , , , , , triphthongs , Chapter 4 Recall that we have come up with a few generalizations in Chapter 3, namely that all short vowels are lax, all diphthongs and triphthongs are tense, non- high long monophthongs are lax, except for //, which behaves in an ambiguous way: sometimes it is tense, in other cases it is lax. -

Dialects, Standards, and Vernaculars
1 Dialects, Standards, and Vernaculars Most of us have had the experience of sitting in a public place and eavesdropping on conversations taking place around the United States. We pretend to be preoccupied, but we can’t seem to help listening. And we form impressions of speakers based not only on the topic of conversation, but on how people are discussing it. In fact, there’s a good chance that the most critical part of our impression comes from how people talk rather than what they are talking about. We judge people’s regional background, social stat us, ethnicity, and a host of other social and personal traits based simply on the kind of language they are using. We may have similar kinds of reactions in telephone conversations, as we try to associate a set of characteristics with an unidentified speaker in order to make claims such as, “It sounds like a salesperson of some type” or “It sounds like the auto mechanic.” In fact, it is surprising how little conversation it takes to draw conclusions about a speaker’s background – a sentence, a phrase, or even a word is often enough to trigger a regional, social, or ethnic classification. Video: What an accent does Assessments of a complex set of social characteristics and personality traits based on language differences are as inevitable as the kinds of judgments we make when we find out where people live, what their occupations are, where they went to school, and who their friends are. Language differences, in fact, may serve as the single most reliable indicator of social position in our society. -

Perceptions of Different Accent
Masaryk University Faculty of Arts Department of English and American Studies English Language and Literature Hana Richterová Perceptions of Different Accents of English Bachelor ’s Diploma Thesis Supervisor: PhDr. Kate řina Tomková, Ph. D. 2013 I declare that I have worked on this thesis independently, using only the primary and secondary sources listed in the bibliography. …………………………………………….. Author’s signature I would like to thank all of my American respondents who took the time and effort to take part in my research, and all of those who helped me contact them via Facebook, especially Karolina Schmid. My greatest thanks go to Mrs. Kate řina Tomková for her continuous support, willingness and inspirational remarks, which were at the very root of this thesis outline. Table of Contents 1. Introduction ................................................................................................................... 1 2. Theory ........................................................................................................................... 5 2.1 The definition of accent .......................................................................................... 5 2.2 Development of accents of English......................................................................... 6 2.3 Differences between British and American accents ................................................ 8 2.3.1 The separation of the accents ........................................................................... 8 2.3.2 Pronunciation differences .............................................................................. -

Vocalic Phonology in New Testament Manuscripts
VOCALIC PHONOLOGY IN NEW TESTAMENT MANUSCRIPTS by DOUGLAS LLOYD ANDERSON (Under the direction of Jared Klein) ABSTRACT This thesis investigates the development of iotacism and the merger of ! and " in Roman and Byzantine manuscripts of the New Testament. Chapter two uses onomastic variation in the manuscripts of Luke to demonstrate that the confusion of # and $ did not become prevalent until the seventh or eighth century. Furthermore, the variations % ~ # and % ~ $ did not manifest themselves until the ninth century, and then only adjacent to resonants. Chapter three treats the unexpected rarity of the confusion of o and " in certain second through fifth century New Testament manuscripts, postulating a merger of o and " in the second century CE in the communities producing the New Testament. Finally, chapter four discusses the chronology of these vocalic mergers to show that the Greek of the New Testament more closely parallels Attic inscriptions than Egyptian papyri. INDEX WORDS: Phonology, New Testament, Luke, Greek language, Bilingual interference, Iotacism, Vowel quantity, Koine, Dialect VOCALIC PHONOLOGY IN NEW TESTAMENT MANUSCRIPTS by DOUGLAS LLOYD ANDERSON B.A., Emory University, 2003 A Thesis Submitted to the Graduate Faculty of the University of Georgia in Partial Fulfillment of the Requirements for the Degree MASTER OF ARTS ATHENS, GEORGIA 2007 © 2007 Douglas Anderson All Rights Reserved VOCALIC PHONOLOGY IN NEW TESTAMENT MANUSCRIPTS by DOUGLAS LLOYD ANDERSON Major Professor: Jared Klein Committee: Erika Hermanowicz Richard -

The Ideology of American English As Standard English in Taiwan
Arab World English Journal (AWEJ) Volume.7 Number.4 December, 2016 Pp. 80 - 96 The Ideology of American English as Standard English in Taiwan Jackie Chang English Department, National Pingtung University Pingtung City, Taiwan Abstract English language teaching and learning in Taiwan usually refers to American English teaching and learning. Taiwan views American English as Standard English. This is a strictly perceptual and ideological issue, as attested in the language school promotional materials that comprise the research data. Critical Discourse Analysis (CDA) was employed to analyze data drawn from language school promotional materials. The results indicate that American English as Standard English (AESE) ideology is prevalent in Taiwan. American English is viewed as correct, superior and the proper English language version for Taiwanese people to compete globally. As a result, Taiwanese English language learners regard native English speakers with an American accent as having the greatest prestige and as model teachers deserving emulation. This ideology has resulted in racial and linguistic inequalities in contemporary Taiwanese society. AESE gives Taiwanese learners a restricted knowledge of English and its underlying culture. It is apparent that many Taiwanese people need tore-examine their taken-for-granted beliefs about AESE. Keywords: American English as Standard English (AESE),Critical Discourse Analysis (CDA), ideology, inequalities 80 Arab World English Journal (AWEJ) Vol.7. No. 4 December 2016 The Ideology of American English as Standard English in Taiwan Chang Introduction It is an undeniable fact that English has become the global lingua franca. However, as far as English teaching and learning are concerned, there is a prevailing belief that the world should be learning not just any English variety but rather what is termed Standard English. -

Ebonics Hearing
S. HRG. 105±20 EBONICS HEARING BEFORE A SUBCOMMITTEE OF THE COMMITTEE ON APPROPRIATIONS UNITED STATES SENATE ONE HUNDRED FIFTH CONGRESS FIRST SESSION SPECIAL HEARING Printed for the use of the Committee on Appropriations ( U.S. GOVERNMENT PRINTING OFFICE 39±641 cc WASHINGTON : 1997 For sale by the U.S. Government Printing Office Superintendent of Documents, Congressional Sales Office, Washington, DC 20402 COMMITTEE ON APPROPRIATIONS TED STEVENS, Alaska, Chairman THAD COCHRAN, Mississippi ROBERT C. BYRD, West Virginia ARLEN SPECTER, Pennsylvania DANIEL K. INOUYE, Hawaii PETE V. DOMENICI, New Mexico ERNEST F. HOLLINGS, South Carolina CHRISTOPHER S. BOND, Missouri PATRICK J. LEAHY, Vermont SLADE GORTON, Washington DALE BUMPERS, Arkansas MITCH MCCONNELL, Kentucky FRANK R. LAUTENBERG, New Jersey CONRAD BURNS, Montana TOM HARKIN, Iowa RICHARD C. SHELBY, Alabama BARBARA A. MIKULSKI, Maryland JUDD GREGG, New Hampshire HARRY REID, Nevada ROBERT F. BENNETT, Utah HERB KOHL, Wisconsin BEN NIGHTHORSE CAMPBELL, Colorado PATTY MURRAY, Washington LARRY CRAIG, Idaho BYRON DORGAN, North Dakota LAUCH FAIRCLOTH, North Carolina BARBARA BOXER, California KAY BAILEY HUTCHISON, Texas STEVEN J. CORTESE, Staff Director LISA SUTHERLAND, Deputy Staff Director JAMES H. ENGLISH, Minority Staff Director SUBCOMMITTEE ON DEPARTMENTS OF LABOR, HEALTH AND HUMAN SERVICES, AND EDUCATION, AND RELATED AGENCIES ARLEN SPECTER, Pennsylvania, Chairman THAD COCHRAN, Mississippi TOM HARKIN, Iowa SLADE GORTON, Washington ERNEST F. HOLLINGS, South Carolina CHRISTOPHER S. BOND, Missouri DANIEL K. INOUYE, Hawaii JUDD GREGG, New Hampshire DALE BUMPERS, Arkansas LAUCH FAIRCLOTH, North Carolina HARRY REID, Nevada LARRY E. CRAIG, Idaho HERB KOHL, Wisconsin KAY BAILEY HUTCHISON, Texas PATTY MURRAY, Washington Majority Professional Staff CRAIG A. HIGGINS and BETTILOU TAYLOR Minority Professional Staff MARSHA SIMON (II) 2 CONTENTS Page Opening remarks of Senator Arlen Specter .......................................................... -

Why “Correcting” African American Language Speakers Is Counterproductive
Language Arts Journal of Michigan Volume 32 Issue 2 Race, Language, & Privilege Article 6 5-2017 Why “Correcting” African American Language Speakers is Counterproductive Alice Lee Illinois State University, [email protected] Follow this and additional works at: https://scholarworks.gvsu.edu/lajm Part of the Bilingual, Multilingual, and Multicultural Education Commons, Curriculum and Instruction Commons, Educational Methods Commons, Elementary Education Commons, Elementary Education and Teaching Commons, and the Junior High, Intermediate, Middle School Education and Teaching Commons Recommended Citation Lee, Alice (2017) "Why “Correcting” African American Language Speakers is Counterproductive," Language Arts Journal of Michigan: Vol. 32: Iss. 2, Article 6. Available at: https://doi.org/10.9707/2168-149X.2162 This Article is brought to you for free and open access by ScholarWorks@GVSU. It has been accepted for inclusion in Language Arts Journal of Michigan by an authorized editor of ScholarWorks@GVSU. For more information, please contact [email protected]. PRACTICE Why “Correcting” African American Language Speakers is Counterproductive ALICE LEE n a Spring afternoon ing them to talk like that in the class- in-service teacher attitudes towards AAL in 2010, I sat in the room, when they’ll be expected to speak in their classrooms. In my experience back of a university standard English in the real world?” working with pre-service teachers, while classroom doing my Those questions began my quest to many are open to accepting AAL as a best to listen to my better understand AAL and what role it “real” language, there are still questions professor talk about language diversity, a should play in the classroom. -

An Examination of Oral Articulation of Vowel Nasality in the Light of the Independent Effects of Nasalization on Vowel Quality
DOI: 10.17469/O2104AISV000002 CHRISTOPHER CARIGNAN An examination of oral articulation of vowel nasality in the light of the independent effects of nasalization on vowel quality In this paper, a summary is given of an experimental technique to address a known issue in research on the independent effects of nasalization on vowel acoustics: given that the separate transfer functions associated with the oral and nasal cavities are merged in the acoustic signal, the task of teasing apart the respective effects of the two cavities seems to be an intractable problem. The results obtained from the method reveal that the independent effects of nasal- ization on the acoustic vowel space are: F1-raising for high vowels, F1-lowering for non-high vowels, and F2-lowering for non-front vowels. The results from previous articulatory research performed by the author on the production of vowel nasality in French, Hindi, and English are discussed in the light of these independent effects of nasalization on vowel quality. Keywords: vowel nasality, vowel quality, articulation, acoustics, sound change. 1. Introduction A traditional characterization of vowel nasality adopts a seemingly binary classification of vowel sounds based on the relative height of the velum: nasal vowels are produced with a low velum position (and, thus, air radiation from both the oral and nasal cavities), where- as oral vowels are produced with a high velum position (and, thus, air radiation from the oral cavity alone). While it is unquestionably true that nasal vowels are produced with a lowered velum, this traditional characterization carries an implicit assumption about the state of the oral cavity for the production of a nasal vowel, i.e., that the nasal vowel maintains the same articulatory characteristics as its non-nasal counterpart in all aspects except for the height of the velum. -

Formant Dynamics of Spanish Vocalic Sequences in Related Speakers: a Forensic-Voice-Comparison Investigation
Journal of Phonetics 75 (2019) 1–26 Contents lists available at ScienceDirect Journal of Phonetics journal homepage: www.elsevier.com/locate/Phonetics Research Article Formant dynamics of Spanish vocalic sequences in related speakers: A forensic-voice-comparison investigation Eugenia San Segundo*, Junjie Yang Department of Criminal Science and Technology, Shanxi Police College, No. 799, North-west Section, Qing Dong Road, Qingxu County, Taiyuan, Shanxi, China article info abstract Article history: This study investigates the dynamic acoustic properties of 19 vocalic sequences of Standard Peninsular Spanish, Received 30 August 2018 showing their potential for forensic voice comparison. Parametric curves (polynomials and discrete cosine trans- Received in revised form 28 March 2019 form) were fitted to the formant trajectories of the 19 Spanish vocalic sequences of 54 male speakers, comprising Accepted 1 April 2019 monozygotic (MZ) and dizygotic (DZ) twin pairs, non-twin brothers and unrelated speakers. Using the curve-fitting estimated coefficients as input to a multivariate-kernel-density formula, cross-validated likelihood ratios were cal- Keywords: culated to express the probability of obtaining the observed difference between two speech samples under the Formant dynamics hypothesis that the samples were produced by the same speaker and under the hypothesis that they were pro- Vocalic sequences duced by a different speaker. The results show that the best-performing system is one that fuses the 19 vocalic Diphthongs sequences with a geometric-mean fusion method. When challenging the system with related speakers, the results Twins show that MZ twin pairs affect performance but, more importantly, that non-twin sibling pairs can deteriorate per- Spanish formance too. -

On the Anatomy of a Chain Shift1 DANIEL A
J. Linguistics, Page 1 of 25. f Cambridge University Press 2010 doi:10.1017/S0022226710000368 On the anatomy of a chain shift1 DANIEL A. DINNSEN, CHRISTOPHER R. GREEN, JUDITH A. GIERUT & MICHELE L. MORRISETTE Indiana University (Received 4 September 2009; revised 28 April 2010) Phonological chain shifts have been the focus of many theoretical, developmental, and clinical concerns. This paper considers an overlooked property of the problem by focusing on the typological properties of the widely attested ‘s>h>f’ chain shift involving the processes of Labialization and Dentalization in early phonological development. Findings are reported from a cross-sectional study of 234 children (ages 3 years; 0 months–7;9) with functional (nonorganic) phonological delays. The results reveal some unexpected gaps in the predicted interactions of these processes and are brought to bear on the evaluation of recent optimality theoretic proposals for the characterization of phonological interactions. A developmental modification to the theory is proposed that has the desired effect of precluding certain early-stage grammars. The proposal is further evaluated against the facts of another widely cited developmental chain shift known as the ‘puzzle>puddle>pickle’ problem (Smith 1973). 1. I NTRODUCTION A common phenomenon in both first- and second-language acquisition and in fully-developed languages is for phonological processes to participate in a chain shift (e.g. Moreton & Smolensky 2002, Jesney 2005, Dinnsen 2008b). Chain shifts typically involve two phonological processes that interact in such a way that they result in an opaque generalization (i.e. one that is not surface-true). This phenomenon has generated much discussion and contro- versy in the theoretical, developmental, and clinical literature over the years and has raised questions about the very nature of chain shifts. -
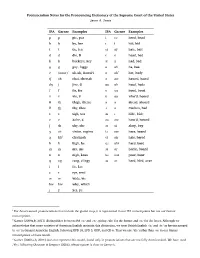
Pronunciation Notes (PDF)
Pronunciation Notes for the Pronouncing Dictionary of the Supreme Court of the United States Jason A. Zentz IPA Garner Examples IPA Garner Examples p p pie, pea i ee heed, bead b b by, bee ɪ i hid, bid t t tie, tea eɪ ay hate, bait d d die, D ɛ e head, bed k k buckeye, key æ a had, bad ɡ g guy, foggy ɑ ah ha, baa ʔ (none)1 uh-uh, Hawaiʻi ɑ ah2 hot, body tʃ ch chai, cheetah ɔ aw hawed, bawd dʒ j jive, G oʊ oh hoed, bode f f fie, fee ʊ uu hood, book v v vie, V u oo whoʼd, booed θ th thigh, theme ə ə ahead, aboard ð th thy, thee ʌ ə Hudson, bud s s sigh, sea aɪ ɪ hide, bide z z Zaire, Z aʊ ow howʼd, bowed ʃ sh shy, she ɔɪ oi ahoy, boy ʒ zh vision, regime iɹ eer here, beard χ kh3 chutzpah ɛɹ air hair, bared h h high, he ɑɹ ahr hard, bard m m my, me ɔɹ or horde, board n n nigh, knee uɹ oor poor, boor ŋ ng rang, clingy əɹ ər herd, bird, over l l lie, Lee ɹ r rye, reed w w wide, we hw hw why, which j y yes, ye 1 For Americanized pronunciations that include the glottal stop, it is represented in our IPA transcriptions but not our Garner transcriptions. 2 Garner (2009a,b, 2011) distinguishes between IPA /ɑ/ and /ɒ/, giving /ah/ for the former and /o/ for the latter.