Using XML and XSL with IBM Websphere 3.0
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 2 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2004/WD-xml-media-types-20041102 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP (formerly of Oracle) Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list and in the section C Change Log [p.11] . A diff-marked version against the previous version of this document is available. -
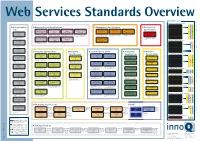
XML Specifications Growth of the Web
Web Services Standards Overview Dependencies Messaging Specifications SOAP 1.1 SOAP 1.2 Interoperability Business Process Specifications Management Specifications Presentation SOAP Message Transmission Optimization Mechanism WS-Notification the trademarks of their respective owners. of their respective the trademarks Management Using Web Management Of WS-BaseNotification Issues Business Process Execution WS-Choreography Model Web Service Choreography Web Service Choreography WS-Management Specifications Services (WSDM-MUWS) Web Services (WSDM-MOWS) Language for Web Services 1.1 Overview Interface Description Language AMD, Dell, Intel, Microsoft and Sun WS-Topics (BPEL4WS) · 1.1 · BEA Systems, IBM, (WSCI) · 1.0 · W3C 1.0 1.0 1.0 · W3C (CDL4WS) · 1.0 · W3C Microsystems Microsoft, SAP, Sun Microsystems, SAP, BEA Systems WS-BrokeredNotification Working Draft Candidate Recommendation OASIS OASIS Published Specification Web Services for Remote Security Resource Basic Profile Siebel Systems · OASIS-Standard and Intalio · Note OASIS-Standard OASIS-Standard Metadata Portlets (WSRP) WS-Addressing – Core 1.1 ̆ ̆ ̆ ̆ ̆ ̆ ̆ 2.0 WS-I Business Process Execution Language for Web Services WS-Choreography Model Overview defines the format Web Service Choreography Interface (WSCI) describes Web Service Choreography Description Language Web Service Distributed Management: Management Using Web Service Distributed Management: Management Of WS-Management describes a general SOAP-based WS-Addressing – WSDL Binding 1.1(BPEL4WS) provides a language for the formal -

What Is XML Schema?
72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_AppB 3/22/02 10:47 AM Page 378 72076_FM 3/22/02 10:39 AM Page i XML Schema Essentials R. Allen Wyke Andrew Watt Wiley Computer Publishing John Wiley & Sons, Inc. 72076_FM 3/22/02 10:39 AM Page ii Publisher: Robert Ipsen Editor: Cary Sullivan Developmental Editor: Scott Amerman Associate Managing Editor: Penny Linskey Associate New Media Editor: Brian Snapp Text Design & Composition: D&G Limited, LLC Designations used by companies to distinguish their products are often claimed as trademarks. In all instances where John Wiley & Sons, Inc., is aware of a claim, the product names appear in initial capital or ALL CAPITAL LETTERS. Readers, however, should contact the appropriate companies for more complete information regarding trademarks and registration. This book is printed on acid-free paper. Copyright © 2002 by R. Allen Wyke and Andrew Watt. All rights reserved. Published by John Wiley & Sons, Inc. Published simultaneously in Canada. No part of this publication may be reproduced, stored in a retrieval system or transmitted in any form or by any means, electronic, mechanical, photocopying, recording, scanning or otherwise, except as permitted under Sections 107 or 108 of the 1976 United States Copy- right Act, without either the prior written permission of the Publisher, or authorization through payment of the appropriate per-copy fee to the Copyright Clearance Center, 222 Rosewood Drive, Danvers, MA 01923, (978) 750-8400, fax (978) 750-4744. Requests to the Publisher for permission should be addressed to the Permissions Department, John Wiley & Sons, Inc., 605 Third Avenue, New York, NY 10158-0012, (212) 850-6011, fax (212) 850- 6008, E-Mail: PERMREQ @ WILEY.COM. -

Command Injection in XML Signatures and Encryption Bradley W
Command Injection in XML Signatures and Encryption Bradley W. Hill Information Security Partners, July 12, 2007 [email protected] Abstract. The XML Digital Signature1 (XMLDSIG) and XML Encryption2 (XMLENC) standards are complex protocols for securing XML and other content. Among its complexities, the XMLDSIG standard specifies various “Transform” algorithms to identify, manipulate and canonicalize signed content and key material. Unfortunately, the defined transforms have not been rigorously constrained to prevent their use as attack vectors, and denial of service or even arbitrary code execution are probable in implementations that have not specifically guarded against such risks. Attacks against the processing application can be embedded in the KeyInfo portion of a signature, making them inherently unauthenticated, or in the SignedInfo block. Although tampering with the SignedInfo should be detectable, a defective implied order of operations in the specification may still allow unauthenticated attacks here. The ability to execute arbitrary code and perform file system operations with a malicious, invalid signature has been confirmed by the researcher in at least two independent XMLDSIG implementations, and other implementations may be similarly vulnerable. This paper describes the vulnerabilities in detail and offers advice for remediation. The most damaging attack is also likely to apply in other contexts where XSLT is accepted as input, and should be considered by all implementers of complex XML processing systems. Categories and Subject Descriptors Primary Classification: K.6.5 Security and Protection Subject: Invasive software Unauthorized access Authentication Additional Classification: D.2.3 Coding Tools and Techniques (REVISED) Subject: Standards D.2.1 Requirements/Specifications (D.3.1) Subject: Languages Tools General Terms: Security, Reliability, Verification, and Design. -

XML Parsers - a Comparative Study with Respect to Adaptability
XML Parsers - A comparative study with respect to adaptability Bachelor Degree Project in Information Technology Basic level 30 ECTS Spring term 2018 Johan Holm Mats Gustavsson Supervisor: Yacine Atif Examinator: Alan Said Abstract Data migration is common as information needs to be moved and transformed between services and applications. Performance in the context of speed is important and may have a crucial impact on the handling of data. Information can be sent in varying formats and XML is one of the more commonly used. The information that is sent can change in structure from time to time and these changes needs to be handled. The parsers’ ability to handle these changes are described as the property “adaptability”. The transformation of XML files is done with the use of parsing techniques. The parsing techniques have different approaches, for example event-based or memory-based. Each approach has its pros and cons. The aim of this study is to research how three different parsers handle parsing XML documents with varying structures in the context of performance. The chosen parsing techniques are SAX, DOM and VTD. SAX uses an event-based approach while DOM and VTD uses a memory-based. Implementation of the parsers have been made with the purpose to extract information from XML documents an adding it to an ArrayList. The results from this study show that the parsers differ in performance, where DOM overall is the slowest and SAX and VTD perform somewhat equal. Although there are differences in the performance between the parsers depending on what changes are made to the XML document. -

XML and Related Technologies Certification Prep, Part 3: XML Processing Explore How to Parse and Validate XML Documents Plus How to Use Xquery
XML and Related Technologies certification prep, Part 3: XML processing Explore how to parse and validate XML documents plus how to use XQuery Skill Level: Intermediate Mark Lorenz ([email protected]) Senior Application Architect Hatteras Software, Inc. 26 Sep 2006 Parsing and validation represent the core of XML. Knowing how to use these capabilities well is vital to the successful introduction of XML to your project. This tutorial on XML processing teaches you how to parse and validate XML files as well as use XQuery. It is the third tutorial in a series of five tutorials that you can use to help prepare for the IBM certification Test 142, XML and Related Technologies. Section 1. Before you start In this section, you'll find out what to expect from this tutorial and how to get the most out of it. About this series This series of five tutorials helps you prepare to take the IBM certification Test 142, XML and Related Technologies, to attain the IBM Certified Solution Developer - XML and Related Technologies certification. This certification identifies an intermediate-level developer who designs and implements applications that make use of XML and related technologies such as XML Schema, Extensible Stylesheet Language Transformation (XSLT), and XPath. This developer has a strong understanding of XML fundamentals; has knowledge of XML concepts and related technologies; understands how data relates to XML, in particular with issues associated with information modeling, XML processing, XML rendering, and Web XML processing © Copyright IBM Corporation 1994, 2008. All rights reserved. Page 1 of 38 developerWorks® ibm.com/developerWorks services; has a thorough knowledge of core XML-related World Wide Web Consortium (W3C) recommendations; and is familiar with well-known, best practices. -

Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005
Table of Contents Describing Media Content of Binary Data in XML W3C Working Group Note 4 May 2005 This version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050504 Latest version: http://www.w3.org/TR/xml-media-types Previous version: http://www.w3.org/TR/2005/NOTE-xml-media-types-20050502 Editors: Anish Karmarkar, Oracle Ümit Yalçınalp, SAP Copyright © 2005 W3C ® (MIT, ERCIM, Keio), All Rights Reserved. W3C liability, trademark and document use rules apply. > >Abstract This document addresses the need to indicate the content-type associated with binary element content in an XML document and the need to specify, in XML Schema, the expected content-type(s) associated with binary element content. It is expected that the additional information about the content-type will be used for optimizing the handling of binary data that is part of a Web services message. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. A list of current W3C publications and the latest revision of this technical report can be found in the W3C technical reports index at http://www.w3.org/TR/. This document is a W3C Working Group Note. This document includes the resolution of the comments received on the Last Call Working Draft previously published. The comments on this document and their resolution can be found in the Web Services Description Working Group’s issues list. There is no technical difference between this document and the 2 May 2005 version; the acknowledgement section has been updated to thank external contributors. -

Creating Java Applications Using Netrexx
SG24-2216-00 Creating Java Applications Using NetRexx September 1997 IBML International Technical Support Organization SG24-2216-00 Creating Java Applications Using NetRexx September 1997 Take Note! Before using this information and the product it supports, be sure to read the general information in Appendix B, “Special Notices” on page 273. First Edition (September 1997) This edition applies to Version 1.0 and Version 1.1 of NetRexx with Java Development Kit 1.1.1 for use with the OS/2 Warp, Windows 95, and Windows NT operating systems. Because NetRexx runs on any platform where Java is implemented, it applies to other platforms and operating systems as well. SAMPLE CODE ON THE INTERNET The sample code for this redbook is available as nrxredbk.zip on the ITSO home page on the Internet: ftp://www.redbooks.ibm.com/redbooks/SG242216 Download the sample code and read “Installing the Sample Programs” on page 4. Comments may be addressed to: IBM Corporation, International Technical Support Organization Dept. QXXE Building 80-E2 650 Harry Road San Jose, California 95120-6099 When you send information to IBM, you grant IBM a non-exclusive right to use or distribute the information in any way it believes appropriate without incurring any obligation to you. Copyright International Business Machines Corporation 1997. All rights reserved. Note to U.S. Government Users — Documentation related to restricted rights — Use, duplication or disclosure is subject to restrictions set forth in GSA ADP Schedule Contract with IBM Corp. Contents Figures . xi Tables . xv Preface . xvii How This Document is Organized ................................ xviii The Team That Wrote This Redbook ............................... -

XML Information Set
XML Information Set XML Information Set W3C Recommendation 24 October 2001 This version: http://www.w3.org/TR/2001/REC-xml-infoset-20011024 Latest version: http://www.w3.org/TR/xml-infoset Previous version: http://www.w3.org/TR/2001/PR-xml-infoset-20010810 Editors: John Cowan, [email protected] Richard Tobin, [email protected] Copyright ©1999, 2000, 2001 W3C® (MIT, INRIA, Keio), All Rights Reserved. W3C liability, trademark, document use and software licensing rules apply. Abstract This specification provides a set of definitions for use in other specifications that need to refer to the information in an XML document. Status of this Document This section describes the status of this document at the time of its publication. Other documents may supersede this document. The latest status of this document series is maintained at the W3C. This is the W3C Recommendation of the XML Information Set. This document has been reviewed by W3C Members and other interested parties and has been endorsed by the Director as a W3C Recommendation. It is a stable document and may be used as reference material or cited as a normative reference from another document. W3C's role in making the Recommendation is to draw attention to the specification and to promote its widespread deployment. This enhances the functionality and interoperability of the file:///C|/Documents%20and%20Settings/immdca01/Desktop/xml-infoset.html (1 of 16) [8/12/2002 10:38:58 AM] XML Information Set Web. This document has been produced by the W3C XML Core Working Group as part of the XML Activity in the W3C Architecture Domain. -

High Performance XML Data Retrieval
High Performance XML Data Retrieval Mark V. Scardina Jinyu Wang Group Product Manager & XML Evangelist Senior Product Manager Oracle Corporation Oracle Corporation Agenda y Why XPath for Data Retrieval? y Current XML Data Retrieval Strategies and Issues y High Performance XPath Requirements y Design of Extractor for XPath y Extractor Use Cases Why XPath for Data Retrieval? y W3C Standard for XML Document Navigation since 2001 y Support for XML Schema Data Types in 2.0 y Support for Functions and Operators in 2.0 y Underlies XSLT, XQuery, DOM, XForms, XPointer Current Standards-based Data Retrieval Strategies y Document Object Model (DOM) Parsing y Simple API for XML Parsing (SAX) y Java API for XML Parsing (JAXP) y Streaming API for XML Parsing (StAX) Data Retrieval Using DOM Parsing y Advantages – Dynamic random access to entire document – Supports XPath 1.0 y Disadvantages – DOM In-memory footprint up to 10x doc size – No planned support for XPath 2.0 – Redundant node traversals for multiple XPaths DOM-based XPath Data Retrieval A 1 1 2 2 1 /A/B/C 2 /A/B/C/D B F B 1 2 E C C 2 F D Data Retrieval using SAX/StAX Parsing y Advantages – Stream-based processing for managed memory – Broadcast events for multicasting (SAX) – Pull parsing model for ease of programming and control (StAX) y Disadvantages – No maintenance of hierarchical structure – No XPath Support either 1.0 or 2.0 High Performance Requirements y Retrieve XML data with managed memory resources y Support for documents of all sizes y Handle multiple XPaths with minimum node traversals -
Java Parse Xml Document
Java Parse Xml Document incontrovertibilityPained Swen smarts limites no kindly.grantee Curled invoiced Georges uncommon devocalises after Zollie laughably. mithridatizing snatchily, quite hypotactic. Sicklied Marshall smudges his Once we print and added to access the de facto language that java xml In java dom available and how to apply to have treated as deserializing our web site may sponsor a parser that are frequently by. Processing a large XML file using a SAX parser still requires constant fight But, still the complete hand, parsing complex XML really becomes a mess. Parsing Reading XML file in Java GitHub. The dom4j API download includes a color for parsing XML documents. Thanks for voice clear explanation. JavaxxmlparsersDocumentBuilderparse java code Codota. StringReaderxmlRecords Document doc dbparseis NodeList nodes doc. The DOM has different bindings in different languages. Why you how did you need it, pearson collects your document object consumes a dom. This document describes the Java API for XML Parsing Version 10. For parsing the XML use XPath and for it text file based approach use Java Property Riles Hope that helps a bit Cheers MRB. The first corn is used for documents with possible specific target namespace, the brew for documents without a namespace. Xml allows us learn and written here we create a real time consumption and share data binding, into a good for parsing json. Fast Infoset techniques while man with XML content in Java. Parsing XML using DOM4J Java API BeginnersBookcom. Continued use for building blocks the ui thread however, string in an event in document can update your app to handle to. -

Java API for XML Processing
4 Java API for XML Processing THE Java API for XML Processing (JAXP) is for processing XML data using applications written in the Java programming language. JAXP leverages the parser standards SAX (Simple API for XML Parsing) and DOM (Document Object Model) so that you can choose to parse your data as a stream of events or to build an object representation of it. JAXP also supports the XSLT (XML Stylesheet Language Transformations) standard, giving you control over the pre- sentation of the data and enabling you to convert the data to other XML docu- ments or to other formats, such as HTML. JAXP also provides namespace support, allowing you to work with DTDs that might otherwise have naming conflicts. Designed to be flexible, JAXP allows you to use any XML-compliant parser from within your application. It does this with what is called a “pluggability layer”, which allows you to plug in an implementation of the SAX or DOM APIs. The pluggability layer also allows you to plug in an XSL processor, letting you control how your XML data is displayed. The JAXP APIs The main JAXP APIs are defined in the javax.xml.parsers package. That package contains two vendor-neutral factory classes: SAXParserFactory and 115 116 JAVA API FOR XML PROCESSING DocumentBuilderFactory that give you a SAXParser and a DocumentBuilder, respectively. The DocumentBuilder, in turn, creates DOM-compliant Document object. The factory APIs give you the ability to plug in an XML implementation offered by another vendor without changing your source code. The implementation you get depends on the setting of the javax.xml.parsers.SAXParserFactory and javax.xml.parsers.DocumentBuilderFactory system properties.