Sequencing and Analysis of Proteins
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Anaphylatoxin-Mediated Shock Susceptibility to C5a Carboxypeptidase N (CPN1) Causes the Murine Small Subunit of Targeted Disrupt
Targeted Disruption of the Gene Encoding the Murine Small Subunit of Carboxypeptidase N (CPN1) Causes Susceptibility to C5a This information is current as Anaphylatoxin-Mediated Shock of September 28, 2021. Stacey L. Mueller-Ortiz, Dachun Wang, John E. Morales, Li Li, Jui-Yoa Chang and Rick A. Wetsel J Immunol 2009; 182:6533-6539; ; doi: 10.4049/jimmunol.0804207 Downloaded from http://www.jimmunol.org/content/182/10/6533 References This article cites 43 articles, 9 of which you can access for free at: http://www.jimmunol.org/ http://www.jimmunol.org/content/182/10/6533.full#ref-list-1 Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists by guest on September 28, 2021 • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2009 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Targeted Disruption of the Gene Encoding the Murine Small Subunit of Carboxypeptidase N (CPN1) Causes Susceptibility to C5a Anaphylatoxin-Mediated Shock1 Stacey L. Mueller-Ortiz,* Dachun Wang,* John E. -

Human Induced Pluripotent Stem Cell–Derived Podocytes Mature Into Vascularized Glomeruli Upon Experimental Transplantation
BASIC RESEARCH www.jasn.org Human Induced Pluripotent Stem Cell–Derived Podocytes Mature into Vascularized Glomeruli upon Experimental Transplantation † Sazia Sharmin,* Atsuhiro Taguchi,* Yusuke Kaku,* Yasuhiro Yoshimura,* Tomoko Ohmori,* ‡ † ‡ Tetsushi Sakuma, Masashi Mukoyama, Takashi Yamamoto, Hidetake Kurihara,§ and | Ryuichi Nishinakamura* *Department of Kidney Development, Institute of Molecular Embryology and Genetics, and †Department of Nephrology, Faculty of Life Sciences, Kumamoto University, Kumamoto, Japan; ‡Department of Mathematical and Life Sciences, Graduate School of Science, Hiroshima University, Hiroshima, Japan; §Division of Anatomy, Juntendo University School of Medicine, Tokyo, Japan; and |Japan Science and Technology Agency, CREST, Kumamoto, Japan ABSTRACT Glomerular podocytes express proteins, such as nephrin, that constitute the slit diaphragm, thereby contributing to the filtration process in the kidney. Glomerular development has been analyzed mainly in mice, whereas analysis of human kidney development has been minimal because of limited access to embryonic kidneys. We previously reported the induction of three-dimensional primordial glomeruli from human induced pluripotent stem (iPS) cells. Here, using transcription activator–like effector nuclease-mediated homologous recombination, we generated human iPS cell lines that express green fluorescent protein (GFP) in the NPHS1 locus, which encodes nephrin, and we show that GFP expression facilitated accurate visualization of nephrin-positive podocyte formation in -

ABSTRACT MUDIGANTI, USHARANI. Insect Response to Alphavirus Infection. (Under the Direction of Prof
ABSTRACT MUDIGANTI, USHARANI. Insect response to alphavirus infection. (Under the Direction of Prof. Dennis T. Brown.) Invertebrate cells survive Alphavirus infections to establish viral persistence, in contrast to cell death seen soon after infection in mammalian cells. Invertebrate response to prototype alphavirus, Sindbis, has been studied to a certain extent, using mosquitoes and cell lines derived from mosquitoes. Some of the observations made in studies using mosquito systems include formation of intracellular vesicles soon after infection with Sindbis, identification of antiviral activity in the media used to grow the mosquito cell lines and in Sindbis-infected mosquito cell lysates, controlled levels of virus production as persistence is established and superinfection exclusion by Sindbis-infected cells. The study presented here is designed to utilize array of genomic and genetic information available in Drosophila model to identify the candidate genes / gene products playing a role in establishment of alphavirus persistence. Observations described in Chapter I establish Drosophila S2 cells as a suitable invertebrate system to study alphavirus-insect interactions. Gene expression analysis identified increased expression of 18 transcripts coding for membrane trafficking and cytoskeletal components and 10 transcripts coding for Notch pathway components, at 5 days post-infection. Identification of upregulation of Notch pathway suggests similarities between mechanism of establishment of persistence of Alphaviruses and Herpesviruses. Transcript coding for TEP II, a wide-spectrum protease inhibitor is increased in expression at 5 days post- infection and upon superinfection at 5 days post-infection. We probed for inhibition of viral protease activity during early persistence and upon superinfection of Sindbis- infected cells with Sindbis. -

Handbook of Proteolytic Enzymes Second Edition Volume 1 Aspartic and Metallo Peptidases
Handbook of Proteolytic Enzymes Second Edition Volume 1 Aspartic and Metallo Peptidases Alan J. Barrett Neil D. Rawlings J. Fred Woessner Editor biographies xxi Contributors xxiii Preface xxxi Introduction ' Abbreviations xxxvii ASPARTIC PEPTIDASES Introduction 1 Aspartic peptidases and their clans 3 2 Catalytic pathway of aspartic peptidases 12 Clan AA Family Al 3 Pepsin A 19 4 Pepsin B 28 5 Chymosin 29 6 Cathepsin E 33 7 Gastricsin 38 8 Cathepsin D 43 9 Napsin A 52 10 Renin 54 11 Mouse submandibular renin 62 12 Memapsin 1 64 13 Memapsin 2 66 14 Plasmepsins 70 15 Plasmepsin II 73 16 Tick heme-binding aspartic proteinase 76 17 Phytepsin 77 18 Nepenthesin 85 19 Saccharopepsin 87 20 Neurosporapepsin 90 21 Acrocylindropepsin 9 1 22 Aspergillopepsin I 92 23 Penicillopepsin 99 24 Endothiapepsin 104 25 Rhizopuspepsin 108 26 Mucorpepsin 11 1 27 Polyporopepsin 113 28 Candidapepsin 115 29 Candiparapsin 120 30 Canditropsin 123 31 Syncephapepsin 125 32 Barrierpepsin 126 33 Yapsin 1 128 34 Yapsin 2 132 35 Yapsin A 133 36 Pregnancy-associated glycoproteins 135 37 Pepsin F 137 38 Rhodotorulapepsin 139 39 Cladosporopepsin 140 40 Pycnoporopepsin 141 Family A2 and others 41 Human immunodeficiency virus 1 retropepsin 144 42 Human immunodeficiency virus 2 retropepsin 154 43 Simian immunodeficiency virus retropepsin 158 44 Equine infectious anemia virus retropepsin 160 45 Rous sarcoma virus retropepsin and avian myeloblastosis virus retropepsin 163 46 Human T-cell leukemia virus type I (HTLV-I) retropepsin 166 47 Bovine leukemia virus retropepsin 169 48 -
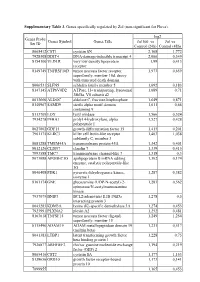
Supplementary Table 3. Genes Specifically Regulated by Zol (Non-Significant for Fluva)
Supplementary Table 3. Genes specifically regulated by Zol (non-significant for Fluva). log2 Genes Probe Genes Symbol Genes Title Zol100 vs Zol vs Set ID Control (24h) Control (48h) 8065412 CST1 cystatin SN 2,168 1,772 7928308 DDIT4 DNA-damage-inducible transcript 4 2,066 0,349 8154100 VLDLR very low density lipoprotein 1,99 0,413 receptor 8149749 TNFRSF10D tumor necrosis factor receptor 1,973 0,659 superfamily, member 10d, decoy with truncated death domain 8006531 SLFN5 schlafen family member 5 1,692 0,183 8147145 ATP6V0D2 ATPase, H+ transporting, lysosomal 1,689 0,71 38kDa, V0 subunit d2 8013660 ALDOC aldolase C, fructose-bisphosphate 1,649 0,871 8140967 SAMD9 sterile alpha motif domain 1,611 0,66 containing 9 8113709 LOX lysyl oxidase 1,566 0,524 7934278 P4HA1 prolyl 4-hydroxylase, alpha 1,527 0,428 polypeptide I 8027002 GDF15 growth differentiation factor 15 1,415 0,201 7961175 KLRC3 killer cell lectin-like receptor 1,403 1,038 subfamily C, member 3 8081288 TMEM45A transmembrane protein 45A 1,342 0,401 8012126 CLDN7 claudin 7 1,339 0,415 7993588 TMC7 transmembrane channel-like 7 1,318 0,3 8073088 APOBEC3G apolipoprotein B mRNA editing 1,302 0,174 enzyme, catalytic polypeptide-like 3G 8046408 PDK1 pyruvate dehydrogenase kinase, 1,287 0,382 isozyme 1 8161174 GNE glucosamine (UDP-N-acetyl)-2- 1,283 0,562 epimerase/N-acetylmannosamine kinase 7937079 BNIP3 BCL2/adenovirus E1B 19kDa 1,278 0,5 interacting protein 3 8043283 KDM3A lysine (K)-specific demethylase 3A 1,274 0,453 7923991 PLXNA2 plexin A2 1,252 0,481 8163618 TNFSF15 tumor necrosis -

University of Alberta
University of Alberta Revisiting the antifibrinolytic effect of carboxypeptidase N: novel structure and regulation by Pascale Libront Swanson A thesis submitted to the Faculty of Graduate Studies and Research in partial fulfillment of the requirements for the degree of Master of Science Medical Sciences - Pediatrics ©Pascale Libront Swanson Fall 2010 Edmonton, Alberta Permission is hereby granted to the University of Alberta Libraries to reproduce single copies of this thesis and to lend or sell such copies for private, scholarly or scientific research purposes only. Where the thesis is converted to, or otherwise made available in digital form, the University of Alberta will advise potential users of the thesis of these terms. The author reserves all other publication and other rights in association with the copyright in the thesis and, except as herein before provided, neither the thesis nor any substantial portion thereof may be printed or otherwise reproduced in any material form whatsoever without the author's prior written permission. Library and Archives Bibliothèque et Canada Archives Canada Published Heritage Direction du Branch Patrimoine de l’édition 395 Wellington Street 395, rue Wellington Ottawa ON K1A 0N4 Ottawa ON K1A 0N4 Canada Canada Your file Votre référence ISBN: 978-0-494-67985-2 Our file Notre référence ISBN: 978-0-494-67985-2 NOTICE: AVIS: The author has granted a non- L’auteur a accordé une licence non exclusive exclusive license allowing Library and permettant à la Bibliothèque et Archives Archives Canada to reproduce, Canada de reproduire, publier, archiver, publish, archive, preserve, conserve, sauvegarder, conserver, transmettre au public communicate to the public by par télécommunication ou par l’Internet, prêter, telecommunication or on the Internet, distribuer et vendre des thèses partout dans le loan, distribute and sell theses monde, à des fins commerciales ou autres, sur worldwide, for commercial or non- support microforme, papier, électronique et/ou commercial purposes, in microform, autres formats. -

BIO-ORGANIC and BIOPHYSICAL CHEMISTRY MODULE No. 8: Introduction to Enzymes, Their Nomenclature & Classification
____________________________________________________________________________________________________ Subject Chemistry Paper No and Title 16; Bioorganic and Biophysical Chemistry Module No and Title 8; Introduction to Enzymes, their classification and nomenclature Module Tag CHE_P16_M8 Chemistry PAPER No. 16: BIO-ORGANIC AND BIOPHYSICAL CHEMISTRY MODULE No. 8: Introduction to Enzymes, their nomenclature & classification ____________________________________________________________________________________________________ TABLE OF CONTENTS 1. Learning Outcomes 2. Introduction 3. Introduction to Enzymes 3.1 Enzymes are biocatalysts 3.2 History of Enzymology 3.3 Interaction of Enzyme with substrate 3.4 Cofactors and coenzymes 4. Nomenclature and classification of enzymes 4.1 Common names 4.2 IUBMB classification and nomenclature 5. Summary Chemistry PAPER No. 16: BIO-ORGANIC AND BIOPHYSICAL CHEMISTRY MODULE No. 8: Introduction to Enzymes, their nomenclature & classification ____________________________________________________________________________________________________ 1. Learning Outcomes After studying this module, you shall be able to: • Know what are enzymes and how they are different from chemical catalysts • Learn history f discovery of enzymes • How to enzymes recognize their substrates? • Know enzymes require cofactors and coenzymes beyond amino acids which it is made of. • Learn how enzymes are named. 2. Introduction Enzymes are biological catalysts Mostly enzymes are proteins which possess catalytic activity. Enzymes were discovered -

(12) Patent Application Publication (10) Pub. No.: US 2012/0266329 A1 Mathur Et Al
US 2012026.6329A1 (19) United States (12) Patent Application Publication (10) Pub. No.: US 2012/0266329 A1 Mathur et al. (43) Pub. Date: Oct. 18, 2012 (54) NUCLEICACIDS AND PROTEINS AND CI2N 9/10 (2006.01) METHODS FOR MAKING AND USING THEMI CI2N 9/24 (2006.01) CI2N 9/02 (2006.01) (75) Inventors: Eric J. Mathur, Carlsbad, CA CI2N 9/06 (2006.01) (US); Cathy Chang, San Marcos, CI2P 2L/02 (2006.01) CA (US) CI2O I/04 (2006.01) CI2N 9/96 (2006.01) (73) Assignee: BP Corporation North America CI2N 5/82 (2006.01) Inc., Houston, TX (US) CI2N 15/53 (2006.01) CI2N IS/54 (2006.01) CI2N 15/57 2006.O1 (22) Filed: Feb. 20, 2012 CI2N IS/60 308: Related U.S. Application Data EN f :08: (62) Division of application No. 1 1/817,403, filed on May AOIH 5/00 (2006.01) 7, 2008, now Pat. No. 8,119,385, filed as application AOIH 5/10 (2006.01) No. PCT/US2006/007642 on Mar. 3, 2006. C07K I4/00 (2006.01) CI2N IS/II (2006.01) (60) Provisional application No. 60/658,984, filed on Mar. AOIH I/06 (2006.01) 4, 2005. CI2N 15/63 (2006.01) Publication Classification (52) U.S. Cl. ................... 800/293; 435/320.1; 435/252.3: 435/325; 435/254.11: 435/254.2:435/348; (51) Int. Cl. 435/419; 435/195; 435/196; 435/198: 435/233; CI2N 15/52 (2006.01) 435/201:435/232; 435/208; 435/227; 435/193; CI2N 15/85 (2006.01) 435/200; 435/189: 435/191: 435/69.1; 435/34; CI2N 5/86 (2006.01) 435/188:536/23.2; 435/468; 800/298; 800/320; CI2N 15/867 (2006.01) 800/317.2: 800/317.4: 800/320.3: 800/306; CI2N 5/864 (2006.01) 800/312 800/320.2: 800/317.3; 800/322; CI2N 5/8 (2006.01) 800/320.1; 530/350, 536/23.1: 800/278; 800/294 CI2N I/2 (2006.01) CI2N 5/10 (2006.01) (57) ABSTRACT CI2N L/15 (2006.01) CI2N I/19 (2006.01) The invention provides polypeptides, including enzymes, CI2N 9/14 (2006.01) structural proteins and binding proteins, polynucleotides CI2N 9/16 (2006.01) encoding these polypeptides, and methods of making and CI2N 9/20 (2006.01) using these polynucleotides and polypeptides. -

All Enzymes in BRENDA™ the Comprehensive Enzyme Information System
All enzymes in BRENDA™ The Comprehensive Enzyme Information System http://www.brenda-enzymes.org/index.php4?page=information/all_enzymes.php4 1.1.1.1 alcohol dehydrogenase 1.1.1.B1 D-arabitol-phosphate dehydrogenase 1.1.1.2 alcohol dehydrogenase (NADP+) 1.1.1.B3 (S)-specific secondary alcohol dehydrogenase 1.1.1.3 homoserine dehydrogenase 1.1.1.B4 (R)-specific secondary alcohol dehydrogenase 1.1.1.4 (R,R)-butanediol dehydrogenase 1.1.1.5 acetoin dehydrogenase 1.1.1.B5 NADP-retinol dehydrogenase 1.1.1.6 glycerol dehydrogenase 1.1.1.7 propanediol-phosphate dehydrogenase 1.1.1.8 glycerol-3-phosphate dehydrogenase (NAD+) 1.1.1.9 D-xylulose reductase 1.1.1.10 L-xylulose reductase 1.1.1.11 D-arabinitol 4-dehydrogenase 1.1.1.12 L-arabinitol 4-dehydrogenase 1.1.1.13 L-arabinitol 2-dehydrogenase 1.1.1.14 L-iditol 2-dehydrogenase 1.1.1.15 D-iditol 2-dehydrogenase 1.1.1.16 galactitol 2-dehydrogenase 1.1.1.17 mannitol-1-phosphate 5-dehydrogenase 1.1.1.18 inositol 2-dehydrogenase 1.1.1.19 glucuronate reductase 1.1.1.20 glucuronolactone reductase 1.1.1.21 aldehyde reductase 1.1.1.22 UDP-glucose 6-dehydrogenase 1.1.1.23 histidinol dehydrogenase 1.1.1.24 quinate dehydrogenase 1.1.1.25 shikimate dehydrogenase 1.1.1.26 glyoxylate reductase 1.1.1.27 L-lactate dehydrogenase 1.1.1.28 D-lactate dehydrogenase 1.1.1.29 glycerate dehydrogenase 1.1.1.30 3-hydroxybutyrate dehydrogenase 1.1.1.31 3-hydroxyisobutyrate dehydrogenase 1.1.1.32 mevaldate reductase 1.1.1.33 mevaldate reductase (NADPH) 1.1.1.34 hydroxymethylglutaryl-CoA reductase (NADPH) 1.1.1.35 3-hydroxyacyl-CoA -

US5593674.Pdf
|||||||||| USOO5593674A United States Patent (19) 11 Patent Number: 5,593,674 Drayna et al. 45) Date of Patent: Jan. 14, 1997 54 PLASMA CARBOXYPEPTIDASE Fricker et al., "Isolation and Sequence Analysis of cDNA for Rat Carboxypeptidase E (EC 3.4.17.10), A Neuropeptide 75 Inventors: Dennis T. Drayna, San Francisco; Dan Processing Enzyme' Molecular Endocrinol L. Eaton, San Rafael, both of Calif. ogy3(4):666-673 (1989). Gardell et al., “A Novel Rat Carboxypeptidase, CPA2: 73) Assignee: Genentech, Inc., South San Francisco, Characterization, Molecular Cloning and Evolutionary Calif. Implications on Substrate Specificity in the Carboxypepti dase Gene Family” Journal of Biological Chemistry (21) Appl. No.: 430,787 263(33):17828-17836 (1988). Gebhard et al., “cDNA Cloning and Complete Primary 22 Filed: Apr. 27, 1995 Structure of the Small, Active Subunit of Human Carbox ypeptidase N (Kininase 1)” European Journal of Biochem Related U.S. Application Data istry178:603-607 (1989). 62 Division of Ser. No. 277,540, Jul. 19, 1994, Pat. No. Goldstein et al., "Detection and Partial Characterization of a 5,474,901, which is a division of Ser. No. 167,727, Dec. 15, Human Mast Cell Carbosypeptidase” J. Immunol. 1993, Pat. No. 5,364,934, which is a continuation of Ser, No. 139(8):2724-2729 (1987). 959,944, Oct. 14, 1992, abandoned, which is a division of Goldstein et al., “Human Mast Cell Carboxypeptidase: Puri Ser. No. 649,591, Feb. 1, 1991, Pat. No. 5,206,161. fication and Characterization' J. Clin. Invest. 83:1630-1636 (51) Int. Cl. ............................. A61K 38/48 (1989). 52 U.S. -
WO 2013/167573 Al 14 November 2013 (14.11.2013) P O P C T
(12) INTERNATIONAL APPLICATION PUBLISHED UNDER THE PATENT COOPERATION TREATY (PCT) (19) World Intellectual Property Organization International Bureau (10) International Publication Number (43) International Publication Date WO 2013/167573 Al 14 November 2013 (14.11.2013) P O P C T (51) International Patent Classification: AO, AT, AU, AZ, BA, BB, BG, BH, BN, BR, BW, BY, C12C 5/00 (2006.01) C12C 7/047 (2006.01) BZ, CA, CH, CL, CN, CO, CR, CU, CZ, DE, DK, DM, C12C 7/04 (2006.01) C12C 7/28 (2006.01) DO, DZ, EC, EE, EG, ES, FI, GB, GD, GE, GH, GM, GT, HN, HR, HU, ID, IL, IN, IS, JP, KE, KG, KM, KN, KP, (21) International Application Number: KR, KZ, LA, LC, LK, LR, LS, LT, LU, LY, MA, MD, PCT/EP2013/059456 ME, MG, MK, MN, MW, MX, MY, MZ, NA, NG, NI, (22) International Filing Date: NO, NZ, OM, PA, PE, PG, PH, PL, PT, QA, RO, RS, RU, 7 May 2013 (07.05.2013) RW, SC, SD, SE, SG, SK, SL, SM, ST, SV, SY, TH, TJ, TM, TN, TR, TT, TZ, UA, UG, US, UZ, VC, VN, ZA, (25) Filing Language: English ZM, ZW. (26) Publication Language: English 4 Designated States (unless otherwise indicated, for every (30) Priority Data: kind of regional protection available): ARIPO (BW, GH, 12167720.7 11 May 2012 ( 11.05.2012) EP GM, KE, LR, LS, MW, MZ, NA, RW, SD, SL, SZ, TZ, UG, ZM, ZW), Eurasian (AM, AZ, BY, KG, KZ, RU, TJ, (71) Applicant: NOVOZYMES A S [DK/DK]; Krogshoejvej TM), European (AL, AT, BE, BG, CH, CY, CZ, DE, DK, 36, DK-2880 Bagsvaerd (DK). -
SUPPLEMENTARY DATA Supplementary Table 1. Characteristics of the Organ Donors and Human Islet Preparations Used for RNA-Seq
SUPPLEMENTARY DATA Supplementary Table 1. Characteristics of the organ donors and human islet preparations used for RNA-seq and independent confirmation and mechanistic studies. Gender Age BMI Cause of death Purity (years) (kg/m2) (%) F 77 23.8 Trauma 45 M 36 26.3 CVD 51 M 77 25.2 CVD 62 F 46 22.5 CVD 60 M 40 26.2 Trauma 34 M 59 26.7 NA 58 M 51 26.2 Trauma 54 F 79 29.7 CH 21 M 68 27.5 CH 42 F 76 25.4 CH 30 F 75 29.4 CVD 24 F 73 30.0 CVD 16 M 63 NA NA 46 F 64 23.4 CH 76 M 69 25.1 CH 68 F 23 19.7 Trauma 70 M 47 27.7 CVD 48 F 65 24.6 CH 58 F 87 21.5 Trauma 61 F 72 23.9 CH 62 M 69 25 CVD 85 M 85 25.5 CH 39 M 59 27.7 Trauma 56 F 76 19.5 CH 35 F 50 20.2 CH 70 F 42 23 CVD 48 M 52 24.5 CH 60 F 79 27.5 CH 89 M 56 24.7 Cerebral ischemia 47 M 69 24.2 CVD 57 F 79 28.1 Trauma 61 M 79 23.7 NA 13 M 82 23 CH 61 M 32 NA NA 75 F 23 22.5 Cardiac arrest 46 M 51 NA Trauma 37 Abbreviations: F: Female; M: Male; BMI: Body mass index; CVD: Cardiovascular disease; CH: Cerebral hemorrhage.